Text/CSV
Summary
| Item | Description |
|---|---|
| Release State | General Availability |
| Products | Excel Power BI (Semantic models) Power BI (Dataflows) Fabric (Dataflow Gen2) Power Apps (Dataflows) Dynamics 365 Customer Insights Analysis Services |
| Function Reference Documentation | File.Contents Lines.FromBinary Csv.Document |
Note
Some capabilities may be present in one product but not others due to deployment schedules and host-specific capabilities.
Capabilities supported
- Import
Connect to local text/CSV file from Power Query Desktop
To load a local text or CSV file:
Select the Text/CSV option in Get Data. This action launches a local file browser where you can select your text file.
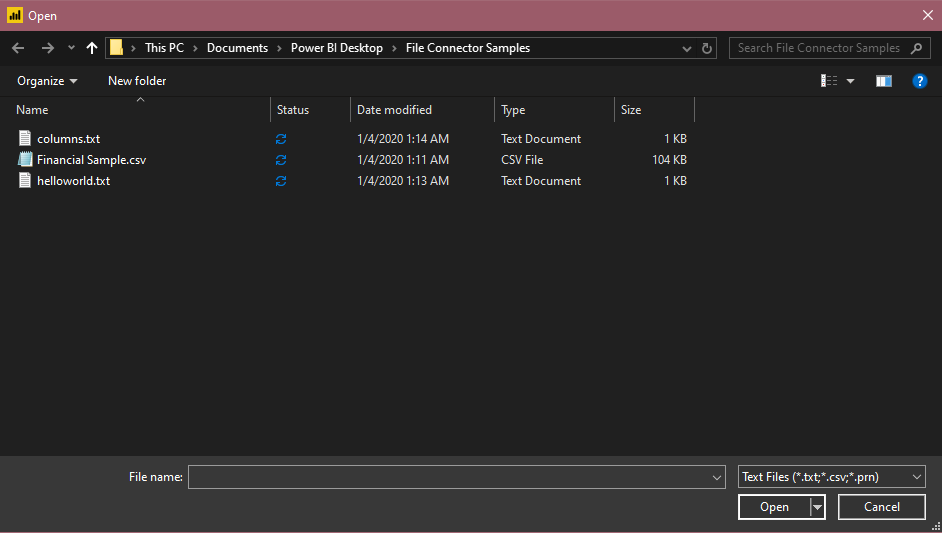
Select Open to open the file.
From the Navigator, you can either transform the data in the Power Query Editor by selecting Transform Data, or load the data by selecting Load.
Connect to text/CSV file from Power Query Online
To load a local text or CSV file:
From the Data sources page, select Text/CSV.
In Connection settings, enter a file path to the local text or CSV file you want.
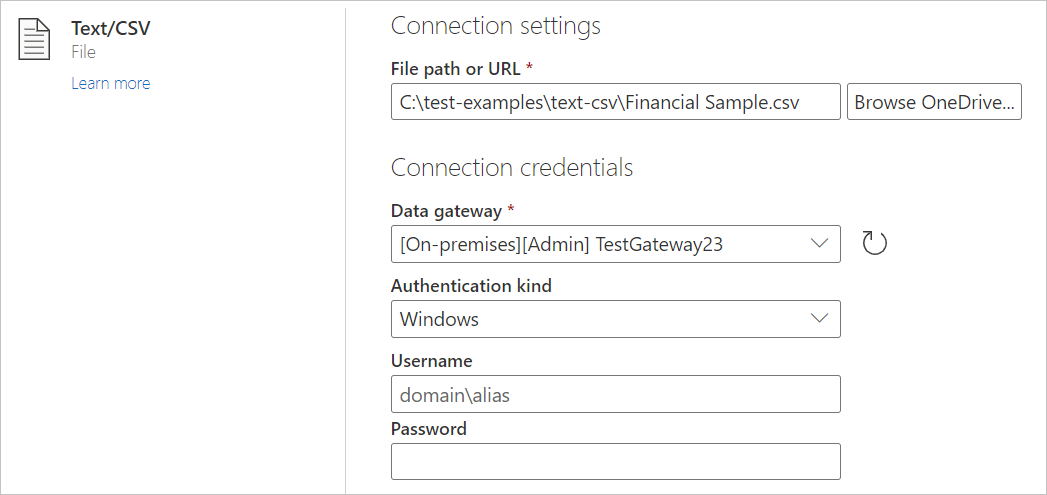
Select an on-premises data gateway from Data gateway.
