How Microsoft develops with DevOps
Microsoft strives to use One Engineering System to build and deploy all Microsoft products with a solid DevOps process centered on a Git branching and release flow. This article highlights practical implementation, how the system scales from small services to massive platform development needs, and lessons learned from using the system across various Microsoft teams.
Adopting a standardized development process is an ambitious undertaking. The requirements of different Microsoft organizations vary greatly, and requirements of different teams within organizations scale with size and complexity. To address these varied needs, Microsoft uses a trunk-based branching strategy to help develop products quickly, deploy them regularly, and deliver changes safely to production.
Microsoft also uses platform engineering principles as part of its One Engineering System.
Microsoft release flow
Every organization should settle on a standard code release process to ensure consistency across teams. The Microsoft release flow incorporates DevOps processes from development to release. The basic steps of the release flow consist of branch, push, pull request, and merge.
Branch
To fix a bug or implement a feature, a developer creates a new branch off the main integration branch. The Git lightweight branching model creates these short-lived topic branches for every code contribution. Developers commit early and avoid long-running feature branches by using feature flags.
Push
When the developer is ready to integrate and ship changes to the rest of the team, they push their local branch to a branch on the server, and open a pull request. Repositories with several hundred developers working in many branches use a naming convention for server branches to alleviate confusion and branch proliferation. Developers usually create branches named users/<username>/feature, where <username> is their account name.
Pull request
Pull requests control topic branch merges into the main branch and ensure that branch policies are satisfied. The pull request process builds the proposed changes and runs a quick test pass. The first- and second-level test suites run around 60,000 tests in less than five minutes. This isn't the complete Microsoft test matrix, but is enough to quickly give confidence in pull requests.
Next, other members of the team review the code and approve the changes. Code review picks up where the automated tests left off, and is particularly useful for spotting architectural problems. Manual code reviews ensure that other engineers on the team have visibility into the changes and that code quality remains high.
Merge
Once the pull request satisfies all build policies and reviewers have signed off, the topic branch merges into the main integration branch, and the pull request is complete.
After merge, other acceptance tests run that take more time to complete. These traditional post-checkin tests do a more thorough validation. This testing process provides a good balance between having fast tests during pull request review and having complete test coverage before release.
Differences from GitHub Flow
GitHub Flow is a popular trunk-based development release flow for organizations to implement a scalable approach to Git. However, some organizations find that as their needs grow, they must diverge from parts of the GitHub Flow.
For example, an often overlooked part of GitHub Flow is that pull requests must deploy to production for testing before they can merge to the main branch. This process means that all pull requests wait in the deployment queue for merge.
Some teams have several hundred developers working constantly in a single repository, who can complete over 200 pull requests into the main branch per day. If each pull requests requires a deployment to multiple Azure data centers across the globe for testing, developers spend time waiting for branches to merge, instead of writing software.
Instead, Microsoft teams continue developing in the main branch and batch up deployments into timed releases, usually aligned with a three-week sprint cadence.
Implementation details
Here are some key implementation details of the Microsoft release flow:
Git repository strategy
Different teams have different strategies for managing their Git repositories. Some teams keep the majority of their code in one Git repository. Code is broken up into components, each in its own root-level folder. Large components, especially older components, may have multiple subcomponents that have separate subfolders within the parent component.

Adjunct repositories
Some teams also manage adjunct repositories. For instance, build and release agents and tasks, the VS Code extension, and open-source projects are developed on GitHub. Configuration changes check in to a separate repository. Other packages that the team depends on come from other places and are consumed via NuGet.
Mono repo or multi-repo
While some teams elect to have a single monolithic repository, the mono-repo, other Microsoft products use a multi-repo approach. Skype, for instance, has hundreds of small repositories that stitch together in various combinations to create many different clients, services, and tools. Especially for teams that embrace microservices, multi-repo can be the right approach. Usually, older products that began as monoliths find a mono-repo approach to be the easiest transition to Git, and their code organization reflects that.
Release branches
The Microsoft release flow keeps the main branch buildable at all times. Developers work in short-lived topic branches that merge to main. When a team is ready to ship, whether at the end of a sprint or for a major update, they start a new release branch off the main branch. Release branches never merge back to the main branch, so they might require cherry-picking important changes.
