SQL Server
Understanding SQL Server Backups
Paul S. Randal
At a Glance:
- Full backups
- Transaction log backups
- Differential backups
- Backup strategy planning and backup integrity
Contents
Full Backups
Differential Backups
Transaction Log Backups
Backup Strategy Planning
Backup Integrity
Summary
Do you really need to take SQL Server backups? Yes. Unless you don't care about your data or you don't mind having to completely recreate your database in the event of a disaster, you need some way of restoring the database to a usable point. Some people argue that having a redundant copy of the database somewhere else removes the need for having backups, but what if that copy is damaged or inaccessible? Backups are still required to make sure you can always recover.
But what kind of backups should you take? How often should you take them? What effect will they have on the database and workload? And how do you make sure they are valid?
Putting together a backup strategy is actually easier than you may think, even though the BACKUP and RESTORE commands have a plethora of options. And I'll help you figure it all out.
This is the first article in a three-part series. Here in Part 1, I cover backups. In Part 2 (September 2009 issue), I will discuss recovering from a disaster using backups. And in Part 3 (November 2009 issue), I'll look at recovering from a disaster without backups. I'm going to go a little deeper than usual in these articles, but you should be able to follow along with the help of the background material.
In this month's article, I'll explain the basics of how the various types of backup work and how you may want to use them in a backup strategy. It will help if you have some knowledge of how the transaction log works (see my article "Understanding Logging and Recovery in SQL Server." There's no point in having backups if they turn out to be corrupt when you try to use them, so I'll also explain how to add some integrity checks to them. Along the way I'll debunk some of the common misconceptions and provide links to further information.
One thing I'm not going to do is explain how the BACKUP syntax works and how to perform the various backup types. SQL Server Books Online has excellent sections that cover this so why waste space duplicating it here? See the topic "Backup (Transact-SQL)" for more info, especially the Examples section at the end. The topic "Backing Up and Restoring How-to Topics (SQL Server Management Studio)" explains how to use the tools to perform backups. It's best to review the how-to after reading this article, as here I'm going to explain the what and the why.
The implementation of your backup strategy is the relatively easy part. Designing an effective strategy is the very important, though often overlooked, part.
Full Backups
The simplest kind of backup is a full database backup. It's also possible to do a full backup of a single data file or filegroup. However, these are not commonly used and as all the principles discussed apply to them, too, I'm going to focus on database-level backups. But as of SQL Server 2005, each of the more granular backup types work exactly the same (this was not true in SQL Server 2000). The same applies to differential backups—they can be performed at the file, filegroup, or database level—but these all work in the same way, as well, regardless of the component being backed up.
A full database backup provides a complete copy of the database and provides a single point-in-time to which the database can be restored. Even though it may take many hours for the backup process to run, you can still only restore the backup to a single point (effectively at the end of the backup, but I'll discuss exactly what that point is later in this article). A full backup does not allow recovery to any point in time while the backup was running. This is also the same for differential backups.
There is a misconception about this, however, fuelled by the fact that you can use the WITH STOPAT=<a time or log sequence number> option on a restore of full and differential backups. Although the syntax allows it, the option has no effect and is just there for convenience.
Another misconception about full backups is that they only contain data. Both full backups and differential backups also contain some transaction log records so that the restored component (database, file, or filegroup) can be made transactionally consistent.
Consider an example transaction that inserts a record into a table with a single nonclustered index. The pages of the table and index are spread through the data file. The transaction is split into two parts internally: a record insertion into a data page in the table and then the insertion of the required record in an index page in the nonclustered index. If the backup process just happens to read the nonclustered index page before the record insertion, but reads the table data page after the record insertion, then the database represented by just the data in the backup is transactionally inconsistent.
This is where the transaction log comes into play. By also including some transaction log records in the backup, recovery can be run on the restored copy of the database, making it transactionally consistent. For this example transaction, depending on when it commits, the recovery part of restore may roll it forward (meaning it will appear as committed in the restored copy of the database) or roll it back (meaning it will not appear at all in the restored copy of the database). In either case, transactional consistency is maintained, which is crucial.
