Incremental refresh for Power Query and Data Lake Storage data sources
Incremental refresh for data sources based on Power Query (preview) or Azure Data Lake Storage provides the following advantages:
- Faster refreshes - Only data that has changed gets refreshed. For example, you might refresh only the past five days of a historical dataset.
- Increased reliability - With smaller refreshes, you don't need to maintain connections to volatile source systems for as long, reducing the risk of connection issues.
- Reduced resource consumption - Refreshing only a subset of your total data leads to more efficient use of computing resources and decreases the environmental footprint.
Configure incremental refresh for data sources based on Power Query (preview)
[This article is prerelease documentation and is subject to change.]
Configure any Power Query data source in Customer Insights - Data to incrementally refresh data. The data source must have a primary key column that uniquely identifies records and a datetime column that indicates when the data was last updated.
Important
- This is a preview feature.
- Preview features aren't meant for production use and may have restricted functionality. These features are available before an official release so that customers can get early access and provide feedback.
Select a data source that supports incremental refresh, such as Azure SQL database.
Select the tables to ingest.
Complete the transformation steps and select Next.
In the Set up incremental refresh dialog box, select Set up to open the Incremental refresh settings. If you select Skip, the data source refreshes the entire data set.
Tip
You can also apply incremental refresh later by editing an existing data source.
On Incremental refresh settings, configure the incremental refresh for all tables that you selected when creating the data source.
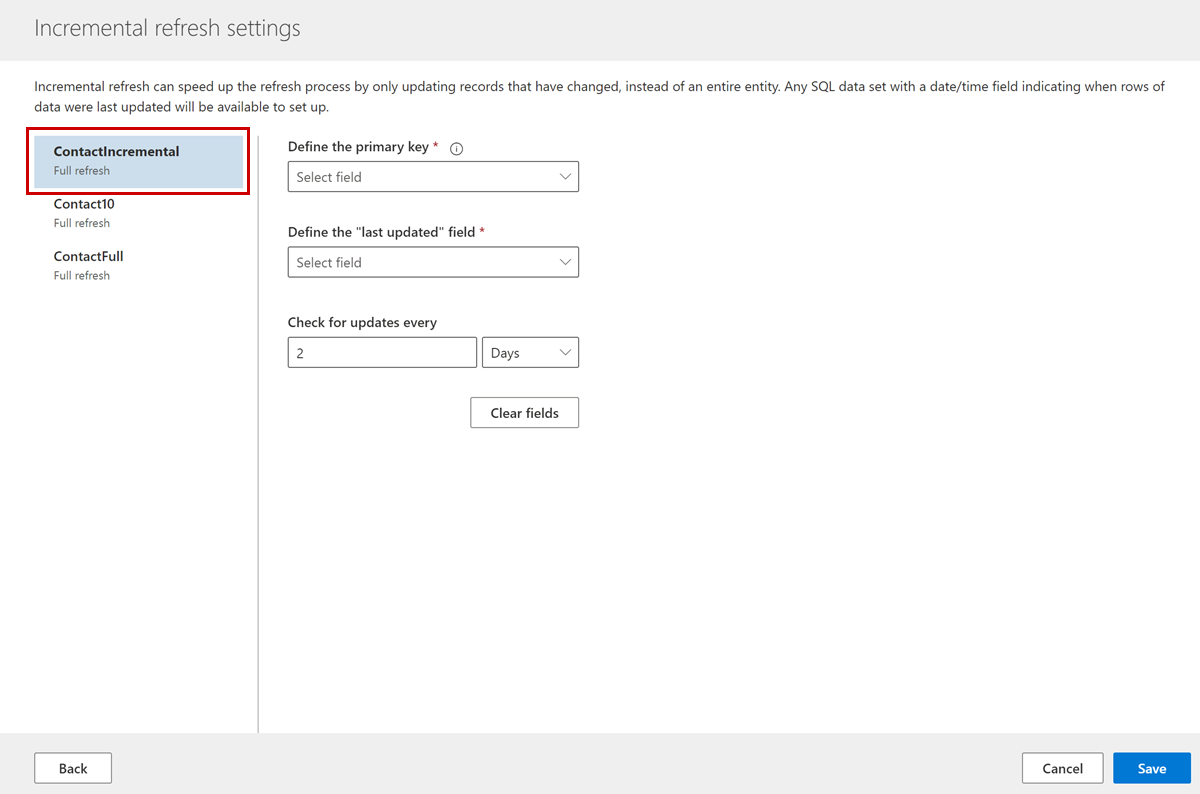
Select a table, and provide the following details:
- Define the primary key: Select a primary key for the table.
