Web Infrastructure
ASP.NET Web Cache Spurs Performance and Scalability
Iqbal Khan
At a Glance:
- Dramatic bottleneck reduction
- Static and dynamic Web caching
- Must-have features: expirations, database dependency, PDF partial content, more
- Special benefits for global organizations
- Web-cache server clusters
- Free and commercial solutions
The Problem: ASP.NET Bottlenecks
The Solution: ASP.NET Web Cache
Must-Have Features in Web Cache
Expirations
Reload Pages on Expirations
Partial-Page Caching
Database Dependency
File Dependency
PDF Partial Content
ViewState Caching
Gzip Compression
Scalable and Dynamic Web-Cache Cluster
Geographical Cache Distribution
Stay Away from the Database
Guidelines
Applications based on ASP.NET, Microsoft's Web-application framework, are making greater inroads into the enterprise. At the same time, bottlenecks resulting from growing numbers of users and transactions continue to prompt IT professional to call for improved performance and scalability.
The Problem: ASP.NET Bottlenecks
Bottlenecks can occur in ASP.NET applications for a variety of reasons. The most obvious: Data-storage technology isn't as scalable as Web-applications architecture. Any place in an ASP.NET application that deals with data storage or data access immediately becomes a logjam when you try to scale your application. Two areas where this happens are Session State storage and application data from a relational or mainframe database (see Figure 1).
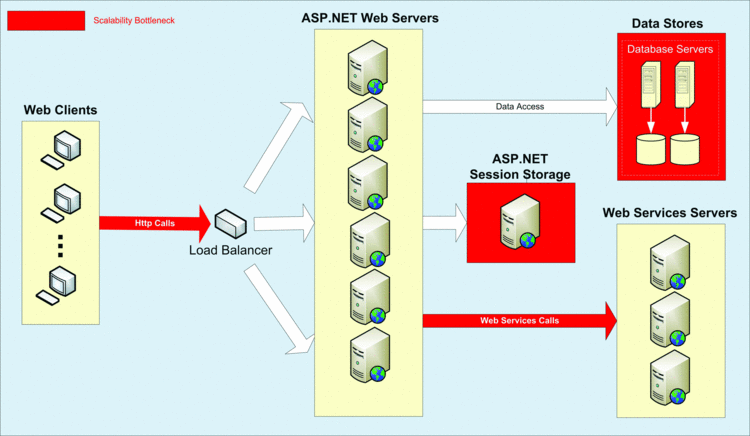
Figure 1 Common areas of performance bottlenecks in ASP.NET applications.
Another bottleneck occurs if your ASP.NET application is making service- oriented architecture (SOA) calls to Web services. Here, the slowdown happens because the Web services have the same issues as your ASP.NET application (namely, in data storage and access). Chances are that a Web-services farm is being shared across multiple applications and, therefore, being stressed much more than any one ASP.NET application, creating the scalability bottleneck.
Bottlenecks can also occur between the user's browser and the ASP.NET Web farm. These clogs are related to the fact that ASP.NET pages have to be executed repeatedly at time involving intensive CPU processing. This process also involves sending heavy data elements (images, documents, etc.) to the user again and again.
In a previous TechNet Magazine article, I discussed ASP.NET performance and scalability issues, focusing on Session State and application data (see "Providing Scalability for ASP.NET Applications," June 2009). In that article, I covered how those problems occur, including the reasons that the ASP.NET Session State becomes a logjam as a Web farm grows. I discussed the fact that distributed in-memory cache is a superior alternative to Microsoft's existing storage option for ASP.NET Session State. I described how application data coming from a database can cause scalability bottlenecks. I also detailed how distributed caching resolves those ASP.NET Session State storage bottlenecks with the help of different caching topologies that each offer different features, but all address scalability and assure 100 percent uptime.
Finally, I generically profiled the different distributed caching options available in the market. Some options are free with limited capabilities, while others are more robust and feature-rich commercial products. However, for best performance and scalability, it's prudent to consider top-of-the-line commercial products.
The Solution: ASP.NET Web Cache
With that problem definition as a backdrop, this article's primary focus is on performance and scalability bottlenecks between the user's browser and the Web server or Web farm. Ideally, you want to reduce the number of times that the Web page itself executes. If the Web page is executed once, and its output isn't changing even briefly, then why execute it again? Why not just cache the output? Then the next time a user can just fetch that page's output directly from the cache, rather than re-executing it. Re-executing the page involves the CPU, consumes memory and uses other Web-server resources—and then, of course, there are the scalability bottleneck problems from data storage.
