Windows Server Failover Clustering with SQL Server
Applies to: ![]() SQL Server
SQL Server
A Windows Server Failover Cluster (WSFC) is a group of independent servers that work together to increase the availability of applications and services. SQL Server takes advantage of WSFC services and capabilities to support Always On availability groups and SQL Server Failover Cluster Instances.
Terms and Definitions
Windows Server Failover Cluster (WSFC) A WSFC is a group of independent servers that work together to increase the availability of applications and services.
Node
A server that is participating in a WSFC.
Cluster resource
A physical or logical entity that can be owned by a node, brought online and taken offline, moved between nodes, and managed as a cluster object. A cluster resource can be owned by only a single node at any point in time.
Role
A collection of cluster resources managed as a single cluster object to provide specific functionality. For SQL Server, a role will be either an Always On Availability Group (AG) or Always On Failover Cluster Instance (FCI). A role contains all of the cluster resources that are required for an AG or FCI. Failover and failback always act in context of roles. For an FCI, the role will contain an IP address resource, a network name resource, and the SQL Server resources. An AG role will contain the AG resource, and if a listener is configured, a network name and an IP resource.
Network name resource
A logical server name that is managed as a cluster resource. A network name resource must be used with an IP address resource. These entries may require objects in Active Directory Domain Services and/or DNS.
Resource dependency
A resource on which another resource depends. If resource A depends on resource B, then B is a dependency of A. Resource A will not be able to start without resource B.
Preferred owner
A node on which a resource group prefers to run. Each resource group is associated with a list of preferred owners sorted in order of preference. During automatic failover, the resource group is moved to the next preferred node in the preferred owner list.
Possible owner
A secondary node on which a resource can run. Each resource group is associated with a list of possible owners. Roles can fail over only to nodes that are listed as possible owners.
Quorum mode
The quorum configuration in a failover cluster that determines the number of node failures that the cluster can sustain.
Force quorum
The process to start the cluster even though only a minority of the elements that are required for quorum are in communication.
Overview of Windows Server Failover Clustering
Windows Server Failover Clustering provides infrastructure features that support the high-availability and disaster recovery scenarios of hosted server applications such as Microsoft SQL Server and Microsoft Exchange. If a cluster node or service fails, the services that were hosted on that node can be automatically or manually transferred to another available node in a process known as failover.
The nodes in a WSFC work together to collectively provide these types of capabilities:
Distributed metadata and notifications. WSFC service and hosted application metadata is maintained on each node in the cluster. This metadata includes WSFC configuration and status in addition to hosted application settings. Changes to a node's metadata or status are automatically propagated to the other nodes in the WSFC.
Resource management. Individual nodes in the WSFC may provide physical resources such as direct-attached storage, network interfaces, and access to shared disk storage. Hosted applications register themselves as a cluster resource, and may configure startup and health dependencies upon other resources.
Health monitoring. Inter-node and primary node health detection is accomplished through a combination of heartbeat-style network communications and resource monitoring. The overall health of the WSFC is determined by the votes of a quorum of nodes in the WSFC.
Failover coordination. Each resource is configured to be hosted on a primary node, and each can be automatically or manually transferred to one or more secondary nodes. A health-based failover policy controls automatic transfer of resource ownership between nodes. Nodes and hosted applications are notified when failover occurs so that they may react appropriately.
For more information, see: Failover Clustering Overview - Windows Server
SQL Server Always On Technologies and WSFC
SQL Server Always On is a high availability and disaster recovery solution that takes advantage of WSFC. The Always On features provide integrated, flexible solutions that increase application availability, provide better returns on hardware investments, and simplify high availability deployment and management.
Both Always On availability groups and Always On Failover Cluster Instances use WSFC as a platform technology, registering components as WSFC cluster resources. Related resources are combined into a role, which can be made dependent upon other WSFC cluster resources. The WSFC can then sense and signal the need to restart the SQL Server instance or automatically fail it over to a different server node in the WSFC.
Important
To take full advantage of SQL Server Always On technologies, you should apply several WSFC-related prerequisites.
