Textual Domain Specific Languages for Developers - Part 3
[This content is no longer valid. For the latest information on "M", "Quadrant", SQL Server Modeling Services, and the Repository, see the Model Citizen blog.]**
Shawn Wildermuth
MCW Technologies
Updated June 2009 for May CTP
In the first article in this series, you were introduced to the textual domain specific languages and why they can help you build solutions that match the intent of project’s stakeholders. The second article walked you through how to build your own textual domain specific language. But now you should have a parse-able textual DSL. What is next? You are ready to consuming your textual DSL. In this article I will explain how to consume instances of your textual DSL and use the data to feed an application.
Consuming a Textual Domain Specific Language
You have now created a grammar for a domain specific language. An example of the textual DSL looks like this:
ReportBundle "Daily Reports"
// Reports for the Board
Group "Status Reports"
Reports
"https://reportserver/reports/dailystatus.aspx"
"https://reportserver/reports/checklist.aspx"
End Reports
Recipients
"management@litware.org"
End Recipients
End Group
Group "Problem Reports"
Reports
- "https://reportserver/reports/problemreports.aspx"
"https://reportserver/reports/systemstatus.aspx"
End Reports
Recipients
"itstaff@litware.org"
"devmanagers@litware.org"
End Recipients
End Group
End ReportBundle
This textual DSL is now ready to power an application. In this case, an application that can take this data and actually process the reports and e-mail them to the recipients would be the logical choice. But how is that done?
The goal of most textual DSLs is to aid writing and comprehension. The MGrammar is there to validate and enable parsing of the data in the DSL. Ultimately you will need a way of parsing the DSL into something that is easier to code against. There are two strategies for using the data that the DSL describes: runtime parsing and using the toolchain.
At runtime, Oslo supports a number of classes that allow you to parse the DSL and manipulate the results natively as shown in Figure 1:

Figure 1: Runtime Parsing
With Runtime Parsing, you will use the managed APIs to load a grammar and the DSL and interrogate the resulting tree of information. Alternatively you can use the command-line tools to turn the textual DSL information into data stored in a database as shown in Figure 2:

Figure 2: Using the Tool Chain
In Oslo, there are number of tools that will allow you to take your grammar and textual DSL and compile and store them into a standard SQL Server database. In either case, the data structure of your DSL will be stored in the database in a simple form (usually Table Per Type (TPT)). Let’s look further into the details of both these techniques.
Using Your DSL
To consume the textual DSL there is a simple example called “BundleRunner” that is included with this article. The sample will process the report bundles using each of these techniques. In the BundleRunner, there is a simple mechanism that reads a ReportBundle, retrieves the reports, and emails them to the recipients. The BundleRunner application is a simple command-line program (though could be refactored to a Windows Service or GUI tool).
The example uses a simple processing class that does the work of retrieval of reports and sending of the emails. This processor takes an interface (IBundleProvider) that will return a data structure containing the details of the reports to process. This allows the BundleRunner to supply different implementations of the provider for each of the example’s scenarios:
public interface IBundleProvider
{
ReportBundle Bundle { get; }
}
The data that the provider returns is a simple structure of the data inside the DSL as shown in Figure 3:
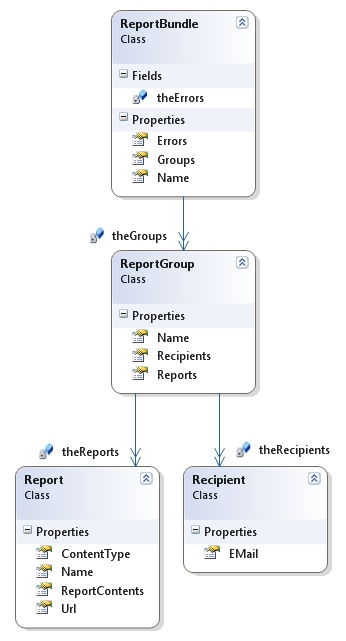
Figure 3: Data Structures
The details of how the processing is done are trivial. What matters most is how you are creating the data structures. The example will create the data with two providers:
- FileBundleProvider: Uses Runtime Parsing of the DSL to produce the data.
- DbBundleProvider: Reads the data from a database.
First up is using the tool chain to insert your data into a database so you can use the DbBundleProvider to build your bundle data. After that you will see how to parse the textual DSL at runtime using the TextBundleProvider.