An ASP.NET page's output can be cached on the Web server itself; Microsoft provides the ASP.NET Output Cache mechanism to allow you to do that, and it works well. However, I do have two concerns about the ASP.NET Output Cache.
First, it requires you to change your ASP.NET code and, at the minimum, put tags on these pages to indicate that you want to cache their output. That's not always possible for an IT person who is managing both internally developed and externally purchased ASP.NET applications. Also, anytime you change your application code, you must go through quality-assurance efforts to make sure that nothing broke in the process. This increases the cost of incorporating caching.
Second, ASP.NET Output Cache caches page output local to each Web server and, in fact, inside each ASP.NET worker process. This creates major issues in terms of consistency and scalability if you have a Web garden (meaning multiple worker processes on a Web server) or a load-balanced Web farm. In these cases, you have multiple disconnected copies of the cache; for high traffic Web sites, this could become a management nightmare. In ASP.NET 4.0, Microsoft is promising an extensible caching framework that would allow you to keep the cache in a separate process or tier by incorporating a third-party distributed cache.
In light of this development, I prefer to cache page output not on the Web server, but in a separate Web-cache server that sits between users and your Web farm (kind of like a reverse proxy; see Figure 2). If a lot of user requests don't make it to the Web farm and are served from a cache in between instead, you're reducing the load on your Web farm and increasing the Web farm's scalability. Fetching output of a Web page from the cache and returning it to the user requires considerably fewer resources than actually executing that Web page. That's because the cache is a high-performance and scalable in-memory storage, unlike any disk storage that can have problems with performance and scalability.
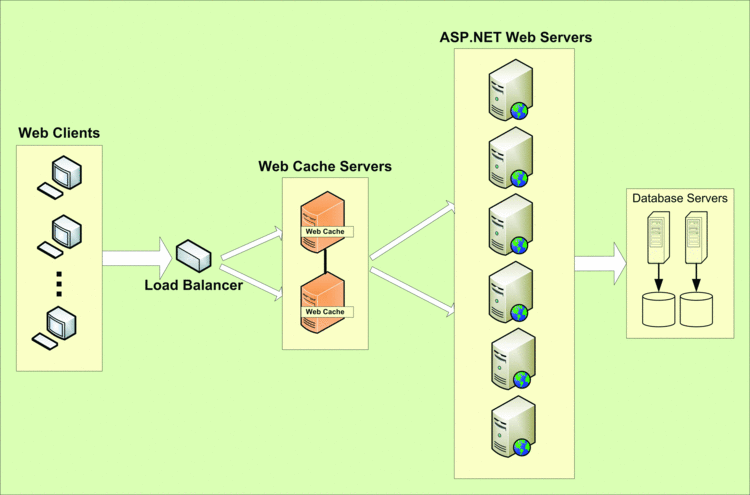
Figure 2 Web-cache servers sitting between users and Web servers.
In this context, I'll discuss how caching the output of Web pages can resolve bottlenecks and considerably boost scalability and performance. A Web-cache server can play an important role in achieving these goals.
A Web-cache server intercepts http requests that users make for Web pages and checks to see whether those pages' output already exists in the cache. If it does, the Web-cache server returns that output to the user. The user request never even makes it to the Web servers. Because it's being fetched from the cache, the return is extremely fast. And because it's in memory and the page doesn't have to be re-executed, a lot of CPU processing is saved as well.
A Web-cache server can work with any back-end Web-technology platform. As long as they're all talking HTML and JavaScript, it doesn't matter whether the Web application is developed in Java, .NET, PHP or some other language. However, a Web-cache server can include some platform-specific features, so features differ from solution to solution.
There are two types of Web-caching solutions. One primarily caches fairly static data, meaning that every page being cached is presumed to be either totally static or to change at predictable intervals. The entire page is cached for a certain amount of time, after which it expires and is removed from the cache. The other type is for dynamic caching, which is more appropriate for dynamic Web sites or Web applications.
If your Web site or Web application is dynamic, where data changes frequently and unpredictably, then you should opt for dynamic caching. These days, most Web sites change at least some of their content frequently. You should be able to cache something for as little as 15 to 30 seconds, but normally for anywhere from a few minutes to a few hours—and in some cases, for days or even weeks.
