Cluster IP address resources fail on both nodes of a two-node, two-site cluster when one node disconnects from the public VLAN
This article describes the behavior that occurs when one node of a two-node, two-site cluster disconnects from the public cluster VLAN. In this case, the IP address resources and their corresponding cluster groups fail on both nodes.
Applies to: Windows Server 2019, Windows Server 2016, Windows Server 2012 R2
Symptoms
Consider the following scenario:
You have a two-site cluster that has one node in each site. The cluster uses a File Share Witness (FSW) resource. The cluster nodes are connected by the following networks:
- One stretched private VLAN
- One non-stretched public VLAN
In this scenario, one of the nodes disconnects from the public VLAN. The following figure shows the resulting configuration.
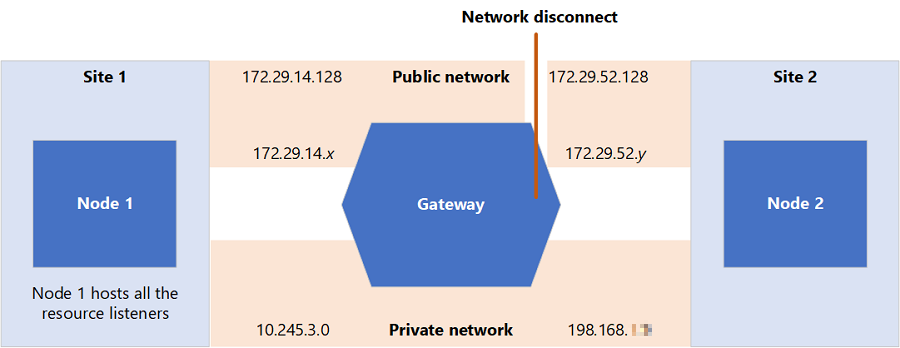
The cluster detects the interruption and marks the public VLAN network adapter on Node 2 as "Failed." Therefore, all the cluster IP address resources on Node 2 fail. The cluster groups that are associated with those resources also fail. The cluster generates messages that resemble the following:
000005ec.000011e4::2020/09/19-19:41:51.777 DBG [IM - public-1.0.0] Adding interface states for cross-subnet-route-only interfaces
000005ec.000011e4::2020/09/19-19:41:51.777 DBG [IM - public-1.0.0] Interface 1ee3567e-84f7-459a-a39e-a5c44de643fa has no up cross-subnet routes. Marking it as failed
Because the two sites cannot communicate across the public VLAN, the cluster also marks the public VLAN network adapter on Node 1 as "Failed." Therefore, all the cluster IP Address resources and the associated cluster groups on Node 1 fail.
00001790.000006ac::2020/09/19-19:41:51.780 INFO [IM] Changing the state of adapters according to result: <class mscs::InterfaceResult>
00001790.00001678::2020/09/19-19:41:51.780 DBG [IM] EventManager::ProcessInterfaceChanged: Ignoring event for Node1- 1.0.0-range that should not be published.
00001790.00001678::2020/09/19-19:41:51.780 DBG [NM] Got interface changed event for adapter Node1 - 1.0.0-range, new state 1
000012dc.00001664::2020/09/19-19:41:51.796 WARN [RES] IP Address <Cluster IP Address x.x.x.x>: WorkerThread: NetInterface 1ee3567e-84f7-459a-a39e-a5c44de643fa has failed. Failing resource.
In the end, lost connection to one node causes the cluster groups on both nodes to be in a failed state. You have to manually bring the nodes online again.
If the two cluster nodes were in the same site, a similar network disconnect would cause the public VLAN network adapter on Node 2 to fail in the same manner. However, in that case all the cluster groups on Node 2 would fail over to Node 1. The cluster IP address resources on Node 1 wouldn't fail.
Status
This behavior is by design. We recommend that you use four nodes instead of two nodes for multi-site clusters. Azure AzS HCI clusters require four nodes.
Workaround
To prevent this behavior, you can change your cluster configuration by using any of the following methods:
- Add at least one cluster node to each site. In this configuration, if one node on a site disconnects, the remaining node continues to communicate with the other site. The cluster resources on the remaining node and on the nodes in the unaffected site remain online.
- Add another cluster node at a third site. In this configuration, if one node disconnects, the two remaining nodes remain online, and cross-site communication continues.
- Change the private cluster network to a non-stretched VLAN. In this configuration, if one node disconnects, the cluster starts the arbitration algorithm to determine resource and quorum ownership.
If you have the configuration that is described in the "Symptoms" section and you have to disconnect a node in a controlled manner (such as for a planned maintenance window), prepare the cluster before you disconnect. Use one of the following approaches:
- Disable all networks except the public cluster VLAN.
- Shut down all the cluster nodes except one.
When you're ready to resume typical operations, start by enabling the networks (or restarting the nodes).
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for