Solucione con Intelligent Insights los problemas de rendimiento de Azure SQL Database y Azure SQL Managed Instance.
Se aplica a:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
En esta página se proporciona información sobre los problemas de rendimiento de Azure SQL Database e Instancia administrada de Azure SQL detectados mediante el registro de recursos de Intelligent Insights. Tanto las métricas como los flujos de recursos se pueden transmitir en secuencias a los registros de Azure Monitor, Azure Event Hubs, Azure Storage o una solución de terceros para las funcionalidades personalizadas de informes y alertas de DevOps.
Nota:
Para ver una guía rápida de solución de problemas de rendimiento con Intelligent Insights, consulte en este documento el diagrama de flujo denominado Flujo de solución de problemas recomendado.
Intelligent Insights es una característica en versión preliminar que no está disponible en las siguientes regiones: Oeste de Europa, Norte de Europa, Oeste de EE. UU. 1 y Este de EE. UU. 1
Patrones de rendimiento de la base de datos detectables
Intelligent Insights detecta automáticamente los problemas de rendimiento en función de los tiempos de espera o los errores en la ejecución de consultas. Intelligent Insights genera patrones de rendimiento detectados en el registro de recursos. Los patrones de rendimiento detectables se resumen en la tabla siguiente.
| Patrones de rendimiento detectables | Azure SQL Database | Instancia administrada de Azure SQL |
|---|---|---|
| Alcance de los límites de recursos | Se alcanzó el límite de recursos del consumo de los recursos disponibles (DTU), los subprocesos de trabajo de la base de datos o las sesiones de inicio de sesión de la base de datos disponibles en la suscripción supervisada. Esto afecta al rendimiento. | El consumo de recursos de CPU está alcanzando los límites de recursos. Esto afecta al rendimiento de la base de datos. |
| Aumento de la carga de trabajo | Se detectó un aumento de la carga de trabajo o una acumulación continua de la carga de trabajo en la base de datos. Esto afecta al rendimiento. | Se ha detectado un aumento de la carga de trabajo. Esto afecta al rendimiento de la base de datos. |
| Presión de memoria | Los trabajos que solicitaron concesiones de memoria deben esperar a las asignaciones de memoria durante cantidades de tiempo considerables desde el punto de vista estadístico, o bien una mayor acumulación de los trabajos que han solicitado concesiones de memoria. Esto afecta al rendimiento. | Los trabajos que solicitaron concesiones de memoria esperan asignaciones de memoria durante un tiempo considerable desde el punto de vista estadístico. Esto afecta al rendimiento de la base de datos. |
| Bloqueo | Se detectó un bloqueo excesivo de la base de datos que afecta al rendimiento. | Se detectó un bloqueo excesivo de la base de datos que afecta al rendimiento de la base de datos. |
| Aumento de MAXDOP | La opción de grado máximo de paralelismo (MAXDOP) ha cambiado y afecta a la eficacia de la ejecución de consultas. Esto afecta al rendimiento. | La opción de grado máximo de paralelismo (MAXDOP) ha cambiado y afecta a la eficacia de la ejecución de consultas. Esto afecta al rendimiento. |
| Contención de PAGELATCH | Hay varios subprocesos que están intentando acceder de forma simultánea a las mismas páginas de búfer de datos en memoria, lo cual provoca un aumento de los tiempos de espera y contención de Pagelatch. Esto afecta al rendimiento. | Hay varios subprocesos que están intentando acceder de forma simultánea a las mismas páginas de búfer de datos en memoria, lo cual provoca un aumento de los tiempos de espera y contención de Pagelatch. Esto afecta al rendimiento de la base de datos. |
| Carencia de un índice | Se detectó que falta un índice que afecta al rendimiento. | Se detectó que falta un índice que afecta al rendimiento de la base de datos. |
| Nueva consulta | Se detectó una nueva consulta que afecta al rendimiento global. | Se detectó una nueva consulta que afecta al rendimiento global de la base de datos. |
| Estadística de espera aumentada | Se detectaron tiempos de espera aumentados de la base de datos que afectan al rendimiento. | Se detectaron tiempos de espera aumentados de la base de datos que afectan al rendimiento de la base de datos. |
| Contención de TempDB | Varios subprocesos están intentando acceder a los mismos recursos de tempdb, lo que produce un cuello de botella. Esto afecta al rendimiento. |
Varios subprocesos están intentando acceder a los mismos recursos de tempdb, lo que produce un cuello de botella. Esto afecta al rendimiento de la base de datos. |
| Escasez de DTU en el grupo elástico | La escasez de las eDTU disponibles en el grupo elástico afecta al rendimiento. | No está disponible para Instancia administrada de Azure SQL, ya que usa el modelo de núcleos virtuales. |
| Regresión de un plan | Se detectó un nuevo plan o un cambio en la carga de trabajo de un plan existente. Esto afecta al rendimiento. | Se detectó un nuevo plan o un cambio en la carga de trabajo de un plan existente. Esto afecta al rendimiento de la base de datos. |
| Cambio del valor de configuración de ámbito de base de datos | Se detectó un cambio de configuración en la base de datos que afecta a su rendimiento. | Se detectó un cambio de configuración en la base de datos que afecta a su rendimiento. |
| Cliente lento | El cliente de aplicación no puede consumir la salida de la base de datos lo suficientemente rápido. Esto afecta al rendimiento. | El cliente de aplicación no puede consumir la salida de la base de datos lo suficientemente rápido. Esto afecta al rendimiento de la base de datos. |
| Degradación del plan de tarifa | El cambio a un plan de tarifa anterior produjo una disminución de los recursos disponibles. Esto afecta al rendimiento. | El cambio a un plan de tarifa anterior produjo una disminución de los recursos disponibles. Esto afecta al rendimiento de la base de datos. |
Sugerencia
Para optimizar el rendimiento continuo de las bases de datos, habilite el ajuste automático. Esta característica de inteligencia integrada supervisa continuamente la base de datos, optimiza automáticamente los índices y aplica las correcciones del plan de ejecución de consultas.
