Building COM Components on UNIX
Christian Gross
euSOFT
July 1998
Christian Gross is a partner at euSOFT, a firm that offers Internet consulting and training to enterprise customers, specializing in architectural issues. He speaks frequently at Microsoft conferences such as the Visual C++ DevCon, Developer Days, Tech Ed, and PDC. He has written numerous articles for MIND, Basic Pro, and other programmer publications, as well as white papers for Microsoft.
Summary: Discusses DCOM on the UNIX platform. Knowledge of COM and UNIX necessary. (18 printed pages) Covers:
- Platform compatibility issues
- The UNIX-specific architecture of DCOM
- Implementing a DCOM component on UNIX
Introduction
Developing Component Object Model (COM) components on Microsoft® Windows® is a widely known process. It is something that we are accustomed to. It can be a simple process or more complicated one, depending on the sophistication of the COM component itself. The COM run time makes it possible for one component to communicate to another component. It is the "middleware," making it possible to create a component that can communicate from one thread to another, from one process to another, or from one machine to another. In other words, anywhere, anyhow, anytime access. While this may seem like nirvana, there is a problem in that it works on Microsoft Windows only, and the world is not only a Microsoft Windows world. It is heterogeneous, filled with many types of computers that perform different functions. Computers must have the ability to interoperate with other computers.
Times change, and things go in and out of fashion. This is a basic fact of humanity. But change costs money. The real question is how to make change economical. One way is through incremental change. While this may not be the most exciting way of doing things, it is preferred because whenever an incremental change is made the best technology at the time can be used. And that is the purpose of Distributed COM (DCOM) on UNIX or on any other platform. It allows the developer to choose when to move an application or component from one platform to another. During this period of change, the system is still running because DCOM is used as the middleware on the various systems. Therefore, incremental changes made with DCOM are very economical, because of its ability to interoperate with a number of different platforms.
The purpose of this article is to discuss DCOM on UNIX. While there are other implementations on other platforms, the focus of this article is UNIX. It is assumed that the reader is somewhat knowledgeable about COM. If not, at the end of the document are a series of URLs that can be used to build a basic knowledge of COM and DCOM. The article begins by examining how DCOM fits into the overall architecture. Then some basic questions about DCOM on UNIX are answered. The next section discusses the architecture of DCOM on UNIX, detailing how DCOM on UNIX is implemented and what each aspect represents. The final section outlines how to go about implementing a DCOM on UNIX component. This section could apply to any platform if only the general aspects are regarded.
The COM that will be discussed in this article is a server-side COM. While it is possible to build client-side COM components that make use of the graphical user interface (GUI), it is not discussed here because most of the COM components that you will be building are based on the server. The COM that will be focused on is called Distributed COM, or DCOM.
The requirements for the programmer reading this article is an understanding of Microsoft Visual C++®, ActiveX® Template Library (ATL), COM, and UNIX. The solution that will be discussed is from Software AG and MainSoft. There will be other solutions; however, they are not yet ready.
Some Questions on DCOM and UNIX
What is the difference between COM and DCOM? The answer is nothing, except that DCOM is COM calling another COM object on another machine. Consider the following diagram:
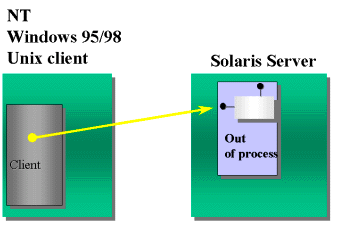
In this example there is a client, which could be any operating system. That client makes a call to the Solaris server via COM that works over the network. To the client, the call is not dependent on location. The call is made and the answer is handled automatically. The process happens transparently. It doesn't matter to the client whether the component is on a Windows NT®, Solaris, or another platform. It is a COM component.
Interoperability or cross-platform?
When writing DCOM code on a platform other than Windows there are two programming styles. The first is to write a true cross-platform application that is started on the Windows platform and later recompiled for the UNIX platform. This is one solution and one that works very well.