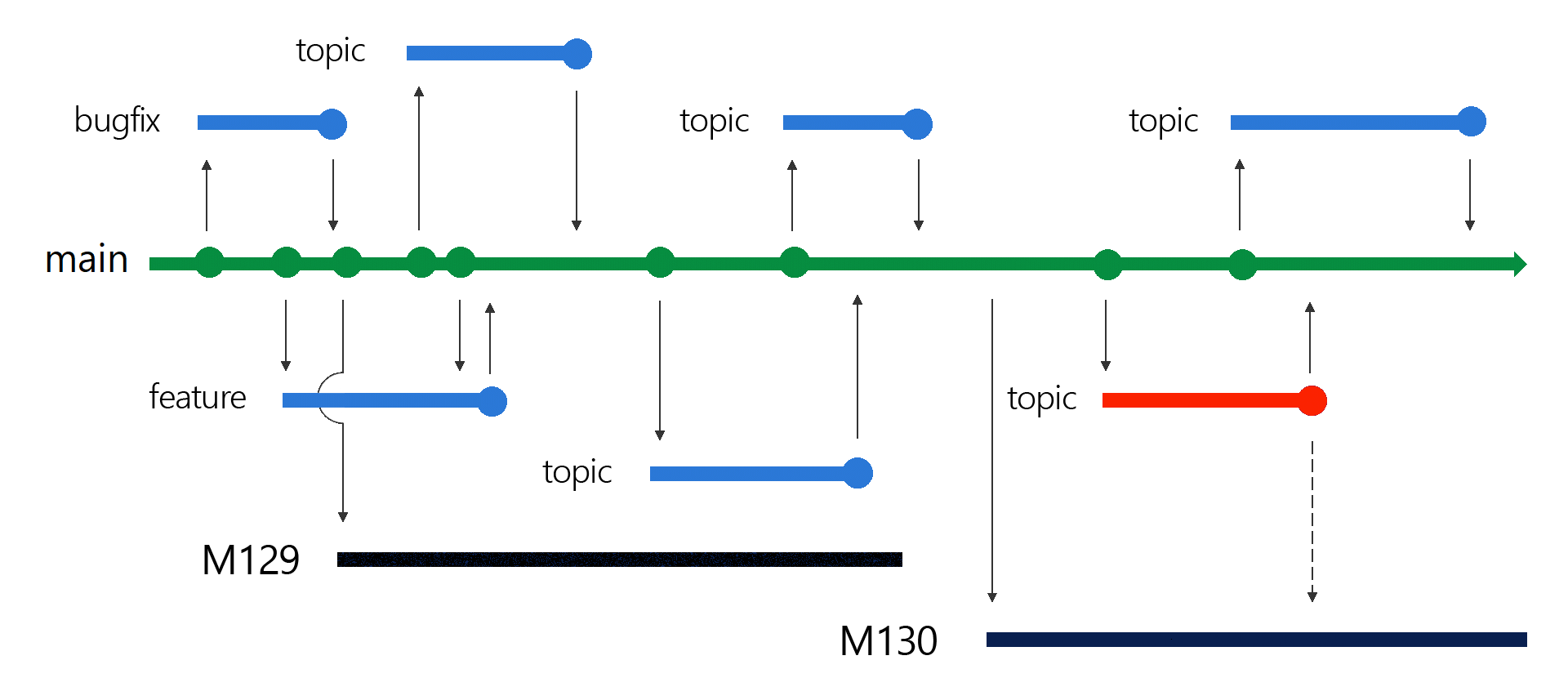
The following diagram shows short-lived branches in blue and release branches in black. One branch with a commit that needs cherry-picking appears in red.
Branch policies and permissions
Git branch policies help enforce the release branch structure and keep the main branch clean. For example, branch policies can prevent direct pushes to the main branch.
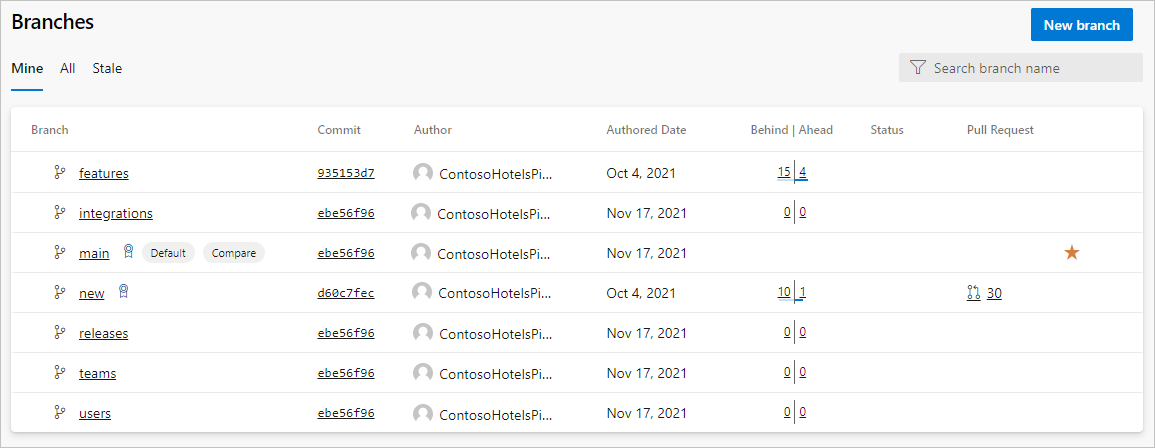
To keep branch hierarchy tidy, teams use permissions to block branch creation at the root level of the hierarchy. In the following example, everyone can create branches in folders like users/, features/, and teams/. Only release managers have permission to create branches under releases/, and some automation tools have permission to the integrations/ folder.
