Understanding Multicore Scaling on NUMA Hardware with IIS 8
by Kaori Sawada
Non-uniform memory access (NUMA) is a modern design for computer memory access, which was designed to overcome the scalability limits of the Symmetric Multi-Processor (SMP) architecture. In SMP, each core accesses its own bus and its own I/O hub. SMP doesn't work well with a large number of CPUs (or CPU cores) because they become competitive for access to the shared bus.
NUMA was designed to alleviate such bottlenecks by limiting how many CPUs could be on any one memory bus and connecting them with a high-speed interconnection. To utilize these capabilities, IIS 8 (which is part of Windows Server 2012) and above offers features to enhance performance on NUMA hardware. This enables IIS to intelligently affinitize worker processes to NUMA nodes and provide better utilization of the CPUs.
New NUMA related options in IIS 8
To provide the administrator with a high degree of control, IIS 8 has the following four new features/options that come into play on servers that support NUMA hardware:
- Processor Affinity
- Affinity Mode
- Optimal NUMA selection
- Web Gardens
Processor Affinity
Processor affinity is not a new feature, but it has been enhanced in IIS 8. The smpProcessorAffinityMask and smpProcessorAffinityMask2 attributes have been available since IIS 7, and allow the administrator to affinitize an Application Pool to a specific core. Their purpose remains the same with IIS 8, but the following new schema elements have been introduced in IIS 8 to support more than 64 logical processors (LPs):
<element name="cpu">
...
<attribute name="smpAffinitized" type="bool" defaultValue="false"/>
<attribute name="smpProcessorAffinityMask" type="uint" defaultValue="4294967295"/>
<attribute name="smpProcessorAffinityMask2" type="uint" defaultValue="4294967295"/>
<attribute name="processorGroup" type="int" defaultValue="0" validationType="integerRange"
validationParameter="0,2147483647"/>
...
</element>
* Changes for IIS 8 are highlighted
Note
To support more than 64 LPs, a new concept was introduced: processor group. Any machine with more than 64 LPs has more than one processor group by necessity. A single processor group is a static set of LPs and is treated as a single scheduling entity. When the operating system starts, it creates the processor groups and assigns logical processors to them. Processor groups are numbered starting with 0.
Since smpProcessorAffinityMask and smpProcessorAffinityMask2 offer 64bits (32 each), the processorGroup attribute can be used to affinitize Application Pools on a system with up-to 64 cores. The two Affinity Masks are used to configure the decimal processor mask, and the decimal processor mask indicates to which CPU the worker processes in an application pool should be bound. For example, if you have a computer with 64 processors and you want to enable the 8th, 15th, 26st, 32th, 40th, 48th, and 60th processors, you would calculate the hexadecimal processor mask as follows.
Processor identification starts at 0, from right to left, so in binary, you would identify processors 8, 15, 26, and 32 for the first 32 processors as:
1000 0010 0000 0000 0100 0000 1000 0000
This number, converted to decimal, is your smpProcessorAffinityMask:
0x82004080
You would also identify processors 40, 48, and 60 for the second set of 32 processors as:
0000 1000 0000 0000 1000 0000 1000 0000
This number, converted to decimal, is your smpProcessorAffinityMask2:
0x8008080
Since the type of these two Affinity Masks is uint, which is Unsigned 32-bit integer, they offer 64 addressable bits in total allowing you to specify up to 64 processors. To support affinitizing the Application Pool to more than 1 processor group or there are more than 64 processors, a processorGroup attribute represents for these situations. If you refer to a processorGroup numbered 0, the corresponding AffinityMask values apply to the first group, which is numbered 0 to 63. If you refer to processorGroup 1, then the mask values apply to the second one, which is numbered 64 to 127. You can specify only one processor group to affnityze the Application Pool to LPs. The below example shows that the mask values apply to only the second processor group, which is group 1. Any worker process in this Application Pool never run on LPs in the first processor group, which is group 0.
The below is the example to configure to of the applicationHost.config.
<applicationPools>
<add name="DefaultAppPool">
<cpu smpAffinitized="true" smpProcessorAffinityMask="82004080"
smpProcessorAffinityMask2="8008080" processorGroup="1" />
</add>
</appricationPools>
Note
You can configure more than 2 processor group even when there is a fewer processors than 64 LPs.
https://msdn.microsoft.com/library/ff542298(VS.85).aspx
In this scenario, some bits of smpProcessorAffinityMask and smpProcessorAffinityMask2 attributes will be ignored.