However, many clients do not have that need. Many corporations that have UNIX stations want the ability to keep their investment on UNIX. It is not a question of not being able to access the data. This has been solved with Open Database Connectivity (ODBC) and OLE DB. There is quite a bit of business code on the UNIX station, which needs to be accessed from a Windows client using a distributed object technology. This means the highest priority is to be able to interoperate with different platforms. Therefore, interoperability must be considered when designing and developing DCOM code on platforms other than Windows.
Where can I get a better description about the DCOM protocol?
The focus of this article is not to explain the DCOM protocol or what it does. Go to the Microsoft Web site at www.microsoft.com/com/tech/dcom.asp for a series of articles explaining DCOM protocol in the context of Windows NT to Windows NT communication.
How does it know about the interface?
When a COM component on Windows calls a COM component on UNIX, the question is, how does it know about the interface? When a COM component is compiled on UNIX the layout of the objects and how variables are stored or referenced are not identical. This would make cross-platform COM calls difficult.
The solution is in how COM functions. With COM there is an interface definition and an implementation of that interface. This basis of COM makes it work across platforms. The interface definition is cross-platform and it works anywhere because it is a neutral definition that must be fitted to the platform. The implementation can be platform specific. But let's focus a bit more on the interface definition. Using a type library compiled from the Microsoft Interface Definition Language (MIDL) environment, any custom interface can be exposed to the rest of the world. This means that all COM components are exposed locally, automatically. For the COM components to be exposed to the rest of the network, a DCOM daemon handles the resolution.
What happens when platform A and platform B have different byte ordering, and how is it handled?
What happens if platform A is 16 bits, platform B is 32 bits, and platform C is 64 bits? Then there is platform D, which is 32 bits, but organizes the integer differently than B and C. All these issues are transparent to any developer using a high-level language. However, when that high-level language is compiled it is forced into one of the specifications. This means that if an integer is saved on one platform, it cannot be easily read on another platform.
With a technology such as DCOM on UNIX, this is an issue. The savior is remote procedure call (RPC). DCOM uses an implementation of distributed computing environment (DCE) RPC. RPC is equipped for this issue and handles the conversion automatically. There is no need to specify anything in the interface definition or the programming language. It is automatic.
The only time this can become an issue is when the client is sending custom data to the server. In this situation the RPC layer treats the sent information as a blob, which is not translated. It is sent byte for byte to the server and the server must then cope with it. If possible, avoid using the custom marshalling.
Windows NT uses NetBUI and UNIX uses TCP/IP, and it works?
Windows NT can use multiple protocols. The most common are NetBIOS User Enhanced User Interface (NetBEUI), Internetwork Packet Exchange/Sequenced Packet Exchange (IPX/SPX) and Transmission Control Protocol/Internet Protocol (TCP/IP). Windows NT to Windows NT DCOM can function over any of these protocols. However, UNIX only uses TCP/IP. The issue is, how can a UNIX machine communicate to a Windows NT or Windows 9X machine? The answer is that it must use TCP/IP for it to function. Therefore, on the Windows 9X or Windows NT machine, TCP/IP must be installed. If multiple protocols are used, to optimize UNIX COM calls ensure the following:
Under the registry key,
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Rpc\DCOM Protocols
make sure that ncacn_ip_tcp is the first entry.
Unix and Windows NT have different security systems. How does it work?
When a DCOM call is made from a Windows NT platform to any platform other than Windows NT, the security model changes. On a UNIX platform there are no access control lists (ACLs), and on the mainframe the model changes yet again. This means that handling security becomes complicated. With this release of DCOM on UNIX, several vendors have no security and several vendors have custom security. A good security concept is not available. The only exception to this rule is the Software AG mainframe port.
Does this mean that there will be no security model available? The answer is not until Windows NT version 5.0 is released, when Kerberos will be implemented. At that point all the DCOM implementations will support it natively. At this stage can the DCOM components be considered secure? For now, the architecture should be such that the COM components are not exposed publicly, but hidden behind a Windows NT server.
Can files be shared across the network?
