Web Infrastructure
Providing Scalability for ASP.NET Applications
Iqbal Khan
At a Glance:
- Scalability bottlenecks in ASP.NET applications
- Session-state storage options
- Available caching topologies
- Necessary distributed cache features
Contents
Where the Problems Are
Why These Problems Exist
What's the Answer?
Caching Topologies
Different Choices
The Real World
The popularity of ASP.NET, the Web application framework from Microsoft, continues to grow by leaps and bounds within the developer, enterprise, and IT ranks. There is one area of difficulty, however: scaling ASP.NET applications out of the box is simply not possible.
Scalability has two meanings in this context. First, you need to be able to effectively handle peak user loads because every application goes through peaks and valleys in terms of the number of users logged in at any point in time. When you design the infrastructure, you want to design the application so it can handle the peak loads as efficiently and as fast as nonpeak loads.
Second, you have to be able to increase the total capacity of your system. Today you may have only 5,000 users. Six months, a year down the road, you may have 10,000 or 15,000 or 20,000, and in a few years you could end up with 100,000 users. Being able to grow with the number of users without grinding the application to a halt is what scalability is all about. It means you are able to add more users without negatively impacting the performance in any noticeable way or, if there is any degradation, it should be within an acceptable range.
A typical ASP.NET application is deployed on one or more Web servers that are linked together in a Web farm, with a load balancer that distributes traffic to all the Web servers. In theory, the more Web servers you add, the more requests you should be able to process per second. The architecture of a Web farm is meant to give scalability to ASP.NET. That's the theory; the reality is a bit different.
The problem for ASP.NET applications is that while Web technology provides an elegant architecture of Web farms and load balancers, data storage technologies have not kept up. Certainly you can scale out in a Web application by adding more servers or by increasing the strength of individual servers with more memory and CPU power.
But as you do that, data storage is not able to scale in the same proportions. It does scale, but not as much as the Web application tier. Consequently, anything in your ASP.NET application associated with data storage or data access is a potential scalability bottleneck. More to the point, a database server does not scale for either sessions or applications data.
Where the Problems Are
Let's take a look at the different access or storage actions that take place within an ASP.NET application, starting with session storage. For every user request, a session is read from the storage at the beginning and written back to the storage at the end of the response. At the beginning of the user request, the page has to execute and, for that, it needs the session data. The entire session data, called a "session object," is loaded so that the page, while it executes, can reference that data. The page will read some of that data from the session object. It will put some more data into the session object. This all happens within the ASP.NET process and no session storage trips are being made.
When the page is done executing, some result needs to be sent back to the user. The session is probably updated during this time so that session now has to be saved back to the storage. It will be kept stored until the next user request for the same session and the same process repeats itself.
From a user's perspective, you click on a link; by the time the user sees the page that results from that link, a session has been read and a session has been written back to the storage once. So there are two trips to a session storage that the ASP.NET application has made.
Now you do the math. If you've got 10,000 users all accessing pages at the same time, you will have maybe 1,000 requests per second. Every user will be clicking something every few seconds, so every second you'll have at least 1,000 and probably more requests going to the Web farm.
Let's say 1,000 or more requests are going to the Web farm and every request going to the Web server results in two trips to the session storage. From a Web perspective, that means 2,000 trips to the session storage. You can see how quickly the load can increase. This is one place a scalability bottleneck can happen.
Scalability bottlenecks can also happen while a page is executing and needs to read or write some application data. Let's use airline flight availability as an example. The user clicks on a page to search for flights from one location to another, which can result in multiple read trips to the application database. Then, of course, the user wants to make a flight reservation, which requires some data be put into the database. This data is called "application data," and it is stored in the database; this save operation might make multiple database trips to store multiple data elements.
Thus, you could, in the end, wind up with the number of database trips being 5, 10, 15, or 20 times more than the actual number of user requests. So the stress on the database is that much more, and this can be a major bottleneck.
A third scalability bottleneck comes about if you are using an SOA (service-oriented architecture) environment and your application is making calls to another service layer, which could be within your data center or in a different data center.
The server layer architecture typically involves a server farm and is therefore scalable in the same way that Web application architecture is. But the service layer has the same scalability bottlenecks for the application because it relies on its own database.
