Learn about trainable classifiers
Categorizing and labeling content so it can be protected and handled properly is the starting place for the information protection discipline. Microsoft Purview has three ways to classify content.
Tip
If you're not an E5 customer, use the 90-day Microsoft Purview solutions trial to explore how additional Purview capabilities can help your organization manage data security and compliance needs. Start now at the Microsoft Purview compliance portal trials hub. Learn details about signing up and trial terms.
Manually
Manual categorizing requires human judgment and action. Users and admins categorize content as they encounter it. You can use either use the pre-existing labels and sensitive information types or use custom created ones. You can then protect the content and manage its disposition.
Automated pattern-matching
These categorization mechanisms include finding content by:
- Keywords or metadata values (keyword query language).
- Using previously identified patterns of sensitive information like social security, credit card, or bank account numbers (Sensitive information type entity definitions).
- Recognizing an item because it's a variation on a template (document finger printing).
- Using the presence of exact strings exact data match.
Sensitivity and retention labels can then be automatically applied to make the content available for use in Learn about Microsoft Purview Data Loss Prevention and auto-apply polices for retention labels.
Classifiers
This categorization method is well suited to content that isn't easily identified by either the manual or automated pattern-matching methods. This method of categorization is more about using a classifier to identify an item based on what the item is, not by elements that are in the item (pattern matching). A classifier learns how to identify a type of content by looking at hundreds of examples of the content you're interested in identifying.
Note
In Preview - You can view the trainable classifiers in content explorer by expanding Trainable Classifiers in the filters panel. The trainable classifiers will automatically display the number of incidents found in SharePoint, Teams, and OneDrive, without requiring any labeling. If you don't want to use this feature, you must file a request with Microsoft Support. This will disable the display of your sensitive data that's not used in any labeling policies within Content Explorer. You can disable scanning of your data as well. If scanning is turned off, sensitivity labeling and DLP policies with those classifiers will not work
Where you can use classifiers
Classifiers are available to use as a condition for:
- Office auto-labeling with sensitivity labels
- Auto-apply retention label policy based on a condition
- Communication compliance
- Sensitivity labels can use classifiers as conditions, see Apply a sensitivity label to content automatically.
- Data loss prevention
Important
Classifiers only work with items that are not encrypted.
Types of classifiers
- pre-trained classifiers - Microsoft has created and pre-trained multiple classifiers that you can start using without training them. These classifiers will appear with the status of
Ready to use. - custom trainable classifiers - If you have content identification and categorization needs that extend beyond what the pre-trained classifiers cover, you can create and train your own classifiers.
See, Trainable classifiers definitions for a complete list of all pre-trained classifiers.
Custom classifiers
When the pre-trained classifiers don't meet your needs, you can create and train your own classifiers. There's more work involved with creating your own, but they'll be much better tailored to your organizations needs.
You start creating a custom trainable classifier by feeding it examples that are definitely in the category. Once it processes those examples, you test it by giving it a mix of both matching and non-matching examples. The classifier then makes predictions as to whether any given item falls into the category you're building. You then confirm its results, sorting out the true positives, true negatives, false positives, and false negatives to help increase the accuracy of its predictions.
When you publish the classifier, it sorts through items in locations like SharePoint Online, Exchange, and OneDrive, and classifies the content. After you publish the classifier, you can continue to train it using a feedback process that is similar to the initial training process.
For example you could create trainable classifiers for:
- Legal documents - such as attorney client privilege, closing sets, statement of work
- Strategic business documents - like press releases, merger and acquisition, deals, business or marketing plans, intellectual property, patents, design docs
- Pricing information - like invoices, price quotes, work orders, bidding documents
- Financial information - such as organizational investments, quarterly or annual results
Process flow for creating custom classifiers
Creating and publishing a classifier for use in compliance solutions, such as retention policies and communication supervision, follows this flow. For more detail on creating a custom trainable classifier see, Creating a custom classifier.
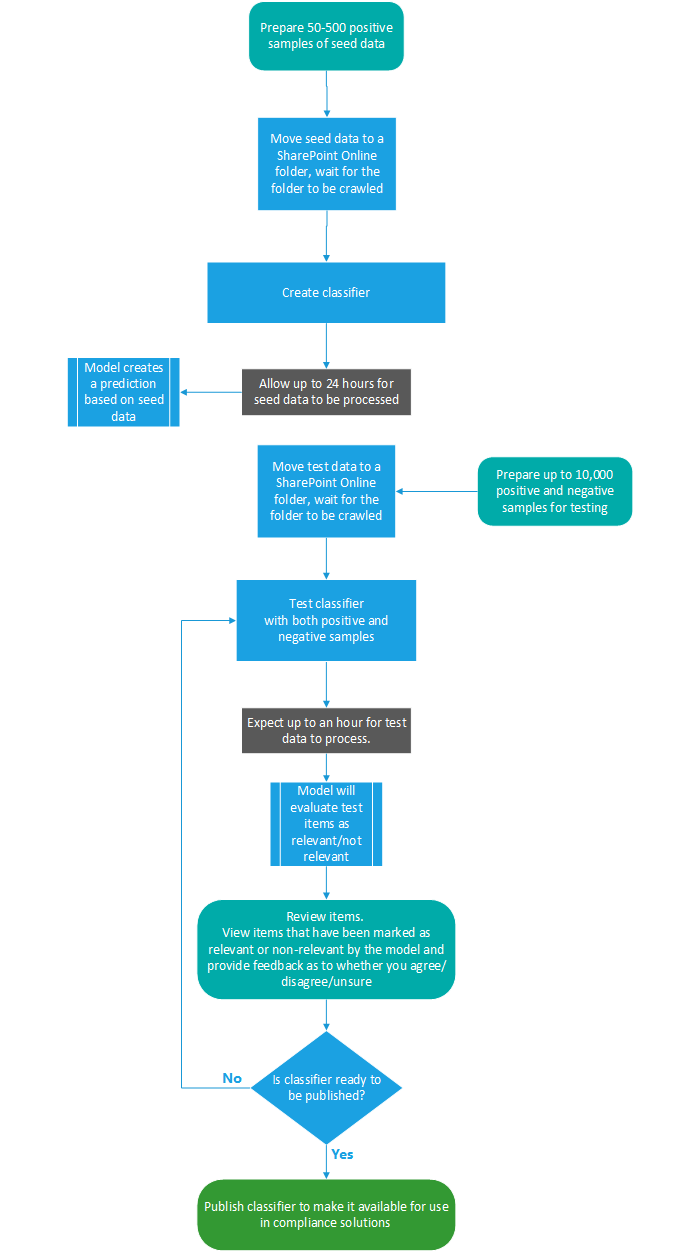
Retraining classifiers
You can help improve the accuracy of all custom trainable classifiers and by providing them with feedback on the accuracy of the classification that they perform. This is called retraining, and follows this workflow.
Note
Pre-trained classifiers cannot be re-trained.

Provide match/not a match accuracy feedback in trainable classifiers
You can view the number of matches a trainable classifier has in Content explorer and Trainable classifiers. You can also provide feedback on whether an item is actually a match or not using the Match, Not a Match feedback mechanism and use that feedback to tune your classifiers. See, Increase classifier accuracy for more information.
See also
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for