Objetivos de nivel de servicio de la supervisión en la nube
Este artículo forma parte de una serie en la guía de supervisión en la nube.
En las siguientes secciones, aprenderá los principios fundamentales de los objetivos de nivel de servicio y cómo implantarlos y aplicarlos.
Información general
Los objetivos de nivel de servicio (SLO) son metas cuantificables para indicadores clave de nivel de servicio (SLI) centrados en el cliente. Miden la experiencia del cliente con una carga de trabajo empresarial o de infraestructura y determinan si el proveedor de servicios de la empresa cumple las promesas realizadas en un acuerdo de nivel de servicio (SLA) negociado formalmente o en un acuerdo informal entre todas las partes.
Como agente de servicios, cuenta con el compromiso de Microsoft con la confiabilidad de los servicios, tal como se define en los acuerdos de nivel de servicio de Microsoft para los servicios de Azure. Esto le permite centrarse en sus responsabilidades de la cadena de servicios como la supervisión sintética, la conectividad y la seguridad de la red y el cumplimiento.
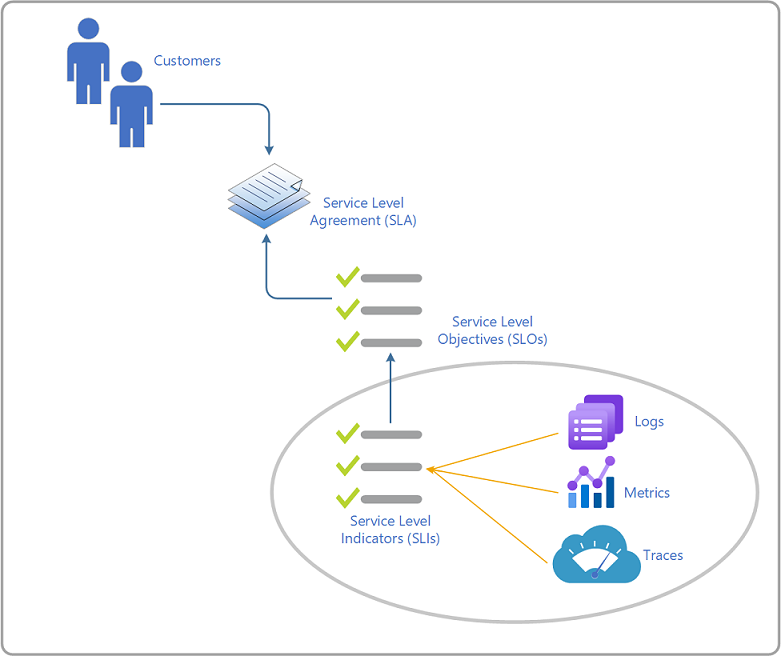
Terminología
A continuación, se muestran las definiciones de cada uno de estos términos y una breve descripción. Estas definiciones se toman del Manual de SRE de Google.
| Término | Descripción |
|---|---|
| Acuerdo de Nivel de Servicio (SLA) | Suele ser un compromiso enlazado entre un proveedor de servicios y un cliente. Un acuerdo suele incluir las consecuencias de no alcanzar los objetivos de las SLO. Los aspectos concretos del servicio son la calidad, la disponibilidad y las responsabilidades acordadas entre el proveedor de servicios y el consumidor del servicio. |
| Supervisión | La práctica de recopilar datos cuantitativos en tiempo real sobre servicios y sistemas. |
| Métricas | Miden el comportamiento del servicio pertinente y se pueden agregar a los indicadores de nivel de servicio (SLI), que se procesan y agregan para medir el estado operativo actual de un servicio y cuantificar su comportamiento. Los SLI son los indicadores principales y en tiempo real del mantenimiento actual de un servicio. |
| Registros | Comienzan por la información del código y los informes sobre una ejecución individual de una ruta de acceso de código o un evento discreto. Use esta información para ayudar a solucionar problemas y trabajar en la identificación de la causa raíz de los problemas que afectan a la experiencia del cliente y a la confiabilidad del servicio medida por SLIs/SLOs. |
| Objetivo de nivel de servicio (SLO) | Es un valor de destino para el nivel de servicio, medido por indicadores de nivel de servicio (SLI), que establece las expectativas sobre el rendimiento de un servicio. Los SLO realizan un seguimiento específico de la experiencia del cliente de principio a fin. Para establecer unos buenos SLO, lo normal es empezar por definir la experiencia deseada y luego instrumentar el código de servicio para medir esa experiencia (recopilar los SLI pertinentes) y fijar el objetivo de cómo se cumplen o no las expectativas del cliente. |
| Indicadores de nivel de servicio (SLI) | Una métrica que cuantifica la calidad o confiabilidad del servicio. Como mínimo, hay cuatro SLI comunes para evaluar: disponibilidad, latencia, rendimiento y tasa de errores. |
| Disponibilidad | Generalmente hace referencia al porcentaje de tiempo medible u observable que un sistema está operativo y funcional. La disponibilidad se mide como objetivo orientado al cliente para la continuidad de la experiencia, que a su vez se ve afectada por uno o varios problemas de confiabilidad (y otros modos de error relacionados con los cambios de configuración, las actualizaciones aplicadas, etc.). |
| Presupuesto de errores | Porcentaje del búfer restante con respecto al SLO. Los presupuestos de errores son la herramienta que DevOps y TI usan para equilibrar la confiabilidad del servicio con el ritmo de innovación. |
El propósito de los SLO
Los SLO sirven para muchos propósitos esenciales en el desarrollo y las operaciones de las cargas de trabajo en la nube, entre ellos:
- Casi en tiempo real (NRT): Ofrece una vista NRT del mantenimiento de un servicio tal como lo experimenta un cliente.