Enter a username and password.
Select Next.
From the Navigator, select Transform Data to begin transforming the data in the Power Query Editor.

Load from the web
To load a text or CSV file from the web, select the Web connector, enter the web address of the file, and follow any credential prompts.
Text/CSV delimiters
Power Query will treat CSVs as structured files with a comma as a delimiter—a special case of a text file. If you choose a text file, Power Query will automatically attempt to determine if it has delimiter separated values, and what that delimiter is. If it can infer a delimiter, it will automatically treat it as a structured data source.
Unstructured Text
If your text file doesn't have structure, you'll get a single column with a new row per line encoded in the source text. As a sample for unstructured text, you can consider a notepad file with the following contents:
Hello world.
This is sample data.
When you load it, you're presented with a navigation screen that loads each of these lines into their own row.
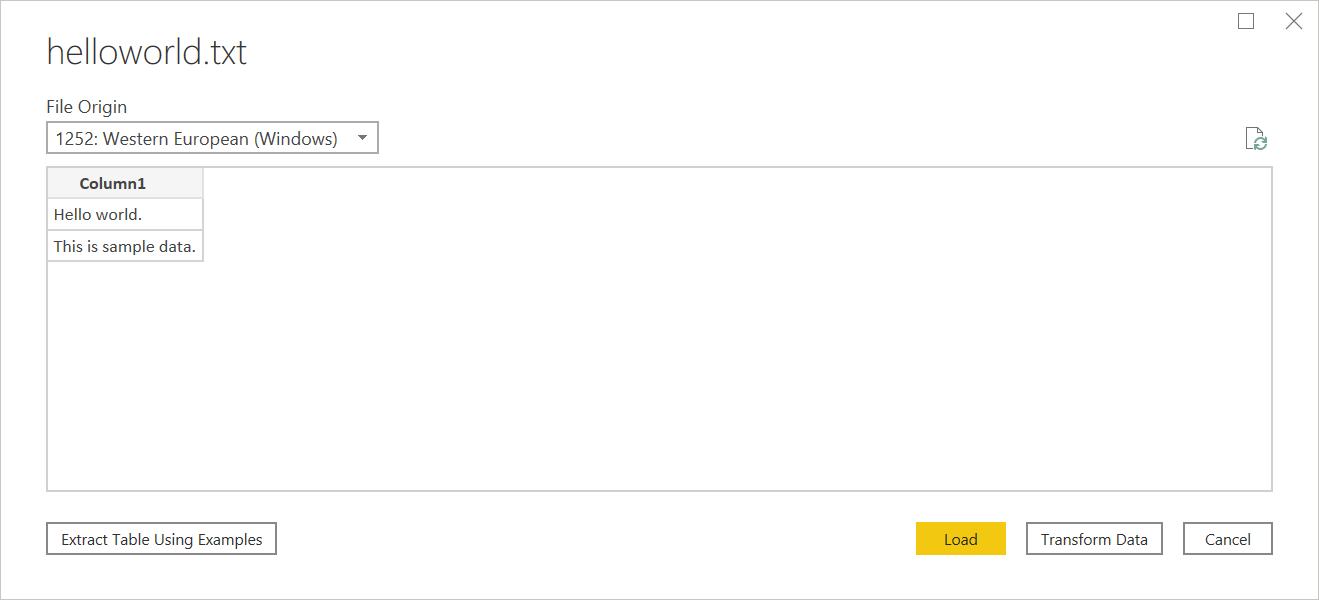
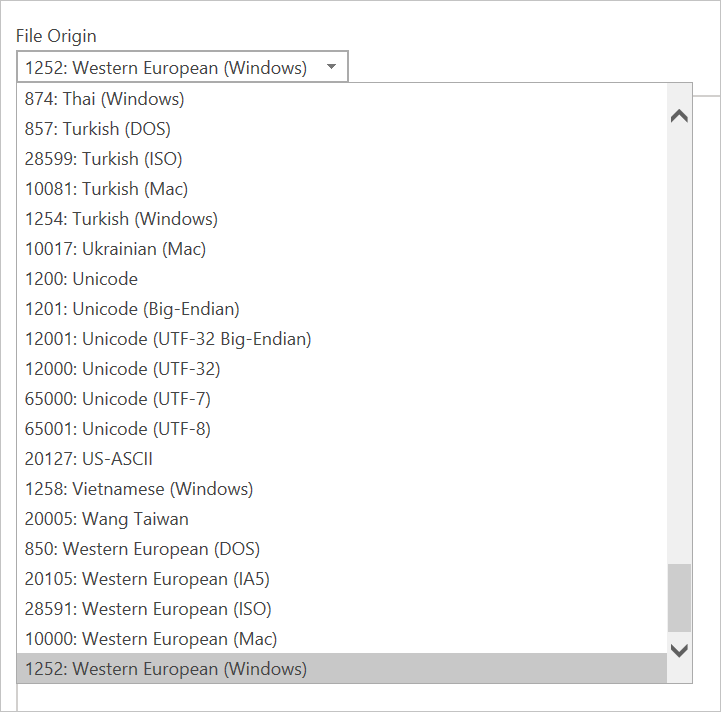
There's only one thing you can configure on this dialog, which is the File Origin dropdown select. This dropdown lets you select which character set was used to generate the file. Currently, character set isn't inferred, and UTF-8 will only be inferred if it starts with a UTF-8 BOM.
CSV
You can find a sample CSV file here.
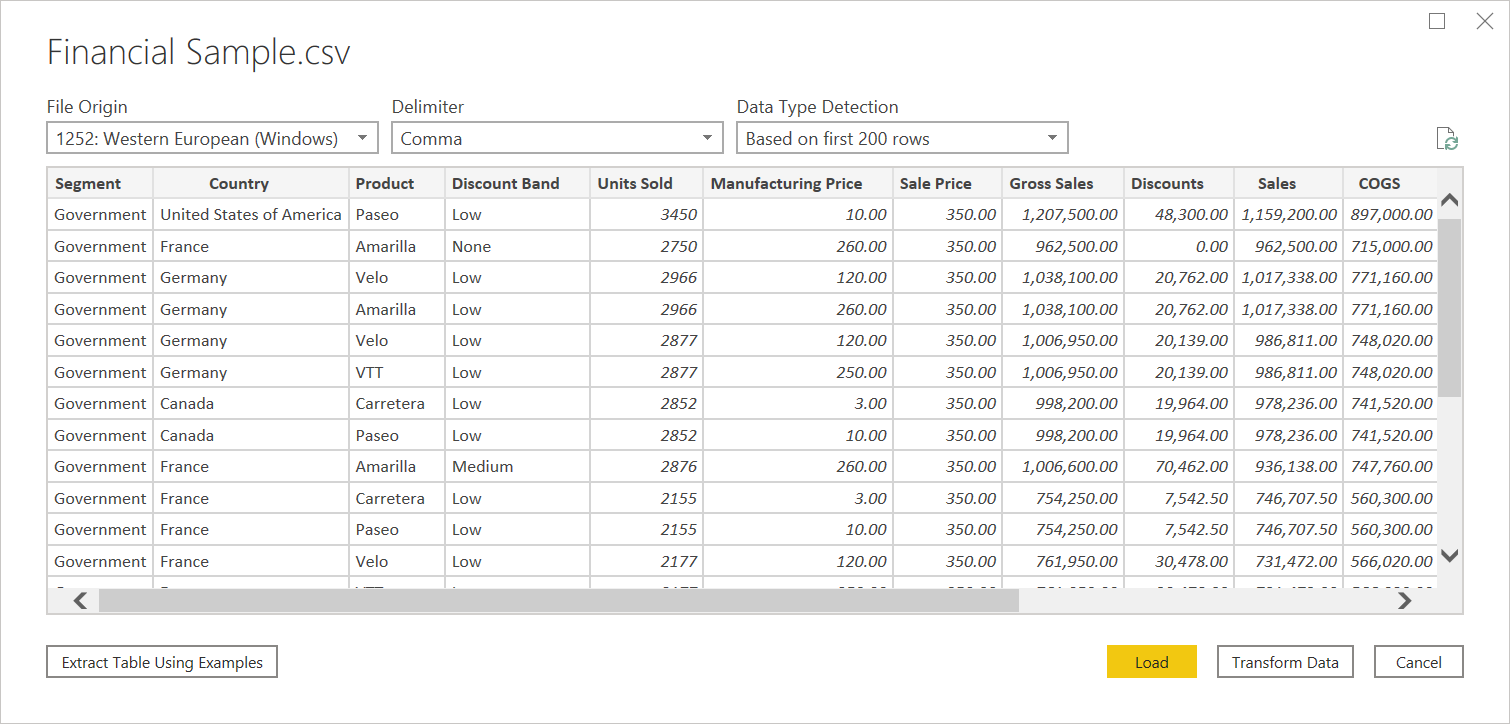
In addition to file origin, CSV also supports specifying the delimiter and how data type detection will be handled.