The possibility exists of creating a compound document using COM. A compound document is the persistence of a COM object. When the compound document is moved from one platform to another the question is if it can be used. The answer is a potential yes. It depends if the compound document has been created using standard COM types. If so then there is no problem with reading and manipulating the data. If, however, the document contains special data types, then the translation of the special data type may not work properly. This issue is identical to the RPC data marshalling. Therefore the suggestion is to make sure all the data types are COM data types.
Can a transaction on Windows NT station be carried to UNIX?
To fully understand the scope of this question, it is important to understand how a transaction functions. Everyone may think that Microsoft Transaction Server (MTS) is the transaction service. However, that is not entirely true. The real transaction coordinator is called the distributed transaction coordinator (DTC). It handles the commit and abort processes. The DTC uses the OLE transactions protocol to coordinate all the resources involved in a transaction. There exists an XA Transaction Protocol resource. Using this protocol, it is possible to coordinate transactions that do not execute on the Windows platform.
There is a bigger issue, though. The advantage of using MTS is that the COM method call and transaction coordination is accomplished implicitly. They are one and the same step. Currently, using DCOM on UNIX, the coordination of the DCOM call and the transaction is not implicit and must be handled on a programming level.
Do I need a fat client or thin client or something along that line?
In the press clients have been publicized as a big issue. A fat client is bad and a thin client is good. The reasoning is that a thin client is supposedly simpler to manage and control. A fat client is bad because it requires large client programs that can only be installed using manual intervention. While this may have been true in the past, consider the following diagram:

In this diagram, the Internet Information Server (IIS) is used to serve Active Server Pages (ASP). ASP pages are dynamic scripts that contain Dynamic HTML code. From an ASP script it is possible to call a component using either DCOM or COM. In this example, the components run within a Microsoft Transaction Server context, so whatever actions are performed by these business objects will be controlled by MTS. From the component it is possible to call Microsoft Message Queue Server (MSMQ) or a database, or use DCOM to call a component on a UNIX system. Using add-in software it is possible for the UNIX component to talk to Oracle using ODBC or to talk to MSMQ. The options are boundless. But it is apparent that, using this architecture, it is an ideal multitier application.
The client that receives the Dynamic HTML scripting can contain references to COM controls that enhance the user interface experience. Those controls can be fat or thin, depending on the client-side functionality. The point is to partition the application such that the client only sees business process objects, which could be COM on Windows NT or COM on UNIX. This is the reason for implementing a DCOM component on UNIX.
DCOM on UNIX, an Introduction
The first step in understanding DCOM on UNIX is to read the documentation from the vendor. This is the most important step because it defines the nuances for the various implementations.
DCOM Architecture
In this section the basic architecture showing how DCOM functions will be discussed. As a point of reference, the first implementation of DCOM on other platforms was provided by Software AG. From that port Microsoft created a reference that has been implemented by various other vendors. But all these variations have common architectural parts. Consider the following diagram:

The layered diagram above shows how DCOM is implemented. Some of the parts are old (midl) and some of the parts are new (libmutant). When the porting, began some things had to be considered. Was the port to be a port that would make UNIX look like Microsoft Win32® or give UNIX COM abilities? The solution was to make UNIX look like Win32 when possible. The reason is not for cross-platform purposes, but so that there is some similarity across all systems.
The diagram will be described starting from the bottom box up. At the bottom is the operating system. This can be any flavor of UNIX (for example, Solaris, Digital UNIX, or HP/UX) or any other operation system.
On the next level up on the right are two boxes specific to the Software AG solution. Paulad (Private Authentication Layer) is the daemon, which is responsible for the security between the non-Windows box and the Windows NT domain. Whenever anyone attempts to use a component, the component communicates to the Windows NT domain and checks if it is okay. This communication is encrypted and needs to happen with the Windows NT Primary Domain Controller (PDC). The RPC process is responsible for the remote procedure calls.
