Diseño de servicios disponibles globalmente con Azure SQL Database
Se aplica a:![]() Azure SQL Database
Azure SQL Database
Al crear e implementar servicios en la nube con Azure SQL Database, usa los grupos de conmutación por error y la replicación geográfica activa para proporcionar resistencia frente a interrupciones regionales y errores graves. La misma característica permite crear aplicaciones distribuidas globalmente optimizadas para el acceso local a los datos. En este artículo se describen patrones de aplicación comunes, incluidas las ventajas y desventajas de cada opción.
Nota:
Si usa bases de datos y grupos elásticos de nivel Premium o Crítico para la empresa, puede hacerlos resistentes a las interrupciones regionales mediante su conversión a una configuración de implementación con redundancia de zona. Consulte Bases de datos con redundancia de zona.
Escenario 1: Utilizar dos regiones de Azure para la continuidad empresarial con un tiempo de inactividad mínimo
En este escenario, las aplicaciones tienen las siguientes características:
- La aplicación está activa en una región de Azure.
- Todas las sesiones de base de datos requieren acceso de lectura y escritura (RW) a los datos.
- El nivel web y la capa de datos deben colocarse para reducir la latencia y el costo de tráfico.
- Básicamente, el tiempo de inactividad es un riesgo empresarial más alto para estas aplicaciones que la pérdida de datos.
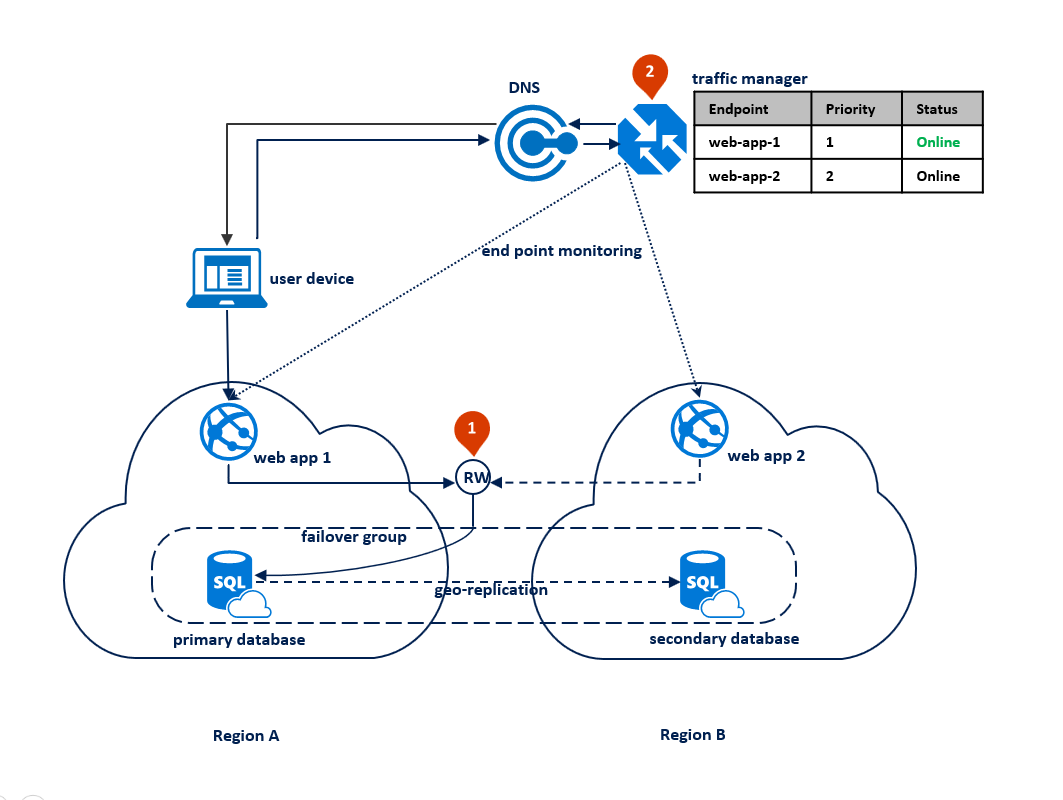
En este caso, la topología de implementación de la aplicación está optimizada para el tratamiento de desastres regionales cuando tiene que realizarse la conmutación por error conjunta de todos los componentes de aplicación. En el diagrama siguiente se muestra esta topología. Para la redundancia geográfica, los recursos de la aplicación se implementan en la región A y B. Sin embargo, no se utilizan los recursos de la región B hasta que se produce un error en la región A. Se configura un grupo de conmutación por error entre las dos regiones para administrar la conmutación por error, la replicación y la conectividad de base de datos. El servicio web de ambas regiones está configurado para tener acceso a la base de datos mediante el agente de escucha de lectura y escritura <nombre del grupo de conmutación por error>. database.windows.net (1). Azure Traffic Manager se configura para usar el método de enrutamiento de prioridad (2).