En la siguiente sección se describen los patrones de rendimiento detectables con más detalle.
Alcance de los límites de recursos
Qué pasa
Este patrón de rendimiento detectable combina los problemas de rendimiento relacionados con el alcance de los límites de recursos disponibles, los límites de trabajo y los límites de sesión. Una vez que se detecta este problema de rendimiento, un campo de descripción del registro de diagnóstico indica si el problema de rendimiento está relacionado con el recurso, el trabajo o los límites de la sesión.
Normalmente, los recursos de Azure SQL Database se denominan recursos de DTU o de núcleo virtual, mientras que los de Instancia administrada de Azure SQL se conocen como recursos de núcleo virtual. El patrón de alcance de los límites de recursos se reconoce cuando la degradación detectada del rendimiento de consultas se produce debido a que se alcanza alguno de los límites de los recursos medidos.
El recurso de límites de sesión denota el número de inicios de sesión simultáneos disponibles en la base de datos. Este patrón de rendimiento se reconoce cuando las aplicaciones que se conectan a las bases de datos han alcanzado el número de inicios de sesión simultáneos disponibles para la base de datos. Si las aplicaciones intenten usar más sesiones que las que hay disponibles en una base de datos, el rendimiento de consultas resultará afectado.
El alcance de los límites de los trabajos es un caso concreto del alcance de los límites de los recursos, ya que no se cuentan los trabajos disponibles en el uso de DTU o núcleo virtual. Si se alcanzan los límites de trabajo de una base de datos, se puede producir un aumento de los tiempos de espera específicos de un recurso, lo que da lugar a una degradación del rendimiento de consultas.
Solución de problemas
El registro de diagnóstico genera códigos hash de consultas que han afectado al rendimiento y a los porcentajes de consumo de recursos. Puede usar esta información como punto de partida para optimizar la carga de trabajo de su base de datos. En concreto, puede optimizar las consultas que afectan a la degradación del rendimiento mediante la adición de índices. O bien, puede optimizar las aplicaciones con una distribución más uniforme de la carga de trabajo. En caso de que no pueda reducir las cargas de trabajo o realizar la optimización, considere la posibilidad de aumentar el plan de tarifa de su suscripción de la base de datos a fin de incrementar la cantidad de recursos disponibles.
Si se han alcanzado los límites de sesión disponibles, puede optimizar las aplicaciones mediante la reducción del número de inicios de sesión realizados en la base de datos. Si no puede reducir el número de inicios de sesión de las aplicaciones en la base de datos, considere la posibilidad de aumentar el plan de tarifa de suscripción de la base de datos. O bien, puede mover la base de datos y dividirla en varias bases de datos para una distribución más uniforme de la carga de trabajo.
Para conocer más sugerencias sobre cómo resolver los límites de sesión, vea Cómo abordar los límites del número máximo de inicios de sesión. Vea Introducción a los límites de recursos de un servidor para obtener información sobre los límites en los niveles de servidor y suscripción.
Aumento de la carga de trabajo
Qué pasa
Este patrón de rendimiento identifica los problemas causados por el aumento de la carga de trabajo, o en su forma más grave, una pila de cargas de trabajo.
Esta detección se realiza mediante la combinación de varias estadísticas. La métrica básica medida consiste en detectar un aumento de la carga de trabajo en comparación con la base de referencia de la carga de trabajo anterior. La otra forma de detección se basa en medir un gran aumento de los subprocesos de trabajo activos que son lo suficientemente grandes como para afectar al rendimiento de la consulta.