Libmutant and Ntd
On the left is a box that contains the words "libmutant" and "ntd," and shows that it equals Win32. Libmutant is a UNIX-specific library that re-creates Win32 on UNIX. The scope of the functions is limited to things such as threading, file manipulation, and anything that is nonvisual in nature, making it possible to write Windows applications without a user interface. Ntd is the daemon that provides the Win32 (libmutant) service. This daemon must be started before any application written using Win32 can function. To start the daemon, type in the following:
ntwopper ntd
The next question is whether this layer is kept in the other vendor implementations. This depends on whether the other vendor had a Win32 implementation already. In the case of MainSoft, which already had a Win32 layer, it did not choose to integrate this layer. Instead, MainSoft replaced the libmutant with its own work. This means that for the programmer there is no difference. It also means that ntwopper does not need to be started.
RPCSS
Above the Win32 layer are three other system shared libraries. These libraries form the basis of COM.
RPCSS is the library responsible for handling the COM class cache and ROT (Running Object Table). Using the ROT, it is possible to bind a client to an already running instance of the object. It is largely an efficiency issue. When a call comes in, the RPCSS takes that call and converts it into an object. Typically, RPCSS will reference the registry, then figure out what to do. Another function of this daemon is to provide the DCOM pinging services. Consider the following scenario: A client creates a component on the server. The client keeps the reference, and some time later it dies. The server is not aware that the client has died. It thinks that the reference still exists. At this point the server is not used, but consumes resources unnecessarily. The DCOM pinging services handle this by making sure that both the server and client are alive. Yet another function provided by this daemon is the OXID (object exporter id) resolver service. The purpose of the OXID service is to handle the pinging service and provide the mapping of the OXID to the string mapping on a local machine.
To start this daemon you will need to switch to root. RPCSS opens a port for servicing and this must be done with root privileges. Then do the following:
su
And give the password:
ntwopper -nowait rpcss
In all the other vendor implementations, the RPCSS was not modified to a large degree. Again, considering the case of the MainSoft implementation, the RPCSS daemon must be started so that DCOM calls can be received.
OLE32 and OLEAUT32
OLE32 and OLEAUT32 are the same dynamic-link libraries (DLLs) ported to UNIX as shared object libraries. They make up the COM infrastructure on the UNIX box. OLEAUT32 provides automation capabilities.
Programming DCOM on UNIX
At this point you should have a basic understanding of how DCOM on UNIX works and what can be done with it. Now comes the step of actually writing an application. Writing an application is not so difficult; the question is how. With the DCOM on UNIX software development kit (SDK), there are several headers. The base headers are COM- and Windows32-based, but there is also an adapted ATL distribution.
Because I worked on two different UNIX implementations, I realized that between those two platforms the implementation of C++ varies considerably. In the documents for the Solaris SDK there was a note stating that ATL had to change because of limitations regarding the C++ compiler. From this I realized that it is not possible to achieve true cross-platform capabilities. The problems stemmed from the usage of templates in ATL. ATL has some very sophisticated templates, which cause the compiler to break. This is okay, because we are only attempting to achieve an interoperability issue. In addition, developing for ATL without the wizards is a bit complicated. However, that is being addressed now that tool developers are working on such wizards.
Therefore, for the remainder of this article the focus will be on converting an existing application on UNIX and COM enabling it. This application was chosen through searching the Web and finding a piece of freeware. There was no inspection of the source code, because this would influence the ease of porting. The original application is a console menu-driven accounting application. This is similar to a terminal-driven application. Currently, there exist many terminal applications. The key is how to extend these applications. The application is pictured as follows:

To use this application the user accesses the desired logic by navigating specific items on the menu.
Step 1: What Kind of Interoperability?
It is important to ask what kind of interoperability is desired. There are three types:
- Synchronous. When the object is called, the client asking for the information waits until an answer is returned.
- Asynchronous. When the object is called, the client submits a request, then returns to its previous task. Depending on the desired reaction, the client either polls for an answer or some asynchronous callback is activated by the client.
- Bulk data transfers. When the client is asking for information, that information is requested in bulk format. The bulk data is returned and any requests work on the bulk data and not the core data.
Because the development is with DCOM on UNIX, the only current options are synchronous or bulk data transfers. For this example, either case could be applicable. To determine the difference, the questions of scalability, cost, and creep concurrency of the database need to be figured out.