Git repository workflow
Within the repository and branch structure, developers do their daily work. Working environments vary heavily by team and by individual. Some developers prefer the command line, others like Visual Studio, and others work on different platforms. The structures and policies in place on Microsoft repositories ensure a solid and consistent foundation.
A typical workflow involves the following common tasks:
Build a new feature
Building a new feature is the core of a software developer's job. Non-Git parts of the process include looking at telemetry data, coming up with a design and a spec, and writing the actual code. Then, the developer starts working with the repository by syncing to the latest commit on main. The main branch is always buildable, so it's guaranteed to be a good starting point. The developer checks out a new feature branch, makes code changes, commits, pushes to the server, and starts a new pull request.
Use branch policies and checks
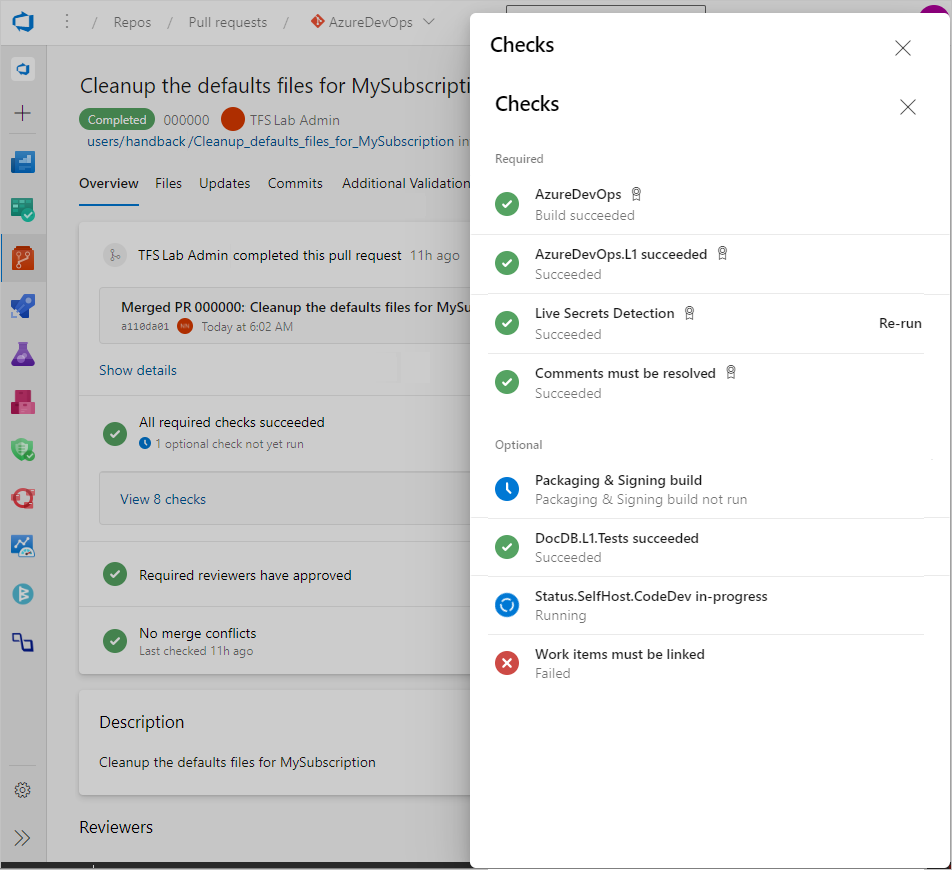
Upon creation of a pull request, automated systems check that the new code builds, doesn't break anything, and doesn't violate any security or compliance policies. This process doesn't block other work from happening in parallel.
Branch policies and checks can require a successful build including passed tests, signoff by the owners of any code touched, and several external checks to verify corporate policies before a pull request can be completed.
Integrate with Microsoft Teams
Many teams configure integration with Microsoft Teams, which announces the new pull request to the developers's teammates. The owners of any code touched are automatically added as reviewers. Microsoft teams often use optional reviewers for code that many people touch, like REST client generation and shared controls, to get expert eyes on those changes.
