Columnstore indexes - Data loading guidance
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Options and recommendations for loading data into a columnstore index by using the standard SQL bulk loading and trickle insert methods. Loading data into a columnstore index is an essential part of any data warehousing process because it moves data into the index in preparation for analytics.
New to columnstore indexes? See Columnstore indexes - overview and Columnstore Index Architecture.
What is bulk loading?
Bulk loading refers to the way large numbers of rows are added to a data store. It's the most performant way to move data into a columnstore index because it operates on batches of rows. Bulk loading fills rowgroups to maximum capacity and compresses them directly into the columnstore. Only rows at the end of a load that don't meet the minimum of 102,400 rows per rowgroup go to the deltastore.
To perform a bulk load, you can use bcp Utility, Integration Services, or select rows from a staging table.
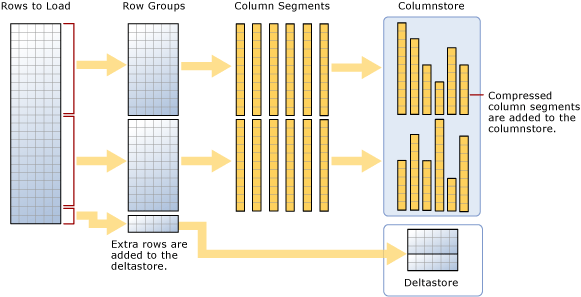
As the diagram suggests, a bulk load:
- Doesn't presort the data. Data is inserted into rowgroups in the order it's received.
- If the batch size is >= 102400, the rows are directly loaded into the compressed rowgroups. You should choose a batch size >=102400 for efficient bulk import, because you can avoid moving data rows to delta rowgroups before the rows are eventually moved to compressed rowgroups by a background thread, Tuple mover (TM).
- If the batch size < 102,400 or if the remaining rows are < 102,400, the rows are loaded into delta rowgroups.
Note
On a rowstore table with a nonclustered columnstore index data, SQL Server always inserts data into the base table. The data is never inserted directly into the columnstore index.
Bulk loading has these built-in performance optimizations:
Parallel loads: You can have multiple concurrent bulk loads (bcp or bulk insert) that are each loading a separate data file. Unlike rowstore bulk loads into SQL Server, you don't need to specify
TABLOCKbecause each bulk import thread loads data exclusively into separate rowgroups (compressed or delta rowgroups) with exclusive lock on it.Reduced logging: The data that is directly loaded into compressed row groups, leads to significant reduction in the size of the log. For example, if data was compressed 10x, the corresponding transaction log is roughly 10x smaller without requiring TABLOCK or Bulk-logged/Simple recovery model. Any data that goes to a delta rowgroup is fully logged. This includes any batch sizes that are less than 102,400 rows. Best practice is to use batchsize >= 102400. Since there's no TABLOCK required, you can load the data in parallel.
Minimal logging: You can get further reduction in logging if you follow the prerequisites for minimal logging. However, unlike loading data into a rowstore, TABLOCK leads to an X lock on the table rather than a BU (Bulk Update) lock and therefore parallel data load can't be done. For more information on locking, see Locking and row versioning.
Locking optimization: The X lock on a row group is automatically acquired when loading data into a compressed row group. However, when bulk loading into a delta rowgroup, an X lock is acquired at rowgroup but SQL Server still locks the PAGE/EXTENT because X rowgroup lock isn't part of locking hierarchy.
If you have a nonclustered B-tree index on a columnstore index, there's no locking or logging optimization for the index itself but the optimizations on clustered columnstore index as described previously are applicable.
Data modification (insert, delete, update) isn't a batch mode operation because it's not parallel.
Plan bulk load sizes to minimize delta rowgroups
Columnstore indexes perform best when most of the rows are compressed into the columnstore and not sitting in delta rowgroups. It's best to size your loads so that rows go directly to the columnstore and bypass the deltastore as much as possible.
These scenarios describe when loaded rows go directly to the columnstore or when they go to the deltastore. In the example, each rowgroup can have 102,400-1,048,576 rows per rowgroup. In practice, the maximum size of a rowgroup can be smaller than 1,048,576 rows when there's memory pressure.
| Rows to bulk load | Rows added to the compressed rowgroup | Rows added to the delta rowgroup |
|---|---|---|
| 102,000 | 0 | 102,000 |
| 145,000 | 145,000 Rowgroup size: 145,000 |
0 |
| 1,048,577 | 1,048,576 Rowgroup size: 1,048,576. |
1 |
| 2,252,152 | 2,252,152 Rowgroup sizes: 1,048,576, 1,048,576, 155,000. |
0 |
The following example shows the results of loading 1,048,577 rows into a table. The results show that one COMPRESSED rowgroup in the columnstore (as compressed column segments), and 1 row in the deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Use a staging table to improve performance
If you're loading data only to stage it before running more transformations, loading the table to heap table is much faster than loading the data to a clustered columnstore table. In addition, loading data to a [temporary table][Temporary] will also load much faster than loading a table to permanent storage.
A common pattern for data load is to load the data into a staging table, do some transformation and then load it into the target table using the following command:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
This command loads the data into the columnstore index in similar ways to bcp or bulk insert but in a single batch. If the number of rows in the staging table < 102400, the rows are loaded into a delta rowgroup otherwise the rows are directly loaded into compressed rowgroup. One key limitation was that this INSERT operation was single threaded. To load data in parallel, you could create multiple staging table or issue INSERT/SELECT with non-overlapping ranges of rows from the staging table. This limitation goes away with SQL Server 2016 (13.x). The following command loads the data from staging table in parallel but you must specify TABLOCK. You may find this contradictory to what was said earlier with bulkload but the key difference is the parallel data load from the staging table is executed under the same transaction.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
There are following optimizations available when loading into a clustered columnstore index from staging table:
- Log Optimization: Reduced logging when the data is loaded into a compressed rowgroup.
- Locking Optimization: When loading data into a compressed rowgroup, the X lock on rowgroup is acquired. However, with delta rowgroup, an X lock is acquired at rowgroup but SQL Server still locks the locks PAGE/EXTENT because X rowgroup lock isn't part of locking hierarchy.
If you have one or more nonclustered indexes, there's no locking or logging optimization for the index itself, but the optimizations on the clustered columnstore index as described previously are still there.
What is trickle insert?
Trickle insert refers to the way individual rows move into the columnstore index. Trickle inserts use the INSERT INTO statement. With trickle insert, all of the rows go to the deltastore. This is useful for small numbers of rows, but not practical for large loads.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Note
Concurrent threads using INSERT INTO to insert values into a clustered columnstore index can insert rows into the same deltastore rowgroup.
Once the rowgroup contains 1,048,576 rows, the delta rowgroup us marked closed but it's still available for queries and update/delete operations, but the newly inserted rows go into an existing or newly created deltastore rowgroup. There's a background thread Tuple Mover (TM) that compresses the closed delta rowgroups periodically every 5 minutes or so. You can explicitly invoke the following command to compress the closed delta rowgroup.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
If you want to force a delta rowgroup closed and compressed, you can execute the following command. You may want run this command if you're done loading the rows and don't expect any new rows. By explicitly closing and compressing the delta rowgroup, you can save storage further and improve the analytics query performance. A best practice is to invoke this command if you don't expect new rows to be inserted.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
How loading into a partitioned table works
For partitioned data, SQL Server first assigns each row to a partition, and then performs columnstore operations on the data within the partition. Each partition has its own rowgroups and at least one delta rowgroup.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for