DBCC SHOW_STATISTICS (Transact-SQL)
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() SQL analytics endpoint in Microsoft Fabric
SQL analytics endpoint in Microsoft Fabric ![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
Displays current query optimization statistics for a table or indexed view. The query optimizer uses statistics to estimate the cardinality or number of rows in the query result, which enables the Query Optimizer to create a high quality query plan. For example, the Query Optimizer could use cardinality estimates to choose the index seek operator instead of the index scan operator in the query plan, improving query performance by avoiding a resource-intensive index scan.
The Query Optimizer stores statistics for a table or indexed view in a statistics object. For a table, the statistics object is created on either an index or a list of table columns. The statistics object includes a header with metadata about the statistics, a histogram with the distribution of values in the first key column of the statistics object, and a density vector to measure cross-column correlation. The Database Engine can compute cardinality estimates with any of the data in the statistics object. For more information, see Statistics and Cardinality Estimation (SQL Server).
DBCC SHOW_STATISTICS displays the header, histogram, and density vector based on data stored in the statistics object. The syntax lets you specify a table or indexed view along with a target index name, statistics name, or column name.
Important updates in past versions of SQL Server:
Starting in SQL Server 2012 (11.x) Service Pack 1, the sys.dm_db_stats_properties dynamic management view is available to programmatically retrieve header information contained in the statistics object for non-incremental statistics.
Starting in SQL Server 2014 (12.x) Service Pack 2 and SQL Server 2012 (11.x) Service Pack 1, the sys.dm_db_incremental_stats_properties dynamic management view is available to programmatically retrieve header information contained in the statistics object for incremental statistics.
Starting in SQL Server 2016 (13.x) Service Pack 1 CU 2, the sys.dm_db_stats_histogram dynamic management view is available to programmatically retrieve histogram information contained in the statistics object.
-
This syntax is not supported by serverless SQL pool in Azure Synapse Analytics.
For more information on statistics in Microsoft Fabric, see Statistics.
![]() Transact-SQL syntax conventions
Transact-SQL syntax conventions
Syntax
Syntax for SQL Server and Azure SQL Database:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Syntax for Azure Synapse Analytics, Analytics Platform System (PDW), and Microsoft Fabric:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
Note
To view Transact-SQL syntax for SQL Server 2014 (12.x) and earlier versions, see Previous versions documentation.
Arguments
table_or_indexed_view_name
Name of the table or indexed view for which to display statistics information.
table_name
Name of the table that contains the statistics to display. The table can't be an external table.
target
Name of the index, statistics, or column for which to display statistics information. target is enclosed in brackets, single quotes, double quotes, or no quotes.
- If target is a name of an existing index or statistics on a table or indexed view, the statistics information about this target is returned.
- If target is the name of an existing column, and an automatically created statistics object on this column exists, information about that auto-created statistic is returned.
If an automatically created statistic doesn't exist for a column target, error message 2767 is returned.
In Azure Synapse Analytics and Analytics Platform System (PDW), target can't be a column name.
In Warehouse in Microsoft Fabric, target can be either the name of a single-column histogram statistics or a column. If a column name is used for target, this command returns distribution information only about the automatically generated histogram statistic. To view the information about a manually created histogram statistic, specify the statistics name as target.
NO_INFOMSGS
Suppresses all informational messages that have severity levels from 0 through 10.
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
Specifying one or more of these options limits the result sets returned by the statement to the specified option or options. If no options are specified, all statistics information is returned.
STATS_STREAM is Identified for informational purposes only. Not supported. Future compatibility is not guaranteed.
Result set
The following table describes the columns returned in the result set when STAT_HEADER is specified.