Deploy with feature flags
Once the reviewers, code owners, and automation are satisfied, the developer can complete the pull request. If there's a merge conflict, the developer gets instructions on how to sync to the conflict, fix it, and re-push the changes. The automation runs again on the fixed code, but humans don't have to sign off again.
The branch merges into main, and the new code deploys in the next sprint or major release. That doesn't mean the new feature will show up right away. Microsoft decouples the deployment and exposure of new features by using feature flags.
Even if the feature needs a little more work before it's ready to show off, it's safe to go to main if the product builds and deploys. Once in main, the code becomes part of an official build, where it's again tested, confirmed to meet policy, and digitally signed.
Shift left to detect issues early
This Git workflow provides several benefits. First, working out of a single main branch virtually eliminates merge debt. Second, the pull request flow provides a common point to enforce testing, code review, and error detection early in the pipeline. This shift left strategy helps shorten the feedback cycle to developers because it can detect errors in minutes, not hours or days. This strategy also gives confidence for refactoring, because all changes are tested constantly.
Currently, a product with 200+ pull requests might produce 300+ continuous integration builds per day, amounting to 500+ test runs every 24 hours. This level of testing would be impossible without the trunk-based branching and release workflow.
Release at sprint milestones
At the end of each sprint, the team creates a release branch from the main branch. For example, at the end of sprint 129, the team creates a new release branch releases/M129. The team then puts the sprint 129 branch into production.
After the branch of the release branch, the main branch remains open for developers to merge changes. These changes will deploy three weeks later in the next sprint deployment.

Release hotfixes
Sometimes changes need to go to production quickly. Microsoft won't usually add new features in the middle of a sprint, but sometimes wants to bring in a bug fix quickly to unblock users. Issues might be minor, such as typos, or large enough to cause an availability issue or live site incident.
Rectifying these issues starts with the normal workflow. A developer creates a branch from main, gets it code reviewed, and completes the pull request to merge it. The process always starts by making the change in main first. This allows creating the fix quickly and validating it locally without having to switch to the release branch.
Following this process also guarantees that the change gets into main, which is critical. Fixing a bug in the release branch without bringing the change back to main would mean the bug would recur during the next deployment, when the sprint 130 release branches from main. It's easy to forget to update main during the confusion and stress that can arise during an outage. Bringing changes to main first means always having the changes in both the main branch and the release branch.
Git functionality enables this workflow. To bring changes immediately into production, once a developer merges a pull request into main, they can use the pull request page to cherry-pick changes into the release branch. This process creates a new pull request that targets the release branch, backporting the contents that just merged into main.

Using the cherry-pick functionality opens a pull request quickly, providing the traceability and reliability of branch policies. Cherry-picking can happen on the server, without having to download the release branch to a local computer. Making changes, fixing merge conflicts, or making minor changes due to differences between the two branches can all happen on the server. Teams can edit changes directly from the browser-based text editor or via the Pull Request Merge Conflict Extension for a more advanced experience.
Once a pull request targets the release branch, the team code review it again, evaluates branch policies, tests the pull request, and merges it. After merge, the fix deploys to the first ring of servers in minutes. From there, the team progressively deploys the fix to more accounts by using deployment rings. As the changes deploy to more users, the team monitors success and verifies that the change fixes the bug while not introducing any deficiencies or slowdowns. The fix eventually deploys to all Azure data centers.
Move on to the next sprint
During the next three weeks, the team finishes adding features to sprint 130 and gets ready to deploy those changes. They create the new release branch, releases/M130 from main, and deploy that branch.
At this point, there are actually two branches in production. With a ring-based deployment to bring changes to production safely, the fast ring gets the sprint 130 changes, and the slow ring servers stay on sprint 129 while the new changes are validated in production.
Hotfixing a change in the middle of a deployment might require hotfixing two different releases, the sprint 129 release and the sprint 130 release. The team ports and deploys the hotfix to both release branches. The 130 branch redeploys with the hotfix to the rings that have already been upgraded. The 129 branch redeploys with the hotfix to the outer rings that haven't upgraded to the next sprint's version yet.
Once all the rings are deployed, the old sprint 129 branch is abandoned, because any changes brought into the sprint 129 branch as a hotfix have also been made in main. So, those changes will also be in the releases/M130 branch.

Summary
The release flow model is at the heart of how Microsoft develops with DevOps to deliver online services. This model uses a simple, trunk-based branching strategy. But instead of keeping developers stuck in a deployment queue, waiting to merge their changes, the Microsoft release flow lets developers keep working.
This release model also allows deploying new features across Azure data centers at a regular cadence, despite the size of the Microsoft codebases and the number of developers working in them. The model also allows bringing hotfixes into production quickly and efficiently.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for