Nota:
Azure Traffic Manager se usa en este artículo únicamente con fines ilustrativos. Puede usar cualquier solución de equilibrio de carga que admita el método de enrutamiento de prioridad.
El diagrama siguiente muestra esta configuración antes de una interrupción:
Después de una interrupción en la región primaria, SQL Database detectará que no se puede acceder a la base de datos principal y desencadenará una conmutación por error a la región secundaria en función de los parámetros de la directiva de conmutación por error automática (1). Dependiendo de su Acuerdo de Nivel de Servicio de aplicación, puede configurar un período de gracia que controle el tiempo entre la detección de la interrupción y la propia conmutación por error. Es posible que Azure Traffic Manager inicie la conmutación por error del punto de conexión antes de que el grupo de conmutación por error desencadene la conmutación por error de la base de datos. En ese caso, la aplicación web no se puede volver a conectar de inmediato a la base de datos. Sin embargo, las reconexiones se realizarán de forma correcta automáticamente tan pronto como se complete conmutación por error de la base de datos. Cuando se restaure la región errónea y vuelva a estar conectada, se volverá a conectar automáticamente con la primaria anterior como una nueva secundaria. El diagrama siguiente muestra la configuración después de la conmutación por error.
Nota:
Durante la reconexión se pierden todas las transacciones confirmadas después de la conmutación por error. Una vez completada la conmutación por error, la aplicación de la región B puede volver a conectarse y reiniciar el procesamiento que solicita el usuario. La aplicación web y la base de datos principal se encuentran ahora en la región B, donde siguen compartiendo ubicación.
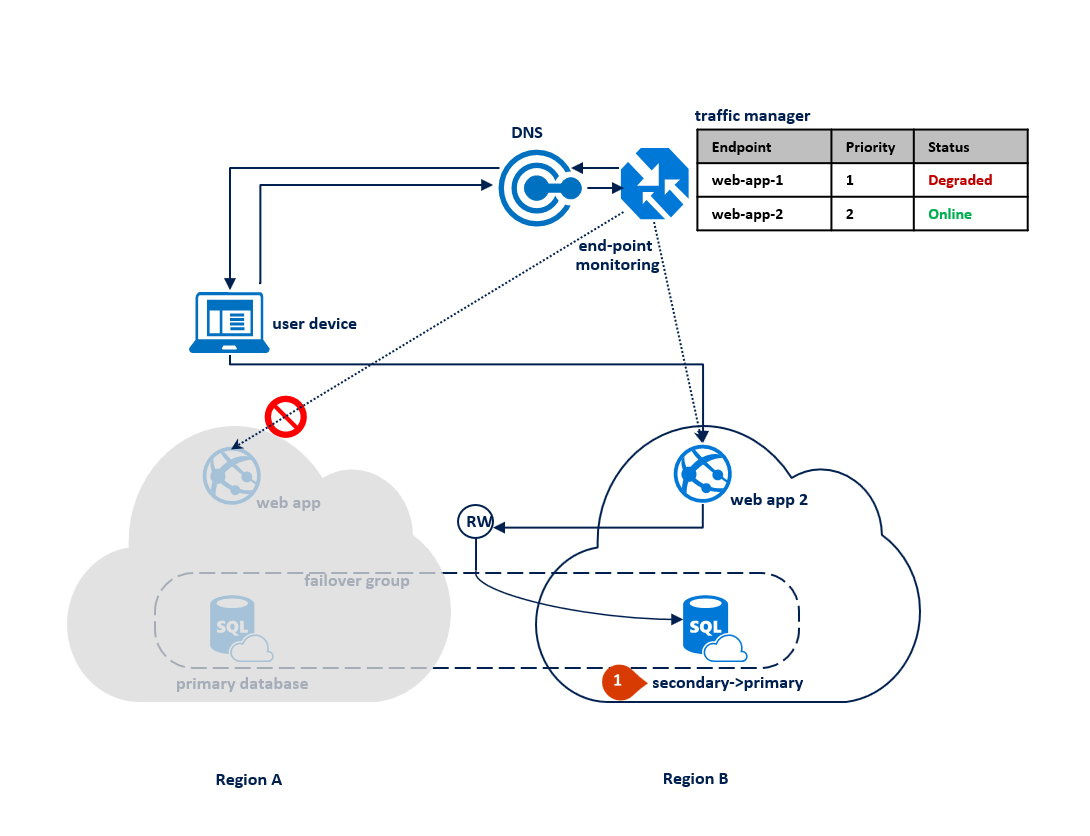
Si se produce una interrupción en la región B, se suspende el proceso de replicación entre la base de datos principal y la secundaria, pero el vínculo entre las dos permanece intacto (1). Traffic Manager detecta que esa conectividad con la región B se ha interrumpido y marca la aplicación web del punto de conexión 2 como Degradada (2). El rendimiento de la aplicación no se ve afectado en este caso, pero la base de datos pasa a estar expuesta y, por tanto, existe un mayor riesgo de pérdida de datos en el caso de que se produzca un error en la región A sucesivamente.