En su forma más grave, la carga de trabajo podría acumularse continuamente debido a la incapacidad de la base de datos para controlarla. Como resultado, la carga de trabajo sigue aumentando constantemente, que es la condición de acumulación de la carga de trabajo. Debido a esta condición, aumenta el tiempo que espera la carga de trabajo para ejecutarse. Esta condición representa uno de los problemas más graves de rendimiento de la base de datos. El problema se detecta mediante la supervisión del aumento del número de subprocesos de trabajo anulados.
Solución de problemas
El registro de diagnóstico proporciona el número de consultas cuya ejecución ha aumentado y el código hash de la consulta que contribuye más al aumento de la carga de trabajo. Puede usar esta información como punto de partida para optimizar la carga de trabajo. La consulta identificada como la que más contribuye al aumento de la carga de trabajo es especialmente útil como punto de partida.
También podría considerar la posibilidad de distribuir las cargas de trabajo a la base de datos de manera más uniforme. Otra manera de optimizar la consulta que afecta al rendimiento es agregar índices. Y también podría distribuir la carga de trabajo entre varias bases de datos. Si ninguna de estas soluciones es posible, podría aumentar el plan de tarifa de su suscripción de la base de datos a fin de aumentar la cantidad de recursos disponibles.
Presión de memoria
Qué pasa
Este patrón de rendimiento indica una degradación en el rendimiento actual de la base de datos provocada por la presión de memoria, o en su forma más grave, una condición de acumulación de memoria, si se compara con la base de referencia de rendimiento de los últimos 7 días.
La presión de memoria indica una condición de rendimiento en la que hay un número elevado de subprocesos de trabajo que solicitan concesiones de memoria. El alto volumen provoca una condición de uso de memoria alta en la que la base de datos no puede asignar de forma eficiente la memoria a todos los trabajos que lo solicitan. Una de las razones más comunes de este problema tiene que ver, por un lado, con la cantidad de memoria disponible para la base de datos. Por otro lado, un aumento en la carga de trabajo provoca el aumento de los subprocesos de trabajo y la presión de memoria.
La forma más grave de presión de memoria es la condición de acumulación de memoria. Esta condición indica que hay un número más alto de subprocesos de trabajo solicitando concesiones de memoria que consultas que liberan la memoria. También puede ocurrir que este número de subprocesos de trabajo que solicitan concesiones de memoria aumente continuamente (se acumulen) porque el motor de base de datos es incapaz de asignar memoria con la suficiente eficiencia como para satisfacer la demanda. La condición de acumulación de memoria representa uno de los problemas más graves de rendimiento de la base de datos.
Solución de problemas
El registro de diagnóstico proporciona los detalles del almacén de objetos de memoria con el distribuidor (es decir, el subproceso de trabajo) marcado como el mayor motivo del uso de memoria alta y las marcas de tiempo pertinentes. Puede usar esta información como base para la solución de problemas.
Puede optimizar o quitar consultas relacionadas con los distribuidores que realizan un mayor uso de memoria. También puede asegurarse de no consultar datos que no vaya a utilizar. Como procedimiento recomendado, use siempre la cláusula WHERE en sus consultas. Además, se recomienda que cree índices no agrupados para buscar los datos en lugar de examinarlos.
Otra manera de reducir la carga de trabajo es optimizarla o distribuirla entre varias bases de datos . Si ninguna de estas soluciones es posible, podría aumentar el plan de tarifa de su base de datos a fin de aumentar la cantidad de recursos de memoria disponibles para la base de datos.
Para obtener más sugerencias de solución de problemas, consulte Memory grants meditation: The mysterious SQL Server memory consumer with many names (Meditación sobre la concesión de memoria: el misterioso consumidor de memoria de SQL Server con muchos nombres). Para obtener más información sobre errores de memoria insuficiente en Azure SQL Database, vea Solución de problemas de errores de memoria insuficiente con Azure SQL Database.
Bloqueo
Qué pasa
Este patrón de rendimiento indica una degradación del rendimiento actual de la base de datos en el que se detectó un bloqueo excesivo de la base de datos en comparación con la base de referencia de rendimiento de los últimos 7 días.
En el sistema de administración de bases de datos relacionales moderno, el bloqueo es esencial para implementar sistemas de varios subprocesos en los que, siempre que sea posible, el rendimiento se maximiza mediante la ejecución de varios trabajos simultáneos y transacciones de la base de datos paralelas. El bloqueo en este contexto hace referencia al mecanismo de acceso integrado en el que solo una transacción puede tener acceso exclusivo a las filas, las páginas, las tablas y los archivos necesarios y no competir con ninguna otra transacción por los recursos. Cuando la transacción se realiza con los recursos cuyo uso tenía bloqueado, se libera el bloqueo en estos recursos y se permite que otras transacciones accedan a los recursos necesarios. Para más información sobre el bloqueo, consulte Bloquear el motor de base de datos.
Si las transacciones ejecutadas por el motor SQL esperan largos períodos de tiempo para el acceso a recursos cuyo uso tienen bloqueado, este tiempo de espera provoca la reducción del rendimiento de la ejecución de la carga de trabajo.