Using the Tool Chain
Oslo ships with a number of command-line tools that are used to process and validate the “M” family of languages. In the case of building your own grammar, you will use a chain of tools that can take your grammar and textual DSL and turn them into real data to consume in your applications. This chain includes the M Compiler (m.exe) and the M Executor (mx.exe). By using these tools to take your grammar and textual DSL, you can automate the storage of information contained in the textual DSLs.
The first of these is the M Compiler (m.exe). This tool allows you to take your grammar and build a compiled grammar that can be used to parse your textual DSL. You can think of a compiled grammar file like an assembly in .NET. It’s a compiled version of the instructions that your Grammar file contained.
The m.exe tool simply takes the Grammar file (and any other grammar files that are required):
m.exe ReportBundle.mg
Using the M Compiler builds a compiled M file (.mx) file that is then used to parse your DSL files with the M Executor.
The M Executor takes the compiled grammar file and the textual DSL and exports either “M” or XAML (though more formats are likely to appear in the future builds). To use the M Executor, simply run the mx.exe tool specifying the source file and a reference (-r) to the compiled grammar that was created with the M Compiler (m.exe):
mx.exe DailyReports.bundle -r:ReportBundle.mx
This command takes the textual DSL (“DailyReports.bundle”) and processes it with the compiled grammar (“ReportBundle.mx”). By default the M Executor produces an M file containing MGraph. The MGraph is an approximate representation of the Abstract Syntax Tree (AST) but since the AST and MGraph are different structurally, there are differences. For example, here is the AST of your DailyReports.bundle file:
ReportBundles{
{
Name{
"Daily Reports"
},
Groups{
{
{
GroupName{
"Status Reports"
},
Reports{
{
{
Url{
"https://reportserver/reports/dailystatus.aspx"
}
},
{
Url{
"https://reportserver/reports/checklist.aspx"
}
}
}
},
Recipients{
{
{
EMail{
"management@litware.org"
}
}
}
}
},
{
GroupName{
"Problem Reports"
},
Reports{
{
{
Url{
"https://reportserver/reports/problemreports.aspx"
}
},
{
Url{
"https://reportserver/reports/systemstatus.aspx"
}
}
}
},
Recipients{
{
{
EMail{
"itstaff@litware.org"
}
},
{
EMail{
"devmanagers@litware.org"
}
}
}
}
}
}
}
}
}
When the M Executor creates the MGraph file, it conforms to the “M” language spec:
module DailyReports
{
ReportBundles
{
{
Name = "Daily Reports",
Groups
{
{
{
GroupName = "Status Reports",
Reports
{
{
{
Url = "https://reportserver/reports/dailystatus.aspx"
},
{
Url = "https://reportserver/reports/checklist.aspx"
}
}
},
Recipients
{
{
{
EMail = "management@litware.org"
}
}
}
},
{
GroupName = "Problem Reports",
Reports
{
{
{
Url = "https://reportserver/reports/problemreports.aspx"
},
{
Url = "https://reportserver/reports/systemstatus.aspx"
}
}
},
Recipients
{
{
{
EMail = "itstaff@litware.org"
},
{
EMail = "devmanagers@litware.org"
}
}
}
}
}
}
}
}
}
The MGraph representation is a well-formed MGraph version of the AST. There are some subtle (but important) differences. For example, notice that the MGraph representation has a module name and that simple structures are converted to property assignment (e.g. EMail { “foo@bar.com” } becomes EMail = “foo@bar.com”).
