Events
Mar 17, 9 PM - Mar 21, 10 AM
Join the meetup series to build scalable AI solutions based on real-world use cases with fellow developers and experts.
Register nowThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Learn how to use a pretrained ONNX model in ML.NET to detect objects in images.
Training an object detection model from scratch requires setting millions of parameters, a large amount of labeled training data and a vast amount of compute resources (hundreds of GPU hours). Using a pretrained model allows you to shortcut the training process.
In this tutorial, you learn how to:
This sample creates a .NET core console application that detects objects within an image using a pretrained deep learning ONNX model. The code for this sample can be found on the dotnet/machinelearning-samples repository on GitHub.
Object detection is a computer vision problem. While closely related to image classification, object detection performs image classification at a more granular scale. Object detection both locates and categorizes entities within images. Object detection models are commonly trained using deep learning and neural networks. See Deep learning vs machine learning for more information.
Use object detection when images contain multiple objects of different types.

Some use cases for object detection include:
Deep learning is a subset of machine learning. To train deep learning models, large quantities of data are required. Patterns in the data are represented by a series of layers. The relationships in the data are encoded as connections between the layers containing weights. The higher the weight, the stronger the relationship. Collectively, this series of layers and connections are known as artificial neural networks. The more layers in a network, the "deeper" it is, making it a deep neural network.
There are different types of neural networks, the most common being Multi-Layered Perceptron (MLP), Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). The most basic is the MLP, which maps a set of inputs to a set of outputs. This neural network is good when the data does not have a spatial or time component. The CNN makes use of convolutional layers to process spatial information contained in the data. A good use case for CNNs is image processing to detect the presence of a feature in a region of an image (for example, is there a nose in the center of an image?). Finally, RNNs allow for the persistence of state or memory to be used as input. RNNs are used for time-series analysis, where the sequential ordering and context of events is important.
Object detection is an image-processing task. Therefore, most deep learning models trained to solve this problem are CNNs. The model used in this tutorial is the Tiny YOLOv2 model, a more compact version of the YOLOv2 model described in the paper: "YOLO9000: Better, Faster, Stronger" by Redmon and Farhadi. Tiny YOLOv2 is trained on the Pascal VOC dataset and is made up of 15 layers that can predict 20 different classes of objects. Because Tiny YOLOv2 is a condensed version of the original YOLOv2 model, a tradeoff is made between speed and accuracy. The different layers that make up the model can be visualized using tools like Netron. Inspecting the model would yield a mapping of the connections between all the layers that make up the neural network, where each layer would contain the name of the layer along with the dimensions of the respective input / output. The data structures used to describe the inputs and outputs of the model are known as tensors. Tensors can be thought of as containers that store data in N-dimensions. In the case of Tiny YOLOv2, the name of the input layer is image and it expects a tensor of dimensions 3 x 416 x 416. The name of the output layer is grid and generates an output tensor of dimensions 125 x 13 x 13.

The YOLO model takes an image 3(RGB) x 416px x 416px. The model takes this input and passes it through the different layers to produce an output. The output divides the input image into a 13 x 13 grid, with each cell in the grid consisting of 125 values.
The Open Neural Network Exchange (ONNX) is an open source format for AI models. ONNX supports interoperability between frameworks. This means you can train a model in one of the many popular machine learning frameworks like PyTorch, convert it into ONNX format and consume the ONNX model in a different framework like ML.NET. To learn more, visit the ONNX website.

The pretrained Tiny YOLOv2 model is stored in ONNX format, a serialized representation of the layers and learned patterns of those layers. In ML.NET, interoperability with ONNX is achieved with the ImageAnalytics and OnnxTransformer NuGet packages. The ImageAnalytics package contains a series of transforms that take an image and encode it into numerical values that can be used as input into a prediction or training pipeline. The OnnxTransformer package leverages the ONNX Runtime to load an ONNX model and use it to make predictions based on input provided.

Now that you have a general understanding of what ONNX is and how Tiny YOLOv2 works, it's time to build the application.
Create a C# Console Application called "ObjectDetection". Click the Next button.