- Reducir el tiempo de notificación (TTN): Impulsa la notificación automatizada de los problemas del servicio a los clientes, lo que reduce significativamente el tiempo de notificación (TTN).
- Señal principal para los clientes: Actúa como señal principal para las operaciones de implementación, impulsando la reversión automatizada si se producen problemas, por lo que exponen menos clientes a posibles problemas.
- Cambiar verificación: Proporciona la validación de que los cambios lograron la mejora esperada de la experiencia del cliente.
- Determinar prioridades: Ayuda a los equipos a comprender si crear características o trabajar en la confiabilidad.
- Información sobre el mantenimiento de los servicios: Habilita discusiones objetivas, centradas en el cliente, sobre el mantenimiento del servicio.
- Reducir el tiempo de análisis: Acelera la mitigación y el análisis de la causa principal (RCA) de los problemas de los clientes dirigiendo la atención al servicio responsable.
- Dependencias de arquitectura: Actúa como una aportación esencial a las decisiones de arquitectura cuando los servicios adoptan dependencias.
- Generar confianza: Proporciona una comprensión compartida de las medidas de mantenimiento, lo que genera confianza entre los equipos.
- Aportar transparencia: Exponer los mismos SLI que usamos para ejecutar nuestro negocio a nuestros clientes para que puedan ejecutar los suyos.
- Un solo panel: habilita un único panel horizontal para los servicios y sus dependencias, y desglosar los silos.
Mediante el uso de los SLO para impulsar el proceso de ingeniería, DevOps y TI pueden comprender pronto el mantenimiento de la aplicación o el servicio de infraestructura que crean o migran en Azure. Luego se pueden usar para impulsar las decisiones humanas y automatizadas que se deben tomar sobre la confiabilidad de estos servicios. Esta transformación de la práctica de la ingeniería repercutirá significativamente en la confiabilidad de esos servicios a corto plazo.
¿Cómo definir SLO?
El objetivo de un SLO es obtener señales claras que midan con precisión la calidad desde la perspectiva del cliente. Cada equipo de servicio crea un pequeño conjunto de objetivos de nivel de servicio (SLO) que definen el intervalo permitido para las métricas medibles más importantes del servicio, según la experiencia del consumidor del servicio. Un SLO es un objetivo numérico definido para una métrica emitida por un servicio. Las métricas asociadas a este objetivo se pueden supervisar para determinar si el servicio es correcto.
Por ejemplo, este es un ejemplo simplificado de un SLO para una aplicación basada en web de seguimiento de tiempo interno: las solicitudes de los últimos 5 minutos se sirven en menos de 1000 milisegundos en el percentil 99.
Las métricas son agregaciones de datos de serie temporal denominados Indicadores de nivel de servicio (SLI). Es muy importante dónde se recopilan los SLI. En el ejemplo anterior, si el cliente interactúa con el servicio mediante una API, la medición de la latencia del sistema y el tiempo para procesar las solicitudes son SLI precisos. Sin embargo, si el cliente interactúa con el servicio mediante un portal web, el tiempo total para atender la solicitud también debe incluir el rendimiento de JavaScript de la página web.
El objetivo de los propietarios de servicios es determinar lo siguiente:
- Qué escenarios son indicadores críticos del mantenimiento del servicio desde la perspectiva del cliente.