In the MGraph that was created, you should notice that the Module matches the file name of your textual DSL. Usually you will want to override this by specifying the module name so that all textual DSL files will end up in the same module. You can do this by using the “–MModuleName” flag and specifying the name of the module. You can use the short form of this flag (-m) to specify the module name as shown below:
mx dailyreports.bundle -r:reportbundle.mx -m:Litware.Data.Reporting
At this point if your MGraph were very simple, you could insert this directly into the database using the tool chain, but in most cases you will want to create an MSchema file to define the structure of your MGrammar projections. This will allow you to compile your M file for preparation to storing them in a database. For example, your MSchema file defines the types that are used in your MGraph production:
module Litware.Data.Reporting {
type ReportBundle
{
ReportBundleID : Integer32 => AutoNumber();
Name : Text#255;
Groups : ReportGroup* where value <= ReportGroups;
} where identity ReportBundleID;
ReportBundles : ReportBundle*;
type ReportGroup
{
ReportGroupID : Integer32 => AutoNumber();
GroupName : Text#255;
Reports : Report* where value <= Litware.Data.Reporting.Reports ;
Recipients : Recipient* where value <= Litware.Data.Reporting.Recipients;
} where identity ReportGroupID;
ReportGroups : ReportGroup*;
type Report
{
ReportID : Integer32 => AutoNumber();
Url : Text;
} where identity ReportID;
Reports : Report*;
type Recipient
{
RecipientID : Integer32 => AutoNumber();
EMail : Text;
} where identity RecipientID;
Recipients : Recipient*;
}
This MSchema file defines the four types and extents that your M Graph uses: ReportBundles, ReportGroups, Reports and Recipients. The M Schema file tells Oslo how to store the M Graph instances of the data in a data store. With your M Schema defined, you can use both the M Graph created by the M Executor and the M Schema you’ve defined to compile your “M” files for use in a data store by using the “M” Compiler:
m.exe DailyReports.m ReportBundleSchema.m /t:TSql10
Notice you’re passing in an M Schema file (ReportBundleSchema.m) and the daily reports M Graph file created by the M Grammer Executor (DailyReports.m). The target flag (/t) specifies that the output will be used. “TSql10” represents a SQL Server 2008 compatible T-SQL.
By default this compiler will produce an image file (DailyReports.mx) that can be used by the M Executor tool. Alternatively you can specify a package flag (/p) to specify that instead of an image file, you want a SQL Script:
m.exe DailyReports.m ReportBundleSchema.m /t:TSql10 /p:Script
This will produce a T-SQL Script that contains the databases schema creation as well as the inserting of the data into the database. In most cases, an image file is what you want if you are going to use the M Executor to insert your data. Using the SQL Script is useful if you are already handing database scripts in your projects in specific ways. Otherwise, use the M Executor to insert the data (and optionally the schema) directly into the database:
mx.exe /i:dailyreports.mx /d:Reports /s:localhost /t:Integrated
Using the M Executor (mx.exe) allows you to take the image file that was created with the M Compiler and insert into a database. The flags used here are:
- /i: The input file (usually an image file).
- /d: The name of the database to insert into.
- /s: The SQL Server name/address to use.
- /t: The Trusted Connection Type. Alternatively you can use /u and /p to pass in the username and password to the database.
Additionally, you can specify that the M Executor create the database using additional flags:
mx.exe /i:dailyreports.mx /d:Reports /s:localhost /t:Integrated /c /f /ig
All the new flags are not necessary but make creating the database much easier. The flags are:
- /c: Create the database
- /f: Forced install which means that schema elements (extents, types and constraints) that exist in the database will be overwritten.
- /ig: Ignore dependencies when creating the database.
Once created, the database objects all use the module name as the schema in the data. For example, the database tables created map to each of the types in your schema (as well as mapping tables) as seen in figure 4:

Figure 4: Database Schema Created by M Executor
If you compare Figure 3 and 4 you will notice that the structure of the data in the database is different than the object model you’re mapping to, so the example will need to use standard data access techniques to get your data from the database and use it at runtime to create the structure the example needs.
The BundleRunner has an Entity Framework model based on the database:

Figure 5: BundleRunner Entity Model
Taking this entity model and using it to create your runtime data is relatively straightforward.
public class DbBundleProvider : IBundleProvider
{
ReportsEntities ctx = new ReportsEntities();
string theBundleName;
ReportBundle theBundle;
// Accept the Bundle Name to find in the database
public DbBundleProvider(string bundleName)
{
theBundleName = bundleName;
}
// Process the bundle once its asked for
public ReportBundle Bundle
{
get
{
if (theBundle == null)
{
ProcessBundle();
}
return theBundle;
}
}
void ProcessBundle()
{
string reportPath =
"ReportBundles_Groups.ReportGroup.ReportGroups_Reports.Report";
string recipPath =
"ReportBundles_Groups.ReportGroup.ReportGroups_Recipients.Recipient";
// Find the bundles and eager load whole model
var qry = from b in ctx.ReportBundles
.Include(reportPath)
.Include(recipPath)
where b.Name == theBundleName
select b;
// Find first bundle (if any)
var bundle = qry.FirstOrDefault();
if (bundle != null)
{
// Build Structure
theBundle = new ReportBundle();
theBundle.Name = bundle.Name;
// Build the Groups
foreach (var bundleGroup in bundle.ReportBundles_Groups)
{
var newGroup = new ReportGroup()
{
Name = bundleGroup.ReportGroup.GroupName
};
theBundle.Groups.Add(newGroup);
// Add Reports
foreach (var groupReport in bundleGroup.ReportGroup.ReportGroups_Reports)
{
newGroup.Reports.Add(
new Report()
{
Url = groupReport.Report.Url
});
}
// Add Recipients
foreach (var groupRecipient in
bundleGroup.ReportGroup.ReportGroups_Recipients)
{
newGroup.Recipients.Add(
new Recipient()
{
EMail = groupRecipient.Recipient.EMail
});
}
}
}
}
}
In this case, the code simply returning the bundle as an object graph of managed objects so that the processor can get the reports and send them off to the recipients.
