Esta arquitectura de referencia muestra cómo realizar la puntuación por lotes con modelos de R mediante Azure Batch. Azure Batch funciona bien con cargas de trabajo intrínsecamente paralelas e incluye la programación de trabajos y la administración de procesos. La inferencia por lotes (puntuación) se usa ampliamente para segmentar clientes, pronosticar ventas, predecir comportamientos de los clientes, predecir el mantenimiento o mejorar la ciberseguridad.
Descargue un archivo Visio de esta arquitectura.
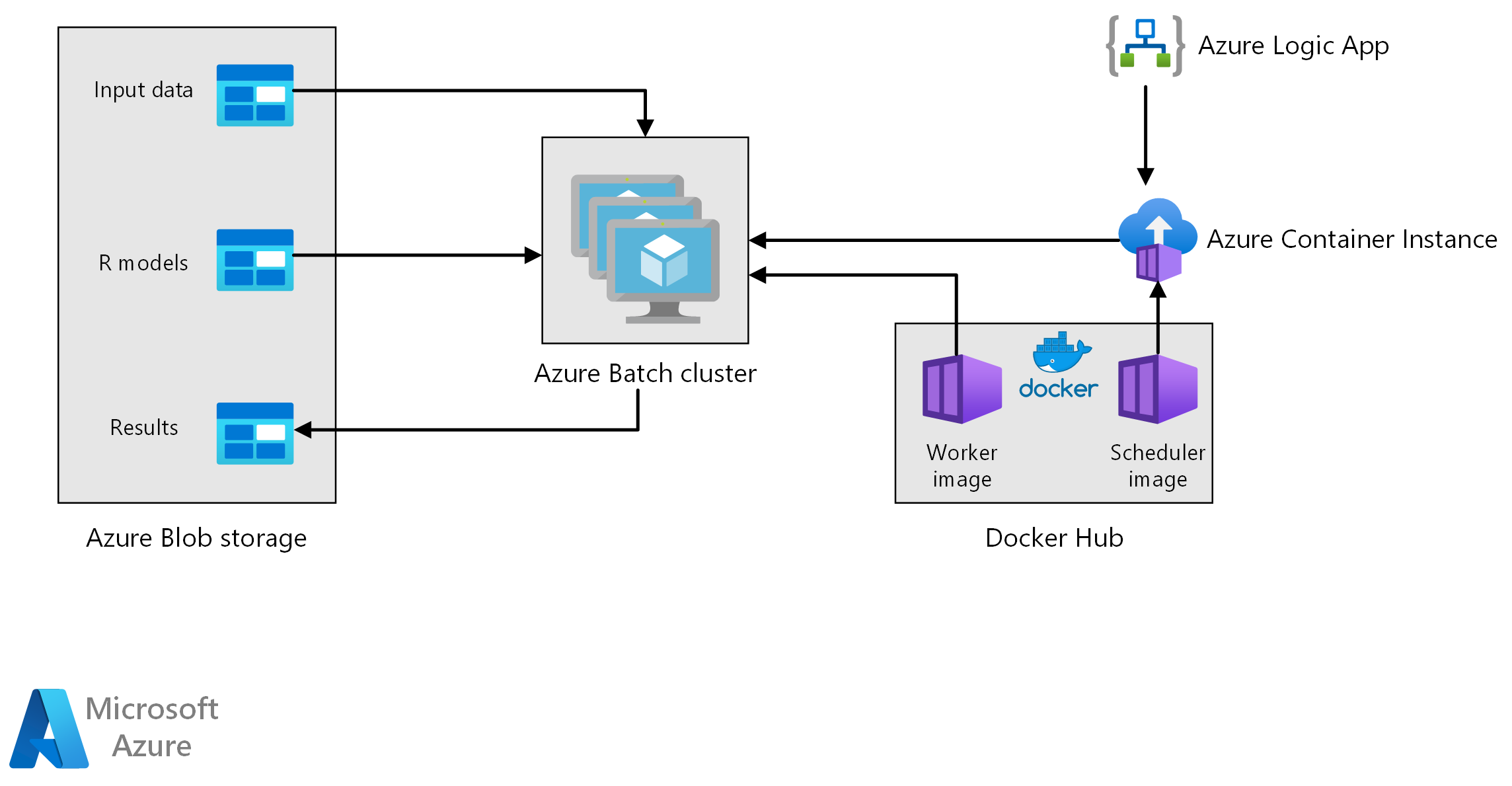
Flujo de trabajo
Esta arquitectura consta de los siguientes componentes.