- Dónde recopilar los SLI para que estén lo más cerca posible de la experiencia del cliente.
- ¿Cuáles deben ser los SLO para estos SLI?
Los SLO se pueden definir con un enfoque gradual para impulsar el logro o se prescribe directamente por la empresa. Use los SLO definidos por un servicio para tomar decisiones arquitectónicas sobre cómo se crean. Por lo tanto, es esencial elegir cuidadosamente qué escenarios medir y durante qué período de tiempo se deben medir. En resumen, un SLO se compone de los valores siguientes:
- Un SLI. Por ejemplo, la proporción de solicitudes suficientemente rápidas, medidas desde el equilibrador de carga, es inferior a 400 ms.
- Una duración. Período de tiempo en el que se mide una métrica.
- Un objetivo. Por ejemplo, un porcentaje objetivo de solicitudes rápidas del total de solicitudes (como el 90 %) que espera cumplir durante un período determinado.
Tipos de SLO
Si observa en todo el sector, hay dos tipos de SLO:
SLO centrados en el servicio: estos SLO son objetivos tácticos que los equipos definen para mejorar la calidad de su servicio a lo largo del tiempo gradualmente. Están diseñados para ser objetivos pragmáticos alcanzables en un hito de ingeniería. Por ejemplo, si un servicio está alcanzando actualmente una disponibilidad del 99,7 %, el equipo podría establecer un objetivo para alcanzar el 99,9 % de disponibilidad en el próximo trimestre.
SLO centrados en el cliente: estos SLO definen el estado o objetivo ideales futuros. En este momento, se considerarían innecesarias las inversiones adicionales en calidad, ya que está cumpliendo plenamente las expectativas de los clientes.
Por ejemplo, si el cliente espera que un servicio empresarial o de infraestructura que opera proporciona una disponibilidad del 99,99 % y el servicio actualmente solo logra una disponibilidad del 99,8 %, el SLO centrado en el cliente sigue siendo del 99,99 %.
La definición de los SLO adecuados tarda tiempo. El primer paso es hablar con los clientes y comprender lo que los usuarios quieren del servicio para derivar una pequeña selección de indicadores y documentarlos. Conozca los escenarios y las tolerancias de cómo utilizan su servicio y lo que su servicio debe ofrecer para que su negocio funcione con éxito. Suele ser una experiencia iterativa, y sus expectativas van de Quiero una disponibilidad del 100 % en todas las condiciones, sin impacto en nuestro flujo de ingresos, a expectativas de administración muy variables entre segmentos de clientes.
Los enfoques de supervisión que solo examinan el mantenimiento del servicio (o instancia de servicio) son vulnerables a problemas de experiencia del cliente que faltan en ambos extremos del espectro; el mantenimiento del servicio no siempre se correlaciona con la calidad de la experiencia del cliente. Esto se debe a que hay diferentes características de comportamiento entre los servicios PaaS y SaaS de Azure, la configuración de esos servicios de Azure, cómo y dónde (es decir, qué región) se implementan sus recursos y la adición de código o lógica personalizados, que agrega más complejidad.
Al definir un SLO, es importante recordar que su proveedor o proveedores de nube dependen de su SLA. Tenga en cuenta los contratos de nivel de servicio especificados para cada uno de sus servicios. Para Azure, consulte Acuerdos de nivel de servicio (SLA) para servicios en línea
¿Cómo se define los SLI?
Una especificación de SLI es una declaración formal de las expectativas de sus usuarios sobre una dimensión concreta de confiabilidad de su servicio, como la latencia o la disponibilidad.
Empiece de forma sencilla mediante la selección de las métricas adecuadas para medir y recopilar, y no se complique mucho recopilando demasiadas métricas que no sean significativas. Asegúrese de que los SLI que defina tienen una relación directa con la experiencia del cliente. Por eso es esencial comprender la perspectiva de los usuarios para empezar con solo unos pocos indicadores.
Si su servicio tiene algún tipo de limitación de recursos, como la memoria o la CPU, su saturación también puede ser un excelente SLI. Sin embargo, la saturación no debe usarse como un SLO, ya que no se corresponde directamente con una experiencia de usuario deficiente (un servicio puede tener un uso elevado de memoria, pero los usuarios no verse afectados).
Le recomendamos que cree hasta tres indicadores. Más de tres indicadores rara vez agregan valor significativo. A menudo, un número excesivo de indicadores podría significar que se incluyen síntomas de los indicadores primarios. El tráfico y la saturación deben ser adicionales a esos tres indicadores principales, ya que describen la carga del servicio y la compatibilidad con la interpretación de otros indicadores de servicio.