Choose .NET 8 as the framework to use. Click the Create button.
Install the Microsoft.ML NuGet Package:
Note
This sample uses the latest stable version of the NuGet packages mentioned unless otherwise stated.
Download The project assets directory zip file and unzip.
Copy the assets directory into your ObjectDetection project directory. This directory and its subdirectories contain the image files (except for the Tiny YOLOv2 model, which you'll download and add in the next step) needed for this tutorial.
Download the Tiny YOLOv2 model from the ONNX Model Zoo.
Copy the model.onnx file into your ObjectDetection project assets\Model directory and rename it to TinyYolo2_model.onnx. This directory contains the model needed for this tutorial.
In Solution Explorer, right-click each of the files in the asset directory and subdirectories and select Properties. Under Advanced, change the value of Copy to Output Directory to Copy if newer.
Open the Program.cs file and add the following additional using directives to the top of the file:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Next, define the paths of the various assets.
First, create the GetAbsolutePath method at the bottom of the Program.cs file.
string GetAbsolutePath(string relativePath)
{
FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location);
string assemblyFolderPath = _dataRoot.Directory.FullName;
string fullPath = Path.Combine(assemblyFolderPath, relativePath);
return fullPath;
}
Then, below the using directives, create fields to store the location of your assets.
var assetsRelativePath = @"../../../assets";
string assetsPath = GetAbsolutePath(assetsRelativePath);
var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx");
var imagesFolder = Path.Combine(assetsPath, "images");
var outputFolder = Path.Combine(assetsPath, "images", "output");
Add a new directory to your project to store your input data and prediction classes.
In Solution Explorer, right-click the project, and then select Add > New Folder. When the new folder appears in the Solution Explorer, name it "DataStructures".
Create your input data class in the newly created DataStructures directory.
In Solution Explorer, right-click the DataStructures directory, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to ImageNetData.cs. Then, select Add.
The ImageNetData.cs file opens in the code editor. Add the following using directive to the top of ImageNetData.cs:
using System.Collections.Generic;
using System.IO;
using System.Linq;
using Microsoft.ML.Data;
Remove the existing class definition and add the following code for the ImageNetData class to the ImageNetData.cs file:
public class ImageNetData
{
[LoadColumn(0)]
public string ImagePath;
[LoadColumn(1)]
public string Label;
public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder)
{
return Directory
.GetFiles(imageFolder)
.Where(filePath => Path.GetExtension(filePath) != ".md")
.Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) });
}
}
ImageNetData is the input image data class and has the following String fields:
ImagePath contains the path where the image is stored.Label contains the name of the file.Additionally, ImageNetData contains a method ReadFromFile that loads multiple image files stored in the imageFolder path specified and returns them as a collection of ImageNetData objects.
Create your prediction class in the DataStructures directory.
In Solution Explorer, right-click the DataStructures directory, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to ImageNetPrediction.cs. Then, select Add.
The ImageNetPrediction.cs file opens in the code editor. Add the following using directive to the top of ImageNetPrediction.cs:
using Microsoft.ML.Data;
Remove the existing class definition and add the following code for the ImageNetPrediction class to the ImageNetPrediction.cs file:
public class ImageNetPrediction
{
[ColumnName("grid")]
public float[] PredictedLabels;
}
ImageNetPrediction is the prediction data class and has the following float[] field:
PredictedLabels contains the dimensions, objectness score, and class probabilities for each of the bounding boxes detected in an image.The MLContext class is a starting point for all ML.NET operations, and initializing mlContext creates a new ML.NET environment that can be shared across the model creation workflow objects. It's similar, conceptually, to DBContext in Entity Framework.
Initialize the mlContext variable with a new instance of MLContext by adding the following line below the outputFolder field.
