How do I enable DirectML acceleration?
The DirectML device is enabled by default, assuming you have an appropriate DirectX 12 GPU available. TensorFlow operations will automatically be assigned to the DirectML device if possible.
If you're having trouble determining whether your model is running using DirectML acceleration or not, you can put tf.debugging.set_log_device_placement(True) as the first statement of your program and TensorFlow will print device placement information to the console.
How do I control device placement of specific operations?
As with any other device (see TensorFlow Guide: Use a GPU), you can use tf.device() to control which device to run on.
For running the TensorFlow 2 with DirectML backend using the TensorFlow-DirectML-Plugin, the device string is 'GPU', and will automatically override any other devices. To change the device name you can build tensorflow-directml-plugin from source.
For TensorFlow-DirectML 1.15, the device string is 'DML'.
import tensorflow as tf
tf.debugging.set_log_device_placement(True)
tf.enable_eager_execution()
# Explicitly place tensors on the DirectML device
with tf.device('/DML:0'):
a = tf.constant([1.0, 2.0, 3.0])
b = tf.constant([4.0, 5.0, 6.0])
c = tf.add(a, b)
print(c)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([5. 7. 9.], shape=(3,), dtype=float32)
I have multiple GPUs. How do I select which one is used by DirectML?
There are a couple of different ways to do this, depending on whether you want to control it process-wide or per-session (or both).
If you want to control which devices are visible to TensorFlow process-wide, use the DML_VISIBLE_DEVICES environment variable. If you want to control it on a per-session basis, use tf.GPUOptions.visible_device_list.
How do I use the `DML_VISIBLE_DEVICES` environment variable to control which GPU(s) get used by DirectML?
TensorFlow with DirectML supports a DML_VISIBLE_DEVICES environment variable, which takes the form of a comma-separated list of device IDs (also known as "adapter indices".) When set, only the device IDs in that list will be visible to TensorFlow process-wide. Devices excluded using DML_VISIBLE_DEVICES will not appear in the list of physical devices available to TensorFlow.
import tensorflow as tf
tf.debugging.set_log_device_placement(True)
tf.enable_eager_execution()
a = tf.constant([1.])
b = tf.constant([2.])
c = tf.add(a, b)
print(c)
Here is example output without DML_VISIBLE_DEVICES set:
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 0 (NVIDIA TITAN V)
DirectML: creating device on adapter 1 (AMD Radeon RX 5700 XT)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
With DML_VISIBLE_DEVICES="1":
DirectML device enumeration: found 1 compatible adapters.
DirectML: creating device on adapter 0 (AMD Radeon RX 5700 XT)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
Note that by restricting the visible devices to only index 1 (AMD Radeon RX 5700 XT), TensorFlow now assigns an ID of 0 to this device, and makes it the default.
You may also re-order devices using this environment variable. For example, setting DML_VISIBLE_DEVICES="1,0":
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 0 (AMD Radeon RX 5700 XT)
DirectML: creating device on adapter 1 (NVIDIA TITAN V)
Executing op Add in device /job:localhost/replica:0/task:0/device:DML:0
tf.Tensor([3.], shape=(1,), dtype=float32)
Notice that the two GPUs (NVIDIA TITAN V and AMD Radeon RX 5700 XT) have now switched places.
To prevent specific devices from being visible, you can supply an invalid ID (e.g. -1) in the comma-separated list. All device IDs after the invalid entry are ignored. You can also use this to disable DirectML acceleration altogether.
DML_VISIBLE_DEVICES="-1":
DirectML device enumeration: found 0 compatible adapters.
Executing op Add in device /job:localhost/replica:0/task:0/device:CPU:0
tf.Tensor([3.], shape=(1,), dtype=float32)
How do I use the `visible_device_list` session option to control which GPU(s) DirectML uses to run the session?
Similar to DML_VISIBLE_DEVICES, you can also set a similar string to control visible devices at a session level. The visible_device_list attribute is available on the GPUOptions class when creating your TensorFlow session.
import tensorflow as tf
a = tf.constant([1.])
b = tf.constant([2.])
c = tf.add(a, b)
gpu_config = tf.GPUOptions()
gpu_config.visible_device_list = "1"
session = tf.Session(config=tf.ConfigProto(gpu_options=gpu_config))
print(session.run(c))
DirectML device enumeration: found 2 compatible adapters.
DirectML: creating device on adapter 1 (AMD Radeon RX 5700 XT)
[3.]
You can read the TensorFlow GPUOptions API reference for more details.
Why does tensorflow-directml have high shared GPU memory usage?
When training large models, you might notice high usage of shared GPU memory in Task Manager:
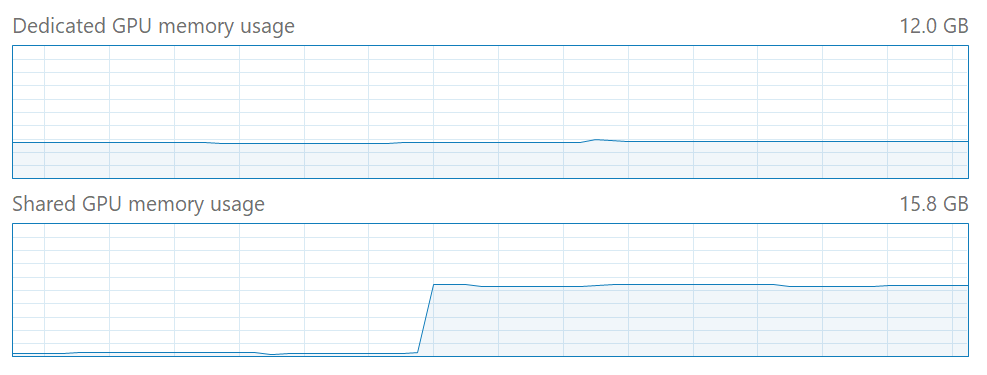
This is normal. TensorFlow-DirectML uses shared GPU memory as a staging area for upload and readback of tensor data to and from the GPU. Because of this, some increase in shared GPU memory utilization is expected.
Note that DirectML will always use dedicated GPU memory (for example, onboard VRAM) in preference to system memory, if available. However, some usage of shared GPU memory is still expected depending on how much staging memory DirectML requires.
Why doesn't DirectML utilize all of my available dedicated GPU memory?
Some devices, like the CUDA device, will by default reserve a large proportion of available dedicated GPU memory at startup.
The DirectML device, however, allocates memory on demand rather than reserving it up front. This behavior avoids starving other system processes of GPU memory, but can occasionally cause a slightly higher memory overhead.
If you prefer to reserve memory up front, then you can control that by setting the TF_FORCE_GPU_ALLOW_GROWTH environment variable to false.
For more information about the environment variables used by tensorflow-directml, see Environment variables.
I'm seeing DXGI_ERROR_DEVICE_REMOVED or DEVICE_HUNG errors. How do I resolve these?
Please refer to the instructions on GitHub: Troubleshooting GPU timeouts in tensorflow-directml.
Why am I getting device assignment or node colocation errors?
If you are seeing errors similar to the following:
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a
device for operation
tensorflow/core/common_runtime/colocation_graph.cc:983] Failed to place the
graph without changing the devices of some resources. Some of the operations
(that had to be colocated with resource generating operations) are not
supported on the resources' devices. Current candidate devices are [...]
This usually means that you're attempting to use an operator that's unsupported by the DirectML device, or a combination of operator and data type that's unsupported. For a full list of supported operators, see Roadmap (operators) on our wiki.