Sugerencias de rendimiento para la versión 2 del SDK de Java sincrónico de Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL
Importante
No se trata de la versión de SDK de Java de Azure Cosmos DB más reciente. Debe actualizar el proyecto al SDK de Azure Cosmos DB para Java v4 y luego leer la guía de sugerencias de rendimiento del SDK de Azure Cosmos DB para Java v4. Siga las instrucciones que se indican en la guía de migración a la versión 4 del SDK de Java Azure Cosmos DB y la guía Reactor frente a RxJava para realizar la actualización.
Estas sugerencias de rendimiento solo se dirigen a la versión 2 del SDK de Java sincrónico de Azure Cosmos DB. Consulte el repositorio de Maven para obtener más información.
Importante
El 29 de febrero de 2024 se retirará el SDK de Java v2.x de Azure Cosmos DB Sync; el SDK y todas las aplicaciones que lo usan seguirán funcionando; Azure Cosmos DB simplemente dejará de proporcionar mantenimiento y soporte técnico para este SDK. Se recomienda seguir las instrucciones anteriores para migrar al SDK de Java v4 de Azure Cosmos DB.
Azure Cosmos DB es una base de datos distribuida rápida y flexible que se escala sin problemas con una latencia y un rendimiento garantizados. No es necesario realizar cambios de arquitectura importantes ni escribir código complejo para escalar la base de datos con Azure Cosmos DB. Escalar o reducir verticalmente es tan sencillo como realizar una única llamada API. Para más información, consulte cómo aprovisionar el rendimiento del contenedor o cómo aprovisionar el rendimiento de la base de datos. Sin embargo, como el acceso a Azure Cosmos DB se realiza mediante llamadas de red, puede realizar optimizaciones en el lado cliente para conseguir un rendimiento máximo al usar la versión 2 del SDK de Java sincrónico de Azure Cosmos DB.
Por lo tanto, si se pregunta "¿Cómo puedo mejorar el rendimiento de mi base de datos?", considere las siguientes opciones:
Redes
Modo de conexión: uso de DirectHttps
El modo en que un cliente se conecta a Azure Cosmos DB tiene implicaciones importantes sobre el rendimiento, especialmente en los términos de la latencia observada en el lado cliente. Hay un valor de configuración clave disponible para configurar el cliente ConnectionPolicy – ConnectionMode. Las dos opciones de ConnectionModes disponibles son:
-
El modo de puerta de enlace se admite en todas las plataformas de SDK y es el valor predeterminado configurado. Si la aplicación se ejecuta dentro de una red corporativa con restricciones de firewall estrictas, el modo de puerta de enlace es la mejor opción, ya que utiliza el puerto HTTPS estándar y un único punto de conexión. La desventaja para el rendimiento, sin embargo, es que el modo de puerta de enlace implica un salto de red adicional cada vez que se leen o escriben datos en Azure Cosmos DB. Por este motivo, el modo DirectHttps ofrece mejor rendimiento debido al número menor de saltos de red.
La versión 2 del SDK de Java sincrónico de Azure Cosmos DB usa HTTPS como protocolo de transporte. HTTPS usa TLS para la autenticación inicial y para cifrar el tráfico. Si se usa la versión 2 del SDK de Java sincrónico de Azure Cosmos DB, solo hay que abrir el puerto HTTPS 443.
ConnectionMode se configura durante la construcción de la instancia de DocumentClient con el parámetro ConnectionPolicy.