MLContext mlContext = new MLContext();
The model segments an image into a 13 x 13 grid, where each grid cell is 32px x 32px. Each grid cell contains 5 potential object bounding boxes. A bounding box has 25 elements:
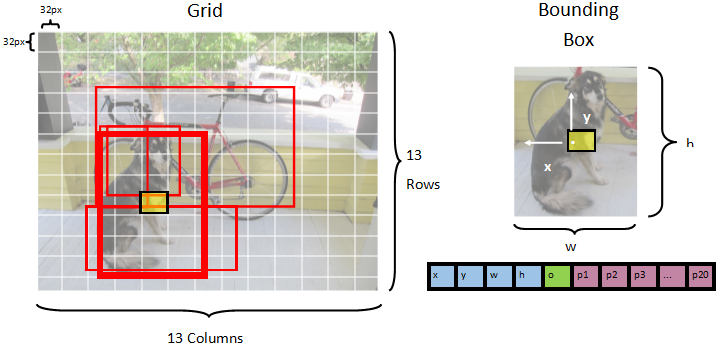
x the x position of the bounding box center relative to the grid cell it's associated with.y the y position of the bounding box center relative to the grid cell it's associated with.w the width of the bounding box.h the height of the bounding box.o the confidence value that an object exists within the bounding box, also known as objectness score.p1-p20 class probabilities for each of the 20 classes predicted by the model.In total, the 25 elements describing each of the 5 bounding boxes make up the 125 elements contained in each grid cell.
The output generated by the pretrained ONNX model is a float array of length 21125, representing the elements of a tensor with dimensions 125 x 13 x 13. In order to transform the predictions generated by the model into a tensor, some post-processing work is required. To do so, create a set of classes to help parse the output.
Add a new directory to your project to organize the set of parser classes.
The data output by the model contains coordinates and dimensions of the bounding boxes of objects within the image. Create a base class for dimensions.
In Solution Explorer, right-click the YoloParser directory, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to DimensionsBase.cs. Then, select Add.
The DimensionsBase.cs file opens in the code editor. Remove all using directives and existing class definition.
Add the following code for the DimensionsBase class to the DimensionsBase.cs file:
public class DimensionsBase
{
public float X { get; set; }
public float Y { get; set; }
public float Height { get; set; }
public float Width { get; set; }
}
DimensionsBase has the following float properties:
X contains the position of the object along the x-axis.Y contains the position of the object along the y-axis.Height contains the height of the object.Width contains the width of the object.Next, create a class for your bounding boxes.
In Solution Explorer, right-click the YoloParser directory, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to YoloBoundingBox.cs. Then, select Add.
The YoloBoundingBox.cs file opens in the code editor. Add the following using directive to the top of YoloBoundingBox.cs:
using System.Drawing;
Just above the existing class definition, add a new class definition called BoundingBoxDimensions that inherits from the DimensionsBase class to contain the dimensions of the respective bounding box.
public class BoundingBoxDimensions : DimensionsBase { }
Remove the existing YoloBoundingBox class definition and add the following code for the YoloBoundingBox class to the YoloBoundingBox.cs file:
public class YoloBoundingBox
{
public BoundingBoxDimensions Dimensions { get; set; }
public string Label { get; set; }
public float Confidence { get; set; }
public RectangleF Rect
{
get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); }
}
public Color BoxColor { get; set; }
}
YoloBoundingBox has the following properties:
Dimensions contains dimensions of the bounding box.Label contains the class of object detected within the bounding box.Confidence contains the confidence of the class.Rect contains the rectangle representation of the bounding box's dimensions.BoxColor contains the color associated with the respective class used to draw on the image.Now that the classes for dimensions and bounding boxes are created, it's time to create the parser.
In Solution Explorer, right-click the YoloParser directory, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to YoloOutputParser.cs. Then, select Add.
The YoloOutputParser.cs file opens in the code editor. Add the following using directives to the top of YoloOutputParser.cs:
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Linq;
Inside the existing YoloOutputParser class definition, add a nested class that contains the dimensions of each of the cells in the image. Add the following code for the CellDimensions class that inherits from the DimensionsBase class at the top of the YoloOutputParser class definition.
class CellDimensions : DimensionsBase { }
Inside the YoloOutputParser class definition, add the following constants and field.