In order to get your DSL data into the database, you would use the tool chain as shown in Figure 2. This means compiling your grammar, processing your DSL into M utilizing the grammar, then compiling schema with the M to store it into the database. This tool chain represents a way of taking textual DSLs and turning them into useful data.
Storing this data in the database can be very useful in managing the longer-lived functionality of the processing of reports. But having to store the data in the database is simply not necessary. There are times when using the data purely at runtime is more valuable. That’s where runtime parsing of your DSLs becomes the tool of choice.
Runtime Parsing
Everything that the tool chain can do you can accomplish with code. In fact, Oslo exposes all those services to developers. To use runtime parsing, you will need to reference the Microsoft.M.dll assembly, the System.DataFlow.dll and the Xaml.dll assembly from the Oslo SDK directory. Once you do that you can compile the M Grammar in your own code like so:
using Microsoft.M;
Stream mgStream = File.OpenRead("ReportBundle.mg");
CompilationResults results = Compiler.Compile(
new CompilerOptions
{
Sources =
{
new TextItem
{
Reader = new StreamReader(mgStream),
ContentType = TextItemType.MGrammar
}
}
});
When you use the M Executor to produce M, the code inside the mx.exe tool simply reads the AST and produces valid MGraph statements that are similar to the AST. When you are building runtimes or tools that parse textual DSLs you can do the same. Again, the same code is available to you as the code that the tool chain authors used.
The functionality for parsing your textual DSL starts with the DynamicParser class (which is contained in the System.Dataflow.dll assembly). To start out, you need to load up the compiled grammar by using the MImage class. Then you can use the new grammar to create a parser (for your specific language). Finally, specify the type of GraphBuilder to use by using the NodeGraphBuilder class. The NodeGraphBuilder exposes a simple navigation through the resulting parsed DSL to simplify our code (this was introduced in the Oslo May 09 CTP). Creating the parser is shown below:
var grammar = new MImage("ReportBundle.mx");
theParser = grammar.ParserFactories["Litware.Data.Reporting.ReportBundle"].Create();
theParser.GraphBuilder = new NodeGraphBuilder();
Once loaded, the DynamicParser can parse your textual DSL. To parse the textual DSL, the DynamicParser’s Parse method is used as shown below:
// Retrieve the root of the AST by performing Parsing
Node root = (Node)Parser.Parse(sourceFileName, null);
Because we specified the NodeGraphBuilder, the Parse method returns a Node that represents the root of the parsed DSL file. The Node class exposes a simple API for walking the AST.
To iterate over the AST, the framework uses the Node class. This class contains methods and properties for walking the tree.
From the root node, you can get a list of descendants by calling the ViewAllNodes method. This method returns a NodeCollection object. You can retrieve this collection like so:
// Get list of Bundles
NodeCollection bundles = root.ViewAllNodes();
The NodeCollection supports the IEnumerable<Node> interface so we can use LINQ against the collection. Because the example assumes only a single bundle in your BundleRunner, you can retrieve the single node like so:
// Get the node that represents the single Bundle
var bundleNode = bundles.First();
Because the bundle’s node contains properties (Name and Groups), could get each of these by retrieving the element by ordinal like so:
var nameNode = bundleNode.ViewAllNodes().ElementAt(0);
But instead, you should find it easier (and more refactorable) to use a property called Brand to determine the node type. The Brand is the name of the item in the AST that you gave it in your grammar. For example, the bundle’s name was specified in your grammar as “Name”. So by checking the Brand.Text value for that name, you can be sure that the item in the AST is the right one. Here is an example of using a switch statement to handle each of the nodes as they show up:
// Go through Children
foreach (var bundleChild in bundleNode.ViewAllNodes())
{
switch (bundleChild.Brand.Text)
{
case "Name":
{
// Get the first element to retrieve the name
theBundle.Name = (string)bundleChild.ViewAllNodes().ElementAt(0).AtomicValue;
break;
}
case "Groups":
{
// Get the first element to retrieve the Group
CreateGroup(bundleChild.ViewAllNodes().ElementAt(0));
break;
}
default:
{
break;
}
}
}
You should notice that because the AST is fairly nested that the code uses the Name node and retrieves the first element (using ElementAt) then casts its AtomicValue to a string. Only leaf nodes will have a valid AtomicValue (whereas it will be null in all other cases). The AtomicValue property therefore is used only when retrieving the final leaf of a node.
