Tutorial: Consulta de un contenedor de Docker de Linux para SQL Server en una red virtual mediante un cuaderno de Azure Databricks
Con este tutorial aprenderá a integrar Azure Databricks con un contenedor de Docker de Linux para SQL Server en una red virtual.
En este tutorial, aprenderá a:
- Implementar un área de trabajo de Azure Databricks en una red virtual
- Instalar una máquina virtual Linux en una red pública
- Instalación de Docker
- Instalar el contenedor del docker de Microsoft SQL Server en Linux
- Consultar el servidor de SQL Server con JDBC desde un cuaderno de Databricks
Prerrequisitos
Instale Ubuntu para Windows.
Descargue SQL Server Management Studio.
Creación de una máquina virtual con Linux
En Azure Portal, seleccione el icono de Máquinas virtuales. Seguidamente, seleccione + Agregar.
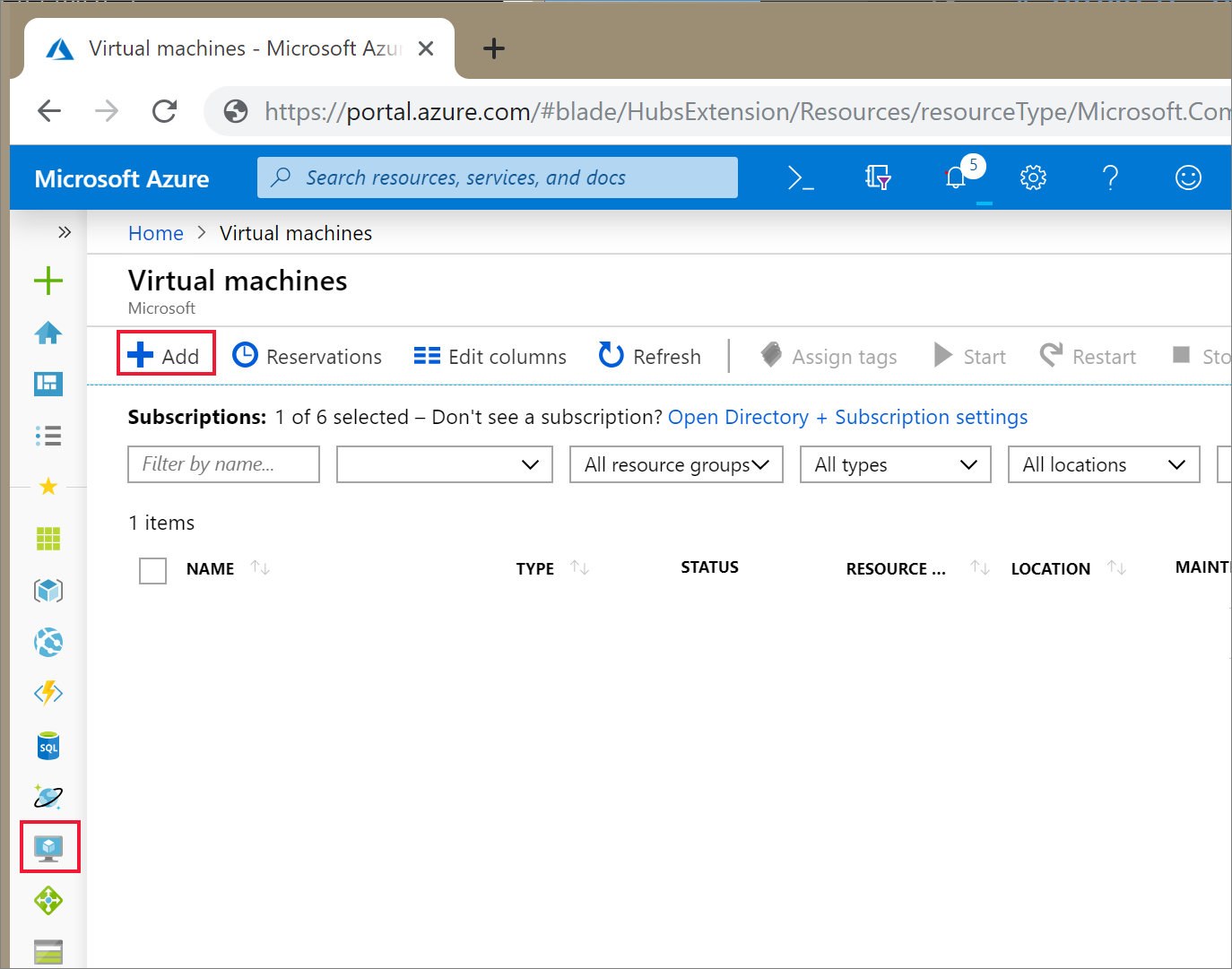
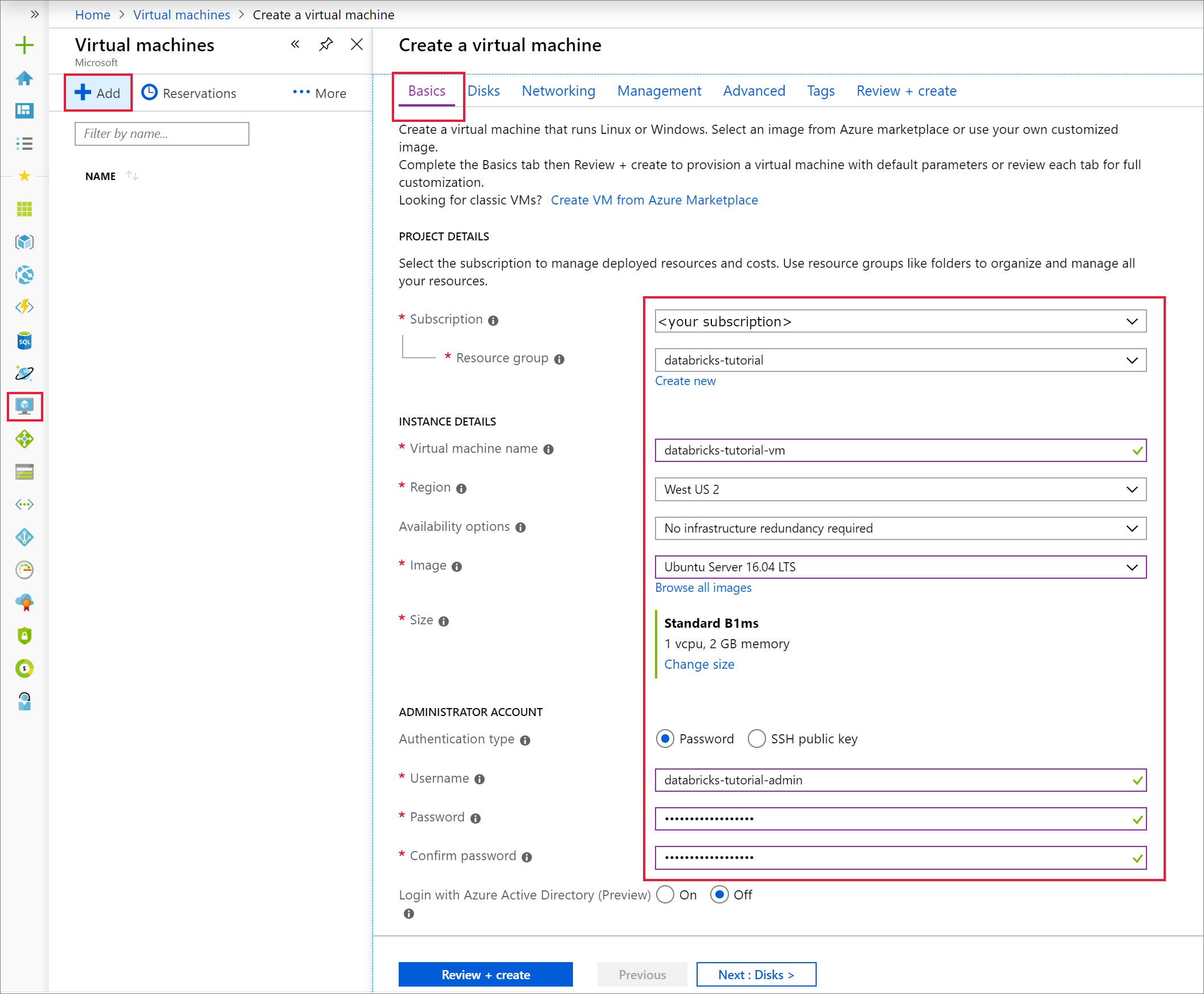
En la pestaña Básico, seleccione Ubuntu Server 18.04 LTS y cambie el tamaño de la máquina virtual a B2s. Elija un nombre de usuario y una contraseña de administrador.