¿Cómo se implementan los SLO?
Los SLI más importantes son los que más claramente representan un impacto en su servicio desde la perspectiva de su cliente. Para muchos servicios, esto incluye la latencia, el rendimiento, la tasa de errores y la disponibilidad. Si su servicio tiene alguna consideración especial que afecte a la experiencia del cliente, también deben medirse los SLI de esas áreas. Por ejemplo, la latencia del proceso de un extremo a otro para un servicio de mensajería es un indicador directo de la experiencia del cliente y debe estar cubierta por un SLI.
Ejemplos de SLO
Recursos humanos está interesado en modernizar su aplicación interna basada en web de seguimiento del tiempo y hospedarla en la nube Azure con la ayuda de TI empresarial. Quieren que el servicio siga llegando a todos los usuarios de la organización, por lo que están interesados en lo siguiente:
- Informes de uso y cuántos usuarios usan el servicio a lo largo del tiempo.
- Supervisión periódica del mantenimiento, como la disponibilidad, el rendimiento, la seguridad y el cumplimiento (garantía del servicio).
- Costo, como el costo mensual de un servicio.
- Ciberseguridad, en términos de controlar el acceso a los recursos y los datos siguiendo una estrategia de seguridad de Confianza cero.
Como vemos en estos ejemplos anteriores, es necesario definir las categorías y los ejemplos de SLO/SLI al principio del diseño del servicio. No es diferente en absoluto de los servicios locales que ha creado.
Tablas de SLO o categorías de SLI
Los ejemplos siguientes no son una lista exhaustiva. Aunque los SLO de confiabilidad y mantenimiento son distintivos de los sistemas durante décadas, puede definir SLO que incluyan medidas para la ciberseguridad, la calidad y la experiencia del usuario, y el costo.
Servicios
Las medidas de alto nivel típicas de un servicio o sistema normalmente se codifican en contratos de servicio. La mayoría de los contratos modernos miden la disponibilidad como SLO clave y usan medidas de tiempo de inactividad sencillas basadas en elementos clave de carga de trabajo o unidades de producción, como los tokens de autenticación, el buzón o la cuenta de almacenamiento.
| Category | Descripción | Ejemplo |
|---|---|---|
| Disponibilidad | Tiempo de inactividad simple o tiempo medio entre mantenimiento o disponibilidad operativa (MTBM/[MTBM+MDT]) | 99,99 % durante un período mensual |
| Capacity | Garantizar el rendimiento adecuado, máximo u óptimo del negocio y el servicio, la capacidad de proceso, el almacenamiento, las personas, el ancho de banda, la demanda, los recursos y las funciones de servicio. Incluye límites de trabajo y tiempo para actuar como desencadenadores. | Porcentaje de uso (CPU, almacenamiento, memoria, latencia, rendimiento, escalado) |
| Seguridad | Amenazas activas y vulnerabilidades (internas y externas) que podrían o que están causando daños a la empresa, los recursos y los datos. | Detección de amenazas de HAFNIUM |
| Cumplimiento normativo | Actualizaciones, niveles de mantenimiento, protección del cumplimiento, desfase de la configuración deseada | 99,5 % de actualizaciones servidas en todos los recursos |
| Continuidad | Capacidad de sobrevivir y recuperarse de grandes desastres y eventos externos. | Tiempo (reconstitución) |
| Calidad de servicio (QoS) | Características de la experiencia real de los usuarios a lo largo del tiempo. | Calidad de llamada de equipos: pérdida de paquetes recibidos < 2 % |
Confiabilidad
La confiabilidad, el SLO clásico, implica el grado de dependencia, durabilidad, calidad a lo largo del tiempo, de los sistemas, los servicios, los recursos o los componentes en relación a errores y conmutaciones por error, con el trabajo de administración aplicado para solucionar errores (por ejemplo, crear más redundancia o agregar una red de entrega de contenido) para aumentar el tiempo de funcionamiento o la disponibilidad. También podría significar la precisión, fidelidad, integridad y confiabilidad de los datos usados para medir los SLO. Puede significar la probabilidad clásica de que un sistema realice su función prevista en condiciones especificadas, como bajo tensión de temperatura. La resistencia también incluye factores de diseño integrados o características que proporcionan capacidad de adaptación, como el escalado, el enfriamiento, el equilibrio de carga, la recuperación, la demanda imprevisible, el rendimiento degradado bajo estrés grave y diseño para la continuidad en desastres más grandes (normalmente un SLO independiente).