So your application has dependencies on other services, which have dependencies on their databases, which in turn have scalability bottlenecks, and the chain is only as strong as its weakest link. If a service does not scale because of its database, your application cannot scale (see Figure 1).

Figure 1 The database becomes a bottleneck as the Web farm grows.
It doesn't really matter whether the database is a mainframe or a relational database. The data access or data storage simply is not able to scale, and it can't keep pace with the scalability of the Web technology. And these bottlenecks in the data storage prevent ASP.NET applications from scaling.
Why These Problems Exist
Why can't data storage scale? Let's first tackle the three session-state storage options Microsoft provides: InProc, StateServer, and SqlServer. InProc has limitations. It was designed to be used in a single-server, single-process environment, and it does not work in a multi-server or multi-process ASP.NET environment. The session is not retained.
Here's what happens. The user starts on one server, and the session is created there. If the load balancer then sends the user to a different server, the application won't find that session; it will think the user is starting fresh and ask her to log in again. Every time a user clicks on anything, she'll have to log in so she will not be able to proceed. The application will not work.
One way you can solve this is by using the "sticky sessions" feature, which lets you always route the user request back to the same server so the application will find that session on the server.
You can also handle InProc limitations by not creating a Web garden on the server. A Web garden is when your application has multiple ASP.NET worker processes running on the same server. If you avoid using a Web garden, there's only one process and that at least allows InProc to be used in a Web farm.
These two workarounds are far from ideal, however. Sticky sessions can cause a major scalability bottleneck because the load on some servers increases more than others because the length of a user session is not uniform. Some users log in for only one minute, others for 20 minutes. Some servers will get a lot of sessions, but those will be virtually empty or free or idle. Even if you add more boxes, you are not necessarily improving the throughput.
Moreover, InProc has memory limitations. Every session in your ASP.NET process requires memory. As you increase the number of sessions, the memory requirements of your worker process grow significantly. In a 32-bit platform, however, there is a 1GB memory limit for a worker process, and that's a problem. You cannot grow session data beyond what fits in a one gigabyte worker process memory, along with other data and application code. So InProc causes bottlenecks. And the more users you have, the more you will encounter these problems.
StateServer stores session state in a process that is separate from the ASP.NET worker process, but it too has limitations. You can configure it so that every Web server contains its own StateServer or you can dedicate a separate box and maintain the state completely in that box.
With the first option, the problem is you still have to use sticky sessions. Wherever the session was created, that's where you always have to go back to it. This first option only mitigates the InProc Web garden limitation. It doesn't resolve the sticky sessions problem that can leave you with extra boxes that don't get used even while others are clogged. The net effect to the user is that his session and response time become extremely slow.
The other drawback to this configuration option is that if any Web server goes down, the StateServer on that Web server box also goes down, so you lose all those sessions. True, you don't lose all the sessions in a Web site, but you do lose any sessions stored on that box, and that's not acceptable. Ideally, you never want to lose any sessions.
If you choose the other configuration StateServer offers—a dedicated StateServer box—you no longer have to use a sticky session because every Web server goes to the same dedicated box. But now you have a bigger problem: if that box ever goes down, the entire Web farm is down because every Web server is trying to get its session from that box.
That's not all. This dedicated StateServer box gets overwhelmed as more Web servers are added and transactions per second escalate. Consequently, it quickly becomes a scalability bottleneck. So the scalability issue is not solved with StateServer, not with either configuration.
Now we come to SqlServer, which stores session state in a SQL Server database and can be thought of as a dedicated StateServer. This is Microsoft's premier database server designed for high transaction environments. It is more scalable than a StateServer because you can create a cluster of database servers.
In SqlServer configuration, all the Web servers actually connect to a dedicated SqlServer box where all the sessions are stored. It's as if each of the Web servers were connected to a dedicated StateServer box. The concept behind this is that SqlServer will be more scalable than a StateServer. But SqlServer is not as fast as a State Server because a StateServer is an in-memory data store and accordingly, has acceptable performance. On the other hand, SqlServer is not an in-memory data store. It is a disk-based data store. All databases are kept on disk because they grow so large that memory is not sufficient to hold the entire database. Thus, a database stores its data on persistent storage, which is a disk. Due to disk storage, SqlServer performance is not as fast, resulting in a performance drop.