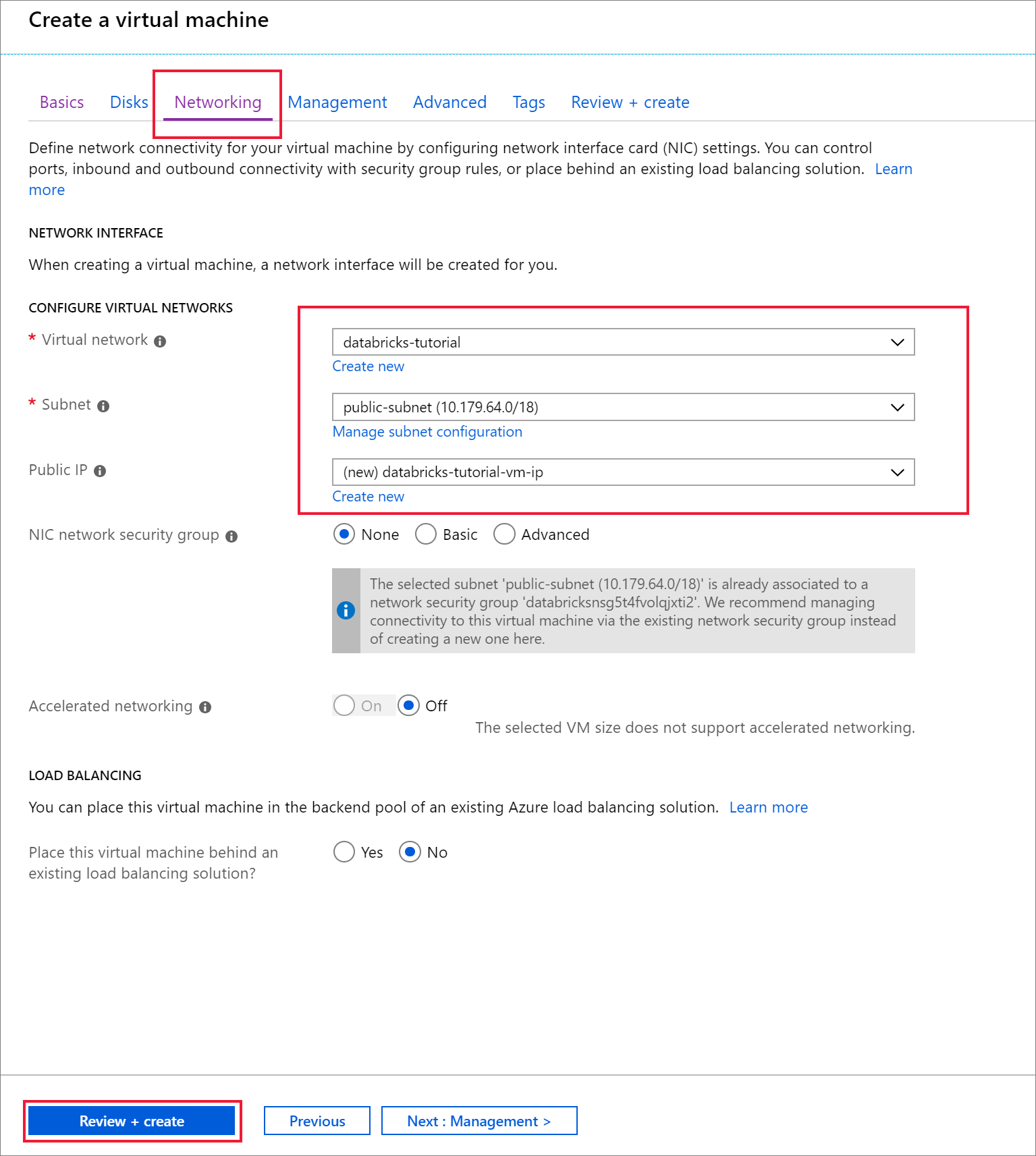
Vaya a la pestaña Redes. Elija la red virtual y la subred pública que incluye el clúster de Azure Databricks. Seleccione Revisar y crear y, a continuación, Crear para implementar la máquina virtual.