For more information, see: Prerequisites, Restrictions, and Recommendations for Always On Availability Groups (SQL Server)
Instance-level High Availability with Always On Failover Cluster Instances
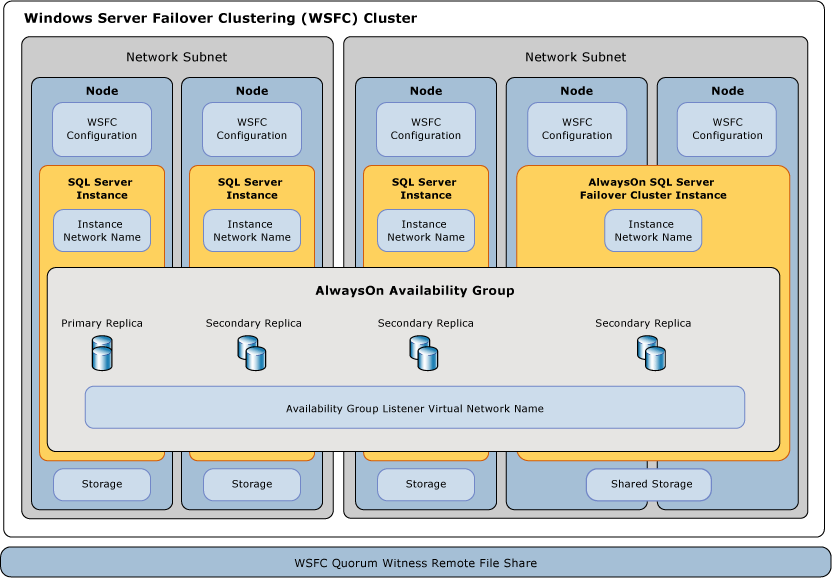
An Always On Failover Cluster Instance (FCI) is a SQL Server instance that is installed across nodes in a WSFC. This type of instance depends on resources for storage and virtual network name. The storage can use Fibre Channel, iSCSI, FCoE, or SAS for shared disk storage, or use locally attached storage with Storage Spaces Direct (S2D). The virtual network name resource depends on one or more virtual IP addresses, each in a different subnet. The SQL Server service and the SQL Server Agent service are also resources, and both are dependent upon the storage and virtual network name resources.
In the event of a failover, the WSFC service transfers ownership of instance's resources to a designated failover node. The SQL Server instance is then re-started on the failover node, and databases are recovered as usual. At any given moment, only a single node in the cluster can host the FCI and underlying resources.
Note
An Always On Failover Cluster Instance requires symmetrical shared disk storage such as a storage area network (SAN) or SMB file share. The shared disk storage volumes must be available to all potential failover nodes in the WSFC cluster.
For more information, see: Always On Failover Cluster Instances (SQL Server)
Database-level High Availability with Always On availability groups
An Always On Availability Group (AG) is a one or more user databases that fail over together. An availability group consists of a primary availability replica and one to four secondary replicas that are maintained through SQL Server log-based data movement for data protection without the need for shared storage. Each replica is hosted by an instance of SQL Server on a different node of the WSFC. The availability group and a corresponding virtual network name are registered as resources in the WSFC cluster.
An availability group listener on the primary replica's node responds to incoming client requests to connect to the virtual network name, and based on attributes in the connection string, it redirects each request to the appropriate SQL Server instance.
In the event of a failover, instead of transferring ownership of shared physical resources to another node, WSFC is leveraged to reconfigure a secondary replica on another SQL Server instance to become the availability group's primary replica. The availability group's virtual network name resource is then transferred to that instance.
At any given moment, only a single SQL Server instance may host the primary replica of an availability group's databases, all associated secondary replicas must each reside on a separate instance, and each instance must reside on separate physical nodes.
Note
Always On availability groups do not require deployment of a Failover Cluster Instance or use of symmetric shared storage (SAN or SMB).
A Failover Cluster Instance (FCI) may be used together with an availability group to enhance the availability of an availability replica. However, to prevent potential race conditions in the WSFC cluster, automatic failover of the availability group is not supported to or from an availability replica that is hosted on a FCI.
For more information, see: Overview of Always On Availability Groups (SQL Server)
WSFC Health Monitoring and Failover
High availability for an Always On solution is accomplished through proactive health monitoring of physical and logical WSFC cluster resources, together with automatic failover onto and re-configuration of redundant hardware. A system administrator can also initiate a manual failover of an availability group or SQL Server instance from one node to another.