SqlServer can come in multiple configurations. In a standalone configuration, which is the most common, there is only one database server that all the Web servers talk to, and as you grow the size of the Web farm and add more Web servers, you put more and more load on the database (see Figure 2).
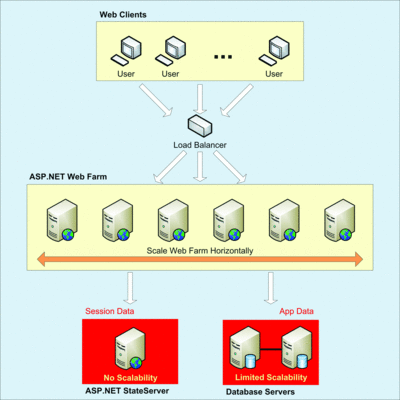
Figure 2 ASP.NET sessions still a bottleneck and database also not fully scalable
Plus, you have a performance issue because SqlServer isn't based on memory, and you have a scalability issue because it's not able to scale out as much. You could scale up by making the hardware more powerful by adding CPUs to that box, but you cannot keep adding more database server boxes as you grow the Web farm. You can maybe go from one to two or two to three servers so that SqlServer provides a database clustering capability, which does scale to be more than a StateServer, but it also has its limitations.
The other problem SqlServer storage has is that all of the sessions are kept in a single table. The locking contention for concurrent access and concurrent updates of the session data becomes obvious as soon as you scale up. As you have more and more transactions per second, you have more and more lock delays because everything is kept in one table.
So, while SqlServer scales more than State-Server, it hands you a performance problem and doesn't scale sufficiently. Moreover, it does not scale linearly. You are supposed to be able to grow a Web farm from a 5- to 50- to 100-server farm, and the Web farm itself is supposed to grow quite smoothly; however, the data access does not grow correspondingly. As I noted earlier, a database is one of those data storage accesses that does not grow, so storing sessions in a database doesn't make any major improvement. It's only an incremental improvement over a State-Server environment. Moreover, a SqlServer becomes a bottleneck for application data as well as for sessions data. Hence, a database server does not scale for either sessions or applications data.
What's the Answer?
The solution is an in-memory storage mechanism, so it can be extremely fast, as fast as a StateServer. However, it should be virtually linearly scalable. Linear scalability means that as you add more servers, you are almost multiplying the capacity. For example, if you could handle 10,000 transactions per second with one box, adding a second box should give you close to 20,000 transactions per second total. Note that "virtually linear" doesn't mean exactly 20,000—it could be 19,000; it won't, however, be 12,000 or 15,000. And this is what we need: storage that can grow almost linearly, and it should also be in memory.
Because of these two needs, we are not talking about persistent storage, which has other requirements and is intended for the long term. A database is intended for long-term storage, while in-memory storage is always transient and temporary. But our needs are temporary. We only need to store data in this temporary storage during a user session or perhaps for the duration of an application, a few hours to a few days, or maybe a few weeks at most. Then that data can go away because there is always permanent master storage, which is the database where we can load the data from again.
So, with all of this in mind, we can think of a storage mechanism called a "distributed cache," a concept that has become popular because it provides the benefits cited above, as Figure 3 shows.
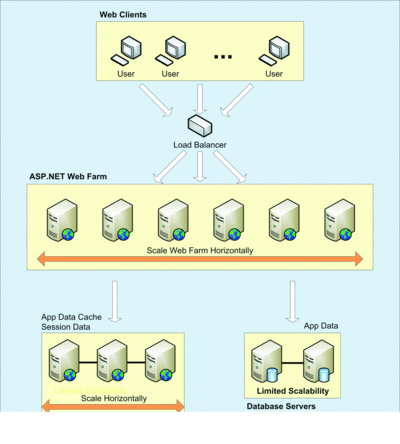
Figure 3 Distributed cache relieving pressure on the database server
A distributed cache is in-memory, so it is fast, and it is designed to distribute growth fairly linearly, especially if you have the right distribution mechanism (also called caching topology).