Web caching offers an important benefit to large worldwide corporations: the ability to geographically disperse Web-caching servers. In a global organization, your main Web site application may be hosted in New York, but you have users all over the world—in San Francisco and London and Tokyo and Sydney and Dubai. Now it's relatively easy to have Web-caching servers geographically located in each of these areas. All requests coming from Europe will go through the European Web-cache server before they hit your Web site. That way, they don't have to cross the Atlantic Ocean and incur that 100-millisecond latency that every packet has to go through. They can basically get a copy of it from a nearby cache.
Let's take another example. You have a server in Dubai serving the Middle East and South Asia regions, and you've got hundreds of thousands of users hitting your Web site simultaneously. With Web caching, traffic to your main data center in New York will drop significantly. Not all the traffic is stopped because you don't cache everything, and whatever you are caching is also removed from the cache (that is, invalidated) at times. But depending on the nature of your application, you've probably reduced the traffic by 30 to 50 percent.
Must-Have Features in Web Cache
Over time, Web sites have transformed from only showing static content to becoming fully interactive Web applications with dynamic data that changes frequently. That means that, today, a Web cache must cater to all requirements of a dynamic Web site. The goal is to cache as much of the Web-site content as possible, while at the same time ensuring that the cached content is correct and not stale or out-of-sync with the underlying data in the database. To handle all that, the Web cache needs certain features to avoid data-integrity problems while boosting performance and scalability.
A typical Web-cache solution includes the following features.
Expirations
Expiration capability allows you to specify rules about which Web pages to cache and for how long. And it allows you to expire pages on either absolute or sliding time. Absolute time means you are going to expire something at a certain time, whether it's midnight today or 10 minutes from now. Sliding time depends on whether a certain page is constantly being accessed. If a page isn't being accessed—if it's not being used at all—you may want to expire it. An idle time would expire a page if it doesn't get used for more than a certain amount of time—for example, 10 or 20 minutes.
Absolute-time expiration is probably the most important time of expiration for Web pages. Web-caching products allow you to specify rules and choose which URL patterns (known as "URI") to cache. Web caching allows you to specify that certain URLs should never be cached. It allows you to specify certain types of URLs to cache for a certain lengths of time.
It should also allow you to specify when to expire various URLs based on information provided in the HTTP headers that comes with the URL output. Every page's HTTP header can contain information about how long it can be cached, when to expire it and when was it last changed. Those are the items Web cache can check to monitor whether a page's content has been changed and whether it needs to upload new content into the cache. Without this feature, you don't have a way to invalidate and remove stale data.
Reload Pages on Expirations
Another important feature is being able to automatically reload a page when it expires for any reason, whether due to absolute or idle-time expiration. For instance, you might say: "This page is good for the next 20 minutes." After 20 minutes, the Web cache automatically re-fetches that page so that it always has the latest copy.
This way, you don't wait for the next request from the user for that page. That's because when the request comes, you don't want the user to go through the delay for fetching that page again from the Web farm. Because you can fetch it in the background, it may take you 5 to 10 seconds to fetch it from the Web server by executing it first. But that's fine, because by the time the user gets it, you'll be able to return it with a sub-second response time, depending on how far away the user is.
Partial-Page Caching
Some of the pages that show up in a browser contain multiple items that each have their own URLs. So for a page to be rendered, the Web browser must call multiple URLs. This achieves the same result as a partial page—but it's not called "partial page" because on the server side, each URL represents a separate page and each page is cached independently and for a different duration, depending on the nature of its content.
In other situations, a single Web page is developed in such a way that its content is divided up into sections. Some sections are static and don't change; some portions are dynamic, with each portion changing after a different interval. In effect, partial-page caching caches page sections based on whether they're static or dynamic and for how long they should be cached, rather than just caching the entire page.
ASP.NET allows you to do partial-page caching through two means: control caching and post-cache substitution. Both require you to modify the particular ASP.NET pages where you want to do this caching. That may not be possible if you don't have your own development resources and you didn't develop this ASP.NET application in-house. Nonetheless, a description of each type of partial-page caching in ASP.NET follows.
You can do partial-page caching in ASP.NET by creating user controls to contain the cached content and then marking the user controls "cacheable." This allows you to cache some parts of the page as user controls so that when the page is re-executed, these portions are simply fetched from the cache and not re-executed. Only those parts of the page that aren't designated as user controls and are not marked "cacheable are re-executed."