Nota:
Para recuperación ante desastres, se recomienda la configuración con la implementación de aplicaciones limitada a dos regiones. Esto es porque la mayoría de las ubicaciones geográficas de Azure tienen solo dos regiones. Esta configuración no protegerá la aplicación de un error grave simultáneo de ambas regiones. En el caso poco probable de que este error se produjese, podría recuperar sus bases de datos en una tercera región mediante una operación de restauración geográfica. Para obtener más información, consulte Guía de recuperación ante desastres para el servicio Azure SQL Database.
Una vez que se reduce la interrupción, la base de datos secundaria se resincroniza automáticamente con la principal. Durante la sincronización, el rendimiento de la principal puede verse afectado. El impacto específico depende de la cantidad de datos que adquirió la nueva principal desde la conmutación por error.
Nota:
Una vez mitigada la interrupción, Azure Traffic Manager comenzará a enrutar las conexiones a la aplicación de la región A como un punto de conexión con una prioridad más alta. Si pretende mantener la base de datos principal en la región B durante algún tiempo, debería cambiar la tabla de prioridades en el perfil de Azure Traffic Manager como corresponda.
El siguiente diagrama ilustra una interrupción en la región secundaria.

Las ventajas clave de este patrón de diseño son:
- La misma aplicación web se implementa en ambas regiones sin ninguna configuración específica de la región y no requiere una lógica adicional para administrar la conmutación por error.
- El rendimiento de la aplicación no se ve afectado por la conmutación por error, ya que la aplicación web y la base de datos siempre están colocadas.
La contrapartida principal es que los recursos de la aplicación de la región B están infrautilizados la mayoría del tiempo.
Escenario 2: Regiones de Azure para la continuidad empresarial con conservación máxima de datos
Esta opción es mejor para las aplicaciones con las siguientes características:
- Cualquier pérdida de datos supone un alto riesgo para la empresa. La conmutación por error de la base de datos solo puede usarse como último recurso si la interrupción se debe a un error muy grave.