Versión 2 del SDK de Java sincrónico (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);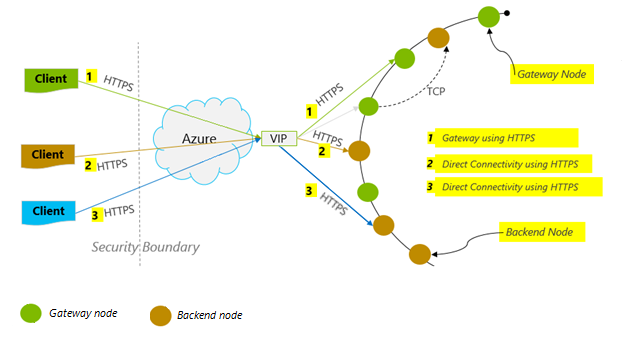
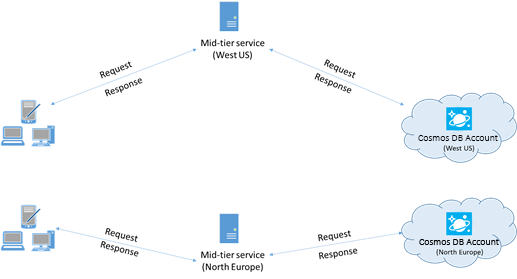
Colocación de los clientes en la misma región de Azure para aumentar el rendimiento
Cuando sea posible, coloque las aplicaciones que llaman a Azure Cosmos DB en la misma región que la base de datos de Azure Cosmos DB. Para obtener una comparación aproximada, las llamadas a Azure Cosmos DB en la misma región se realizan en menos de 1 o 2 ms, pero la latencia entre las costas este y oeste de Estados Unidos es >50 ms. Esta latencia podría variar de una solicitud a otra, según la ruta tomada por la solicitud cuando pasa del cliente al límite del centro de datos de Azure. Para conseguir la menor latencia posible, asegúrese de que la aplicación que llama se encuentra en la misma región de Azure que el punto de conexión de Azure Cosmos DB aprovisionado. Para obtener una lista de regiones disponibles, consulte Regiones de Azure.
Uso del SDK
Instalación del SDK más reciente
Los SDK de Azure Cosmos DB se mejoran constantemente para proporcionar el mejor rendimiento. Para determinar las mejoras más recientes del SDK, visite el SDK de Azure Cosmos DB.
Uso de un cliente de Azure Cosmos DB singleton para aumentar la duración de la aplicación
Cada instancia de DocumentClient está protegida frente a amenazas y realiza una administración de conexiones y un almacenamiento en caché de las direcciones de manera eficiente cuando funciona en modo directo. Para permitir la administración eficiente de las conexiones y un rendimiento mejor mediante DocumentClient, se recomienda usar una sola instancia de DocumentClient por AppDomain durante la vigencia de la aplicación.
Aumento de MaxPoolSize por host al utilizar el modo de puerta de enlace
Las solicitudes de Azure Cosmos DB se realizan a través de HTTPS o REST cuando se usa el modo de puerta de enlace, y están condicionadas por los límites de conexión predeterminados por nombre de host o dirección IP. Puede que deba establecer MaxPoolSize en un valor mayor (200-1000) para que la biblioteca cliente pueda utilizar varias conexiones simultáneas a Azure Cosmos DB. En la versión 2 del SDK de Java sincrónico de Azure Cosmos DB, el valor predeterminado de ConnectionPolicy.getMaxPoolSize es 100. Use setMaxPoolSize para cambiar el valor.
Ajuste de consultas paralelas en colecciones particionadas
A partir de la versión 1.9.0 y posteriores del SDK de Java sincrónico de Azure Cosmos DB se admiten consultas paralelas que permiten consultar una colección con particiones en paralelo. Para obtener más información, consulte ejemplos de código relacionados para trabajar con los SDK. Las consultas paralelas están diseñadas para mejorar la latencia y el rendimiento de la consulta en todos sus homólogos seriales.
(a) Las consultas paralelas Tuning setMaxDegreeOfParallelism: realizan consultas en varias particiones en paralelo. Sin embargo, los datos de una recopilación con particiones individual se capturan en serie con respecto a la consulta. Por lo tanto, use el parámetro setMaxDegreeOfParallelism para establecer el número de particiones que tiene la máxima probabilidad de conseguir el mejor rendimiento de consulta, siempre y cuando el resto de las demás condiciones del sistema permanezcan invariables. Si no conoce el número de particiones, puede usar setMaxDegreeOfParallelism para establecer un número alto y el sistema elegirá el mínimo (número de particiones, entrada proporcionada por el usuario) como el grado máximo de paralelismo.
Es importante tener en cuenta que las consultas en paralelo producen los mejores beneficios si los datos se distribuyen uniformemente entre todas las particiones con respecto a la consulta. Si la colección con particiones está dividida de tal forma que todos, o la mayoría de datos, devueltos por una consulta se concentran en algunas particiones (una partición en el peor de los casos), entonces el rendimiento de la consulta se vería afectada por cuellos de botella debido a esas particiones.
(b) La consulta paralela Ajuste setMaxBufferedItemCount está diseñado para capturar previamente los resultados mientras el cliente procesa el lote actual de resultados. La captura previa ayuda a mejorar la latencia general de una consulta. setMaxBufferedItemCount limita el número de resultados capturados previamente. Si establece setMaxBufferedItemCount en el número esperado de resultados devueltos (o un número más alto), esto permite que la consulta reciba el máximo beneficio de la captura previa.