Synchronous would be used if the scalability of the application is adequate. It is also generally used when cost is an issue. A synchronous COM component is one where the logic on the UNIX box is kept intact and a COM interface is "slapped on." But if, in the end, the data resides on the UNIX machine and cannot be moved, the synchronous approach must be taken.
In a bulk transfer, the data is moved from one machine to another, or to multiple others. The reason for doing this is that the cost associated with adding anything to the existing machine is either very complex, cannot scale, or the creep of the database is low or can be batched. Creep of the database is the amount of data that changes throughout the business process. If the concurrency is high and the data changes often, bulk transfers are not appropriate.
For the example program the method used is synchronous.
Step 2: Decide on the Interface.
The definition of the interface is perhaps the most complicated decision. It is a constant battle between solving the problem quickly and designing the interface for future usage. One of my pet peeves is that not enough focus is put on the design of an interface. There are plenty of books and theories about how to design classes, but even those are inadequate. The reason is simple: Legacy applications can live for years. Up to this point there are no objects that have lived for years. Objects are just starting to live. What happens when the objects that are designed today are still used 20 years from now? Very few books talk about designing objects that live on for years.
No magic bullet
There is no right way; there are many best decisions at the time. So often I have gone into a consultation and looked at decisions and found that there is no "right" answer. Sure, there may be problems, but that is normal. A saying keeps coming to mind: "If it were easy, everyone would be doing it." For example, one ongoing argument is how to design an interface. Is it designed for solving the problem or is it future proofed for any situation in the future? The answer is simple: Solve your design today, but make sure it can withstand incremental changes. Then, after some amount of time, expect a reengineering that encompasses everything that has been learned before. The key is to keep building on the knowledge learned, even if it means rewriting. Sounds easy, but there are three techniques to help the incremental changes: Decoupling, Helper Objects, and Object Wrappers.
Decoupling
COM is by its nature a perfect decoupling mechanism. Decoupling is the process of defining an interface and some implementation separately. When a consumer uses an object, it does not see the implementation, but the interface. The advantage of decoupling is that it is possible to have the consumer dynamically decide what the implementation is. Therefore, this step is already done for you by using COM. For example, while the interface is currently running on a UNIX box, another implementation could reside on Windows NT.
Helper Objects
Consider the following code:
class Person { public: Person(); void makePhoneCall( const Person &inpPerson); private: vector< PhoneCall> m_calls; char m_name[ 255]; long m_age; };There exists a Person class and this person has the ability to make a phone call. The single parameter is the other person making the call. This class definition is problematic because it binds the phone call and the person. If the definition of the call is updated, the Person class needs to be updated as well—a bad proposition. Consider the updated example:
class Person { public: Person(); private: char m_name[ 255]; long m_age; }; // Other file class Person; class PhoneCall { public: void makeCall( Person *p1, Person *p2); private: Person *m_caller; Person *m_called; };In this example, the phone call has been updated to reference the two people involved. PhoneCall is not really a proper class because it is an action, which should normally be a method. This odd class is a helper object, and because it references Person as a pointer and never references a method, it is considered a lightweight class. A recompile of one does require a recompile of the other.
Object Wrappers
This technique is only helpful in legacy situations. The purpose of Object Wrappers is to create an object-oriented (OO) layer between the legacy and the multitier system. Using Object Wrappers is a good and accepted technique. However, there is a catch with developing wrappers: The interface still needs to be properly designed.
The resulting interface that will be designed is based on the Object Wrapper concept. Because the object will potentially live for a long time, the interface is based on Helper Object design. The key is to design a good business object interface that encapsulates the operations even if the underlying data storage technique changes. How the initial business object is instantiated and what its database is, is part of the Helper Object functionality. It is assumed that some time down the road this Helper Object will become obsolete and a new Helper Object based on a database will be implemented.