- La aplicación admite los modos de solo lectura y lectura y escritura de operaciones y puede funcionar en "modo de solo lectura" durante un período de tiempo.
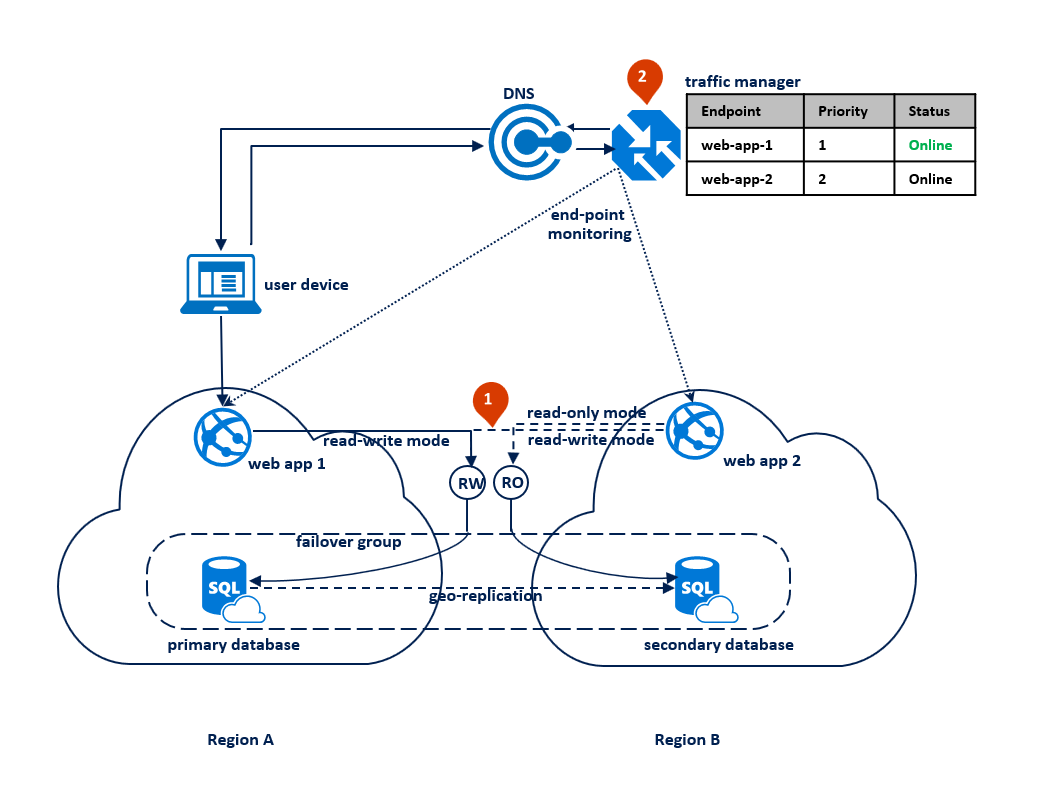
En este modelo, la aplicación cambia al modo de solo lectura cuando las conexiones de lectura y escritura empiezan a tener errores de tiempo de espera agotado. La aplicación web se implementa en ambas regiones e incluyen una conexión con el punto de conexión del agente de escucha de lectura y escritura y otra conexión con el punto de conexión del agente de escucha de solo lectura (1). El perfil de Traffic Manager debe usar el enrutamiento de prioridad. Debe habilitarse la supervisión de punto de conexión para el punto de conexión de la aplicación en cada región (2).
El siguiente diagrama muestra esta configuración antes de una interrupción:
Cuando Traffic Manager detecta un error de conectividad con la región A, cambia automáticamente el tráfico de usuario a la instancia de aplicación de la región B. Con este modelo, es importante establecer el período de gracia con pérdida de datos en un valor suficientemente alto, por ejemplo, 24 horas. Esto asegurará que se evita la pérdida de datos si la interrupción se mitiga durante ese período. Cuando la aplicación web de la región B se active, las operaciones de lectura y escritura comenzarán a generar errores. En ese momento, debe cambiar al modo de solo lectura (1). En este modo, las solicitudes se enrutarán automáticamente a la base de datos secundaria. Si la interrupción se debe a un error muy grave, lo más probable es que no pueda mitigarse dentro del período de gracia. Cuando expira, el grupo de conmutación por error activa la conmutación por error. Después de eso, el agente de escucha de lectura y escritura pasará a estar disponible y las conexiones a él dejarán de dar error (2). El siguiente diagrama muestra las dos fases del proceso de recuperación.
Nota:
Si la interrupción de la región primaria se soluciona dentro del período de gracia, Traffic Manager detecta la restauración de la conectividad en la región principal y cambia el tráfico de usuario de nuevo a la instancia de aplicación de la región A. Esa instancia de aplicación se reanuda y funciona en modo de lectura y escritura usando la base de datos principal de la región A, tal y como se mostró en el diagrama anterior.