You can see the type of named objects to return by looking at the resulting AST. In this case your example must get the named member called “Groups” which happens to be a collection of your Group nodes. You can see this by looking at the AST in figure 8:

Figure 6: AST Node Types
By using the Node class, you can iterate through an entire AST. The entire parsing of your textual DSL can be seen here:
// Perform the parsing of the AST
void Parse()
{
// Retrieve the root of the AST by performing Parsing
Node root = (Node)Parser.Parse(sourceFileName, null);
// Get list of Bundles
var bundles = root.ViewAllNodes();
// We expect a single bundle so throw an exception if necessary
if (bundles.Count == 0)
{
throw new InvalidOperationException(
"Expecting a single Bundle, found none.");
}
if (bundles.Count > 1)
{
throw new InvalidOperationException(
"Expecting a single Bundle, found more.");
}
// Get the node that represents the single Bundle
var bundleNode = bundles.First();
// Go through Children
foreach (var bundleChild in bundleNode.ViewAllNodes())
{
switch (bundleChild.Brand.Text)
{
case "Name":
{
// Get the first element to retrieve the name
theBundle.Name = (string)bundleChild.ViewAllNodes().ElementAt(0).AtomicValue;
break;
}
case "Groups":
{
// Get the first element to retrieve the Group
CreateGroup(bundleChild.ViewAllNodes().ElementAt(0));
break;
}
default:
{
break;
}
}
}
}
void CreateGroup(Node groupNode)
{
foreach (var info in groupNode.ViewAllNodes())
{
// Create a new Group to fill in
ReportGroup group = new ReportGroup();
// Navigate to the actual Group Contents
foreach (var groupPart in info.ViewAllNodes())
{
// Look at each part of the group
switch (groupPart.Brand.Text)
{
case "GroupName":
{
group.Name = (string)groupPart.ViewAllNodes().ElementAt(0).AtomicValue;
break;
}
case "Reports":
{
var contents = groupPart.ViewAllNodes().ElementAt(0);
foreach (var rptNode in contents.ViewAllNodes())
{
Report rpt = new Report();
rpt.Url = (string) rptNode.ViewAllNodes().ElementAt(0).AtomicValue;
group.Reports.Add(rpt);
}
break;
}
case "Recipients":
{
var contents = groupPart.ViewAllNodes().ElementAt(0);
foreach (var rcptNode in contents.ViewAllNodes())
{
Recipient rcpt = new Recipient();
rcpt.EMail = (string)rcptNode.ViewAllNodes().ElementAt(0).AtomicValue;
group.Recipients.Add(rcpt);
}
break;
}
default:
{
break;
}
}
}
Bundle.Groups.Add(group);
}
}
Where we are…
As you should know by now, building the textual DSL is only half the task. Being able to work with the data that your textual DSL exemplifies is the other half. The Oslo toolset provides a number of ways to work with that data. While the Oslo tool chain allows you to process your textual DSL into a data store for use in the rest of the system, this doesn’t represent the only way. Being able to write your own code against the raw AST provides a lower level of power to turn the textual DSL back into the intent of the requirements.
By understanding the entire chain from why textual DSLs are so powerful, how to build the grammars that represent the rules for those textual DSLs and finally being able to use the data in the textual DSLs; you should be able to build powerful, data-driven systems without relying on technical and terse ways of capturing that data. Involving those important users and stakeholders will help you as a developer keep the business of writing compelling solutions without having to worry about as much of the minutiae of the system requirements. You can write your applications to be powered by the rules instead of encoding the rules.
Resources
- Microsoft’s Oslo DevCenter
- My Blog