| Column name | Description |
|---|---|
| Name | Name of the statistics object. |
| Updated | Date and time the statistics were last updated. The STATS_DATE function is an alternate way to retrieve this information. For more information, see the Remarks section in this page. |
| Rows | Total number of rows in the table or indexed view when the statistics were last updated. If the statistics are filtered or correspond to a filtered index, the number of rows might be less than the number of rows in the table. For more information, see Statistics. |
| Rows Sampled | Total number of rows sampled for statistics calculations. If Rows Sampled < Rows, the displayed histogram and density results are estimates based on the sampled rows. |
| Steps | Number of steps in the histogram. Each step spans a range of column values followed by an upper bound column value. The histogram steps are defined on the first key column in the statistics. The maximum number of steps is 200. |
| Density | Calculated as 1 / distinct values for all values in the first key column of the statistics object, excluding the histogram boundary values. This Density value isn't used by the Query Optimizer and is displayed for backward compatibility with versions before SQL Server 2008 (10.0.x). |
| Average Key Length | Average number of bytes per value for all of the key columns in the statistics object. |
| String Index | Yes indicates the statistics object contains string summary statistics to improve the cardinality estimates for query predicates that use the LIKE operator; for example, WHERE ProductName LIKE '%Bike'. String summary statistics are stored separately from the histogram and are created on the first key column of the statistics object when it's of type char, varchar, nchar, nvarchar, varchar(max), nvarchar(max), text, or ntext.. |
| Filter Expression | Predicate for the subset of table rows included in the statistics object. NULL = non-filtered statistics. For more information about filtered predicates, see Create Filtered Indexes. For more information about filtered statistics, see Statistics. |
| Unfiltered Rows | Total number of rows in the table before applying the filter expression. If Filter Expression is NULL, Unfiltered Rows is equal to Rows. |
| Persisted Sample Percent | Persisted sample percentage used for statistic updates that don't explicitly specify a sampling percentage. If value is zero, then no persisted sample percentage is set for this statistic. Applies to: SQL Server 2016 (13.x) Service Pack 1 CU 4 |
The following table describes the columns returned in the result set when DENSITY_VECTOR is specified.
| Column name | Description |
|---|---|
| All Density | Density is 1 / distinct values. Results display density for each prefix of columns in the statistics object, one row per density. A distinct value is a distinct list of the column values per row and per columns prefix. For example, if the statistics object contains key columns (A, B, C), the results report the density of the distinct lists of values in each of these column prefixes: (A), (A,B), and (A, B, C). Using the prefix (A, B, C), each of these lists is a distinct value list: (3, 5, 6), (4, 4, 6), (4, 5, 6), (4, 5, 7). Using the prefix (A, B) the same column values have these distinct value lists: (3, 5), (4, 4), and (4, 5) |
| Average Length | Average length, in bytes, to store a list of the column values for the column prefix. For example, if the values in the list (3, 5, 6) each require 4 bytes the length is 12 bytes. |
| Columns | Names of columns in the prefix for which All density and Average length are displayed. |
The following table describes the columns returned in the result set when the HISTOGRAM option is specified.
| Column name | Description |
|---|---|
| RANGE_HI_KEY | Upper bound column value for a histogram step. The column value is also called a key value. |
| RANGE_ROWS | Estimated number of rows whose column value falls within a histogram step, excluding the upper bound. |
| EQ_ROWS | Estimated number of rows whose column value equals the upper bound of the histogram step. |
| DISTINCT_RANGE_ROWS | Estimated number of rows with a distinct column value within a histogram step, excluding the upper bound. |
| AVG_RANGE_ROWS | Average number of rows with duplicate column values within a histogram step, excluding the upper bound. When DISTINCT_RANGE_ROWS is greater than 0, AVG_RANGE_ROWS is calculated by dividing RANGE_ROWS by DISTINCT_RANGE_ROWS. When DISTINCT_RANGE_ROWS is 0, AVG_RANGE_ROWS returns 1 for the histogram step. |
Remarks
Statistics update date is stored in the statistics blob object together with the histogram and density vector, not in the metadata. When no data is read to generate statistics data, the statistics blob isn't created, the date isn't available, and the updated column is NULL. This is the case for filtered statistics for which the predicate doesn't return any rows, or for new empty tables.
Histogram
A histogram measures the frequency of occurrence for each distinct value in a data set. The query optimizer computes a histogram on the column values in the first key column of the statistics object, selecting the column values by statistically sampling the rows or by performing a full scan of all rows in the table or view. If the histogram is created from a sampled set of rows, the stored totals for number of rows and number of distinct values are estimates and don't need to be whole integers.
To create the histogram, the query optimizer sorts the column values, computes the number of values that match each distinct column value and then aggregates the column values into a maximum of 200 contiguous histogram steps. Each step includes a range of column values followed by an upper bound column value. The range includes all possible column values between boundary values, excluding the boundary values themselves. The lowest of the sorted column values is the upper boundary value for the first histogram step.
The following diagram shows a histogram with six steps. The area to the left of the first upper boundary value is the first step.

For each histogram step:
- Bold line represents the upper boundary value (RANGE_HI_KEY) and the number of times it occurs (EQ_ROWS)
- Solid area left of RANGE_HI_KEY represents the range of column values and the average number of times each column value occurs (AVG_RANGE_ROWS). The AVG_RANGE_ROWS for the first histogram step is always 0.