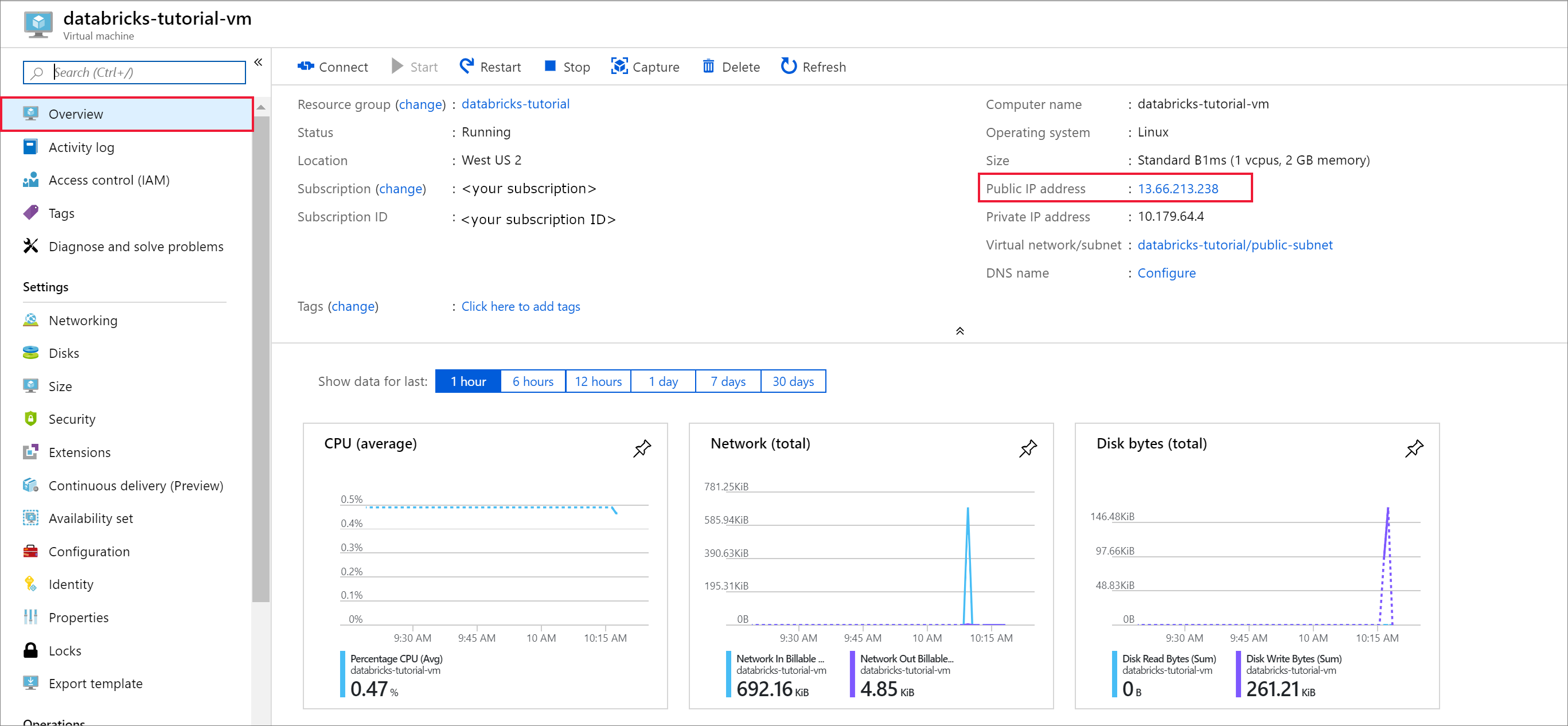
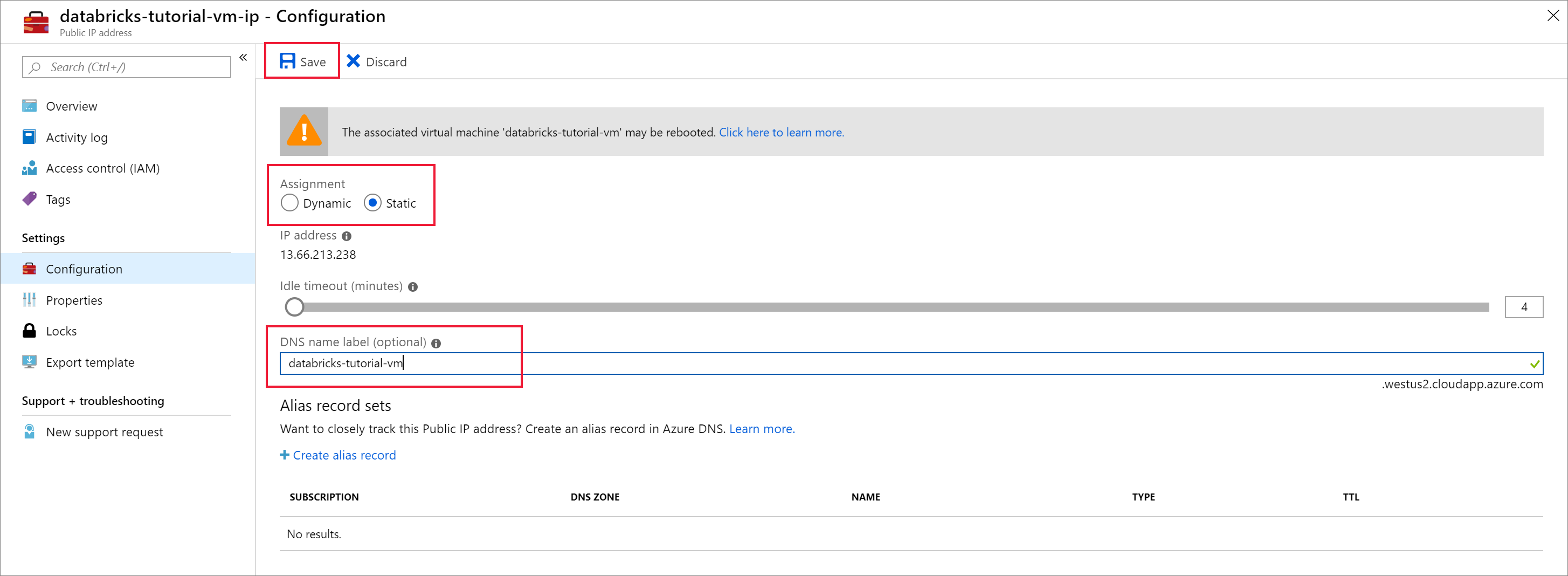
Una vez completada la implementación, vaya a la máquina virtual. Observe la dirección IP pública y la red virtual/subred en la Información general. Seleccione la Dirección IP pública.
Cambie la Asignación a Estática y escriba una Etiqueta de nombre DNS. Seleccione Guardar y reinicie la máquina virtual.
Seleccione la pestaña Redes en Configuración. Tenga en cuenta que el grupo de seguridad de red que se creó durante la implementación de Azure Databricks está asociado con la máquina virtual. Seleccione Agregar regla de puerto de entrada.
Agregue una regla para abrir el puerto 22 para SSH. Use la configuración siguiente:
Configuración Valor sugerido Descripción Origen Direcciones IP Direcciones IP especifica que el tráfico entrante desde una dirección IP de origen específica se permitirá o denegará por esta regla. Direcciones IP de origen <la IP pública> Escriba la dirección IP pública. Para conocer la IP pública, visite bing.com y busque "Mi IP". Source port ranges * Permitir el tráfico de cualquier puerto. Destination Direcciones IP Direcciones IP especifica que el tráfico saliente para una dirección IP de origen específica se permitirá o denegará por esta regla. Direcciones IP de destino <la IP pública de VM> Escriba la dirección IP pública de la máquina virtual. Puede encontrarla en la página Información general de la máquina virtual. Intervalos de puertos de destino 22 Abra el puerto 22 para SSH. Priority 290 Asigne a la regla una prioridad. Nombre ssh-databricks-tutorial-vm Asigne un nombre a la regla. 