| Category | Descripción | Ejemplo |
|---|---|---|
| Frecuencia de errores | Número de errores durante el total de horas de funcionamiento | 5 errores en 973,00514 horas |
| Tiempo medio entre errores (MTBF) | MTBF es el inverso de la frecuencia de errores | 194,6 horas |
Capacidad de mantenimiento
Combine los SLO de soporte técnico para los procesos de administración de servicios de TI, como la administración de incidentes y problemas, junto con los SLO de confiabilidad, para que se pueda lograr la medición de la disponibilidad.
| Category | Descripción | Ejemplo |
|---|---|---|
| Rendimiento de incidentes de servicio | Por categoría, producto o prioridad. | Medidas de tiempo y costo para cada fase del ciclo de vida del incidente. |
| Rendimiento de incidentes de seguridad | Por categoría, producto o prioridad. | Medidas de tiempo y costo para cada fase del ciclo de vida del incidente. |
| Tiempo medio para reparación de componente (MTTR) | Desde la detección de eventos a través de la restauración o corrección. | |
| Tiempo medio entre mantenimientos (MTBM) | Tiempo medio o promedio entre todas las acciones de mantenimiento, incluidas las acciones preventivas en las que se produce el trabajo de producción normal. | Consulte Tiempo de retraso de mantenimiento. |
| Tiempo de retraso de mantenimiento (MDT) | Tiempo total desde la detección hasta la recuperación, incluida la logística y el retraso administrativo. | Tiempo para reemplazar el hardware para incluir pedidos, envíos e instalación. |
Experiencia del cliente
| Category | Descripción | Ejemplo |
|---|---|---|
| Throughput | Cantidad, tasa o velocidad de carga de trabajo o carga productiva colocada en un sistema a lo largo del tiempo. | Transacciones por unidad de tiempo. |
| Frecuencia de errores | El número de errores totales en porcentaje. | Porcentaje de eventos de seguridad |
| Latencia | Medida de tiempo o retraso de la entrada a la salida, el movimiento del trabajo a través de un proceso o de la aplicación al usuario. | Segundos promedio. |
Otros
| Category | Descripción | Ejemplo |
|---|---|---|
| Coste | Mida los gastos, la facturación y las facturas por servicio, componente o tiempo. | Gastos de capital o gastos operativos |
| Cobertura | Porcentaje de componentes, sistemas y servicios bajo administración (cumplimiento) | Cumplimiento normativo |
| Confiabilidad de fuentes | Errores de latido, conectores, cambios, etc. | Seguimiento de los cambios en los datos críticos de la empresa. |
| Productividad | Eficacia para realizar tareas de forma productiva | Trabajo, tiempo por empleado, productividad de analistas. |
Consideraciones
Garantiza el acceso. Asegúrese de que a los administradores y a otros roles de la organización se les concede acceso a las visualizaciones disponibles en Azure Monitor o desde otros servicios de Azure, especialmente Azure SaaS y PaaS, para evitar duplicarlas.
Asegúrese de supervisar la cobertura o la visibilidad total de los recursos. Proteja los agentes, los registros emitidos, además de las tablas y las consultas de todos los recursos que deben administrarse y protegerse, e identifique "puntos ciegos" o brechas en la cobertura para garantizar el realismo en los SLO.
Coloque los datos correctos frente a los consumidores adecuados. Asegúrese de que los consumidores de SLO y SLI puedan interpretar los datos subyacentes para generar confianza y orientar las decisiones utilizando la información obtenida de los datos.
Haz promesas razonables. Al establecer los SLO como objetivos, especialmente cuando la administración de costos es esencial, asegúrese de que el rendimiento real del sistema no realiza una entrega insuficiente o en exceso, ni ajusta el objetivo para administrar las expectativas del cliente.
Tenga en cuenta los eventos externos imprevistos. Desarrolle planes de continuidad y evaluaciones de riesgos para tener en cuenta los eventos que no están bajo su control, como el tiempo, las interrupciones de energía o los desastres.
Tenga en cuenta los cambios. Asegúrese de que los SLO tienen en cuenta las modificaciones en el servicio o los cambios en la confiabilidad técnica, el rendimiento, la calidad y la capacidad de mantenimiento, como las reducciones de personal de soporte técnico.
Proporcione un conjunto equilibrado de SLO. Asegúrese de contar con una serie de SLO que ofrezcan una perspectiva equilibrada o de 360 grados sobre el servicio o sistema y se centren en la confiabilidad.
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de