Introducing compute pools in SQL Server Big Data Clusters
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
This article describes the role of SQL Server compute pools in a SQL Server big data cluster. Compute pools provide scale-out computational resources for a SQL Server big data cluster. They are used to offload computational work, or intermediate result sets, from the SQL Server master instance. The following sections describe the architecture, functionality and usage scenarios of a compute pool.
You can also watch this 5-minute video for an introduction into compute pools:
Compute pool architecture
A compute pool is made of one or more compute pods running in Kubernetes. The automated creation and management of these pods is coordinated by the SQL Server master instance. Each pod contains a set of base services and an instance of the SQL Server database engine.
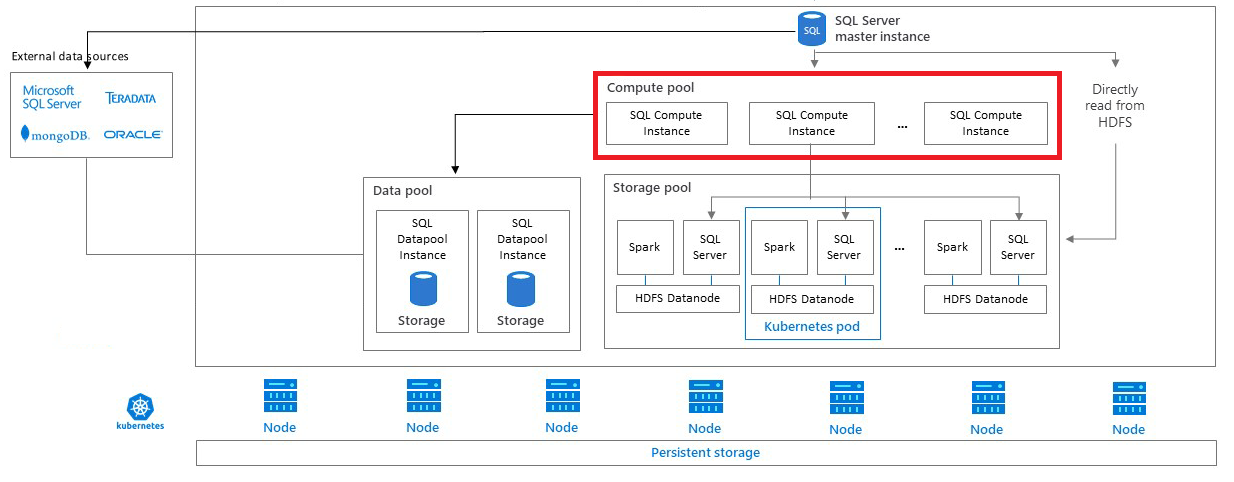
Scale-out groups
A compute pool can act as a PolyBase scale-out group for distributed queries over different external data sources such as SQL Server, Oracle, MongoDB, Teradata and HDFS. By using compute pods in Kubernetes, a SQL Server big data cluster can automate creating and configuring compute pods for PolyBase scale-out groups.
Compute pool scenarios
Scenarios where the compute pool is used include:
When queries submitted to the master instance use one or more tables located in the storage pool.
When queries submitted to the master instance use one or more tables with round-robin distribution located in the data pool.
When queries submitted to the master instance use partitioned tables with external data sources of SQL Server, Oracle, MongoDB, and Teradata. For this scenario, the query hint OPTION (FORCE SCALEOUTEXECUTION) must be enabled.
When queries submitted to the master instance use one or more tables located in HDFS tiering.
Scenarios where the compute pool is not used include:
When queries submitted to the master instance use one or more tables in an external Hadoop HDFS cluster.
When queries submitted to the master instance use one or more tables in Azure Blob Storage.
When queries submitted to the master instance use non-partitioned tables with external data sources of SQL Server, Oracle, MongoDB, and Teradata.
When the query hint OPTION (DISABLE SCALEOUTEXECUTION) is enabled.
When queries submitted to the master instance apply to databases located on the master instance.
Next steps
To learn more about the SQL Server Big Data Clusters, see the following resources:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for