With post-cache substitution, the page is cached, but some portions or fragments inside it are marked "dynamic" or "non-cacheable." Then, when this page is re-executed, only the dynamic or non-cacheable portions are actually executed. The rest of the page is obtained from the cache, and both cached and dynamic portions are combined to return the output of the page.
Interestingly, partial-page caching can only be performed on the Web server. For that reason, some programming is necessary. In the case of ASP.NET, partial-page caching is done by programming in the ASP.NET pages to determine what—and what not—to cache. But this caching is performed on the Web server itself and still executes the ASP.NET page, at least portions of it.
In ASP.NET, partial-page caching is implemented based on Microsoft's specification, but on the Java platform, a partial-page caching standard called Edge Service Includes (ESI) has emerged. ESI defines a simple XML-based markup language that defines cacheable and non-cacheable Web-page components that can be aggregated, assembled and delivered at the network edge, whether it's in a content-delivery network, an end user's browser or a Web-cache server acting as a reverse proxy between users' browsers and the Web server.
So, partial-page caching is highly platform-specific—and, of course, for ASP.NET, you must use Microsoft's approach.
Database Dependency
Another key feature is database dependency, which allows a page output to be invalidated from the cache when corresponding data in the database changes. The pages' output is often generated based on data in the database. The data they are depicting comes from one or more rows in one or more database tables. Therefore, if those rows change, then these pages must be removed from the cache. For that reason, database synchronization is an important feature. This means that when data changes in the database, these pages' output should be invalidated and should be removed from the cache. This capability allows you to automatically determine when certain pages should be removed from the cache.
One way to create this dependency is by specifying an SQL "select" statement (or a stored procedure call containing a select statement) that corresponds to the page in question, then mapping some of the page GET/POST parameters with parameters in the SQL statement. At run-time, the Web page parameters are used to execute the SQL statement and a SqlCacheDependency is created against a SQL Server 2005/2008 or Oracle 10g R2 or later database. Then when the corresponding row in the database changes, the database server fires a .NET event that's captured by the Web-cache server. Then the corresponding Web page output is removed from the cache (see Figure 3).
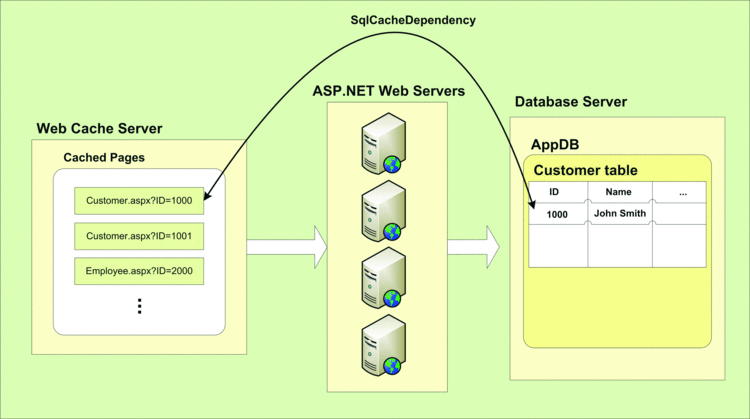
Figure 3 Page removed from Web cache if database row changes.
File Dependency
Another key feature is file dependency. You may associate a page output with a file in the system with the instructions: "If this file is ever updated or removed, please invalidate this page." Then the Web cache monitors that file, which is kept in a shared folder. If that file is ever updated or removed, the Web cache automatically invalidates the corresponding URL from the cache. This enables you to update that file from anywhere in your system, whether it involves another application or even a trigger in the database server based on when some related data changes. For example, if your data is stored on a mainframe rather than in SQL 2005/2008 or Oracle databases, you could use a file dependency to invalidate a cache page.
All this allows you to notify the cache when to invalidate if certain things happen in your data store or in your environment, which aren't directly accessible by the Web cache.
PDF Partial Content
Many people now access PDF files online. The common usage pattern is that they read one page at a time, going through the entire PDF file page by page. Few people download an entire PDF and then read it locally; most read it in their browsers. When they're viewing the information that way, they typically don't read the entire document; they abandon it after getting through some portion of it.
So serving the entire PDF is often a waste of resources; in fact could be the differentiating factor between acceptable and unacceptable performance during peak hours. For that reason, PDF Partial Content handling is an important feature in a Web cache. It reduces the bandwidth load on the Web server and improves overall scalability.