A good object-oriented designer would be tempted to create a proper hierarchy to access the data object. This is because the old data access hierarchy is so outdated and it is determined that the old hierarchy will automatically go to Structured Query Language (SQL). Developing an object hierarchy for SQL is a known design. The trick would be to partially implement the hierarchy and at a later time implement the methods. The supposed advantage would be that any application relying on this hierarchy would not need any changes. However, there is a problem: When will that change happen? Is it assured that the next generation of databases will be SQL based? What about object-oriented and Extensible Markup Language (XML) databases? There is no definite answer. The better answer is to define what is known and provide a temporary solution for the rest.
Defining the IDL interfaces
The next step is to define interfaces. This step has been undervalued. Most people are used to defining interfaces via a wizard and at the same time define an implementation. While this type of solution may work for a simple component where there is only one implementation, it is not as applicable in a cross-platform or enterprise scenario. Currently, defining interfaces is done in Interface Definition Language (IDL). The definition of the interfaces are as follows:
[
object,
uuid(5644D34B-C939-11d1-948A-00A0247D759A),
pointer_default(unique),
local,
version(1.0)
]
interface IUserRecords : IUnknown
{
void getValue( BSTR column, [out, retval]BSTR *output);
void setValue( BSTR column, BSTR input);
void addRecord( int year, int month, int day, BSTR description,
double cashValue, double creditCard, double income);
void setCurrent( int record);
void searchDate( BSTR startDate, BSTR endDate);
void searchText( BSTR text);
}
[
object,
uuid(5644D34C-C939-11d1-948A-00A0247D759A),
pointer_default(unique),
local,
version(1.0)
]
interface IHelperDatabase : IUnknown
{
HRESULT saveRecords();
HRESULT loadRecords([out, retval]IUnknown *retRecords);
HRESULT database([out, retval]BSTR *value);
HRESULT descriptions([out, retval]BSTR *value);
HRESULT numDescriptions([out, retval]long *value);
}
IUserRecords is an interface that defines the basic business object that is used to access the legacy information. When a client works with this interface, they assume that there is a collection of data. How that data was added to the collection is not a function of this interface. This interface replicates the functionality exposed by the console application. It was decided not extend this functionality, because that is all that is required.
The Helper Object is IHelperDatabase. It is a legacy interface to the file-based mechanism. It provides the collection dependency that the application requires. Notice that IUserRecords does not depend on the Helper Object. And the Helper Object does not depend on IUserRecords because the common IUnknown interface is used. This is vital because it decouples everything and allows a scripting language to dynamically bind components together.
Step 3: Implement the Server Component.
This is the last step, and a very important one. It was decided in the previous step that the interface would serve as an Object Wrapper to the legacy application. The decision as to why this was done is best answered by looking at the source code. Consider the following main function:
void main(int argc, char *argv[])
{
opt_unit main_opt;
int menu_choice;
if(argc>1) strcpy(main_opt.options_file,argv[1]);
else strcpy(main_opt.options_file,".options");
if(!(main_opt.items_list=(char **)malloc(100)))
{printf("main_opt.items_list malloc error\n");exit(-1);}
read_options(main_opt.options_file,&main_opt);
menu_choice=main_menu();
while(menu_choice<8)
{
switch (menu_choice)
{
case 1:
new_data(&main_opt);
break;
case 2:
load_data(&main_opt);
break;
case 3:
save_data(&main_opt);
break;
case 4:
view_data(&main_opt);
break;
case 5:
edit_data(&main_opt);
break;
case 6:
options(&main_opt);
break;
case 7:
if(!(exit_check()))
{
printf("Bye for now :-)\n");
exit(0);
}
else break;
default:
break;
}
menu_choice=main_menu();
}
}
This main function block is simple because it delegates all the functionality to a series of functions. This makes it easy to add an Object Wrapper to the environment. The object methods can delegate their requests to the individual methods.
Singletons
At this moment, the situation can become difficult or simple. Imagine the same application above that reads in the application and stores the information in global variables. Those global variables are referenced throughout the application. This creates a situation where it is necessary to create a singleton. A singleton is a class where there can only exist one instance. It is a sort of global class. Singletons are needed because some applications wish to keep global data. There are two ways to create a singleton. The first way is to indicate that the COM component should only run once. This is okay, but there is a preferred way.