Solución de problemas
El registro de diagnóstico genera detalles del bloqueos que puede usar como base para la solución de problemas. Puede analizar las consultas de bloqueo notificadas, es decir, las consultas que presentan la degradación del rendimiento de bloqueo, y quitarlas. En algunos casos, es posible que la optimización de las consultas de bloqueo se realice correctamente.
La forma más sencilla y segura de mitigar el problema es mantener cortas las transacciones y reducir la superficie de bloqueo de las consultas más costosas. Puede dividir un lote grande de operaciones en operaciones más pequeñas. Se recomienda reducir la superficie de bloqueo de consulta. Para ello, haga que la consulta sea tan eficaz como sea posible. Reduzca las exploraciones grandes porque aumentar las posibilidades de interbloqueos y afectan negativamente al rendimiento general de la base de datos. En el caso de consultas identificadas que provocan bloqueo, puede crear nuevos índices o agregar columnas al índice existente para evitar recorridos de tabla.
Para ver más sugerencias, consulte:
- Descripción y resolución de problemas de bloqueo en Azure SQL
- Resolución de problemas de bloqueo causados por la extensión de bloqueo en SQL Server.
Aumento de MAXDOP
Qué pasa
Este patrón de rendimiento detectable indica una condición en la que se pararelizó un plan de ejecución de consultas elegido más de lo necesario. El optimizador de consultas puede mejorar el rendimiento de la carga de trabajo mediante la ejecución de consultas en paralelo para acelerar los procesos, siempre que sea posible. En algunos casos, los trabajos paralelos que procesan una consulta pasan más tiempo esperándose entre sí para sincronizar y combinar los resultados que ejecutando la misma consulta con menos trabajos en paralelo, o incluso, en algunos casos, con un subproceso de trabajo único.
El sistema experto analiza el rendimiento actual de la base de datos y lo compara con el período de base de referencia. De esta forma, determina si una consulta ejecutada anteriormente funciona más lenta que antes porque el plan de ejecución de consultas está más paralelizado de lo que debería.
La opción de configuración del servidor MAXDOP se usa para controlar el número de núcleos de CPU que se pueden usar para ejecutar la misma consulta en paralelo.
Solución de problemas
El registro de diagnóstico genera códigos hash de consulta relacionados con las consultas en las que ha aumentado la duración de la ejecución porque están más paralelizadas de lo que deberían. El registro también genera tiempos de espera CXP. Este tiempo representa el tiempo en que un subproceso de organizador o coordinador único (subproceso 0) espera a que todos los demás subprocesos finalicen, antes de combinar los resultados y seguir avanzando. Además, el registro de diagnóstico proporciona los tiempos de espera de las consultas con un rendimiento deficiente durante la ejecución general. Puede usar esta información como base para la solución de problemas.
En primer lugar, optimice o simplifique las consultas más complejas. Le recomendamos que divida los trabajos por lotes largos en partes más pequeñas. Además, asegúrese de que se han creado índices para admitir las consultas. También puede aplicar manualmente el grado máximo de paralelismo (MAXDOP) para una consulta que se marcó como con un rendimiento deficiente. Para configurar esta operación mediante T-SQL, consulte Configurar la opción de servidor MAXDOP.
Si se establece la opción de configuración del servidor MAXDOP en cero (0) como valor predeterminado, se indica que la base de datos puede usar todos los núcleos de CPU disponibles con el fin de paralelizar los subprocesos para ejecutar una sola consulta. La configuración de MAXDOP en uno (1) indica que solo un núcleo puede usarse para la ejecución de una única consulta. En la práctica, esto significa que el paralelismo se ha desactivado. En función de cada caso, los núcleos disponibles para la base de datos y la información de registro de diagnóstico, puede ajustar la opción MAXDOP al número de núcleos usados para la ejecución de consultas en paralelo que podrán resolver el problema en su caso.
Contención de PAGELATCH
Qué pasa
Este patrón de rendimiento indica la degradación del rendimiento actual de la carga de trabajo de la base de datos debido a una contención de Pagelatch en comparación con la base de referencia de la carga de trabajo de los últimos 7 días.
Los bloqueos temporales son mecanismos de sincronización ligeros que se usan para permitir el multithreading. Garantizan la coherencia de las estructuras en memoria que incluyen índices, páginas de datos y otras estructuras internas.
Existen muchos tipos de bloqueos temporales. Por motivos de simplicidad, los bloqueos temporales de búfer se usan para proteger las páginas en memoria en el grupo de búferes. Los bloqueos temporales de E/S se usan para proteger las páginas que aún no se han cargado en el grupo de búferes. Siempre que se escriben o se leen datos en una página del grupo de búferes, primero es necesario que un subroceso de trabajo adquiera un bloqueo temporal de búferes para la página. Cada vez que un subproceso de trabajo intenta acceder a una página que aún no está disponible en el grupo de búferes en memoria, se realiza una solicitud de E/S para cargar la información necesaria desde el almacenamiento. Esta secuencia de eventos indica una forma más grave de degradación del rendimiento.
