Data management and integration by using data entities overview
This article provides a brief overview of the mechanics of synchronous and asynchronous integration.
Synchronous services
Synchronous integrations are relatively straightforward. Any entity that has Is public enabled is automatically available as a service application programming interface (API) in the following URL: https://[BaseURL]/Data/<<Data Entity Public Collection Name>>.
Currently, OData protocol is used to expose endpoints where all public-enabled entities can be interacted with.
Supported protocol: OData V4.0
Data format: JSON
Metadata URL: https://[BaseURL]/Data/$metadata
Data import/export and recurring integration scenarios
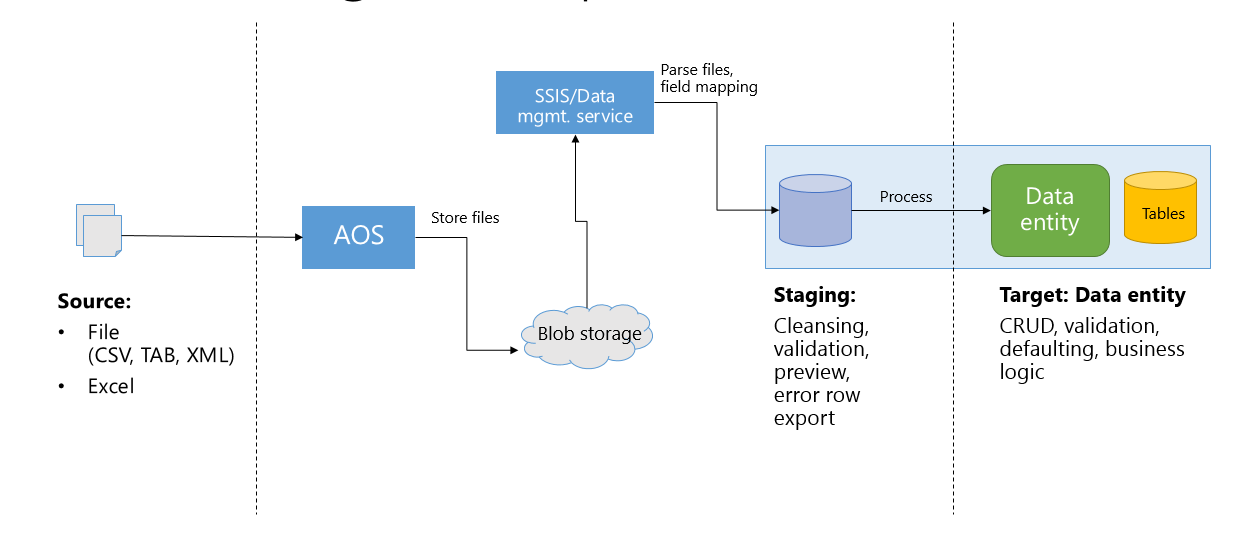
Integration through the data management platform provides more capabilities and higher throughput for inserting/extracting data through entities. Typically, data goes through three phases in this integration scenario:
- Source – These are inbound data files or messages in the queue. Typical data formats include CSV, XML, and tab-delimited.
- Staging – These are automatically generated tables that map closely to the data entity. When Data management enabled is true, staging tables are generated to provide intermediary storage. This enables the framework to do high-volume file parsing, transformation, and some validations.
- Target – This is the data entity where data will be imported.
The following diagram shows an inbound flow.
Known limitations in data import/export
When you import text files, string sizes are limited to 32,768 characters. If there is a string larger than this, the imported string will be truncated. This is a limitation in the underlying implementation and is due to SQL Server Integration Services (SSIS).
If you need to import strings that are larger than 32,768 characters, we suggest that you use container entity fields.
For more information, watch the FastTrack Tech Talk video: Dynamics 365 for Operations – Tech Talk: Integration.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for