A full backup does the following:
- Force a database checkpoint and make a note of the log sequence number at this point. This flushes all updated-in-memory pages to disk before anything is read by the backup to help minimize the amount of work the recovery part of restore has to do.
- Start reading from the data files in the database.
- Stop reading from the data files and make a note of the log sequence number of the start of the oldest active transaction at that point (see my article "Understanding Logging and Recovery in SQL Server" for an explanation of these terms).
- Read as much transaction log as is necessary.
Explaining how much transaction log is necessary is best done with the visual aid in Figure 1. The red numbers on the timeline are explained in this list:
- Checkpoint and begin reading from the database.
- The read operation reads page X.
- Transaction A starts.
- Transaction A makes a change to page X. The copy in the backup is now out of date. Note that the backup will not read page X again—it's already passed that point in the database.
- Transaction B starts. It does not complete before the data read operation completes.
- Transaction A commits. This commits the changes to page X.
- The backup data read operation completes and transaction log reading starts.
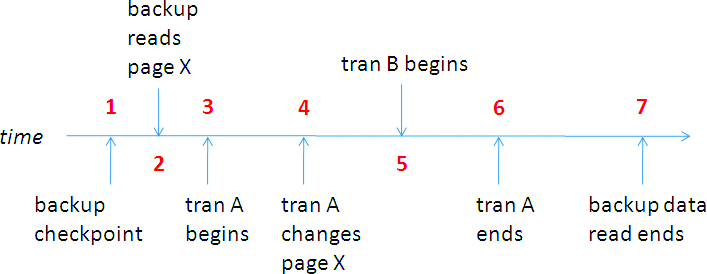
Figure 1 Example Timeline of Changes During a Full Backup
Backing up enough of the transaction log is required so that recovery can successfully run during the restore and so that all pages in the database are at the same point in time—the time at which the data reading portion of the backup operation completed (Point 7). The transaction log from the beginning of the oldest active (or uncommitted) transaction (Point 5, Transaction B) to the end of the backup (Point 7), is required to allow recovery to run. The transaction log back from the backup checkpoint (Point 1) to the end of the backup (Point 7) is required to allow all pages to be brought to the same point in time.
If the transaction log was only included from the beginning of the oldest active transaction (Point 5), then the copy of page X that was restored from the backup read at Point 2 would not be updated with the changes from transaction A, which occurred at Point 4. This means that it would not be transactionally consistent with the rest of the database as of the time the read data operation completed (Point 7).
So, the minimum log sequence number (LSN) of the transaction log that is included in the full backup is MIN (LSN of backup checkpoint, LSN of oldest active transaction) and it could be for a transaction that began even before the backup began. This ensures that the restored copy of the database (or whatever you restored—page, file, filegroup, database) is completely consistent.
This mechanism means that transactions are not paused in any way by backup operations, although the extra I/O workload on the database may slow them down somewhat. The downside of this mechanism is that the transaction log cannot be cleared for the duration of the full backup because it is required. If there's a lot of update activity and the full backup takes a long time to complete, this could lead to transaction log growth—a problem that I've already discussed in several previous articles and in the SQL Q&A column.
The data contained in a full backup is not necessarily all of the contents of all data files. The backup will only contain the allocated pages from the data files. For example, a single-file database may be 100GB but only contain 15GB of allocated data. In that case, the full backup will only contain the 15GB of allocated data plus the necessary transaction log. (However, the restored database will always be the same size as the original—in this case, 100GB.)
Another misconception is that the backup process examines or changes the data it is backing up. This is untrue, except for in a single case when backup checksums are enabled, which I'll explain shortly.
Differential Backups
The other type of data backup is a differential backup. A differential backup performs the same operations as a full backup, but only contains all the data that has changed or been added since the previous full backup. A common misconception here is that differential backups are incremental. They are actually cumulative and successive differential backups after a full backup and will increase in size as more data is changed or added.