La contención en los bloqueos temporales de páginas se produce cuando varios subprocesos intentan adquirir simultáneamente bloqueos temporales en la misma estructura en memoria, lo que introduce un tiempo de espera mayor en la ejecución de la consulta. En el caso de la contención de E/S de PAGELATCH, cuando es necesario acceder a los datos desde el almacenamiento, este tiempo de espera es incluso mayor. Esto puede afectar considerablemente al rendimiento de la carga de trabajo. La contención de PAGELATCH es el escenario más común de subprocesos que se esperan mutuamente y compiten por recursos en varios sistemas de CPU.
Solución de problemas
El registro de diagnóstico genera detalles de contención de Pagelatch. Puede usar esta información como base para la solución de problemas.
Dado que Pagelatch es un mecanismo de control interno, se determina automáticamente cuándo se debe usar. Las decisiones de aplicación, incluido el diseño de esquema, pueden afectar al comportamiento de Pagelatch debido al comportamiento determinista de los bloqueos temporales.
Un método para controlar la contención de bloqueos temporales es reemplazar una clave de índice secuencial por una clave no secuencial a fin de distribuir uniformemente las inserciones en un intervalo de índices. Normalmente, una columna inicial en el índice distribuye la carga de trabajo de manera proporcional. Otro método que se debe tener en cuenta es la creación de particiones de tablas. La creación de un esquema de creación de particiones por hash con una columna calculada en una tabla con particiones es un enfoque común para mitigar la contención de bloqueos temporales excesivos. En el caso de la contención de E/S de PAGELATCH, la introducción de índices ayuda a mitigar este problema de rendimiento.
Para más información, consulte Diagnosing and Resolving Latch Contention on SQL Server (Diagnóstico y resolución de la contención de bloqueo temporal en SQL Server) (descarga de PDF).
Carencia de un índice
Qué pasa
Este patrón de rendimiento indica la degradación del rendimiento actual de la carga de trabajo de la base de datos en comparación con la base de referencia de los últimos 7 días debido a que falta un índice.
Se usa un índice para acelerar el rendimiento de las consultas. Proporciona acceso rápido a los datos de la tabla al reducir el número de páginas del conjunto de datos que se deben visitar o examinar.
Las consultas específicas que provocaron una degradación del rendimiento se identifican mediante esta detección para la que la creación de índices resultaría beneficiosa para el rendimiento.
Solución de problemas
El registro de diagnóstico genera códigos hash para las consultas que se identificaron que afectaban al rendimiento de la carga de trabajo. Puede crear índices para estas consultas. También puede optimizar o quitar estas consultas si no son necesarias. Una buena práctica para el rendimiento es evitar la consulta de datos que no se usen.
Sugerencia
¿Sabía que la inteligencia integrada puede administrar automáticamente los índices con mejor rendimiento para sus bases de datos?
Para optimizar continuamente el rendimiento, se recomienda que habilite el ajuste automático. Esta característica única de inteligencia integrada supervisa continuamente la base de datos y, de forma automática, optimiza y crea índices para las bases de datos.
Nueva consulta
Qué pasa
Este patrón de rendimiento indica que se detectó una nueva consulta que presenta un rendimiento deficiente y que afecta al rendimiento de la carga de trabajo en comparación con la base de referencia de rendimiento de 7 días.
Escribir una consulta que tenga un buen rendimiento a veces puede ser una tarea complicada. Para más información sobre cómo escribir consultas, consulte Writing SQL queries (Escritura de consultas SQL). Para optimizar el rendimiento de las consultas existentes, consulte Optimizar consultas.
Solución de problemas
El registro de diagnóstico genera información de hasta las dos nuevas consultas que realizan un mayor consumo de la CPU, incluidos sus códigos hash de consulta. Dado que la consulta detectada afecta al rendimiento de la carga de trabajo, puede optimizar la consulta. Una buena práctica consiste en recuperar únicamente los datos que necesite usar. También se recomienda el uso de consultas con una cláusula WHERE. Además, se recomienda simplificar las consultas complejas y dividirlas en consultas más pequeñas. Otra buena práctica consiste en dividir las consultas por lote de gran tamaño en consultas por lote más pequeñas. La introducción de índices para las nuevas consultas suele ayudar a mitigar este problema de rendimiento.
Considere la posibilidad de usar Información de rendimiento de consultas en Azure SQL Database.
Estadística de espera aumentada
Qué pasa
Este patrón de rendimiento detectable indica una degradación del rendimiento de la carga de trabajo en la que se identifican consultas con un rendimiento deficiente en comparación con la base de referencia de carga de trabajo de los últimos 7 días.