The below image shows how you can configure the mask in the application pool advanced configuration dialog.
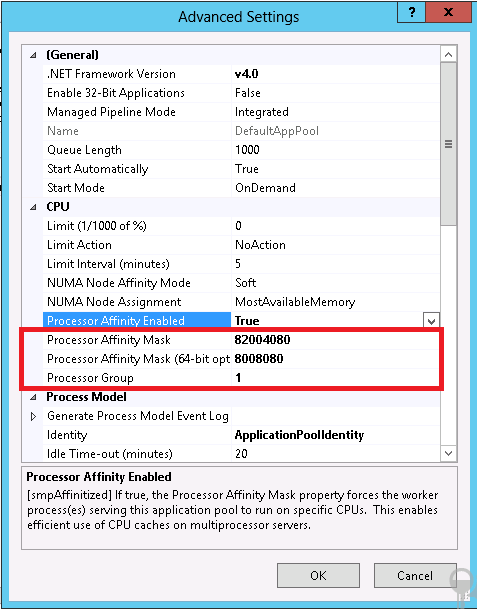
When this configuration is used, the ApplicationPools are hard affinitized, meaning there is no impact on other NUMA nodes. In testing, it has been shown that hard affinity offers higher throughput than soft affinity as measured in Requests per Second (RPS).
Note
The processorGroup is honored only when it is used with AffinityMasks to manually affinitize a process to a core..
Affinity MODE
When it comes to affinitizing a process to a core or NUMA node, two affinity modes are possible:
- Hard Affinity. A process is affinitized to a core (or cores that make up a NUMA node) and all threads for the process are executed by the affinitized core. The threads cannot be executed by the other cores on the system, regardless of whether the other cores have extra CPU cycles or not. The threads are contained within the affinitized core.
- Soft Affinity. A process is affinitized to a core (or cores that make up a NUMA node) as the "preferred core". When a thread is about to be scheduled to be executed, the "preferred core" is considered first, however, depending on the load and the availability of the other cores on the system, the thread maybe scheduled on the other cores on the system. This behavior is often described as a "spill over" effect, in which the threads are "spilling over" to the other non-soft-affinitized cores.
The following new schema element has been introduced in IIS 8 for configuring the affinity modes:
<element name="cpu">
...
<attribute name="numaNodeAffinityMode" type="enum" defaultValue="Soft">
<enum name="Soft" value="0" />
<enum name="Hard" value="1" />
</attribute>
</element>
The administrator can also configure the numaNodeAffinityMode attribute using the Internet Service Manager.

By default, Application Pools are soft affinitized because it is a more "forgiving" configuration for the majority of scenarios. If you are advanced enough to be able to intelligently configure the smpProcessorAffinityMask and smpProcessorAffinityMask2 attributes, then configuring the hard/soft affinity in accord with the system’s node layout can improve performance.
Optimal NUMA selection
By default, Windows assigns each process to the next NUMA node in the system using a simple "round-robin" algorithm. This ensures that the threads for any given process run within the same NUMA node by default wherever possible. However, IIS 8 enables another scheduling algorithm to minimize access to memory on remote NUMA nodes. Optimal NUMA selection refers to a functionality in which IIS 8 selects a NUMA node that should furnish better performance for a worker process that is about to be instantiated. There are two options in IIS 8 for this configuration:
MostAvailableMemory. The scheduling algorithm for worker processes started by WAS which will schedule the process on the node with the most available memory. This helps in minimizing access to memory on a remote NUMA node. The first worker process is selected based on which NUMA node has the most available (free) memory. The rest of the worker processes are affinitized in a round-robin fashion.
Note
The numaNodeAffinityMode attribute is applicable only with MostAvailableMemory.
WindowsScheduling. The operating system, by default, assigns each process to the next NUMA node in the system using a "round-robin" algorithm on a NUMA system. The worker processes are spread out evenly because Windows chooses the NUMA node based on this "round-robin" algorithm and soft affinitizes the processes to NUMA nodes.
Note
The numaNodeAffinityMode attribute is not applicable with WindowsScheduling because this is not an IIS implementation but Windows implementation as itself.