In every 4GB section (called a GAM interval) of every data file there is a special database page called a differential bitmap that tracks which portions (called extents) of that 4GB section have changed since the last full backup, indicating data that has changed or been added to the database. (There are several other allocation bitmaps, too, and you can find more information about these in my blog article "Inside The Storage Engine: GAM, SGAM, PFS and other allocation maps").
A differential backup scans through these bitmaps and only backs up the data file extents that are marked as changed. The bitmaps are reset by the next full backup, so you can see that as more and more of the database changes, more of it will be marked in the differential bitmaps and successive differential backups will be larger and larger. Eventually, if most of the database has changed, a differential backup may become as large as the full backup. You can find out how large your next differential backup will be using a script I wrote that is available from my blog article "New script: How much of the database has changed since the last full backup?." Incidentally, this script can also be used to get an idea of the churn rate of a database—for instance, on a SharePoint content database.
As a side note, if you want to take an ad-hoc full backup and not have it reset the differential bitmaps, you should use the WITH COPY_ONLY option on the BACKUP statement. This is very useful, as otherwise the next differential backups would be based on the ad-hoc full backup you took, instead of on the regular (probably scheduled) full backup. This could lead to big problems when you try to restore in a disaster situation.
So why are differential backups useful? As I'll discuss in the backup strategy section, differential backups can really speed up restore operations by allowing many transaction log backups to be skipped in the restore process. It's much faster to essentially jump forward in time using a differential backup than to have to replay a lot of transaction log records to get to the same point in time.
Transaction Log Backups
Transaction log backups are only possible in the FULL or BULK_LOGGED recovery models, whereas full and differential backups are also possible in the SIMPLE recovery model.
A transaction log backup contains all the transaction log records generated since the last log backup (or full backup that starts a log backup chain) and is used to allow the database to be recovered to a specific point in time (usually the time right before a disaster strikes). This means they are incremental, unlike differential backups, which are cumulative. Since these are incremental, if you want to restore the database to a particular point in time, you need to have all the transaction log records necessary to replay database changes up to that point in time. These are contained in the log backup chain.
A log backup chain is an unbroken series of log backups that contain all the transaction log records necessary to recover a database to a point in time. A chain starts with a full database backup, and continues until something breaks the chain, thus preventing more log backups being taken until another full (or differential) backup is taken.
Operations that break the log backup chain include switching to the SIMPLE recovery model, reverting from a database snapshot, and forcibly clearing the log using the WITH NO_LOG or TRUNCATE_ONLY options (which are not available in SQL Server 2008). It is inadvisable to break the log backup chain, as it forces another (potentially large) full backup to be taken.
Although a log backup chain stretches back to a full backup, you don't necessarily need to restore all those log backups during recovery. If you took a full backup, say, on Sunday night and on Wednesday night, with log backups every half hour since Sunday night, then restoring the database after a disaster on Friday could use Wednesday's full backup plus all the log backups since Wednesday night instead of having to go all the way back to Sunday night's full backup. (The second article in our series will go deeper into this topic.)
Log backups are also required to help manage the size of the transaction log. In the FULL or BULK_LOGGED recovery models, the log will not clear until a log backup has been performed (see the February article for details of what log clearing means), so regular log backups must be performed to prevent the log file from growing out of control. If the log cannot clear, the log will grow until it runs out of space. As such, if you don't want to do point-in-time recovery using log backups, the easiest option is to switch to the SIMPLE recovery model and not use the FULL or BULK_LOGGED recovery models. I discuss this in more depth in the blog post "Importance of proper transaction log size management."
There is a special case in logging that improves performance by allowing some operations to run as minimally-logged operations, where only the page allocations are logged, not the actual insertion of data. This can improve the performance of operations such as bulk loads and index rebuilds. In these cases, not everything about the operation is logged, so the backed up log records don't contain enough information to completely replay the operation. In that case, how can restore and recovery possibly work if there isn't enough information?
The answer is that the first log backup following a minimally-logged operation will also contain some data. Just like the differential bitmaps I mentioned earlier, there is another bitmap called the minimally-logged bitmap (sometimes called the bulk-changed map). This bitmap tracks which extents of a data file have been changed because of a minimally-logged operation.