Delimiters available include colon, comma, equals sign, semicolon, space, tab, a custom delimiter (which can be any string), and a fixed width (splitting up text by some standard number of characters).
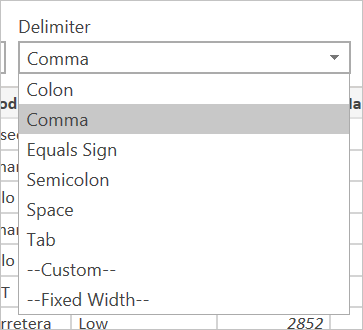
The final dropdown allows you to select how you want to handle data type detection. It can be done based on the first 200 rows, on the entire data set, or you can choose to not do automatic data type detection and instead let all columns default to 'Text'. Warning: if you do it on the entire data set it may cause the initial load of the data in the editor to be slower.

Since inference can be incorrect, it's worth double checking settings before loading.
Structured Text
When Power Query can detect structure to your text file, it will treat the text file as a delimiter separated value file, and give you the same options available when opening a CSV—which is essentially just a file with an extension indicating the delimiter type.
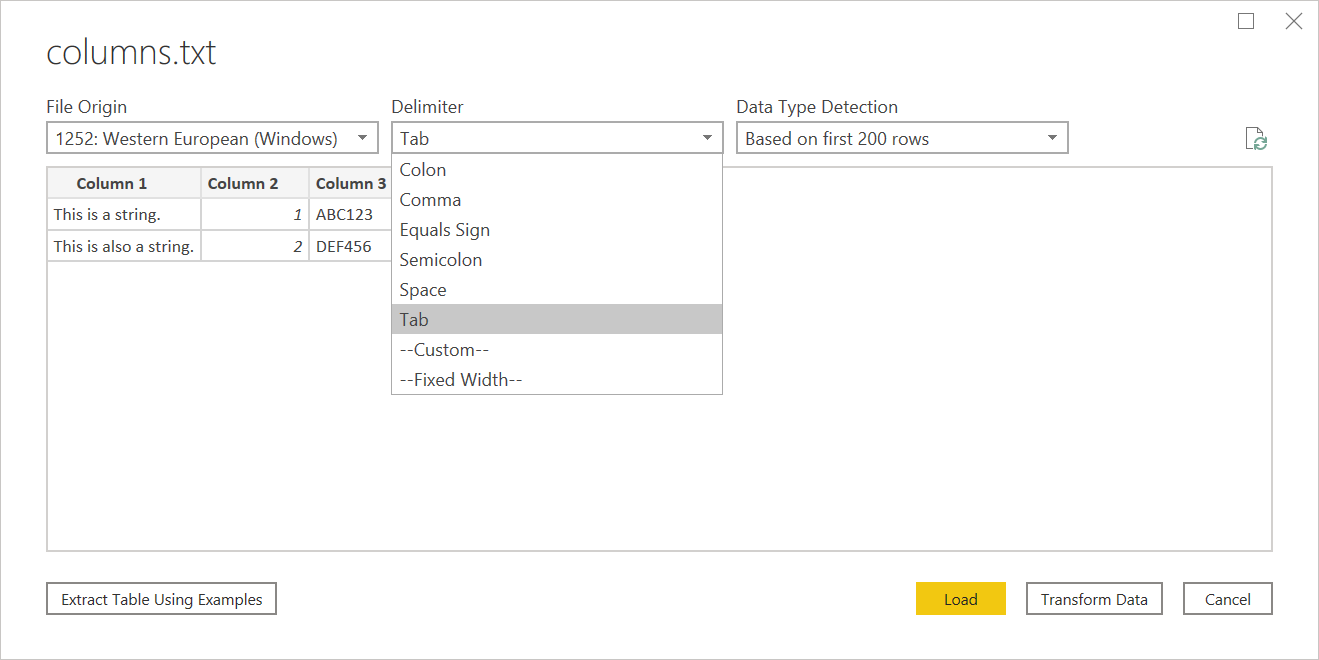
For example, if you save the following example as a text file, it will be read as having a tab delimiter rather than unstructured text.