Configuring these options are done using new schema options:
<element name="cpu">
...
<attribute name="numaNodeAssignment" type="enum" defaultValue="MostAvailableMemory">
<enum name="MostAvailableMemory" value="0"/>
<enum name="WindowsScheduling" value="1"/>
</attribute >
...
</element>
The administrator can configure the numaNodeAssignment attribute using the Internet Service Manager as well.
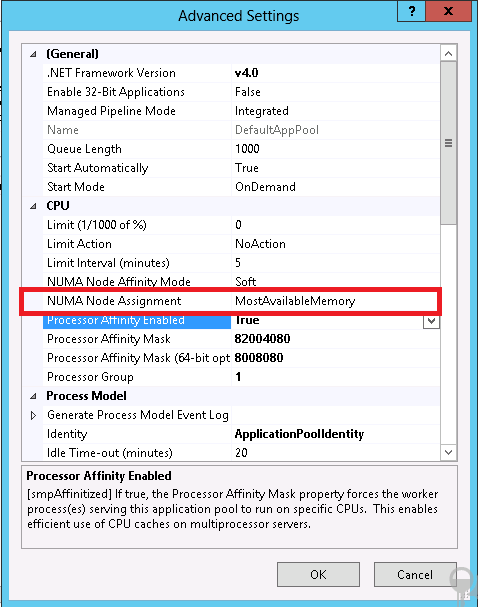
How this works?
Consider a configuration in which there are 8 NUMA nodes, and a web garden of 4 processes. If the numaNodeAssignment attributes is set to MostAvailableMemory and NUMA Node 2 is chosen as the optimal NUMA node for the first of the 4 processes and is affinitized to, the subsequent ones will be affinitized to NUMA Node 3, Node 4, and Node 5 in sequence:
| NUMA0 | NUMA1 | NUMA2 | NUMA3 | NUMA4 | NUMA5 | NUMA6 | NUMA7 |
|---|---|---|---|---|---|---|---|
| IIS w3wp | IIS w3wp | IIS w3wp | IIS w3wp |
Similarly, if NUMA Node 6 is chosen for the first of the 4 processes, the subsequent ones will be affinitized to NUMA Node 7, 0, and 1 in sequence:
| NUMA0 | NUMA1 | NUMA2 | NUMA3 | NUMA4 | NUMA5 | NUMA6 | NUMA7 |
|---|---|---|---|---|---|---|---|
| IIS w3wp | IIS w3wp | IIS w3wp | IIS w3wp |
Web Gardens
Web garden behavior on IIS 8 and later has changed a little as well. On IIS 7.5 (which shipped with Windows Server 2008 R2), the value for maxProcesses attribute started from 1, and with IIS 8, this value now starts at 0 (although the default value is still 1!). This is how it looks in the schema:
<element name="processModel">
...
<attribute name="maxProcesses" type="uint" defaultValue="1" validationType="integerRange"
validationParameter="0,2147483647" />
...
</element>
Naturally, this is also configurable with the GUI:
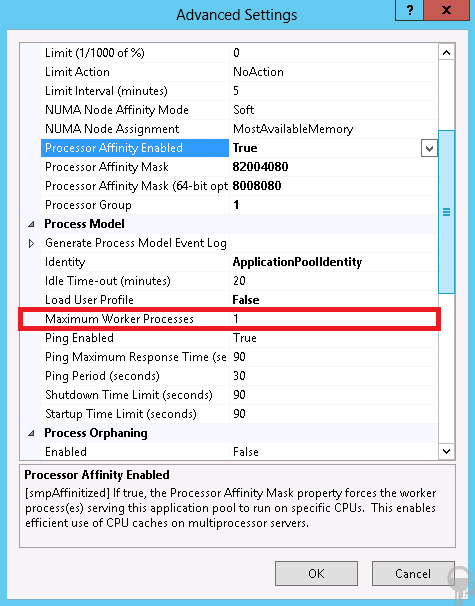
When this configuration is set to 0 on non-NUMA hardware, the default value of 1 is used. When it is set to 0 on NUMA hardware, IIS will launch as many worker processes as there are NUMA nodes on the system so that there is a 1:1 affinity between the worker processes and NUMA nodes. On such systems, you should set the maxProcesses value to 0 to achieve maximum performance.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for