The log backup following a minimally-logged operation will scan through these bitmaps and also back up those data extents that are marked as having changed. The bitmaps are cleared after being scanned. This means that the log backup has enough information to completely replay the effects of the minimally-logged operation in the database, when the log backup is restored. There's a twist though: There's nothing in that log backup that says when any particular data extent was changed. So a log backup that also contains data from a minimally logged operation cannot be restored to any point in time except the end of the time period covered (or beyond, if the log backup is part of a log backup chain that you're restoring from). So, while you can get performance improvements when switching to the BULK_LOGGED recovery model, you must consider changing to it as a temporary operation—just to improve your batch process and once the batch process is complete, you should switch back to FULL and perform a log backup as soon as possible.
There is also a special case log backup to allow the log to be backed up after a disaster that damages the data files. This is called a tail-of-the-log (or tail-log) backup, where the data files can be damaged or destroyed, but all the transaction log leading up to the disaster point can be backed up. This allows minimal work loss (called up-to-the-minute recovery) when the database is subsequently restored; however, it is supported only when the database is running in the FULL recovery model. More information on these and restrictions with minimally logged operations can be found in the Books Online topic "Tail-Log Backups." The first screen cast that accompanies this article shows me demonstrating tail-of-the-log backups.
In versions of SQL Server prior to SQL Server 2005, transaction log backups could not be performed concurrently with full database or differential database backups—they would block until the database-level backup completed. File and filegroup-based backups did not cause log backups to block. While this complicated the recovery process for file and filegroup backups, it gave them an advantage by not blocking log backups. In SQL Server 2005, all full and differential backups (regardless of component) work in the same way. The behavior now is that the concurrent transaction log backup completes, but the transaction log is not cleared until the full or differential backup (that requires the log) also completes.
Backup Strategy Planning
Now that you know about the three types of backups and how they work, I'll show you how you might put them together into a backup strategy.
A common question I get is how to start thinking about a backup strategy. I always like to say that you shouldn't design a backup strategy. You should design a restore strategy—that enables you to restore as little as possible in the event of a disaster so your downtime is as small as possible while still preserving your data. After you've worked that out, then work out what backups you need so you can perform the restores you need. In other words, your backup strategy should allow you to meet your Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
With a strategy that only includes full backups you're somewhat limited in what you can do with restores. Basically, you can only restore to the time of each full backup, as in Figure 2. If disaster strikes at 23:59 on Saturday, just before the next full backup is scheduled, then all the work since the last full backup might be lost. For this reason, if data-loss needs to be avoided and the data cannot be recreated, log backups are also included, as shown in Figure 3.

Figure 2 Backup Strategy with only Full Backups

Figure 3 Backup Strategy with Full and Log Backups
Imagine that the log backups are being taken every 30 minutes. As long as all the backups are available, this means that the database can be restored to any point in time. However, this still may not be the best strategy. What if disaster strikes at 23:59 on Saturday with this strategy in place? First thing would be to take a tail-of-the-log backup and then start restoring.
To restore the database up to the point of the disaster would mean restoring last Sunday's full backup and then 336 log backups (that's six days of 48 log backups per day, plus 47 on Saturday plus the tail-of-the-log backup). Depending on how much churn there was in the database over the week that could be a huge amount of transaction log that will take a very long time to replay. That's clearly not an optimal restore strategy—but it's a common strategy I see in the field. If you have a strategy like this, make sure that you've practiced doing a restore so you know whether you can meet your RTO in the event of a disaster.
To mitigate this problem, some strategies use more frequent full backups—but these might be prohibitively large to take every day, for instance. The alternative is to use differential backups, which only contain the data that has changed since the previous full backup. Continuing our example, that strategy is illustrated in Figure 4.