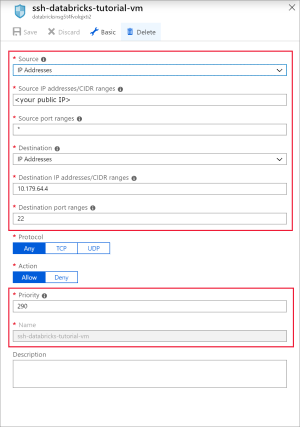
Agregue una regla para abrir el puerto 1433 para SQL con la siguiente configuración:
Configuración Valor sugerido Descripción Origen Any Origen especifica que el tráfico entrante desde una dirección IP de origen específica se permite o deniega según esta regla. Source port ranges * Permitir el tráfico de cualquier puerto. Destination Direcciones IP Direcciones IP especifica que el tráfico saliente para una dirección IP de origen específica se permitirá o denegará por esta regla. Direcciones IP de destino <la IP pública de VM> Escriba la dirección IP pública de la máquina virtual. Puede encontrarla en la página Información general de la máquina virtual. Intervalos de puertos de destino 1433 Abra el puerto 22 para SQL Server. Priority 300 Asigne a la regla una prioridad. Nombre sql-databricks-tutorial-vm Asigne un nombre a la regla. 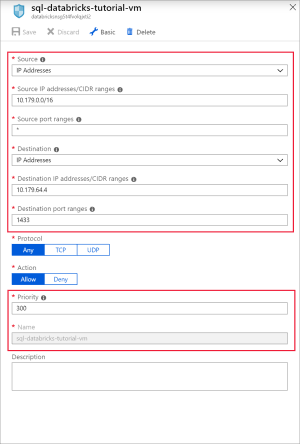
Ejecución de SQL Server en un contenedor de Docker
Abra Ubuntu para Windows o cualquier otra herramienta que le permita conectarse mediante SSH a la máquina virtual. Vaya a la máquina virtual en Azure Portal y seleccione Conectar para obtener el comando SSH que necesita para conectarse.
