Create, export, and score Spark machine learning models on SQL Server Big Data Clusters
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
The following sample shows how to build a model with Spark ML, export the model to MLeap, and score the model in SQL Server with its Java Language Extension. This is done in the context of a SQL Server big data cluster.
The following diagram illustrates the work performed in this sample:
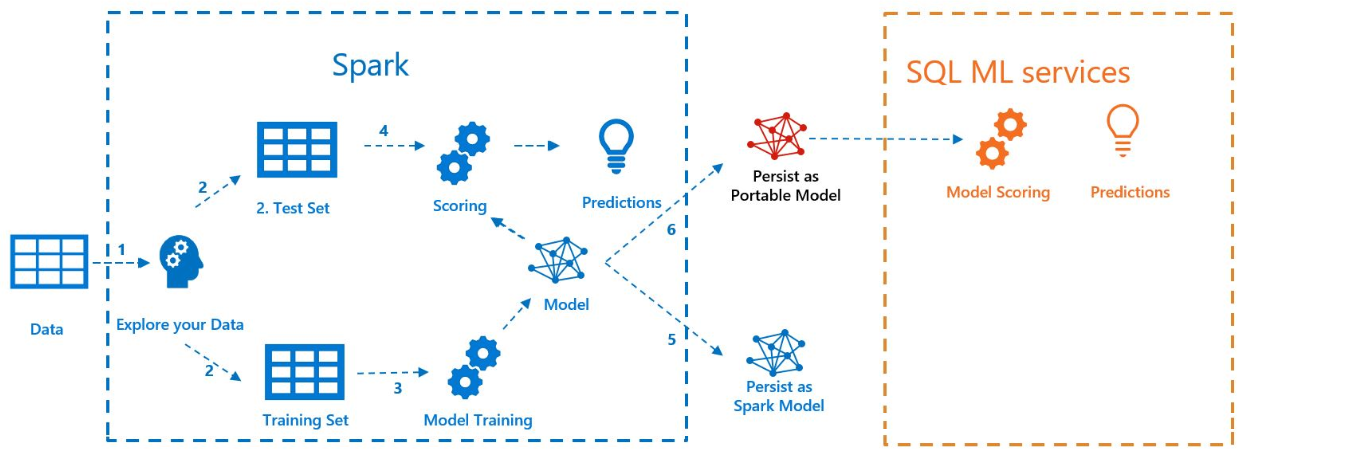
Prerequisites
All files for this sample are located at https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
To run the sample, you must also have the following prerequisites:
-
- kubectl
- curl
- Azure Data Studio
Model training with Spark ML
For this sample, census data (AdultCensusIncome.csv) is used to build a Spark ML pipeline model.
Use the mleap_sql_test/setup.sh file to download the data set from internet and put it on HDFS in your SQL Server big data cluster. This enables it to be accessed by Spark.
Then download the sample notebook train_score_export_ml_models_with_spark.ipynb. From a PowerShell or bash command line, run the following command to download the notebook:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"This notebook contains cells with the required commands for this section of the sample.
Open the notebook in Azure Data Studio, and run each code block. For more information about working with notebooks, see How to use notebooks with SQL Server.
The data is first read into Spark and split into training and testing data sets. Then the code trains a pipeline model with the training data. Finally, it exports the model to an MLeap bundle.
Tip
You can also review or run the Python code associated with these steps outside of the notebook in the mleap_sql_test/mleap_pyspark.py file.
Model scoring with SQL Server
Now that the Spark ML pipeline model is in a common serialization MLeap bundle format, you can score the model in Java without the presence of Spark.
This sample uses the Java Language Extension in SQL Server. In order to score the model in SQL Server, you first need to build a Java application that can load the model into Java and score it. You can find the sample code for this Java application in the mssql-mleap-app folder.
After building the sample, you can use Transact-SQL to call the Java application and score the model with a database table. This can be seen in thee mleap_sql_test/mleap_sql_tests.py source file.
Next steps
For more information about big data clusters, see How to deploy SQL Server Big Data Clusters on Kubernetes
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for