ViewState Caching
Among the most important features in ASP.NET is the ability to declare controls that run on the server and post-back to the same page. Prior to ASP.NET, in classic ASP, you ended up creating multiple pages to handle different operations that, logically, belonged to one page—for example, loading data, saving data or taking other actions. But in ASP.NET, you no longer have to do that. Form fields and other controls can now be declared to run on the server and the server simply posts the page back to itself.
To handle these post-backs, a ViewState is created that remembers the identity of the controls and any dynamic information assigned to these controls. In essence, ViewState preserves the state of a page's controls across multiple posts.
ViewState is important for ASP.NET applications. Essentially, it's information sent by the Web server to the browser so that the browser can send the same information back to the server the next time user does a post for the same page.
For example, you may load a customer on the customer.aspx page. Then, you make some changes in the customer data and click "Save." The Save button again calls customer.aspx, but also sends the ViewState so that the customer.aspx knows how to handle this post-back. The ViewState contains the information that customer.aspx had sent to the browser, and the post-back contains the new data that the user has perhaps modified. That allows customer.aspx to determine what changed and what to do about it. This is only a simple example; ViewState can also contain other dynamically created data for each control on the page.
Although ViewState is highly useful in ASP.NET, it also carries cost of transferring data back and forth from a Web server to the user's browser. This cost could have a performance and scalability impact during peak loads of the application and when the users are far from the Web server and across a slow Internet connection.
But the ViewState often doesn't have to travel all the way to the browser if it can be cached in the Web cache. In that case, only a tag or a unique ID could be sent to the browser so that if the browser comes back, the Web cache would re-insert a ViewState and give it back to the Web server based on the unique ID. All a Web server requires is that the next time the browser sends the request, it contains the ViewState from the previous time. It doesn't matter whether the ViewState reaches the browser because the browser never uses that information—only the Web server does.
In technical terms, a ViewState is used for post-back, so if you ever do post-backs, you'll need a ViewState, and a Web cache can cache a ViewState. That also saves considerable bandwidth, because a ViewState could be just a few kilobytes in size.
Gzip Compression
These days, most browsers can uncompress gzip-compressed content. But not all Web servers are configured to automatically compress Web pages' output. And even if compression is turned on, it consumes a lot of unnecessary CPU on each Web server, which is already being stressed by high traffic. However, if the compression is done by an intermediary proxy Web-cache server, it becomes more scalable.
It's easiest to compress static data that never changes. However, most pages in an ASP.NET application are dynamic and their content should only be compressed if the page output isn't changing every time. Otherwise, compression would put an unreasonable load on the CPU, perhaps dwarfing the gains in bandwidth usage. But because a Web cache is already intelligent about figuring out which dynamic pages output is cacheable (meaning that it doesn't change for at least a brief period of time), it's also able to automatically compress any cache pages. Then these cached pages are served to the clients multiple times in compressed form and considerably reduced bandwidth usage.
A typical gzip compression reduces the content by almost 80 percent, unless the content is already compressed (for example, PDF, JPEG, TIFF, etc.). A good Web cache should allow the user to specify which URLs to compress and which to ignore for compression.
Scalable and Dynamic Web-Cache Cluster
A Web cache is a server that sits in front of an ASP.NET Web farm (almost like an appliance). Today, ASP.NET Web farms can grow from two servers to 100-plus servers with a load balancer. Therefore, a single Web-cache server is unable to handle the load of a growing Web farm. A good rule of thumb is that for every five Web servers in the farm, you should have one Web cache server.
Having multiple Web-cache servers not only improves scalability, but also allows the Web cache to replicate so that if any one server goes down or is taken down, the cache isn't lost and there's no performance degradation (see Figure 4).