A distributed cache must provide high performance and linear scalability, and since it exists in-memory, it must provide replication so that if any machine goes down (the memory in that machine becomes available), another machine will have the data and you won't lose any. Replication provides more than one copy of the same data in different locations on different boxes and by doing that, you achieve 100 percent up time for the duration of your data storage.
A distributed cache stores a .NET object or a Java object or, for that matter, any other data like an XML document. It stores data in a prepared format. It does not have the concept of tables and rows and primary keys and foreign keys that a database has. For programmers, a distributed cache is essentially a HASH table, where there is a key and each key has a value and that value is an object. You need to know the key, and based on the key, you can fetch the object you want. This is one logical cache that can span multiple servers. You can add servers at the same time to grow cache cluster size, and you can remove boxes at the same time to shrink the cache cluster without stopping anything.
Caching Topologies
The various topologies that an effective cache should provide are replicated, partitioned, a hybrid of replicated and partitioned, and client or local cache. The idea is to have different caching topologies for different types of usage, making the cache extremely flexible. A replicated topology replicates the cache many times, depending on how many times you need (see Figure 4). It is intended for situations where you have a read-intensive cache usage, but not a lot of updates.

Figure 4 The replicated cache is ideal for read-intensive usage
A partitioned cache is the highly scalable topology for update-intensive or transactional data that needs to be cached. This could be ASP.NET session data, which is very transactional. As mentioned earlier, for every Web request, the session is read once and updated once, so it has an equal number of reads and writes.
A partitioned topology (see Figure 5) is excellent for environments where updates must be done at least as many times as you are doing reads, or fairly close to that. In this topology, the cache is divided. As you add more and more cache servers, the cache is further partitioned in such a way that almost one Nth (N means the number of nodes) of the cache is stored on each cache server.

Figure 5 A partitioned cache is ideal for write-intensive usage.
A third topology is a hybrid of the partitioned and replicated versions. You can partition the cache and, at the same time, every partition can be replicated. Hence, you achieve the best of both worlds. You'll be able to partition and grow, plus you can replicate for availability to make sure that no data is lost (see Figure 6).

Figure 6 Partition-replica caches are ideal for write-intensive usage with reliability.
With the help of partitioned and partitioned-replication hybrid topologies, you can grow your cache linearly in terms of scalability.
A client or local cache is the fourth highly useful topology that sits on the application server. This type of cache is very close to the application and can even be InProc. It's usually a small subset of the actual large distributed cache and is based on whatever the application at that moment in time has been requesting. Whatever the application requests, a copy is kept in the client cache. The next time that application wants the same data, it will automatically find it in the client cache. It won't have to go to distributed cache, to save even that as a trip, because the distributed cache is often across the network on a separate caching server or cluster of cache servers. A client cache gives you an additional performance and scalability boost.
The data in a client cache must be kept synchronized with the distributed cache. If that same data is changed in the distributed cache, the distributed cache has to synchronize that change with the client cache. This is an important aspect—you don't want to have just a local cache that is totally disconnected. That's just the equivalent of an InProc cache, which is unacceptable because you have data integrity problems. You have multiple copies of the same data that gets out of sync.
Different Choices
There are multiple distributed caching features available... And, as in most situations, free solutions provide a more limited feature set while commercial ones offer a lot more options and features.
Aside from high performance, scalability, and high availability, an efficient distributed cache must include several key features to help you to keep the cache fresh and synchronized with the master data source, whether database or mainframe. The cache should have an expiration option so you can tell it to perform automatic expiration, which may be either an absolute time or what's called "sliding time." Basically, that's idle time; if no one uses the data, it is automatically expired.
A cache should also be able to manage relationships between different types of data. Most data is relational. For example, if you've got a customer, you have orders for that customer so there is a relationship between customer data and order data. If you cache both customer and order data and you inadvertently delete the customer data from the cache, it makes sense that the order would be automatically deleted. In this instance, you don't know if you removed the customer data from the cache or you permanently deleted it. In case you permanently deleted it, the order is also invalid now because the order has to be from a valid customer.