En este caso, el sistema no puede clasificar las consultas con un rendimiento deficiente en cualquier otra categoría de rendimiento detectable estándar, pero detectó la estadística de espera responsable de la regresión. Por lo tanto, las considera consultas con estadísticas de espera aumentada, donde también se expone la estadística de espera aumentada responsable de la regresión.
Solución de problemas
El registro de diagnóstico genera información sobre los detalles de los tiempos de espera aumentada y los códigos hash de las consultas afectadas.
Dado que el sistema no pudo identificar correctamente la causa principal de las consultas con un rendimiento deficiente, la información de diagnóstico es un buen punto de partida para la solución manual de problemas. Puede optimizar el rendimiento de estas consultas. Una buena práctica es capturar solo los datos que necesite y simplificar y dividir las consultas complejas en otras más pequeñas.
Para más información sobre cómo optimizar el rendimiento de las consultas, consulte Optimizar consultas.
Contención de TempDB
Qué pasa
Este patrón de rendimiento detectable indica una condición de rendimiento de la base de datos en la que existe un cuello de botella de subprocesos que intentan acceder a los recursos de tempdb. (Esta condición no está relacionada con la E/S). El escenario típico de este problema de rendimiento consiste en cientos de consultas simultáneas que crean, usan y colocan tablas pequeñas de tempdb. El sistema detectó que aumentó el número de consultas simultáneas que usan las mismas tablas de tempdb con una significación estadística suficiente que afecta al rendimiento de la base de datos en comparación con la base de referencia de rendimiento de los últimos 7 días.
Solución de problemas
El registro de diagnóstico genera detalles de contención de tempdb. Puede usar la información como punto de partida para solucionar el problema. Hay dos cosas que puede hacer para solucionar este tipo de contención y mejorar el rendimiento de la carga de trabajo general: la primera es dejar de usar las tablas temporales y la segunda usar tablas optimizadas para memoria.
Para más información, consulte Introducción a las tablas optimizadas para memoria.
Escasez de DTU en el grupo elástico
Qué pasa
Este patrón de rendimiento detectable indica una degradación del rendimiento actual de la carga de trabajo de la base de datos en comparación con la base de referencia de los últimos 7 días. El motivo es la escasez de DTU disponibles en el grupo elástico de su suscripción.
Los recursos del grupo elástico de Azure se usan como un grupo de recursos disponibles que se comparten entre varias bases de datos con finalidades de escala. Cuando los recursos de eDTU disponibles en su grupo elástico no son lo suficientemente grandes como para admitir todas las bases de datos del grupo, el sistema detecta el problema de rendimiento por escasez de DTU en el grupo elástico.
Solución de problemas
El registro de diagnóstico genera información sobre el grupo elástico, enumera las bases de datos que realizan un mayor consumo de DTU y proporciona un porcentaje de la DTU del grupo que usa la base de datos que más consume.
Como esta condición de rendimiento está relacionada con varias bases de datos que usan el mismo grupo de eDTU en el grupo elástico, los pasos de solución de problemas se centran en las bases de datos que más consumen DTU. Puede reducir la carga de trabajo en las bases de datos que más consumen, lo que incluye la optimización de las consultas que más consumen en esas bases de datos. También puede asegurarse de no consultar datos que no vaya a utilizar. Otro enfoque consiste en optimizar las aplicaciones con las bases de datos que realizan un mayor consumo de DTU y redistribuir la carga de trabajo entre varias bases de datos.
Si no es posible reducir y optimizar la carga de trabajo actual en las bases de datos que más consumen DTU, considere la posibilidad de aumentar el plan de tarifa de su grupo elástico. Dicho aumento da como resultado el aumento de las DTU disponibles en el grupo elástico.
Regresión de un plan
Qué pasa
Este patrón de rendimiento detectable indica una condición en la que la base de datos usa un plan de ejecución de consultas poco óptimo. El plan poco óptimo normalmente provoca un aumento de la ejecución de consultas, lo que incrementa los tiempos de espera de las consultas actuales y otras.
El motor de base de datos determina el plan de ejecución de consultas con el menor costo para la ejecución de una consulta. Dado que el tipo de las consultas y las cargas de trabajo cambia, a veces los planes existentes ya no son eficaces, o es posible que el motor de base de datos no haya realizado una buena evaluación. A fin de corregir esto, es posible forzar manualmente los planes de ejecución de consulta.
Este patrón de rendimiento detectable combina tres casos diferentes de regresión de un plan: regresión de un plan nuevo, regresión de un plan anterior y carga de trabajo cambiada en los planes existentes. El tipo determinado de regresión del plan que se ha producido se proporciona en la propiedad details del registro de diagnóstico.