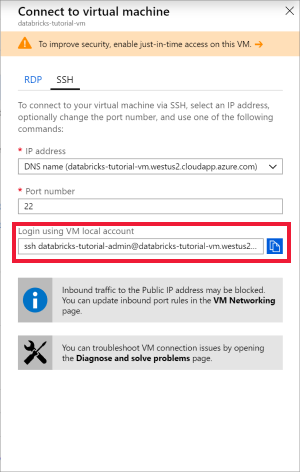
Escriba el comando en el terminal de Ubuntu y escriba la contraseña de administrador que creó al configurar la máquina virtual.
Utilice el siguiente comando para instalar Docker en la máquina virtual.
sudo apt-get install docker.ioVerifique la instalación de Docker con el comando siguiente:
sudo docker --versionInstale la imagen.
sudo docker pull mcr.microsoft.com/mssql/server:2017-latestCompruebe las imágenes.
sudo docker imagesEjecute el contenedor desde la imagen.
sudo docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Password1234' -p 1433:1433 --name sql1 -d mcr.microsoft.com/mssql/server:2017-latestCompruebe que el contenedor se está ejecutando.
sudo docker ps -a
Creación de una base de datos SQL
Abra SQL Server Management Studio y conéctese al servidor mediante el nombre del servidor y la autenticación de SQL. El nombre de usuario de inicio de sesión es SA y la contraseña es la contraseña establecida en el comando de Docker. La contraseña en el comando de ejemplo es
Password1234.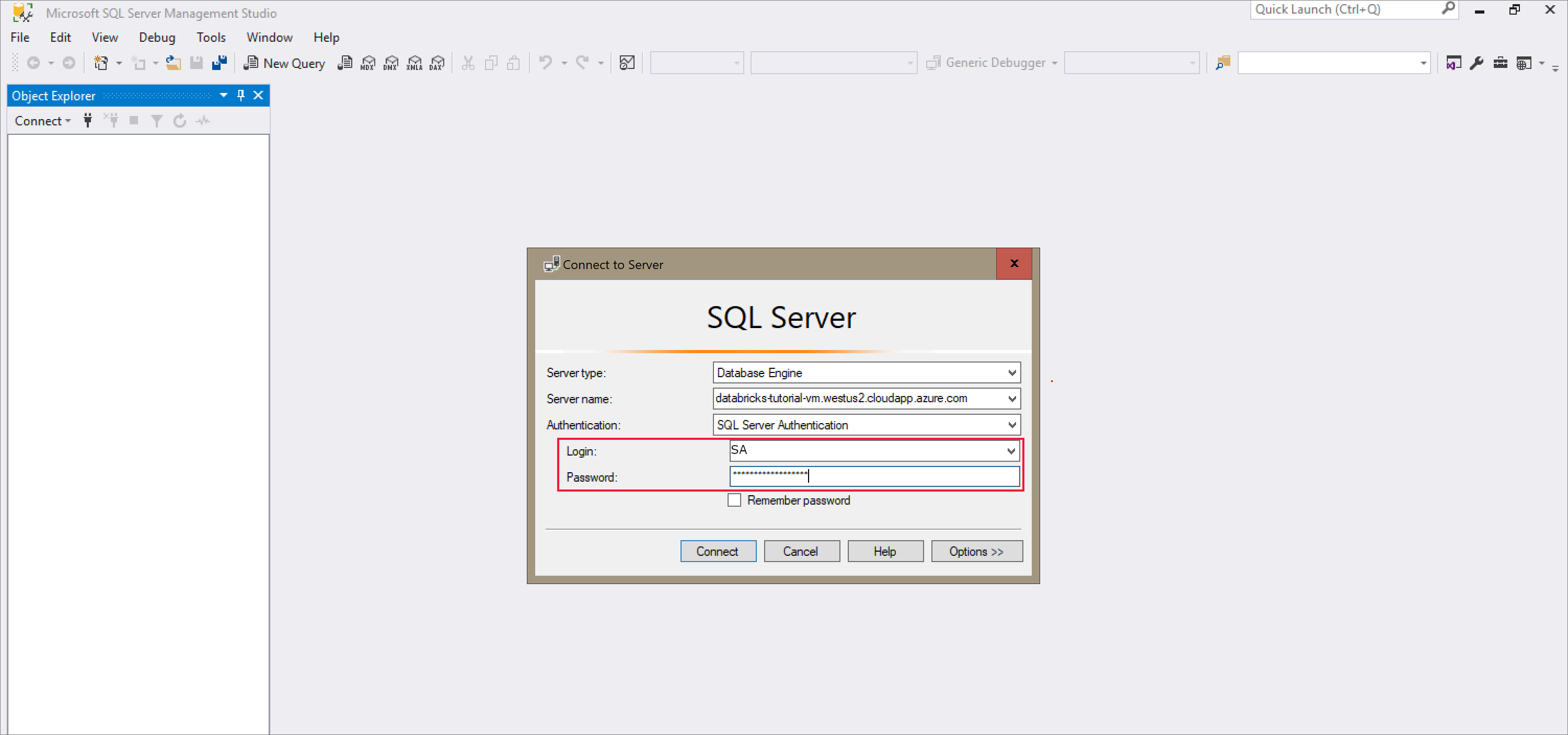
Cuando se haya conectado correctamente, seleccione Nueva consulta y escriba el siguiente fragmento de código para crear una base de datos y una tabla e insertar algunos registros en la tabla.