public const int ROW_COUNT = 13;
public const int COL_COUNT = 13;
public const int CHANNEL_COUNT = 125;
public const int BOXES_PER_CELL = 5;
public const int BOX_INFO_FEATURE_COUNT = 5;
public const int CLASS_COUNT = 20;
public const float CELL_WIDTH = 32;
public const float CELL_HEIGHT = 32;
private int channelStride = ROW_COUNT * COL_COUNT;
ROW_COUNT is the number of rows in the grid the image is divided into.COL_COUNT is the number of columns in the grid the image is divided into.CHANNEL_COUNT is the total number of values contained in one cell of the grid.BOXES_PER_CELL is the number of bounding boxes in a cell,BOX_INFO_FEATURE_COUNT is the number of features contained within a box (x,y,height,width,confidence).CLASS_COUNT is the number of class predictions contained in each bounding box.CELL_WIDTH is the width of one cell in the image grid.CELL_HEIGHT is the height of one cell in the image grid.channelStride is the starting position of the current cell in the grid.When the model makes a prediction, also known as scoring, it divides the 416px x 416px input image into a grid of cells the size of 13 x 13. Each cell contains is 32px x 32px. Within each cell, there are 5 bounding boxes each containing 5 features (x, y, width, height, confidence). In addition, each bounding box contains the probability of each of the classes, which in this case is 20. Therefore, each cell contains 125 pieces of information (5 features + 20 class probabilities).
Create a list of anchors below channelStride for all 5 bounding boxes:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Anchors are predefined height and width ratios of bounding boxes. Most object or classes detected by a model have similar ratios. This is valuable when it comes to creating bounding boxes. Instead of predicting the bounding boxes, the offset from the predefined dimensions is calculated therefore reducing the computation required to predict the bounding box. Typically these anchor ratios are calculated based on the dataset used. In this case, because the dataset is known and the values have been precomputed, the anchors can be hard-coded.
Next, define the labels or classes that the model will predict. This model predicts 20 classes, which is a subset of the total number of classes predicted by the original YOLOv2 model.
Add your list of labels below the anchors.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
There are colors associated with each of the classes. Assign your class colors below your labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
There are a series of steps involved in the post-processing phase. To help with that, several helper methods can be employed.
The helper methods used in by the parser are:
Sigmoid applies the sigmoid function that outputs a number between 0 and 1.Softmax normalizes an input vector into a probability distribution.GetOffset maps elements in the one-dimensional model output to the corresponding position in a 125 x 13 x 13 tensor.ExtractBoundingBoxes extracts the bounding box dimensions using the GetOffset method from the model output.GetConfidence extracts the confidence value that states how sure the model is that it has detected an object and uses the Sigmoid function to turn it into a percentage.MapBoundingBoxToCell uses the bounding box dimensions and maps them onto its respective cell within the image.ExtractClasses extracts the class predictions for the bounding box from the model output using the GetOffset method and turns them into a probability distribution using the Softmax method.GetTopResult selects the class from the list of predicted classes with the highest probability.IntersectionOverUnion filters overlapping bounding boxes with lower probabilities.Add the code for all the helper methods below your list of classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Once you have defined all of the helper methods, it's time to use them to process the model output.
Below the IntersectionOverUnion method, create the ParseOutputs method to process the output generated by the model.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Create a list to store your bounding boxes and define variables inside the ParseOutputs method.
var boxes = new List<YoloBoundingBox>();
Each image is divided into a grid of 13 x 13 cells. Each cell contains five bounding boxes. Below the boxes variable, add code to process all of the boxes in each of the cells.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Inside the inner-most loop, calculate the starting position of the current box within the one-dimensional model output.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Directly below that, use the ExtractBoundingBoxDimensions method to get the dimensions of the current bounding box.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Then, use the GetConfidence method to get the confidence for the current bounding box.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
After that, use the MapBoundingBoxToCell method to map the current bounding box to the current cell being processed.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Before doing any further processing, check whether your confidence value is greater than the threshold provided. If not, process the next bounding box.
if (confidence < threshold)
continue;
Otherwise, continue processing the output. The next step is to get the probability distribution of the predicted classes for the current bounding box using the ExtractClasses method.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Then, use the GetTopResult method to get the value and index of the class with the highest probability for the current box and compute its score.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Use the topScore to once again keep only those bounding boxes that are above the specified threshold.