There are other similar types of relationships that must be managed in the cache. If the cache doesn't do it, then the application has to keep track and that is very cumbersome. A Microsoft cache object in ASP.NET that is very useful is called a "cache dependency concept." One cached item depends on another one. If that other cached item is ever removed from the cache or even updated, the first cache item is removed as well. This is a powerful cache dependency concept that should be available in all caches that cache relational data.
Synchronizing with the database is another important ability for the cache. A database is usually shared by multiple applications. If an application using the cache is the only one updating the database, you probably don't need the database synchronization feature. But quite often, other applications, sometimes third-party applications, are updating data in the database because the database is a shared, common store and those applications are not using your cache. They may not even be .NET applications. They may be third-party applications you don't control, but they are updated in the database. So you have to allow for situations where the database might be updated outside your application, but some of that data that has been updated in the database is also cached. Therefore, the cache has to be able to synchronize. It has to be able to know whenever the data it has is no longer the same in the database. It must remove that data from the cache and maybe even reload the latest copy from the database. Database synchronization can be done either through events fired by the database server or by the cache polling the database. Events are of course more real-time, and polling has a slight delay. But polling can be more efficient if a lot of data is changing.
Event notification is among the most important features an effective distributed cache should have. A cache is often shared among multiple applications and even within an application among multiple users. Therefore, the cache should have an event notification mechanism in case, for example, a cached object is updated or removed. If your application is using that same data, you may want to be notified so you can reload either from the database or a new copy from the cache itself. A notification mechanism improves collaboration among multiple users or multiple applications through the cache.
The Real World
IT management faces all the performance issues associated with databases, and in the case of bottlenecks, if you're lucky enough to be able to report them to developers, they may attempt to resolve them. Unfortunately, development isn't always in-house. Often you are living with and managing a third-party application.
In any case, the best place to start implementing distributed caching to open bottlenecks and turbo-charge your applications is with ASP.NET Session storage, because you don't need to depend on developers. There's no programming involved. It's a simple matter of replacing existing Session storage with an in-memory distributed cache. Furthermore, implementing a distributed cache for ASP.NET Session storage gives you the opportunity to see the benefits that accrue for performance and scalability, and then you can decide whether to do the same for your application data.
To experience the scalability improvement, you either have to run distributed cache storage in production or you have to simulate that load in your test environment. You may have access to QA, which can help perform a stress test in a test environment to simulate a large load before putting a distributed cache in production. Most IT managers would probably not be comfortable putting a distributed cache in production unless they had tested it first in their QA environment, even if they couldn't simulate the same amount of load. So that's a good place to start.
Once you're up and running with a distributed cache and reaping its benefits, you can share your new ASP.NET Session performance and scalability findings with your in-house or third-party-vendor development team. With the hard evidence in hand, you can ask the development team to analyze areas where they can cache application data in this distributed cache as well.
Caching application data provides a further boost and in many cases a lot more boost than simply using a distributed cache for ASP.NET Session storage. The developers would be able to identify all the data elements that are read more frequently than they are updated. Even transactional data (such as customers, orders, and the like) is a good candidate for caching, even if it remains in the cache for a few minutes before expiring. This is because within this brief period of time, the data may be reread many times, and if this rereading is from the cache and not from the database, it relieves your database of a lot of read load.
However, for developers to cache application data, they'll have to do a bit of programming by making API calls to the distributed cache. The idea is very simple. Whenever their application tries to fetch data from the database, it should first check the cache. If the cache has that data, the data is taken from the cache. Otherwise, the application fetches the data from the database, caches it, and then gives it to the user. This way, the data will be found in the cache the next time it is read. Similarly, whenever data is modified in the database, it should also be updated in the cache. And, if the cache lives on multiple servers, it must therefore be synchronized automatically to ensure that if your application runs in a Web farm, the same cache data is accessible from all servers in the farm. For more information on the topic of how to develop an application that uses a distributed cache for better scalability, look for my upcoming article in the July issue of MSDN Magazine.
Iqbal Khan is the President and Technology Evangelist of Alachisoft, the company that provides NCache—the industry's leading .NET distributed cache for boosting performance and scalability in enterprise applications. Iqbal received an MS in Computer Science from Indiana University, Bloomington, in 1990. You can reach him at iqbal@alachisoft.com.