Figure 4 Backup Strategy with Full, Log, and Differential Backups
With this strategy, recovering from a disaster at 23:59 on Saturday is a lot faster. Remember that a differential backup is cumulative—so the restore strategy is the Sunday full backup, the 00:00 Saturday differential backup, plus all the log backups from Saturday. Having the differential backup from 00:00 Saturday means that all the log backups before that can be skipped, as the differential backup contains the same as the net-result of restoring all those log backups.
This was a pretty simple and contrived example, but it clearly shows the benefits of each backup type. Once you've designed your backup strategy, make sure you test it to ensure that it allows you to perform your desired restores.
Here's an example that I saw a customer face a few years back. A customer had a corrupt database and wanted to recover with zero data-loss. They were reluctant to use their backups and tried running repair on a copy of the database, but it had to delete data, forcing them into using their backups. It turned out that they had a full backup from January plus a log backup every half-hour up to April—over 5,000 backups in total and all on tape! I'm sure you're rolling your eyes and thinking "I bet it didn't work," but in fact it did; however, it took three days to do it! The customer thought they had a great backup strategy—FULL recovery model plus log backups—but their backup strategy didn't allow them to do the restores that they wanted.
Backup Integrity
There's no point in having backups if you find that they're corrupt when you try to restore from them. Of course, the best way to check the validity of your backups is to restore them on another server, but in SQL Server 2005 a new feature was introduced that allowed some backup integrity checks to be performed without having to actually restore them. You can use the WITH CHECKSUM option when taking a backup (of any variety).
This creates a checksum over the entire backup stream, which is stored in the backup itself. If the backup is a full or differential, and the database has page checksums enabled, then this option will also cause all existing page checksums to be tested as the backup process reads the pages. If a bad page checksum is found, the backup operation will fail. This offers great protection against accidentally backing up a database that's already corrupt in some way. (You can find more information about page checksums in the "Top Tips for Effective Database Maintenance" article from August 2008.)
Once the backup has completed, it can be verified using a command like the following:
RESTORE VERIFYONLY FROM <backup device(s)> WITH CHECKSUM
This will recalculate the checksum over the entire backup stream and compare it against the one stored in the backup. For full and differential backups, it will also test any page checksums on pages in the backup. If any problems are found, then you know that backup has been corrupted in some way.
Naturally, there are the exceptions to the rule, where you may want to back up a corrupt database (if it's the only copy of the database you have and you're going to have to run repair, for instance). In that case, you can force the backup to complete using the WITH CONTINUE_AFTER_ERROR option.
You can find more information on backup validation on information on backup validation on my blog and also watch me demonstrate some aspects of backup validation in the second screen cast that accompanies this article.
Summary
As with any complex topic, there are lots of areas of backups that I didn't have space to cover, but now that the basics are covered, you can dive into some of the Books Online and blog links for deeper information. The best place to start in Books Online is the topic "Backup Overview (SQL Server)." On my blog, you can start with the Backup/Restore category.
One area that you may think is conspicuous in its absence is backup compression. This is deliberate as I'll be covering it later in the year in an article on all the new compression technologies in SQL Server 2008. In the meantime, you can check out the Books Online topic "Backup Compression (SQL Server)" and also on my blog.
If I had to sum up this article in three bullet points, they would be:
- Make sure you have backups.
- Make sure you have valid backups.
- Make sure you have the right backups.
In other words, take backups if you want to be able to restore your database, do something so you know the backups will work when you need them to, and make sure you can restore from your backups and meet your RTO and RPO.
In the next article, I'll explain all about restoring from your backups, including the different kinds of restore operations and how they work, restoring from multiple backups, and partial database availability.
In the meantime, and as always, if you have any feedback or questions, drop me a line at Paul@SQLskills.com.
Paul S. Randal is the Managing Director of SQLskills.com, a SQL Server MVP, and Microsoft Regional Director. He worked on the SQL Server Storage Engine team at Microsoft from 1999 to 2007. Paul wrote DBCC CHECKDB/repair for SQL Server 2005 and was responsible for the Core Storage Engine during SQL Server 2008 development. Paul is an expert on disaster recovery, high-availability, and database maintenance and is a regular presenter at conferences around the world. He blogs at SQLskills.com/blogs/paul.