if (topScore < threshold)
continue;
Finally, if the current bounding box exceeds the threshold, create a new BoundingBox object and add it to the boxes list.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Once all cells in the image have been processed, return the boxes list. Add the following return statement below the outer-most for-loop in the ParseOutputs method.
return boxes;
Now that all of the highly confident bounding boxes have been extracted from the model output, additional filtering needs to be done to remove overlapping images. Add a method called FilterBoundingBoxes below the ParseOutputs method:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
Inside the FilterBoundingBoxes method, start off by creating an array equal to the size of detected boxes and marking all slots as active or ready for processing.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Then, sort the list containing your bounding boxes in descending order based on confidence.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
After that, create a list to hold the filtered results.
var results = new List<YoloBoundingBox>();
Begin processing each bounding box by iterating over each of the bounding boxes.
for (int i = 0; i < boxes.Count; i++)
{
}
Inside of this for-loop, check whether the current bounding box can be processed.
if (isActiveBoxes[i])
{
}
If so, add the bounding box to the list of results. If the results exceed the specified limit of boxes to be extracted, break out of the loop. Add the following code inside the if-statement.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Otherwise, look at the adjacent bounding boxes. Add the following code below the box limit check.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Like the first box, if the adjacent box is active or ready to be processed, use the IntersectionOverUnion method to check whether the first box and the second box exceed the specified threshold. Add the following code to your innermost for-loop.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Outside of the inner-most for-loop that checks adjacent bounding boxes, see whether there are any remaining bounding boxes to be processed. If not, break out of the outer for-loop.
if (activeCount <= 0)
break;
Finally, outside of the initial for-loop of the FilterBoundingBoxes method, return the results:
return results;
Great! Now it's time to use this code along with the model for scoring.
Just like with post-processing, there are a few steps in the scoring steps. To help with this, add a class that will contain the scoring logic to your project.
In Solution Explorer, right-click the project, and then select Add > New Item.
In the Add New Item dialog box, select Class and change the Name field to OnnxModelScorer.cs. Then, select Add.
The OnnxModelScorer.cs file opens in the code editor. Add the following using directives to the top of OnnxModelScorer.cs:
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Data;
using ObjectDetection.DataStructures;
using ObjectDetection.YoloParser;
Inside the OnnxModelScorer class definition, add the following variables.
private readonly string imagesFolder;
private readonly string modelLocation;
private readonly MLContext mlContext;
private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();
Directly below that, create a constructor for the OnnxModelScorer class that will initialize the previously defined variables.
public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext)
{
this.imagesFolder = imagesFolder;
this.modelLocation = modelLocation;
this.mlContext = mlContext;
}
Once you have created the constructor, define a couple of structs that contain variables related to the image and model settings. Create a struct called ImageNetSettings to contain the height and width expected as input for the model.
public struct ImageNetSettings
{
public const int imageHeight = 416;
public const int imageWidth = 416;
}
After that, create another struct called TinyYoloModelSettings that contains the names of the input and output layers of the model. To visualize the name of the input and output layers of the model, you can use a tool like Netron.
public struct TinyYoloModelSettings
{
// for checking Tiny yolo2 Model input and output parameter names,
//you can use tools like Netron,
// which is installed by Visual Studio AI Tools
// input tensor name
public const string ModelInput = "image";
// output tensor name
public const string ModelOutput = "grid";
}
Next, create the first set of methods use for scoring. Create the LoadModel method inside of your OnnxModelScorer class.
private ITransformer LoadModel(string modelLocation)
{
}
Inside the LoadModel method, add the following code for logging.
Console.WriteLine("Read model");
Console.WriteLine($"Model location: {modelLocation}");
Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");
ML.NET pipelines need to know the data schema to operate on when the Fit method is called. In this case, a process similar to training will be used. However, because no actual training is happening, it is acceptable to use an empty IDataView. Create a new IDataView for the pipeline from an empty list.
var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());
Below that, define the pipeline. The pipeline will consist of four transforms.