Azure Batch ejecuta trabajos de generación de previsión en paralelo en un clúster de máquinas virtuales. Las predicciones se realizan mediante modelos de Machine Learning entrenados previamente e implementados en R. Azure Batch puede escalar automáticamente el número de máquinas virtuales en función del número de trabajos enviados al clúster. En cada nodo, un script de R se ejecuta dentro de un contenedor de Docker para puntuar los datos y generar las previsiones.
Azure Blob Storage almacena los datos de entrada, los modelos de aprendizaje automático entrenados previamente y los resultados de la previsión. Ofrece un almacenamiento rentable para el rendimiento que requiere esta carga de trabajo.
Azure Container Instances ofrece proceso sin servidor a petición. En este caso, se implementa una instancia de contenedor según una programación para desencadenar los trabajos de Batch que generan las previsiones. Los trabajos de Batch se desencadenan desde un script de R mediante el paquete doAzureParallel. La instancia de contenedor se cierra automáticamente una vez finalizados los trabajos.
Azure Logic Apps desencadena todo el flujo de trabajo mediante la implementación de las instancias de contenedor según una programación. Un conector Azure Container Instances en Logic Apps permite implementar una instancia en un intervalo de eventos desencadenadores.
Componentes
Detalles de la solución
Aunque el escenario siguiente se basa en la previsión de ventas de tiendas minoristas, su arquitectura se puede generalizar para cualquier escenario que requiera la generación de predicciones a mayor escala mediante modelos de R. Hay disponible una implementación de referencia de esta arquitectura en GitHub.
Posibles casos de uso
Una cadena de supermercados debe hacer una previsión de las ventas de productos para el próximo trimestre. La previsión permite a la empresa administrar mejor su cadena de suministro y asegurarse de que puede satisfacer la demanda de productos en cada una de sus tiendas. La empresa actualiza sus previsiones cada semana a medida que los nuevos datos de ventas de la semana anterior estén disponibles y se establezca la estrategia de marketing del producto para el próximo trimestre. Se generan previsiones por cuantiles para estimar la incertidumbre de las previsiones de ventas individuales.
El procesamiento implica los siguientes pasos:
Una aplicación lógica de Azure desencadena el proceso de generación de previsión una vez por semana.
La aplicación lógica inicia una instancia de Azure Container que ejecuta el contenedor de Docker de Scheduler, que desencadena los trabajos de puntuación en el clúster de Batch.
Los trabajos de puntuación se ejecutan en paralelo en los nodos del clúster de Batch. Cada nodo:
Extrae la imagen de Docker de trabajo e inicia un contenedor.
Lee los datos de entrada y los modelos de R entrenados previamente de Azure Blob Storage.
Puntúa los datos para generar previsiones.
Escribe los resultados de la previsión en Blob Storage.
