Internet Information Services
Scaling ASP.NET Applications: Lessons Learned
Richard Campbell
At a Glance:
- The importance of developer/IT collaboration
- Understanding the principal scaling strategies
- Sharing knowledge across teams
- Agreeing on a core set of knowledge
Contents
The Fundamentals of Scaling
The Meeting of the Minds
What Networking Needs to Know from Development
What Development Needs to Know from Networking
Getting Back to Scaling
The Cooperative Firefight
As a consultant, every successfully scaling ASP.NET application I've ever worked with has been the result of a collaborative effort between the developers (who built it) and the network administrators (who actually run it). Unfortunately, it's not always apparent at the beginning of an
application's lifecycle that this collaboration is essential. As a result, I almost never have a chance to get involved at the beginning of an application's lifecycle—only at the bitter end when there is trouble.
The simple truth is that no application scales effectively the first time around—it's impossible to get everything correct right out of the gate. To successfully scale an application, you need to understand how the application was built as well as how the operating environment it runs in works. In other words, you need information from both the development folks and the network folks. Without that shared knowledge, you can not succeed.
The Fundamentals of Scaling
Before diving in, let's set the stage for what it takes to actually scale an ASP.NET application. There are two fundamental strategies that are typically employed—specialization and distribution—and most large, scaling ASP.NET applications apply both strategies. Furthermore, every trick in the book to help your ASP.NET application scale breaks down into one or the other.
Specialization entails separating elements of the application so they can be scaled independently. For example, you might build dedicated image servers rather than using the same servers that render the ASP.NET pages. The optimal configuration of an image server is quite different from an ASP.NET server. Also, separating your image requests from the rest of the application opens up the possibility of using third-party resources for serving images. The same approach can apply to other resource files.
Distribution, on the other hand, involves spreading the application symmetrically across multiple servers, typically called a Web farm. ASP.NET applications are particularly suited to distribution because each individual page request is relatively small, and the interactions of a given user are largely independent of other users. Distribution is really the manifestation of the "scale out" philosophy, where multiple mid-performance servers work together to service the users, rather than the "scale up" approach that has one massive server doing it all.
Combining specialization and distribution increases efficiency—you can distribute only the elements of the application that need additional performance. For example, if you've created specialized image servers but image serving is still not adequate, you can add image servers rather than adding servers for the entire application. It's important to keep these strategies in mind as you dig into improving the performance and scalability of your ASP.NET application.
The Meeting of the Minds
At some point during the lifecycle of every ASP.NET application, the developers and the network/IT personnel are likely to meet. With any luck, this will take place before the application is deployed, but sometimes it happens only after there is a crisis—for example, when the application runs great in the test environment, then ships to the users and slows to a crawl. (This is when consultants like me are called in.)
When developers and network people meet, the primary goal is to exchange information. The developers possess key knowledge about the application, as do the network personnel about the operating environment. Each group needs to understand the other group's data, and the earlier in the application lifecycle they meet, the better.
This meeting should not occur for the first time during a crisis. Without a core understanding between the two teams, it's extremely hard to figure out why the application isn't performing up to requirements. Furthermore, it's all too easy to defensively decide that the problem lies solely with the other team. And that's simply never true—invariably it takes both parties to solve any significantly complex problem.
Even in good times, however, such a meeting can be a very challenging. Those I have orchestrated typically start with the network folks on one side of the table, the development folks on the other. Staring ensues. To get the conversation rolling, I outline the goal of the meeting, specifically a trading of knowledge. It doesn't matter who goes first. I'm going to start with what networking needs to know from development.
What Networking Needs to Know from Development
Every ASP.NET application has its own quirks, but there are key elements that apply in every case. The web.config file is one of these (see Figure 1). Web.config is an intersection point between development and networking. Sometimes it's configured by the developers, sometimes by networking folks. Either way, what's in web.config puts limits on the hardware and network configuration and directly affects how the application operates. Exploring every little aspect of the web.config file in detail would easily fill an entire book; here the point is that both groups need to study the web.config file and agree on what the configuration it represents means and also on the impact the various settings will have on the application and on the environment.
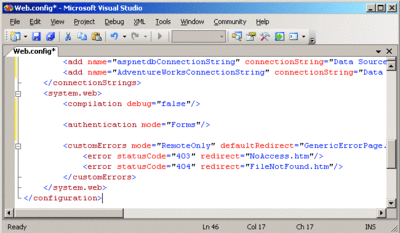
Figure 1 A basic web.config showing some application settings and custom error configuration (Click the image for a larger view)
For example, the <authorization> section of web.config specifies how users will be authenticated in the application, and thus defines a dependency. If the application uses Windows® authentication, it may be dependent on Active Directory®. If it uses forms-based authentication, the dependency is on a data store of user accounts. That's certainly worth a conversation.
The <customErrors> section is worth noting because it affects how failure looks to users. This is not a complex setting, but it's worth discussing just to understand what the error pages will be. Early on in the collaborative cycle there probably are no custom error pages—that too is worth a conversation.