LoadImages loads the image as a Bitmap.ResizeImages rescales the image to the size specified (in this case, 416 x 416).ExtractPixels changes the pixel representation of the image from a Bitmap to a numerical vector.ApplyOnnxModel loads the ONNX model and uses it to score on the data provided.Define your pipeline in the LoadModel method below the data variable.
var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath))
.Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image"))
.Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image"))
.Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));
Now it's time to instantiate the model for scoring. Call the Fit method on the pipeline and return it for further processing.
var model = pipeline.Fit(data);
return model;
Once the model is loaded, it can then be used to make predictions. To facilitate that process, create a method called PredictDataUsingModel below the LoadModel method.
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Inside the PredictDataUsingModel, add the following code for logging.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Then, use the Transform method to score the data.
IDataView scoredData = model.Transform(testData);
Extract the predicted probabilities and return them for additional processing.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Now that both steps are set up, combine them into a single method. Below the PredictDataUsingModel method, add a new method called Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Almost there! Now it's time to put it all to use.
Now that all of the setup is complete, it's time to detect some objects.
Below the creation of the mlContext variable, add a try-catch statement.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
Inside of the try block, start implementing the object detection logic. First, load the data into an IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Then, create an instance of OnnxModelScorer and use it to score the loaded data.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Now it's time for the post-processing step. Create an instance of YoloOutputParser and use it to process the model output.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Once the model output has been processed, it's time to draw the bounding boxes on the images.
After the model has scored the images and the outputs have been processed, the bounding boxes have to be drawn on the image. To do so, add a method called DrawBoundingBox below the GetAbsolutePath method inside of Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
First, load the image and get the height and width dimensions in the DrawBoundingBox method.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Then, create a for-each loop to iterate over each of the bounding boxes detected by the model.
foreach (var box in filteredBoundingBoxes)
{
}
Inside of the for-each loop, get the dimensions of the bounding box.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Because the dimensions of the bounding box correspond to the model input of 416 x 416, scale the bounding box dimensions to match the actual size of the image.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Then, define a template for text that will appear above each bounding box. The text will contain the class of the object inside of the respective bounding box as well as the confidence.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
In order to draw on the image, convert it to a Graphics object.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
Inside the using code block, tune the graphic's Graphics object settings.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Below that, set the font and color options for the text and bounding box.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Create and fill a rectangle above the bounding box to contain the text using the FillRectangle method. This will help contrast the text and improve readability.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Then, Draw the text and bounding box on the image using the DrawString and DrawRectangle methods.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Outside of the for-each loop, add code to save the images in the outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
For additional feedback that the application is making predictions as expected at run time, add a method called LogDetectedObjects below the DrawBoundingBox method in the Program.cs file to output the detected objects to the console.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Now that you have helper methods to create visual feedback from the predictions, add a for-loop to iterate over each of the scored images.
for (var i = 0; i < images.Count(); i++)
{
}
Inside of the for-loop, get the name of the image file and the bounding boxes associated with it.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Below that, use the DrawBoundingBox method to draw the bounding boxes on the image.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Lastly, use the LogDetectedObjects method to output predictions to the console.
LogDetectedObjects(imageFileName, detectedObjects);
After the try-catch statement, add additional logic to indicate the process is done running.
Console.WriteLine("========= End of Process..Hit any Key ========");
That's it!
After following the previous steps, run your console app (Ctrl + F5). Your results should be similar to the following output. You may see warnings or processing messages, but these messages have been removed from the following results for clarity.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
To see the images with bounding boxes, navigate to the assets/images/output/ directory. Below is a sample from one of the processed images.

Congratulations! You've now successfully built a machine learning model for object detection by reusing a pretrained ONNX model in ML.NET.
You can find the source code for this tutorial at the dotnet/machinelearning-samples repository.
In this tutorial, you learned how to:
Check out the Machine Learning samples GitHub repository to explore an expanded object detection sample.
.NET feedback
.NET is an open source project. Select a link to provide feedback:
Events
Mar 17, 9 PM - Mar 21, 10 AM
Join the meetup series to build scalable AI solutions based on real-world use cases with fellow developers and experts.
Register now