Failover Policies for Nodes, Failover Cluster Instances, and Availability Groups
A failover policy is configured at the WSFC node, the SQL Server Failover Cluster Instance (FCI), and the availability group levels. These policies, based on the severity, duration, and frequency of unhealthy cluster resource status and node responsiveness, can trigger a service restart or an automatic failover of cluster resources from one node to another, or can trigger the move of an availability group primary replica from one SQL Server instance to another.
Failover of an availability group replica does not affect the underlying SQL Server instance. Failover of a FCI moves the hosted availability group replicas with the instance.
For more information, see: Failover Policy for Failover Cluster Instances
WSFC Resource Health Detection
Each resource in a WSFC can report its status and health, periodically or on-demand. A variety of circumstances may indicate resource failure; e.g. power failure, disk or memory errors, network communication errors, or non-responsive services.
WSFC resources such as networks, storage, or services can be made dependent upon one another. The cumulative health of a resource is determined by successively rolling up its health with the health of each of its resource dependencies.
WSFC Inter-node Health Detection and Quorum Voting
Each node in a WSFC participates in periodic heartbeat communication to share the node's health status with the other nodes. Unresponsive nodes are considered to be in a failed state.
Quorum is a mechanism that helps ensure that the WSFC is up and running through ensuring enough resources are online in the WSFC. If the WSFC has enough votes, it is healthy and able to provide node-level fault tolerance.
A quorum mode is configured in the WSFC that dictates the methodology used for quorum voting and when to perform an automatic failover or take the cluster offline.
Tip
It is a best practice to always have an odd number of quorum votes in a WSFC. For the purposes of quorum voting, SQL Server does not have to be installed on all nodes in the cluster. An additional server can act as a quorum member, or the WSFC quorum model can be configured to use a remote file share as a tie-breaker.
For more information, see: WSFC Quorum Modes and Voting Configuration (SQL Server)
Disaster Recovery Through Forcing Quorum
Depending upon operational practices and WSFC configuration, you can incur both automatic and manual failovers, and still maintain a robust, fault-tolerant SQL Server Always On solution. However, if a quorum of the eligible voting nodes in the WSFC cannot communicate with one another, or if the WSFC cluster otherwise fails health validation, then the WSFC may go offline.
If the WSFC goes offline because of an unplanned disaster, or due to a persistent hardware or communications failure, then manual administrative intervention is required to force quorum and bring the surviving cluster nodes back online in a non-fault-tolerant configuration.
Afterwards, a series of steps must also be taken to reconfigure the WSFC, recover the affected database replicas, and to re-establish a new quorum.
For more information, see: WSFC Disaster Recovery through Forced Quorum (SQL Server)
Relationship of SQL Server Always On Components to WSFC
Several layers of relationships exist between SQL Server Always On and WSFC features and components.
Always On availability groups are hosted on SQL Server instances.
A client request that specifies a logical availability group listener network name to connect to a primary or secondary database is redirected to the appropriate instance network name of the underlying SQL Server instance or SQL Server FCI.
SQL Server instances are actively hosted on a single node.
If present, a stand-alone SQL Server Instance always resides on a single Node with a static instance network name. If present, a SQL Server FCI is active on one of two or more possible failover nodes with a single virtual Instance Network Name.
Nodes are members of a WSFC cluster.
WSFC configuration metadata and status for all nodes is stored on each node. Each server may provide asymmetric storage or shared storage (SAN) volumes for user or system databases. Each server has at least one physical network interface on one or more IP subnets.
The WSFC monitors health and manages configuration for a group of servers.
The WSFC mechanisms propagate changes to WSFC configuration metadata and status to all nodes in the WSFC. If a disk witness is used, the metadata is also stored there. By default, each node of the WSFC gets a vote towards quorum and a witness will be used if necessary and is configured.
Always On availability groups registry keys are subkeys of the WSFC cluster.
If you delete and re-create a WSFC, you must disable and re-enable the Always On availability groups feature on each server instance that was enabled for Always On availability groups on the original WSFC. For more information, see Enable and Disable Always On Availability Groups (SQL Server).
Related Tasks
Related Content
See Also
Always On Failover Cluster Instances (SQL Server)
Overview of Always On Availability Groups (SQL Server)
WSFC Quorum Modes and Voting Configuration (SQL Server)
Failover Policy for Failover Cluster Instances
WSFC Disaster Recovery through Forced Quorum (SQL Server)
SQL Server 2016 Supports Windows Server 2016 Storage Spaces Direct
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for