In the IHelperDatabase interface, there is a method called loadRecords. This method retrieves an interface representing the IUserRecords interface. When the method is called it should first do a global check that verifies that the IUserRecords interface has not already been instantiated. If so, it would return that active interface. Otherwise, it would create one. Since the IHelperDatabase interface is responsible for creating the interface, it must be responsible for destroying the interface as well. Therefore, a sort of super AddRef counter is implemented. When the last instance of IHelperDatabase is destroyed, so is the global instance IUserRecords. To make this concept work in a free-threaded model, it is important that IUserRecords cannot be instantiated outside of IHelperDatabase. The exact details of the implementation are beyond the scope of this article.
Towards a generic COM interface
The interface has been defined; UNIX MIDL will have compiled it and created a header and IID implementation file. Lets look a bit closer at what MIDL on NT generates and what MIDL on UNIX generates for the IUnknown interface:
MIDL on NT
MIDL_INTERFACE("00000000-0000-0000-C000-000000000046")
IUnknown
{
public:
BEGIN_INTERFACE
virtual HRESULT STDMETHODCALLTYPE QueryInterface(
/* [in] */ REFIID riid,
/* [iid_is][out] */ void __RPC_FAR *__RPC_FAR *ppvObject) = 0;
virtual ULONG STDMETHODCALLTYPE AddRef( void) = 0;
virtual ULONG STDMETHODCALLTYPE Release( void) = 0;
END_INTERFACE
};
MIDL on UNIX
DECLARE_INTERFACE( IUnknown )
{
INTERFACE_PROLOGUE( IUnknown )
STDMETHODEX_ ( HRESULT , QueryInterface, ( THIS_
/* [in] */ REFIID riid,
/* [iid_is][out] */ void **ppvObject) )
STDMETHODEX_ ( ULONG , AddRef, ( THIS) )
STDMETHODEX_ ( ULONG , Release, ( THIS) )
INTERFACE_EPILOGUE( IUnknown ) };
Looking at the definitions there seems to be a huge difference between them. Taking an interface from one interface to another would seem to be very difficult. This is not true, because the macros on UNIX resolve the same as on NT. The only extra piece of information is the MIDL_INTERFACE macro, which has no counterpart. This macro could be defined to nothing for UNIX. But if the interfaces on both platforms are basically identical, why the macros? The answer is, if the comparison is made between the MIDL for NT and MIDL for UNIX for C-language programmers, there are huge differences. VTables with a C++ compiler generate the same thing, but to build up the identical vtable representation becomes difficult if there are integer size differences or ordering differences. The macros realign everything.
Defining IClassFactory
All COM components on UNIX are implemented as executables. Therefore, when the executable starts, the first step is to initialize the COM layer and pass the IclassFactory to it. Because the code is written directly to COM, an IClassFactory for each interface must be defined. Of course this is based on the premise that the component can be created externally. Otherwise, to keep life simple, create an IClassFactory and register it with the COM layer. Because the IClassFactory implementation is generic, it could be replaced with the following template:
template< class impl>
class ClassFactoryImpl : public IClassFactory
{
…
// IClassFactory
STDMETHODIMP CreateInstance (LPUNKNOWN punkOuter, REFIID iid,
void **ppv) {
LPUNKNOWN punk;
HRESULT hr;
*ppv = NULL;
if (punkOuter != NULL)
return CLASS_E_NOAGGREGATION;
punk = new impl;
if (punk == NULL)
return E_OUTOFMEMORY;
hr = punk->QueryInterface(riid, ppv);
punk->Release();
return hr;
}
STDMETHODIMP LockServer (BOOL fLock) {
if (fLock)
SvcLock();
else
SvcUnlock();
return S_OK;
}
}
Parts of the template have been cut out for simplicity. Passed into the template is the COM component that the template is supposed to create. When CreateInstance is called it creates the correct object. In the LockServer method there are calls made to SvcLock and SvcUnlock. These methods call InterlockedIncrement and InterlockedDecrement, respectively. This brings up the question: If the developer were to use the Win32 application programming interface (API), can they still use the UNIX API? The answer is yes, with restrictions. The real issue is with interprocess communication (IPC) and process calls. The potential hazard there would be COM and the components stepping on each other's feet.