La condición de regresión de un plan nuevo hace referencia a un estado en el que el motor de base de datos empieza a ejecutar un nuevo plan de ejecución de consultas que no es tan eficaz como el anterior. La condición de regresión de un plan anterior se refiere al estado en que el motor de base de datos pasa de usar un nuevo plan más eficaz al plan anterior, que no es tan eficaz como el nuevo. La regresión de la carga de trabajo cambiada en los planes existentes se refiere al estado en el que el plan nuevo y el anterior se alternan continuamente, aunque la balanza se decanta más por el plan de rendimiento deficiente.
Para más información sobre las regresiones de un plan, consulte What is plan regression in SQL Server (Qué es la regresión de un plan en SQL Server).
Solución de problemas
El registro de diagnóstico genera los códigos hash de consulta, el identificador de un plan bueno, el identificador de un plan malo y los identificadores de consulta. Puede usar esta información como base para la solución de problemas.
Puede analizar qué plan le puede ir mejor para sus consultas específicas que puede identificar con los códigos hash de consulta proporcionados. Una vez determine el plan que funciona mejor para sus consultas, puede forzarlo manualmente.
Para más información, consulte How SQL Server prevents plan regressions (Cómo SQL Server impide las regresiones del plan).
Sugerencia
¿Sabía que la característica de inteligencia integrada puede administrar automáticamente los planes de ejecución de consultas con mejor rendimiento para sus bases de datos?
Para optimizar continuamente el rendimiento, se recomienda que habilite el ajuste automático. Esta característica de inteligencia integrada supervisa continuamente la base de datos y, de forma automática, optimiza y crea los planes de ejecución de consultas con mejor rendimiento para sus bases de datos.
Cambio del valor de configuración de ámbito de base de datos
Qué pasa
Este patrón de rendimiento detectable indica una condición en la que un cambio en la configuración del ámbito de base de datos provoca la regresión del rendimiento detectado en comparación con el comportamiento de la carga de trabajo de base de datos de los últimos 7 días. Este patrón indica que el cambio reciente realizado en la configuración de ámbito de base de datos no parece ser beneficioso para el rendimiento de la base de datos.
Los cambios de configuración de ámbito de base de datos se pueden establecer para cada base de datos individual. Esta configuración se usa en función de cada caso para optimizar el rendimiento individual de su base de datos. Para cada base de datos individual se pueden configurar las opciones siguientes: MAXDOP, LEGACY_CARDINALITY_ESTIMATION, PARAMETER_SNIFFING, QUERY_OPTIMIZER_HOTFIXES y CLEAR PROCEDURE_CACHE.
Solución de problemas
El registro de diagnóstico genera los cambios en la configuración de ámbito de base de datos realizados recientemente que han provocado la degradación del rendimiento en comparación con el comportamiento de la carga de trabajo de los últimos 7 días. Se pueden revertir los cambios de configuración a los valores anteriores. También puede ajustar los valores uno a uno hasta alcanzar el nivel de rendimiento deseado. Puede copiar los valores de configuración de ámbito de la base de datos de una base de datos similar con un rendimiento satisfactorio. Si no puede solucionar los problemas de rendimiento, revierta a los valores predeterminados e intente ajustar a partir de esta base de referencia.
Para más información sobre cómo optimizar la configuración de ámbito de base de datos y la sintaxis de T-SQL para cambiar la configuración, consulte Modificar configuración de ámbito de base de datos (Transact-SQL).
Cliente lento
Qué pasa
Este patrón de rendimiento detectable indica una condición en la que el cliente que usa la base de datos no puede consumir la salida de la base de datos a la misma velocidad a la que la base de datos envía los resultados. Dado que la base datos no está almacenando los resultados de las consultas ejecutadas en un búfer, se ralentiza y espera a que el cliente consuma las salidas de consultas transmitidas antes de continuar. Esta condición también podría estar relacionada con una red que no es lo suficientemente rápida como para transmitir las salidas de la base de datos al cliente de consumo.
Esta condición solo se genera si se detecta una regresión del rendimiento en comparación con el comportamiento de la carga de trabajo de la base de datos de los últimos 7 días. Este problema de rendimiento se detecta únicamente si se ha producido una degradación del rendimiento estadísticamente significativa en comparación con el comportamiento de rendimiento anterior.
Solución de problemas
Este patrón de rendimiento detectable indica una condición del lado cliente. Es necesario solucionar los problemas en la aplicación del lado cliente o la red del cliente. El registro de diagnóstico genera los códigos hash de consulta y los tiempos de espera que parecen estar esperando lo máximo hasta que el cliente los consuma en las últimas dos horas. Puede usar esta información como base para la solución de problemas.
Puede optimizar el rendimiento de la aplicación para el consumo de estas consultas. También puede considerar los posibles problemas de latencia de la red. Como el problema de degradación del rendimiento estaba relacionado con los cambios en la base de referencia de rendimiento de los últimos 7 días, puede investigar si los cambios recientes en la condición de la aplicación o de la red provocó este evento de regresión del rendimiento.