CREATE DATABASE MYDB; GO USE MYDB; CREATE TABLE states(Name VARCHAR(20), Capitol VARCHAR(20)); INSERT INTO states VALUES ('Delaware','Dover'); INSERT INTO states VALUES ('South Carolina','Columbia'); INSERT INTO states VALUES ('Texas','Austin'); SELECT * FROM states GO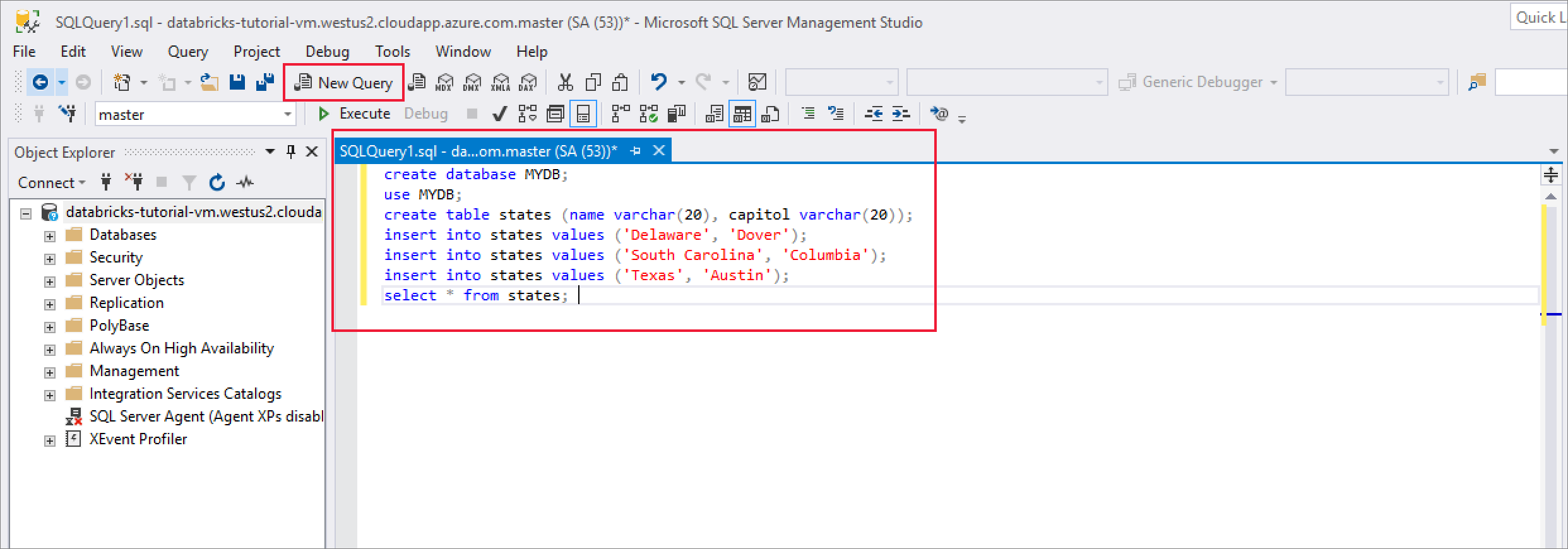
Consulta de SQL Server desde Azure Databricks
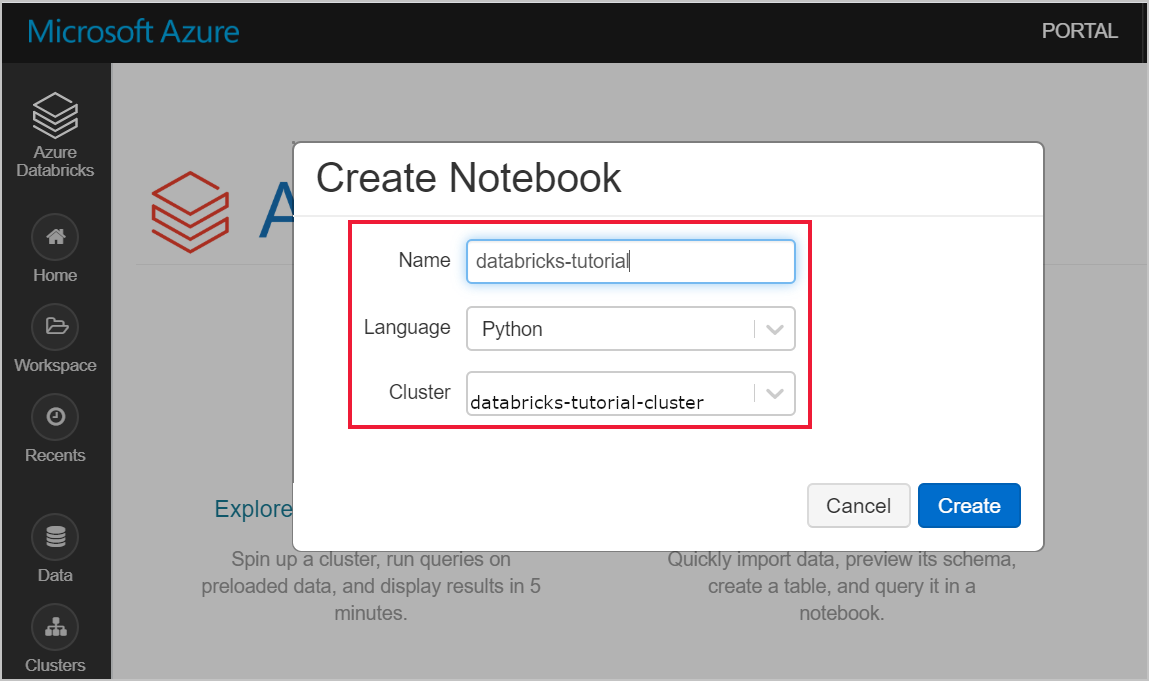
Desplácese hasta el área de trabajo de Azure Databricks y compruebe que ha creado un clúster como parte de los requisitos previos. A continuación, seleccione Create a Notebook (Crear un cuaderno). Asigne un nombre al cuaderno, seleccione Python como lenguaje y seleccione el clúster que ha creado.
Use el siguiente comando para hacer ping a la dirección IP interna de la máquina virtual de SQL Server. Este ping debería completarse correctamente. Si no es así, compruebe que el contenedor se está ejecutando y revise la configuración del grupo de seguridad de red.
%sh ping 10.179.64.4También puede usar el comando nslookup para revisar.
%sh nslookup databricks-tutorial-vm.westus2.cloudapp.azure.comUna vez que haya hecho ping correctamente en el servidor SQL Server, puede consultar la base de datos y las tablas. Ejecute el siguiente código Python:
jdbcHostname = "10.179.64.4" jdbcDatabase = "MYDB" userName = 'SA' password = 'Password1234' jdbcPort = 1433 jdbcUrl = "jdbc:sqlserver://{0}:{1};database={2};user={3};password={4}".format(jdbcHostname, jdbcPort, jdbcDatabase, userName, password) df = spark.read.jdbc(url=jdbcUrl, table='states') display(df)
Limpieza de recursos
Cuando ya no los necesite, elimine el grupo de recursos, el área de trabajo de Azure Databricks y todos los recursos relacionados. Si elimina el trabajo evitará que se generen facturas innecesarias. Si planea usar el área de trabajo de Azure Databricks en el futuro, puede detener el clúster y reiniciarlo más tarde. Si no va a seguir usando esta área de trabajo de Azure Databricks, elimine todos los recursos creados en este tutorial mediante los siguientes pasos:
En el menú de la izquierda de Azure Portal, haga clic en Grupos de recursos y en el nombre del grupo de recursos que creó.
En la página del grupo de recursos, seleccione Eliminar, escriba el nombre del recurso que quiere eliminar en el cuadro de texto y seleccione Eliminar de nuevo.
Pasos siguientes
Vaya al siguiente artículo para aprender cómo extraer, transformar y cargar datos mediante Azure Databricks.