Column 1 Column 2 Column 3
This is a string. 1 ABC123
This is also a string. 2 DEF456
This can be used for any kind of other delimiter-based file.
Editing Source
When editing the source step, you'll be presented with a slightly different dialog than when initially loading. Depending on what you are currently treating the file as (that is, text or csv) you'll be presented with a screen with a variety of dropdowns.
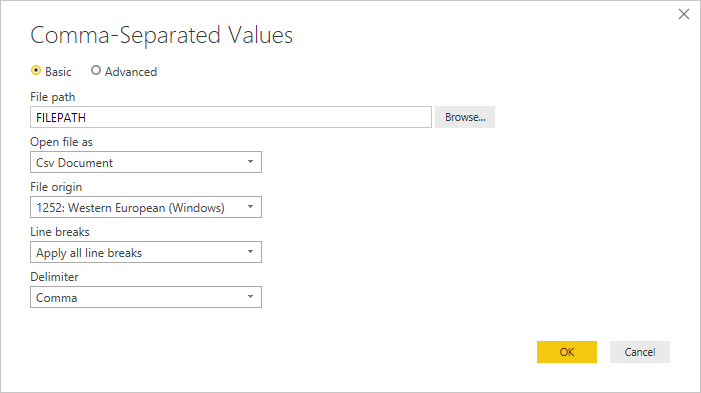
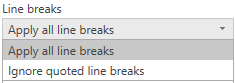
The Line breaks dropdown will allow you to select if you want to apply line breaks that are inside quotes or not.
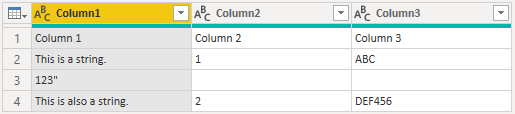
For example, if you edit the 'structured' sample provided above, you can add a line break.
Column 1 Column 2 Column 3
This is a string. 1 "ABC
123"
This is also a string. 2 "DEF456"
If Line breaks is set to Ignore quoted line breaks, it will load as if there was no line break (with an extra space).

If Line breaks is set to Apply all line breaks, it will load an extra row, with the content after the line breaks being the only content in that row (exact output may depend on structure of the file contents).
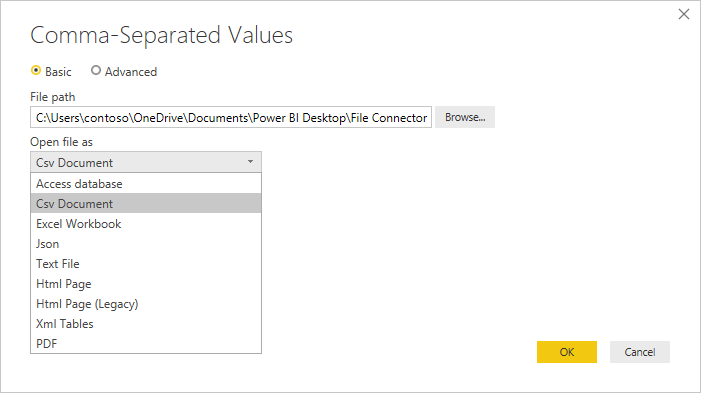
The Open file as dropdown will let you edit what you want to load the file as—important for troubleshooting. For structured files that aren't technically CSVs (such as a tab separated value file saved as a text file), you should still have Open file as set to CSV. This setting also determines which dropdowns are available in the rest of the dialog.