Degradación del plan de tarifa
Qué pasa
Este patrón de rendimiento detectable indica una condición en la que se degrada el plan de tarifa de la suscripción de la base de datos. Debido a la reducción de los recursos (DTU) disponibles para la base de datos, el sistema detecta una disminución en el rendimiento actual de la base de datos en comparación con la base de referencia de los últimos 7 días.
Además, podría haber una condición en la que el plan de tarifa de la suscripción de la base de datos se degradara y, luego, se actualizara al nivel más alto en un período de tiempo muy corto. La detección de esta degradación temporal del rendimiento se muestra en la sección de detalles del registro de diagnóstico como degradación y actualización del plan de tarifa.
Solución de problemas
Si ha reducido su plan de tarifa (y, por lo tanto, las DTU disponibles) y le satisface el rendimiento, no tiene que hacer nada. Si ha reducido el plan de tarifa y no está satisfecho con el rendimiento de la base de datos, reduzca las cargas de trabajo de la base de datos o considere la posibilidad de aumentar el plan de tarifa a un nivel superior.
Flujo de solución de problemas recomendado
Siga el diagrama de flujo para obtener un enfoque recomendado para solucionar los problemas de rendimiento mediante Intelligent Insights.
Navegue a Azure SQL Analytics y acceda a Intelligent Insights a través de Azure Portal. Intente ubicar la alerta de rendimiento entrante y selecciónela. Identifique qué ocurre en la página de detecciones. Observe el análisis proporcionado de la causa principal del problema, el texto de la consulta, las tendencias del tiempo de consulta y la evolución del incidente. Para intentar resolverlo, use la recomendación de Intelligent Insights para mitigar el problema de rendimiento .
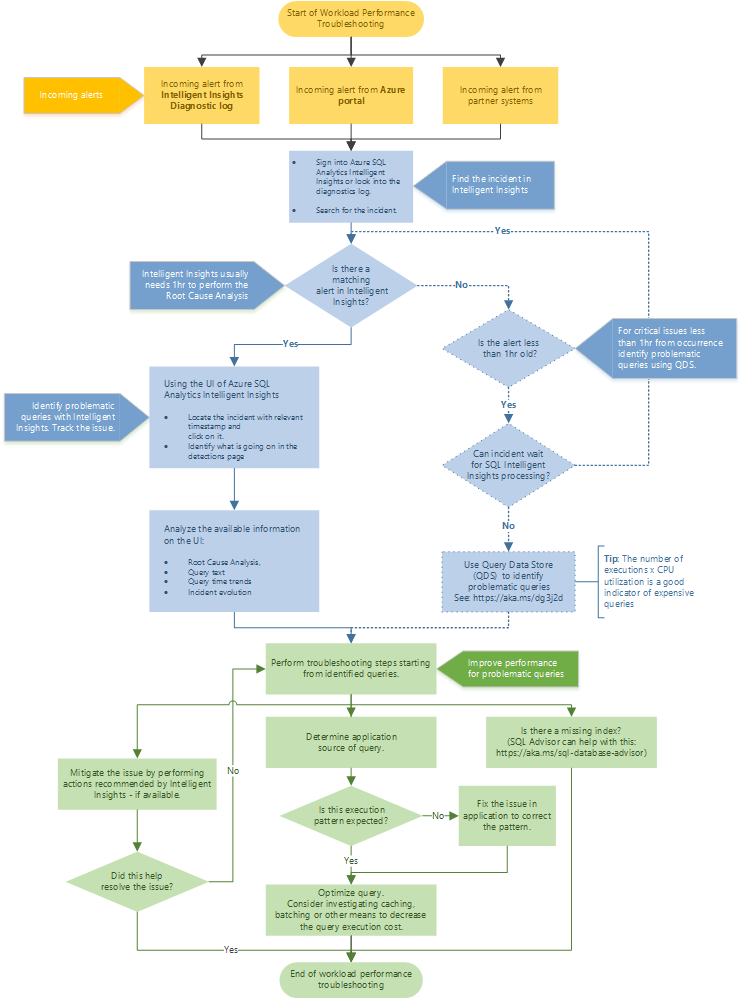
Sugerencia
Seleccione el diagrama de flujo para descargar una versión en PDF.
Intelligent Insights normalmente necesita una hora para realizar el análisis de la causa principal del problema de rendimiento. Si no puede encontrar el problema en Intelligent Insights y es importante para usted, use el Almacén de consultas para identificar manualmente la causa principal del problema de rendimiento. (Normalmente, estos problemas se han producido hace menos de una hora). Para más información, consulte Supervisión del rendimiento mediante el almacén de consultas.
Pasos siguientes
- Conozca los conceptos de Intelligent Insights.
- Use el registro de diagnóstico del rendimiento de Intelligent Insights.
- Realice la supervisión con Azure SQL Analytics.
- Aprenda a recopilar y usar los datos de registro provenientes de los recursos de Azure.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de