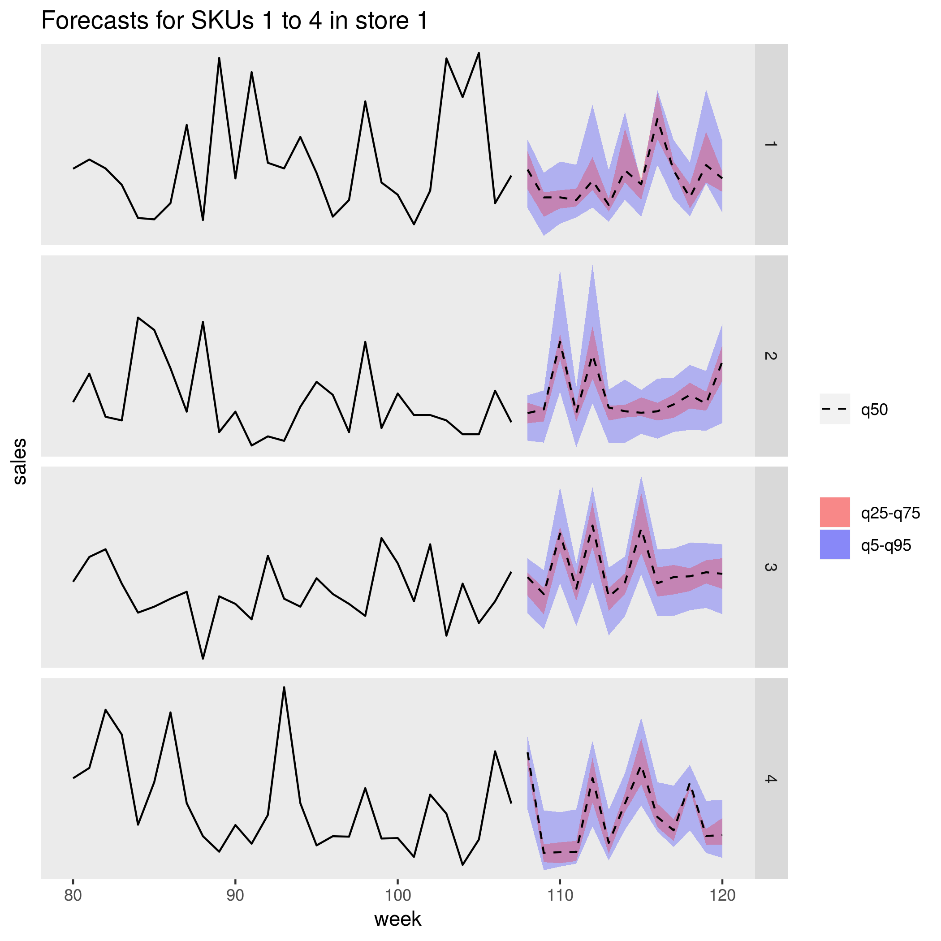
En la imagen siguiente se muestran las ventas previstas de cuatro productos (SKU) en una tienda. La línea negra es el historial de ventas, la línea discontinua es la previsión de la mediana (q50), la banda rosa representa los percentiles veinticinco y setenta y cinco, y la banda azul representa los percentiles cincuenta y noventa y cinco.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Rendimiento
Implementación en contenedores
Con esta arquitectura, todos los scripts de R se ejecutan en contenedores de Docker. El uso de contenedores garantiza que los scripts se ejecuten siempre en un entorno coherente, con la misma versión de R y las mismas versiones de paquetes. Se usan imágenes independientes de Docker para los contenedores de programador y de trabajo, ya que cada uno tiene un conjunto diferente de dependencias de paquetes de R.
Azure Container Instances proporciona un entorno sin servidor para ejecutar el contenedor de Scheduler. El contenedor de Scheduler ejecuta un script de R que desencadena los trabajos de puntuación individuales que se ejecutan en un clúster de Azure Batch.
Cada nodo del clúster de Batch ejecuta el contenedor de trabajo, que ejecuta el script de puntuación.
Paralelización de la carga de trabajo
Cuando haya datos de puntuación por lotes con modelos de R, tenga en cuenta cómo paralelizar la carga de trabajo. Los datos de entrada se deben particionar para que la operación de puntuación se pueda distribuir en los nodos del clúster. Pruebe diferentes enfoques para detectar la mejor opción para distribuir la carga de trabajo. En cada caso, tenga en cuenta lo siguiente:
- Cantidad de datos que se pueden cargar y procesar en la memoria de un solo nodo.