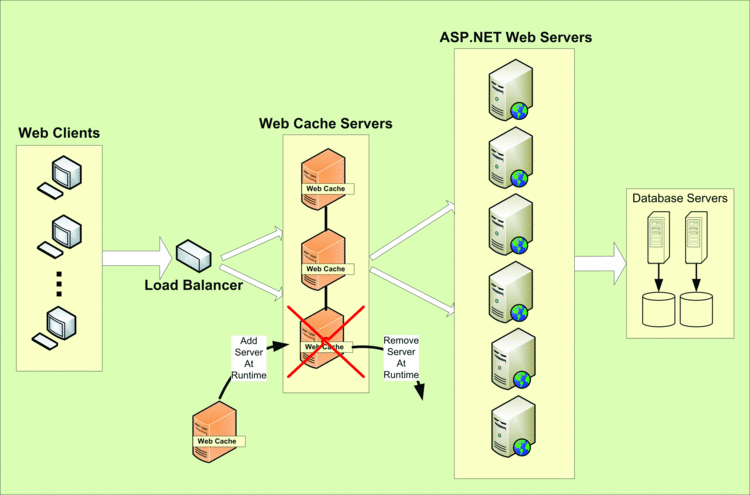
Figure 4 Dynamic Web-cache cluster (add or remove servers at runtime).
A good Web-cache server should be able to build a cluster of Web-caching servers to handle reliability through replication and scalability through multiple servers. However many Web caching-servers are involved, it's still considered one logical Web cache. Even if there are multiple copies of the cache in the cluster, they're always kept synchronized. In short, having a cluster of Web-caching servers allows you to scale while keeping the logical correctness of the cache.
Once you have a cache cluster, a good Web cache should allow you to specify different cache-storing options, also known as caching topologies. The main topologies include Replicated Cache, Partitioned Cache and Client Cache.
Replicated Cache means the entire cache is copied to each cache server in the cluster. As a result, each cache server has the entire cache. All "get" operations are always local to that box and, as a result, are very fast. However, updates are made to multiple cache servers, and if there are more than two such servers in the cluster, then the update cost grows.
On the other hand, Partitioned Cache breaks up (or partitions) the cache, storing each partition on a different cache server. The number of partitions equals the number of cache servers. This allows you to increase cache storage capacity by adding more cache servers, which you can't do in Replicated Cache. Partition Cache also allows you to create backups of each partition on a different cache server so that if any of those servers goes down, you don't lose the cache. Partition Cache is the most scalable caching topology for both storage and transactions per second.
Finally, Client Cache is a topology that is combined either with Partitioned or Replicated Cache (especially if the actual cache is hosted on a server other than the Web-cache server). Client Cache keeps a small subset of the cache within the client process so that the frequently used data is always available close by. What's kept in the Client Cache depends on what that client recently fetched. You can specify a maximum size for the Client Cache so when it reaches that size, it starts to evict (or remove) older items to make room for new ones. That way, the Client Cache never consumes more memory than what you have determined is feasible.
If you use multiple Web-cache servers without building a cache cluster, you'll end up with multiple disconnected copies of the cache. That outcome may be acceptable if your Web site is fairly static, but for dynamic Web sites and ASP.NET applications, that may cause data-integrity problems. Additionally, you'll end up sending the user request to the Web server even though another Web Cache server has the output of this page in the cache, thereby increasing the load on the ASP.NET Web farm.
Geographical Cache Distribution
Many ASP.NET application Web sites today have users worldwide even though the Web site itself is hosted in a single location. It's often impossible for the Web site to be located in multiple geographical locations because of the complexity and the cost of its infrastructure. For example, an ASP.NET Web farm also has to have a database server in the same location; database servers aren't usually ideal for geographical distribution when they involve highly transactional applications. As a result, end users experience slow performance because of wide area network (WAN) latency.
One way to remedy that problem is to place Web-cache servers in each geographical location, then route all the traffic from that area through the nearest Web-cache server (see Figure 5). Then if a Web-cache server doesn't have a page already cached, it directly sends the request to the main data center, where another set of Web-cache servers is located.
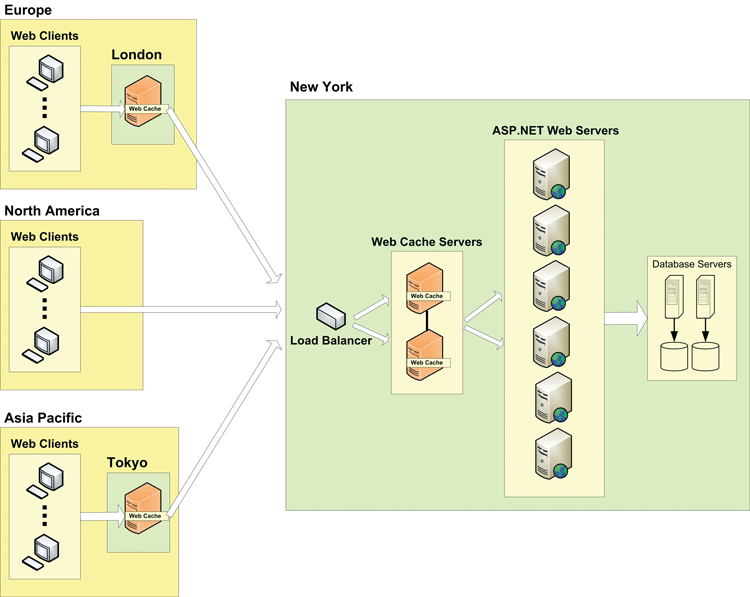
Figure 5 Web-cache server in geographically distributed environment.