Text/CSV by Example
Text/CSV By Example in Power Query is a generally available feature in Power BI Desktop and Power Query Online. When you use the Text/CSV connector, you'll see an option to Extract Table Using Examples on the bottom-left corner of the navigator.
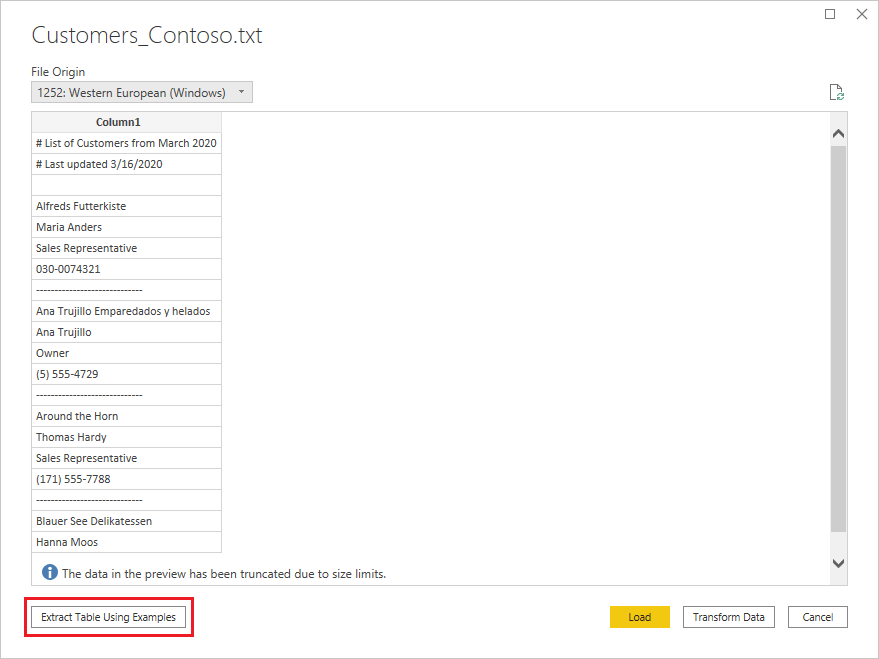
When you select that button, you’ll be taken into the Extract Table Using Examples page. On this page, you specify sample output values for the data you’d like to extract from your Text/CSV file. After you enter the first cell of the column, other cells in the column are filled out. For the data to be extracted correctly, you may need to enter more than one cell in the column. If some cells in the column are incorrect, you can fix the first incorrect cell and the data will be extracted again. Check the data in the first few cells to ensure that the data has been extracted successfully.
Note
We recommend that you enter the examples in column order. Once the column has successfully been filled out, create a new column and begin entering examples in the new column.