- Sobrecarga de iniciar cada trabajo de Batch.
- Sobrecarga de cargar los modelos de R.
En el escenario que se usa en este ejemplo, los objetos de modelo son grandes y solo se tarda unos segundos en generar una previsión para cada producto. Por esta razón, puede agrupar los productos y ejecutar un solo trabajo de Batch por nodo. Un bucle dentro de cada trabajo genera previsiones para los productos de forma secuencial. Este método es la forma más eficaz de paralelizar esta carga de trabajo concreta. Evita la sobrecarga que supone iniciar muchos trabajos de Batch más pequeños y cargar repetidamente los modelos de R.
Un enfoque alternativo es desencadenar un trabajo de Batch por producto. Azure Batch forma automáticamente una cola de trabajos y los envía para que se ejecuten en el clúster a medida que los nodos estén disponibles. Use escalado automático para ajustar el número de nodos del clúster en función del número de trabajos. Este enfoque resulta útil si se tarda un tiempo relativamente largo en completar cada operación de puntuación, lo que justifica la sobrecarga que supone iniciar los trabajos y volver a cargar los objetos del modelo. Este enfoque también es más sencillo de implementar y ofrece la flexibilidad de usar el escalado automático, una consideración importante si el tamaño de la carga de trabajo total no se conoce de antemano.
Supervisión de trabajos de Azure Batch
Supervise y finalice los trabajos de Batch del panel Trabajos de la cuenta de Batch en Azure Portal. Supervise el clúster de Batch, incluido el estado de cada uno de los nodos, en el panel Grupos.
Registro con doAzureParallel
El paquete doAzureParallel recopila automáticamente los registros de todas las propiedades stdout/stderr de cada trabajo enviado en Azure Batch. Estos registros se encuentran en la cuenta de almacenamiento que se creó durante la instalación. Para verlos, use una herramienta de exploración de almacenamiento como Explorador de Azure Storage o Azure Portal.
Para depurar rápidamente trabajos por lotes durante el desarrollo, vea los registros en la sesión de R local. Para más información, consulte Configuración y envío de ejecuciones de entrenamiento.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Los recursos de proceso que se usan en esta arquitectura de referencia son los componentes más caros. En este escenario, se crea un clúster de tamaño fijo cada vez que se desencadena el trabajo y se cierra después de que el trabajo se haya completado. Solo se generan costos mientras los nodos del clúster se inician, se ejecutan o se cierran. Este enfoque es adecuado para un escenario en el que los recursos de proceso necesarios para generar las previsiones permanecen relativamente constantes de un trabajo a otro.
En escenarios en los que no se conoce de antemano la cantidad de proceso necesaria para completar el trabajo, podría ser más adecuado usar el escalado automático. Con este enfoque, el tamaño del clúster se escala o reduce verticalmente en función del tamaño del trabajo. Azure Batch admite un intervalo de fórmulas de escalado automático que se pueden establecer al definir el clúster mediante la API de doAzureParallel.
En algunos escenarios, el tiempo de un trabajo a otro podría ser demasiado corto para apagar e iniciar el clúster. En estos casos, mantenga el clúster en ejecución entre trabajos si es necesario.
Azure Batch y doAzureParallel admiten el uso de máquinas virtuales de prioridad baja. Estas máquinas virtuales tienen un gran descuento, pero corren el riesgo de ser utilizadas por otras cargas de trabajo de mayor prioridad. Por lo tanto, no se recomienda el uso de máquinas virtuales de prioridad baja para cargas de trabajo de producción críticas. No obstante, estas pueden resultar útiles para cargas de trabajo experimentales o de desarrollo.
Implementación de este escenario
Para implementar esta arquitectura de referencia, siga los pasos descritos en el repositorio de GitHub.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Angus Taylor | Científico de datos sénior
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.