Defining the COM implementation
Defining the COM implementation is the last step, and one of the simplest. The only COM interface that needs to be implemented is IUnknown. A sample IUnknown implementation is as follows:
STDMETHODIMP QueryInterface (REFIID iid, void **ppv) {
if (ppv == NULL)
return E_INVALIDARG;
if (riid == IID_IUnknown || riid == IID_IUserRecords) {
*ppv = (IUnknown *) this;
AddRef();
return S_OK;
}
*ppv = NULL;
return E_NOINTERFACE;
}
STDMETHODIMP_(ULONG) AddRef(void) {
return m_cRef++;
}
STDMETHODIMP_(ULONG) Release(void) {
if (--m_cRef == 0) {
delete this;
return 0;
}
return 1;
}
The rest of the implementation is a calling of the individual interfaces from the Object Wrapper. For exact details, please look at the accompanying source code.
Tips
When working on the UNIX platforms with the various implementations, there are some things to look out for.
Many implementations take different approaches on how to develop for UNIX. The Software AG approach assumes that most of your development is on UNIX. This means that only some of your code may be ported to UNIX. MainSoft assumes that your primary development environment is Windows NT and you want to port your application to UNIX. This difference in approach defines your overall development architecture. How do you know which approach to take? Simple, how much legacy is there? If you are only providing a bridge for your application until it is converted to Windows NT, the Software AG approach is great. However, if you plan to develop applications or COM components that need to be distributed on various platforms without a development nightmare, the MainSoft approach is for you.
The development tools are primitive and nothing is done implicitly. You will need to customize your makefiles and your editor to support the COM development methodology. A company in Austria, Take Five, has created a development tool called Sniff. This development environment needs tweaking, but it is very usable in the UNIX environment. It makes development simpler. For real COM development comfort, the only development environment is Windows NT. If this is really necessary, looking at MainSoft would be recommended.
Understand the individual environments. Because there is still quite a bit of development effort needed on the other platforms, the platform needs to be understood. Even the MainSoft solution, with its one-step compilation, requires platform knowledge. This knowledge is not needed when everything works, but when things do not work. Remember that all this technology is a layer on top of the operating system. If the operating system does not support threads natively, a thunking layer is developed. Consider the case of using pthreads on Linux. Pthreads fork the processes and make them look like threads. This means that certain programming habits are not possible and can only be understood if the platform is understood. I will be honest when I state that the least problematic platform on a programming level has been Solaris. The other platforms have their quirks.
Understand the compiler. ATL has been ported to the various platforms, but there are many issues. ATL is a very advanced and high-performance template library. Many compilers on various platforms cannot deal with this complexity, despite its standard use of C++ templates. Therefore, many DCOM implementations have put limitations on what can be done. If this concerns you, it is advised to use plain vanilla COM code. On his Web site (see http://www.develop.com/dbox/) Don Box has created a very simple YATL template library that can be used to create COM components. This library is simple and can easily be tuned, but it does save on the grunt work of creating COM components. If your COM components use special tricks on a platform, you will run into problems.
Summing It Up
There you have it—developing COM components on platforms other than Windows. It is simple if you stay within the boundaries. The moment you step out of the simple boundaries, things can become very complicated and there can be many issues. As the NT operating system and its services become more refined, however, interoperability between Windows and other platforms will also become more easily achieved.
References
COM: www.microsoft.com/com, https://msdn.microsoft.com
Writing Portable Code: http://www.mozilla.org/docs/tplist/catBuild/portable-cpp.html.
Software AG: http://www.sagus.com/. (Look for EntireX DCOM, Dcomdoc.txt for installation and tips/tricks.)
MainSoft: http://www.mainsoft.com/. (MainSoft specializes in an implementation of Windows on UNIX. Their library was used to port Microsoft Internet Explorer.)