- Define the "last updated" field: This field only shows attributes of type date or time. Select an attribute that indicates when the records were last updated. This attribute identifies the records that fall within the incremental refresh time frame.
- Check for updates every: Specify how long you want the incremental refresh time frame to be.
Select Save to complete the creation of the data source. The initial data refresh is a full refresh. Afterwards, the incremental data refresh happens as configured in the previous step.
Configure incremental refresh for Azure Data Lake Storage data sources
Microsoft recommends the Delta Lake format to obtain the best performance and results for working with large data sets. Customer Insights - Data provides a connector that is optimized for Delta Lake formatted data. Internal processes such as unification are optimized to incrementally process only the changed data, resulting in shorter processing times.
To use incremental ingestion and refresh for a Data Lake table, configure that table when adding or editing the Azure Data Lake data source. The table data folder must contain the following folders:
- FullData: Folder with data files containing initial records
- IncrementalData: Folder with date/time hierarchy folders in yyyy/mm/dd/hh format containing the incremental updates. Year, month, day, and hour folders are expected to be four and two digits respectively. hh represents the UTC hour of the updates and contains the Upserts and Deletes folders. Upserts contains data files with updates to existing records or new records. Deletes contains data files with records to remove.
Order of processing incremental data
The system processes the files in the IncrementalData folder after the specified UTC hour ends. For example, if the system starts processing the incremental refresh on January 21, 2023 at 8:15 AM, all files that are in folder 2023/01/21/07 (representing data files stored from 7 AM to 8 AM) are processed. Any files in folder 2023/01/21/08 (representing the current hour where the files are still being generated) aren't processed until the next run.
If there are two records for a primary key, an upsert and delete, Customer Insights - Data uses the record with the latest modified date. For example, if the delete timestamp is 2023-01-21T08:00:00 and the upsert timestamp is 2023-01-21T08:30:00, it uses the upsert record. If the deletion occurred after the upsert, the system assumes the record is deleted.
Configure the incremental refresh for Azure Data Lake data sources
When adding or editing a data source, navigate to the Attributes pane for the table.
Review the attributes. Make sure a created or last updated date attribute is set up with a dateTime Data format and a Calendar.Date Semantic type. Edit the attribute if necessary and select Done.
From the Select Tables pane, edit the table. The Incremental ingestion checkbox is selected.

- Browse to the root folder that contains the .csv or .parquet files for full data, incremental data upserts, and incremental data deletes.
- Enter the extension for the full data and both incremental files (.csv or .parquet).
- For .csv files, select the column delimiter and if you want the first row of the file as a column header.
- Select Save.
For Last updated, select the date timestamp attribute.
If the Primary key isn't selected, select the primary key. The primary key is an attribute unique to the table. For an attribute to be a valid primary key, it shouldn't include duplicate values, missing values, or null values. String, integer, and GUID data type attributes are supported as primary keys.
Select Close to save and close the pane.
Continue with adding or editing the data source.
Run a one-time full refresh for Azure Data Lake data sources
After you configure an incremental refresh for Azure Data Lake data sources, there are times when data needs to be processed with a full refresh. The full data folder set up for the incremental refresh must contain the location of the full data.
When editing the data source, navigate to the Select tables pane and edit the table you want to refresh.
On the Edit table pane, scroll to the Run one-time full refresh checkbox and select it.

For Process incremental files from, specify the date and time to retain the incremental files. Full data plus the incremental data starts processing after the specified date and time. For example, if you want to perform a partial data refresh/backfill until the end of November while retaining the incremental data from the beginning of December to today (Dec 30), enter December 1. To replace all the data and ignore the data in the incremental folder, specify a future date.
Select Close to save and close the pane.
Select Save to apply your changes and return to the Data sources page. The data source is in Refreshing status, performing a full refresh.