La captura previa funciona de la misma manera con independencia de MaxDegreeOfParallelism, y existe un único búfer para los datos de todas las particiones.
Implementación del retroceso según intervalos de getRetryAfterInMilliseconds
Durante las pruebas de rendimiento, debe aumentar la carga hasta que se limite una tasa de solicitudes pequeña. Si se limita, la aplicación del cliente debe retroceder de acuerdo con la limitación para el intervalo de reintento que el servidor especificó. Respetar el retroceso garantiza que dedica una cantidad de tiempo mínima de espera entre reintentos. Se incluye compatibilidad con la directiva de reintentos en la versión 1.8.0 y versiones posteriores del SDK sincrónico de Java Azure Cosmos DB. Para más información, vea getRetryAfterInMilliseconds.
Escalado horizontal de la carga de trabajo de cliente
Si va a realizar pruebas en niveles de alto rendimiento (>50 000 RU/s), la aplicación cliente puede volverse un cuello de botella debido a que la máquina limita el uso de CPU o de la red. Si llega a este punto, puede seguir insertando la cuenta de Azure Cosmos DB mediante la escala horizontal de las aplicaciones cliente en varios servidores.
Uso del direccionamiento basado en nombres
Use el direccionamiento basado en nombres, en el que los vínculos tienen el formato
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, en lugar de SelfLinks (_self) que tiene el formatodbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>, para evitar recuperar los valores de ResourceIds de todos los recursos empleados para la construcción del vínculo. Además, a medida que se recrean estos recursos (posiblemente con el mismo nombre), almacenarlos en la caché puede que no sea útil.Ajuste del tamaño de página en consultas y fuentes de lectura para aumentar el rendimiento
Al realizar una lectura masiva de documentos mediante la funcionalidad de fuentes de lectura (por ejemplo, readDocuments) o al emitir una consulta SQL, los resultados se devuelven de forma segmentada si el conjunto de resultados es demasiado grande. De forma predeterminada, se devuelven resultados en fragmentos de 1 MB o de 100 artículos, el límite que se alcance primero.
Para reducir el número de recorridos de ida y vuelta de red necesarios para recuperar todos los resultados aplicables, puede aumentar el tamaño de página con el encabezado de solicitud x-ms-max-item-count hasta 1000. En aquellos casos en los que solo sea necesario mostrar unos cuantos resultados, por ejemplo, si la interfaz de usuario o la API de aplicación solo devuelven 10 resultados de una vez, también puede reducir el tamaño de página a 10 a fin de reducir el rendimiento consumido en las lecturas y consultas.
También puede establecer el tamaño de página con el método setPageSize.
Directiva de indexación
Exclusión de rutas de acceso sin utilizar de la indexación para acelerar las escrituras
La directiva de indexación de Azure Cosmos DB le permite especificar las rutas de acceso de documentos que se incluirán en la indexación o se excluirán de esta mediante el aprovechamiento de las rutas de acceso de indexación (setIncludedPaths y setExcludedPaths). El uso de rutas de acceso de indexación puede ofrecer un rendimiento de escritura mejorado y un almacenamiento de índices reducido en escenarios en los que los patrones de consulta se conocen de antemano, dado que los costos de indexación están directamente correlacionados con el número de rutas de acceso únicas indexadas. Por ejemplo, en el siguiente código se muestra cómo excluir una sección completa (subárbol) de los documentos de la indexación mediante el comodín "*".
Versión 2 del SDK de Java sincrónico (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Para más información, consulte Directivas de indexación de Azure Cosmos DB.
Throughput
Medición y optimización del uso menor de unidades de solicitud por segundo
Azure Cosmos DB ofrece un amplio conjunto de operaciones de base de datos, incluidas consultas relacionales y jerárquicas con funciones definidas por el usuario, procedimientos almacenados y desencadenadores. Todo funciona con los documentos dentro de una colección de base de datos. El costo asociado a cada una de estas operaciones variará en función de la CPU, la E/S y la memoria necesarias para completar la operación. En lugar de administrar y pensar sobre los recursos de hardware, puede pensar en una unidad de solicitud (RU) como una medida única para los recursos necesarios para realizar varias operaciones de la base de datos y dar servicio a una solicitud de la aplicación.