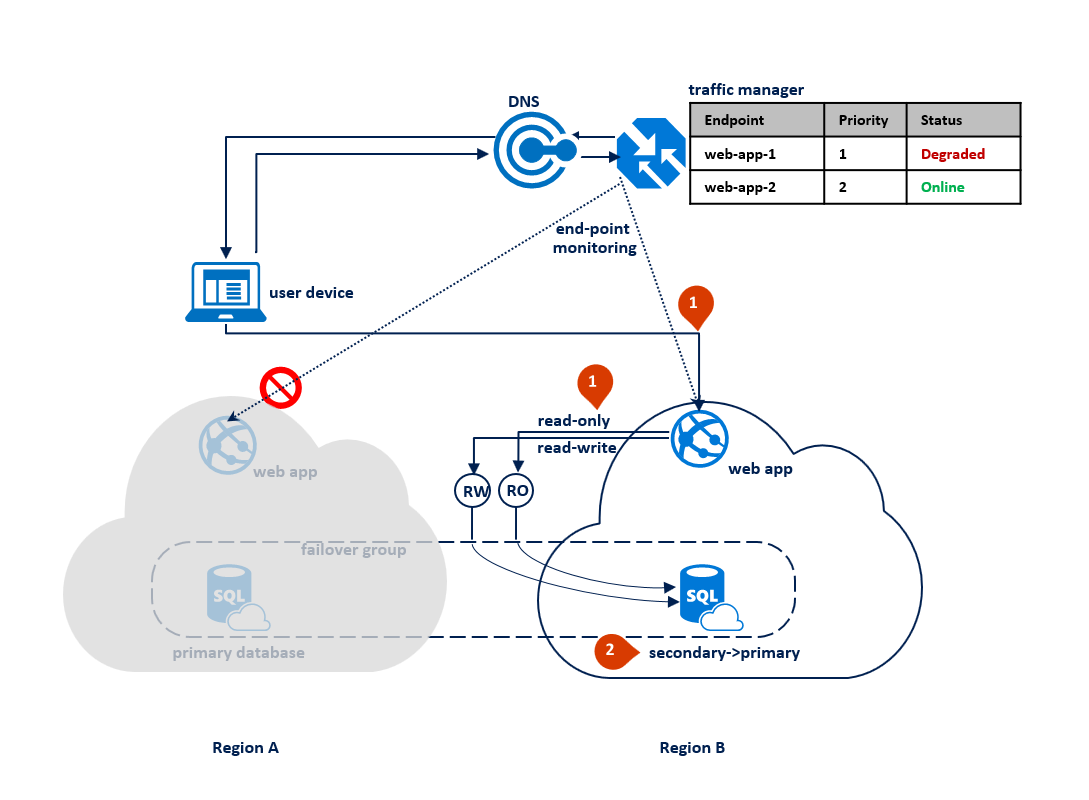
Si se produce una interrupción en la región B, Traffic Manager detecta el error de la aplicación web del punto de conexión 2 en la región B y lo marca como Degradado (1). Mientras tanto, en el grupo de conmutación por error cambia el agente de escucha de solo lectura a la región A (2). Esta interrupción no afecta a la experiencia del usuario final, pero la base de datos principal queda expuesta mientras tanto. El siguiente diagrama muestra un error en la región secundaria:

Una vez mitigada la interrupción, la base de datos secundaria se sincroniza inmediatamente con la principal y el agente de escucha de solo lectura se vuelve a cambiar a la base de datos secundaria de la región B. Durante la sincronización, el rendimiento de la principal podría verse ligeramente afectado dependiendo de la cantidad de datos que se necesite sincronizarse.
Este patrón de diseño tiene varias ventajas:
- Evita la pérdida de datos durante las interrupciones temporales.
- El tiempo de inactividad depende solo de la rapidez de Traffic Manager para detectar el error de conectividad, que se puede configurar.
La contrapartida es que la aplicación debe poder funcionada en modo de solo lectura.
Planificación de la continuidad del negocio: elección del diseño de una aplicación para la recuperación ante desastres en la nube
Su estrategia de recuperación ante desastres en la nube puede combinar o ampliar estos patrones para satisfacer mejor las necesidades de su aplicación. Como se mencionó anteriormente, la estrategia que elija se basa en el acuerdo de nivel de servicio que desee ofrecer a sus clientes y en la topología de implementación de la aplicación. Para guiarle en su decisión, la siguiente tabla compara las opciones en función del objetivo de punto de recuperación (RPO) y el tiempo de recuperación calculado (ERT).
| Patrón | RPO | ERT |
|---|---|---|
| Implementación activa-pasiva para la recuperación ante desastres con acceso a base de datos colocalizada | Acceso de lectura y escritura < 5 s | Tiempo de detección de errores + TTL de DNS |
| Implementación activa-activa para el equilibrio de carga de aplicación | Acceso de lectura y escritura < 5 s | Tiempo de detección de errores + TTL de DNS |
| Implementación activa-pasiva para la conservación de datos | Acceso de solo lectura < 5 s | Acceso de solo lectura = 0 |
| Acceso de lectura y escritura = cero | Acceso de lectura y escritura = Tiempo de detección de errores + Período de gracia con pérdida de datos |
Pasos siguientes
- Para obtener una descripción general y los escenarios de la continuidad empresarial, consulte Continuidad empresarial con Base de datos SQL de Azure
- Para obtener más información sobre la replicación geográfica activa, consulte Replicación geográfica activa.
- Para obtener información acerca de los grupos de conmutación por error, consulte Grupos de conmutación por error.
- Para información acerca de cómo utilizar la replicación geográfica activa con los grupos elásticos, consulte Estrategias de recuperación ante desastres para aplicaciones que usan grupos elásticos de SQL Database.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de