The <appSettings> section of web.config can be especially significant. This is typically where developers stash global values, like connection strings for databases. It's a great source of dependencies and a key part of planning for failover, migration, and so on. But since the <appSettings> section is entirely custom, it can contain almost anything and may require a lot of explanation to understand what's there. Often orphans are left in this section—values that don't actually get used anywhere in the application.
Even if your developers aren't using <appSettings>, the network/operations folks may want them to—having all database connection strings there is an effective way to create a simple failover strategy. If the database server dies, a replacement string can be inserted to point to a different database server. Catching this opportunity early in the development cycle can increase the reliability and maintainability of the application.
Finally, you should note that an absolutely key value in web.config from a scaling perspective is the <sessionState> tag, which determines where session data will be stored for the application. By default, session data is stored "InProc," or in the process space of the ASP.NET application. If the session data is configured for in-process, it means all load balancing must be "sticky"—a given user must always be served back to the same server, where the session data resides. This is a huge conversation between developers and network folks because it directly impacts how you scale and how you failover. Talking early about this can save a lot of heartache when trying to debug the application.
Once the conversation gets to session state, it's easy to segue into the load-balancing requirements of the application in general. Some environments have dedicated load-balancing hardware with specific features—but if the application can't handle these features, they aren't going to mean much. I have encountered situations where hardware load balancing was being used with an ASP.NET application that had in-process session data. The consequence was occasional lost sessions with no explanation. It looked like a bug in the application, but it wasn't—it was a configuration mistake.
The network folks need to know clearly from development exactly what load balancing schemes will work for the application. This is very much a two-way conversation, about what load-balancing schemes are available as well as what the application can tolerate. A powerful advantage to having this conversation early in the lifecycle of the application is that you could plan in advance to go to an out-of-process, non-affinity load balancing scheme.
By the time an ASP.NET application is ready for deployment (or is already in its initial deployment), the development staff will have a pretty good idea of the areas of the application that are fast and slow. Most importantly, they'll have a sense of the bottlenecks or potential crisis points in the system. If the network/operations team knows about these bottlenecks, they can prepare for problems ahead of time, and perhaps even avert them.
For example, I once worked with an application that had a massive data-load process every night, during the application's downtime. The developers built the data-loading mechanism, tested it, and understood how it worked. They knew it was very stressful for the database, but it was effective and a good way to solve the problem.
But they never told the networking team that this process took place, or that they scheduled it to run at 1 A.M.—exactly the time the database backups ran. The database remained online, but it ran much more slowly during backup time as all transactions being sent to the database would be held in the transaction log.
It wasn't until the combination of simultaneous dataload and backup caused the database transaction log volume to run out of disk space that the conflict was identified. Moving the data load to start at 3 A.M. completely resolved the problem—but only after several days of crisis.
Having a conversation early about these kinds of workload items in your application can save a ton of grief down the road.
What Development Needs to Know from Networking
My favorite starting point for the part of the meeting where the networking folks explain their world to the development folks is the network diagram. All too often, the developers see the network as in Figure 2—that is, no network, merely just Web servers, browsers, and the Internet.
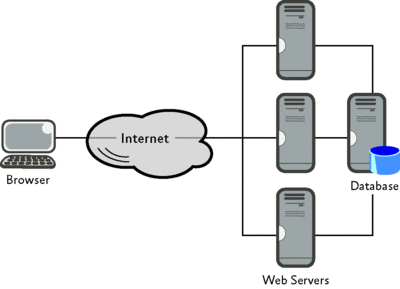
Figure 2 The simple network vision of the developer (Click the image for a larger view)
The reality, of course, is a lot more complex. A diagram like Figure 3 is closer to the truth, though even that is simplified. When you look at Figure 3, you immediately have more questions, such as "how will the Virtual Private Network (VPN) users work with the application," or "what is the authentication difference between an internal user and a public user," and so on.
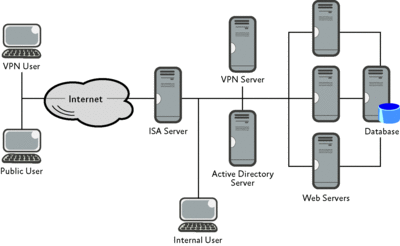
Figure 3 The real network that the developers need to understand (Click the image for a larger view)
Obviously, it's not enough to simply provide a network diagram. It's important to also explain the network in detail because it's impossible to know, just by looking at a diagram, exactly what elements will impact the application. You need to talk through the actual connect process of a public user, a VPN user, and an internal user. And discussing the various firewall rules that exist, especially in more complex DMZ-style network architectures, will naturally bring up potential issues for the application.
Obviously, it would be advantageous to have all these discussions before the application was deployed, even before development started—but no matter what, the discussion has to happen eventually, and having everyone at the table understand the entire network diagram is key.
Networking is also the arena of failover and redundancy models, but without some software support or at least awareness of behavior, these models rarely work as planned. A detailed discussion of what various scenarios of failure look like has to take place. If there is clustering in place on the database, this will affect code relating to accessing the database. For example, can the queries retry after a server switchover? If there is a redundant site available, how is data going to be replicated to the site? How does a switchover take place from one site to the other?