El rendimiento se aprovisiona en función del número de unidades de solicitud establecido para cada contenedor. El consumo de la unidad de solicitud se evalúa como frecuencia por segundo. Las aplicaciones que superan la frecuencia de unidad de solicitud aprovisionada para su contenedor están limitadas hasta que la frecuencia cae por debajo del nivel aprovisionado del contenedor. Si la aplicación requiere un mayor nivel de rendimiento, puede aumentar el rendimiento mediante el aprovisionamiento de unidades de solicitud adicionales.
La complejidad de una consulta afecta a la cantidad de unidades de solicitud consumidas para una operación. El número de predicados, la naturaleza de los predicados, el número de UDF y el tamaño del conjunto de datos de origen influyen en el costo de operaciones de consulta.
Para medir la sobrecarga de cualquier operación (crear, actualizar o eliminar), inspeccione el encabezado x-ms-request-charge (o la propiedad RequestCharge equivalente en ResourceResponse<T> o FeedResponse<T>>) para medir el número de unidades de solicitudes usadas por estas operaciones.
Versión 2 del SDK de Java sincrónico (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();El cargo de solicitud devuelto en este encabezado es una fracción de la capacidad de proceso aprovisionada. Por ejemplo, si tiene 2000 RU/segundo aprovisionadas, y si la consulta anterior devuelve 1000 documentos de 1 KB, el costo de la operación será 1000. Por lo tanto, al cabo de un segundo, el servidor atenderá solo dos de estas solicitudes antes de limitar la velocidad de las solicitudes posteriores. Para más información, consulte Unidades de solicitud y la calculadora de unidades de solicitud.
Administración de la limitación de velocidad y la tasa de solicitudes demasiado grande
Cuando un cliente intenta superar la capacidad de proceso reservada para una cuenta, no habrá ninguna degradación del rendimiento en el servidor y no se utilizará ninguna capacidad de proceso más allá del nivel reservado. El servidor finalizará de forma preventiva la solicitud con RequestRateTooLarge (código de estado HTTP 429) y devolverá el encabezado x-ms-retry-after-ms para indicar la cantidad de tiempo, en milisegundos, que el usuario debe esperar antes de volver a intentar realizar la solicitud.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Los SDK capturan implícitamente esta respuesta, respetan el encabezado retry-after especificado por el servidor y reintentan la solicitud. A menos que varios clientes obtengan acceso a la cuenta al mismo tiempo, el siguiente reintento se realizará correctamente.
Si tiene más de un cliente que funciona acumulativamente de forma coherente por encima de la tasa de solicitudes, puede que el número de reintentos predeterminado establecido actualmente en 9 de manera interna por el cliente no sea suficiente; en este caso, el cliente producirá una excepción DocumentClientException con el código de estado 429 para la aplicación. El número de reintentos predeterminado se puede cambiar mediante setRetryOptions en la instancia ConnectionPolicy. De forma predeterminada, la excepción DocumentClientException con el código de estado 429 se devuelve tras un tiempo de espera acumulativo de 30 segundos si la solicitud sigue funcionando por encima de la tasa de solicitudes. Esto sucede incluso cuando el número de reintentos actual es inferior al número de reintentos máximo de 9, el valor predeterminado, o un valor definido por el usuario.
Aunque el comportamiento de reintento automático ayuda a mejorar la resistencia y la usabilidad en la mayoría de las aplicaciones, podría no resultar ventajoso al realizar comparativas de rendimiento, en especial al medir la latencia. La latencia observada del cliente aumentará si el experimento llega a la limitación del servidor y hace que el SDK del cliente realice reintentos de forma silenciosa. Para evitar aumentos de latencia durante los experimentos de rendimiento, mida el gasto devuelto por cada operación y asegúrese de que las solicitudes funcionan por debajo de la tasa de solicitudes observada. Para más información, consulte Unidades de solicitud.
Diseño de documentos más pequeños para un mayor rendimiento
El gasto de solicitud (es decir, el costo de procesamiento de solicitudes) de una operación dada está directamente correlacionado con el tamaño del documento. Las operaciones con documentos grandes cuestan más que las operaciones con documentos pequeños.
Pasos siguientes
Para más información sobre cómo diseñar la aplicación para escalarla y obtener un alto rendimiento, consulte Partición y escalado en Azure Cosmos DB.