So a good Web cache should have the ability to create a hierarchy of servers so that each Web cache knows where to route the request, even if it doesn't have the page cached.
Stay Away from the Database
As discussed in my June 2009 article, data doesn't change every time; it stays constant. Unfortunately, without distributed caching, you're going through unnecessary cycles to reproduce that same data over and over. But you don't have to go to the database all the time. It's the same data, so why go there? Why not take it from the cache?
Here is an example to highlight this issue. An airline's main web page isn't changing much; it can be cached for a long time. A customer visits to search for flights. The information is constantly shifting because as other users book seats, the information changes on the back end.
If the customer is searching for, say, a flight from New York to San Francisco, seat availability determines the results. Seat availability is based on the number of people already booked, with bookings happening constantly. A harried businessperson may complicate matters by inputting incorrect information or making multiple entries to assure a seat assignment.
The user receives results indicating that a particular flight is available, with that information changing in the cache every five minutes. But once the customer actually wants to reserve a seat, then a real-time check is performed in the database. That's because for every 1,000 people who check for flight availability, probably only about 10 actually make a reservation. It's fine to show flight availability to all those visitors, even though the information provided may not be entirely correct. In such situations, you can cache that page even if it's highly dynamic.
But you can cache it with the idea that it's acceptable to provide information with some risk that it's not completely accurate. However, on the reservations page in the database, it's critical to ensure that all information is accurate and up to date. The point here is that every application has common information that can be cached and a Web-site user doesn't have to be sent to the airline's database every time.
The easiest stage is when you want to cache all the images. You don't change your company logo or your president's picture or standard documents that you've got available for people to read. But then there are other portions that are more dynamic. That's where you can specify rules and say, for example, "I want to cache this page for this long."
With other pages, you might say, "I can't tell how long it's going to be cached, so I want to tie it to the database. If this row in this table changes, I want this page to be invalidated." That means removing it from the cache and reloading it, making a fresh copy. Every page category is different. As long as a Web cache allows you to determine how you want to cache pages, you're creating a situation in which the more you cache, the less you go to the Web farm.
Guidelines
In most cases, you can achieve significant benefits by deploying Web cache. If you've only got one Web server, chances are you don't have enough traffic to experience these types of problems. But if you got 1,000 or more users, you probably already have a load-balanced Web farm. In that case, you're a candidate for exploring ways to optimize performance and scalability.
Plan ahead. Don't wait for problems to occur because once they do, you'll be in panic mode. The best time is when you aren't facing any major issues—but at that point, you must be able to convince top management about why you require funding for such a project. One good way to accomplish that goal: Ask management what it might cost your business if your Web site provided painfully slow response times during peak hours (upward of 30 to 60 seconds per click). And what if your Web site went down for 30 to 60 minutes? Considering those questions can help convince your organization's executives about the need for a Web cache.
As previously noted, both free and commercially Web-caching options are available. With ASP.NET's growing popularity among developers, commercial Web-caching options that support .NET are now emerging. However, at this writing, most Web-caching products support Java and PHP. Most are software-based, but some hardware-appliance options are available as well.
As you consider your choices, stay focused on your organization and Web site. How dynamic is the site? How many users do you have? How much caching is going to really help you?
Then consider what caching features you need. As we've discussed, caching makes transactions blazingly fast and scalable. But it can sometimes give users outdated information. Keep that balance in mind as you consider various solutions.
Iqbal Khan is the President and Technology Evangelist of Alachisoft. Alachisoft provides NWebCache, which is a leading ASP.NET Web cache for boosting performance and scalability. Iqbal received an M.S. degree in Computer Science from Indiana University, Bloomington, in 1990. You can reach him at iqbal@alachisoft.com.