Once again, having the conversation early helps, but better late than never—all the folks involved with the application need to understand how these things work. There's nothing more frustrating than having a failover solution that doesn't actually work when it's needed.
Finally, there's one other key network resource that needs to be shared—production logs. I always recommend that production logs be made available to the development team. The usual reaction from network folks to this request is "Ask me for them and I'll send them to you." I don't think this is adequate—it's much more effective to give developers the ability to retrieve the logs themselves, typically from a backup site.
Production logs are essential during a crisis. They're often the best (and only) source of real, empirical data on what actually happened. But they're equally valuable in more ordinary circumstances. When developers have routine access to production logs, they can check through them to see how a new feature is behaving. And that's a great way to find out that your feature is not doing what you expected and correct the problem before it's a crisis. When everyone has access to logs, you can react to problems quicker and fix them sooner.
Getting Back to Scaling
The meeting between network and development is all about understanding the full scope of the issues surrounding scaling an ASP.NET application. The actual environment the application operates in directly affects how the code the application runs will work. All the strategies around scaling will impact its behavior in the environment. Applying a specialization strategy such as separating out the SSL-related parts of the application may require changes to the networking environment and possibly changes in the servers themselves.
Even an apparently code-centric change like using caching can impact the environment. That is because when you add data caching to your ASP.NET application, you're decreasing the number of database calls in exchange for an increase in memory usage. The result is that you might increase the number of ASP.NET servers you need, or increase the number of worker thread recycles on the servers, which would trigger events at the network monitoring side.
Scaling your ASP.NET application does impact both development and network personnel—so it's well worth involving both groups in the decision-making process. Often the collaboration will yield original solutions that the teams working independently wouldn't discover. For example, network folks might be aware of existing hardware solutions within the company that can help the developers deliver on performance and scaling requirements. Talking through the details of the application and the environment will reveal these opportunities.
The Cooperative Firefight
Resources for Scaling ASP.NET Apps
- Developing High-Performance ASP.NET Applications
- How To: Scale .NET Applications
- How To: Tune and Scale Performance of Applications That Are Built on the .NET Framework
- Implementing a Scalable Architecture
- Maximizing IIS Performance
- Scaling Strategies for ASP.NET Applications
A crisis in scaling isn't automatically a bad thing—in fact, it's usually a good thing since it's brought on by too many users wanting to run your application, making it proof of the application's value! Now, though, you have to make it work.
Sometimes scaling crises are brought on by another event—perhaps your company is doing a promotion, or you were blogged about, or a social networking site has pointed a tremendous number of people at your Web site all at once. All of a sudden, you're in a firefight to keep the application running. As you might guess, it's best to work through this kind of scenario before it actually happens. And a demonstration of how collaboration can help an organization survive this sort of crisis is a great way to close your meeting of developers and network folks.
The first question in managing the crisis is "How do we detect that the site is dying under load?" All too often the answer is, "we get a call from the CTO." If the first sign that your Web site is in trouble is a call from anyone outside, you have a problem. Some decent metering should inform you of problems before the phone rings. It won't actually stop the phone from ringing, but it will at least give you a head start on how to answer. Saying "Oh really?" to the CTO is not a career-enhancing move.
Next question—who gets called first? Who responds to the event? Often a network person gets the first warning, and that person might be relatively inexperienced so there needs to be a clear escalation plan. Who gets called next? The challenge is doing early, rapid diagnosis to find out what sort of problem you're having. If it's a network outage, that's one thing. But if it's a scaling problem, that's something else entirely. With scaling problems, getting someone from the development team involved early is advisable.
Everyone involved in the firefight needs good information, so effective access rights are key. The goal is to disseminate as much information as possible so that an effective diagnosis can be made, and this should ultimately dictate the scope of the solution.
Often, if the only answer is to write code, the event will be over before the code can be written. Of course the event should be noted in order to help shape development priorities in the future, but it's not reasonable (or smart) to try writing a pile of code and ram it into production without careful testing. Rule #1 of any firefight—don't make the fire any worse.
When it comes to scaling problems, sometimes the solution is to simply wait it out. But that is still a decision that can be made.
At the same time, planning for these contingencies means that different techniques can be rapidly applied. Bringing both network and development resources to bear on a scaling problem often solves it in remarkably good time, perhaps even soon enough to make that promotional event even more of a success.
In conclusion, the lesson learned from the network side is that a high-scaling, well-performing ASP.NET application represents a successful collaboration between the folks who build the application and the ones who deploy and operate it.
The collaboration is inevitable, so it's best to start early with meetings between the teams to share information. The goal of the meetings is to build understanding and agreement on all elements of the application, what it does, how it works, what it depends on, how it behaves under load, and how it copes with problems that arise over time.
When this collaboration is really effective, the result is a more agile company, one that is able to respond quickly when there are problems, and one that is able to communicate clear goals on what the application needs in order to succeed in the future.
Richard Campbell is a Microsoft Regional Director, an MVP in ASP.NET, and the co-host of .NET Rocks, the Internet Audio Talkshow for .NET Developers (go to dotnetrocks.com). He has spent years consulting with companies on the performance and scaling of ASP.NET and is also one of the co-founders of Strangeloop Networks.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.