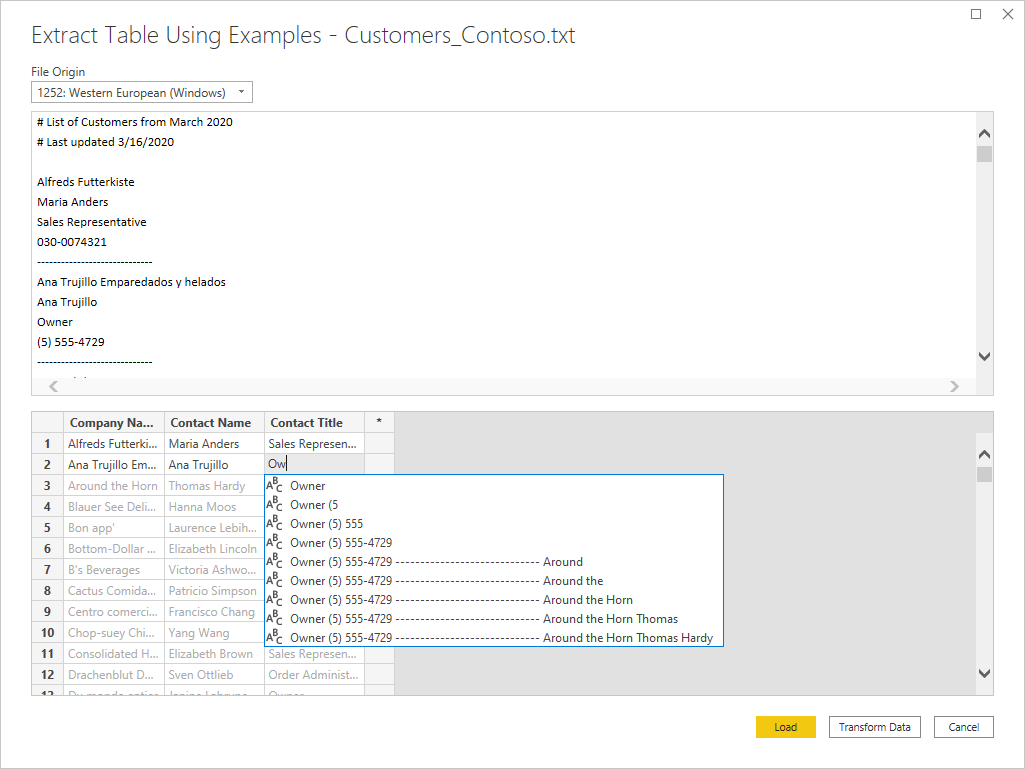
Once you’re done constructing that table, you can either select to load or transform the data. Notice how the resulting queries contain a detailed breakdown of all the steps that were inferred for the data extraction. These steps are just regular query steps that you can customize as needed.

Troubleshooting
Loading Files from the Web
If you're requesting text/csv files from the web and also promoting headers, and you’re retrieving enough files that you need to be concerned with potential throttling, you should consider wrapping your Web.Contents call with Binary.Buffer(). In this case, buffering the file before promoting headers will cause the file to only be requested once.
Working with large CSV files
If you're dealing with large CSV files in the Power Query Online editor, you might receive an Internal Error. We suggest you work with a smaller sized CSV file first, apply the steps in the editor, and once you're done, change the path to the bigger CSV file. This method lets you work more efficiently and reduces your chances of encountering a timeout in the online editor. We don't expect you to encounter this error during refresh time, as we allow for a longer timeout duration.
Unstructured text being interpreted as structured
In rare cases, a document that has similar comma numbers across paragraphs might be interpreted to be a CSV. If this issue happens, edit the Source step in the Power Query editor, and select Text instead of CSV in the Open File As dropdown select.
Columns in Power BI Desktop
When you import a CSV file, Power BI Desktop generates a columns=x (where x is the number of columns in the CSV file during initial import) as a step in Power Query Editor. If you subsequently add more columns and the data source is set to refresh, any columns beyond the initial x count of columns aren't refreshed.
Error: Connection closed by host
When loading Text/CSV files from a web source and also promoting headers, you might sometimes encounter the following errors: "An existing connection was forcibly closed by the remote host" or "Received an unexpected EOF or 0 bytes from the transport stream." These errors might be caused by the host employing protective measures and closing a connection which might be temporarily paused, for example, when waiting on another data source connection for a join or append operation. To work around these errors, try adding a Binary.Buffer (recommended) or Table.Buffer call, which will download the file, load it into memory, and immediately close the connection. This should prevent any pause during download and keep the host from forcibly closing the connection before the content is retrieved.
The following example illustrates this workaround. This buffering needs to be done before the resulting table is passed to Table.PromoteHeaders.
- Original:
Csv.Document(Web.Contents("https://.../MyFile.csv"))
- With
Binary.Buffer:
Csv.Document(Binary.Buffer(Web.Contents("https://.../MyFile.csv")))
- With
Table.Buffer:
Table.Buffer(Csv.Document(Web.Contents("https://.../MyFile.csv")))
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for