- Dotted lines represent the sampled values used to estimate total number of distinct values in the range (DISTINCT_RANGE_ROWS) and total number of values in the range (RANGE_ROWS). The query optimizer uses RANGE_ROWS and DISTINCT_RANGE_ROWS to compute AVG_RANGE_ROWS and doesn't store the sampled values.
The query optimizer defines the histogram steps according to their statistical significance. It uses a maximum difference algorithm to minimize the number of steps in the histogram while maximizing the difference between the boundary values. The maximum number of steps is 200. The number of histogram steps can be fewer than the number of distinct values, even for columns with fewer than 200 boundary points. For example, a column with 100 distinct values can have a histogram with fewer than 100 boundary points.
Density vector
The query optimizer uses densities to enhance cardinality estimates for queries that return multiple columns from the same table or indexed view. The density vector contains one density for each prefix of columns in the statistics object. For example, if a statistics object has the key columns CustomerId, ItemId and Price, density is calculated on each of the following column prefixes.
| Column prefix | Density calculated on |
|---|---|
(CustomerId) |
Rows with matching values for CustomerId |
(CustomerId, ItemId) |
Rows with matching values for CustomerId and ItemId |
(CustomerId, ItemId, Price) |
Rows with matching values for CustomerId, ItemId, and Price |
Limitations
DBCC SHOW_STATISTICS doesn't provide statistics for spatial indexes nor memory-optimized columnstore indexes.
Permissions for SQL Server and SQL Database
In order to view the statistics object, the user must have the SELECT permission on the table.
The following requirements exist for SELECT permissions to be sufficient to run the command:
- Users must have permissions on all columns in the statistics object
- Users must have permission on all columns in a filter condition (if one exists)
- The table can't have a row-level security policy.
- If any of the columns within a statistics object is masked with Dynamic Data Masking rules, in addition to the
SELECTpermission, the user must have theUNMASKpermission, or be a member of the db_ddladmin role.
In versions before SQL Server 2012 (11.x) Service Pack 1, the user must own the table or the user must be a member of the sysadmin fixed server role, the db_owner fixed database role, or the db_ddladmin fixed database role.
Note
To change the behavior back to the pre SQL Server 2012 (11.x) Service Pack 1 behavior, use Trace Flag 9485.
Permissions for Azure Synapse Analytics and Analytics Platform System (PDW)
DBCC SHOW_STATISTICS requires SELECT permission on the table or membership in the sysadmin fixed server role, the db_owner fixed database role, or the db_ddladmin fixed database role.
Limitations and Restrictions for Azure Synapse Analytics and Analytics Platform System (PDW)
DBCC SHOW_STATISTICS shows statistics stored in the Shell database at the Control node level. It doesn't show statistics that are auto-created by SQL Server on the Compute nodes.
DBCC SHOW_STATISTICS isn't supported on external tables.
In Microsoft Fabric, DBCC SHOW_STATISTICS only shows results for histogram statistics, not ACE-* statistics.
Examples: SQL Server and Azure SQL Database
A. Return all statistics information
The following example displays all statistics information for the AK_Address_rowguid index of the Person.Address table in the AdventureWorks2022 database.
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. Specify the HISTOGRAM option
This limits the statistics information displayed for Customer_LastName to the HISTOGRAM data.
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
Examples: Azure Synapse Analytics and Analytics Platform System (PDW)
C. Display the contents of one statistics object
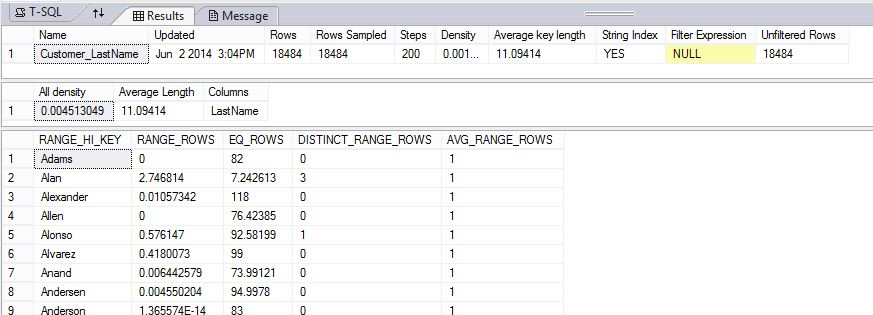
The following example creates a statistics object and then displays the contents of the Customer_LastName statistics on the DimCustomer table in the AdventureWorksPDW2022 sample database.
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
The results show the header, the density vector, and part of the histogram.
See also
- Statistics
- Statistics in Microsoft Fabric
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for