Conjuntos de datos de Azure Data Factory y Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se explica qué son los conjuntos de datos, cómo se definen en formato JSON y cómo se usan en canalizaciones de Azure Data Factory y Synapse.
Si no está familiarizado con Data Factory, consulte Introducción a Azure Data Factory para obtener información general. Para obtener más información sobre Azure Synapse, vea ¿Qué es Azure Synapse?
Información general
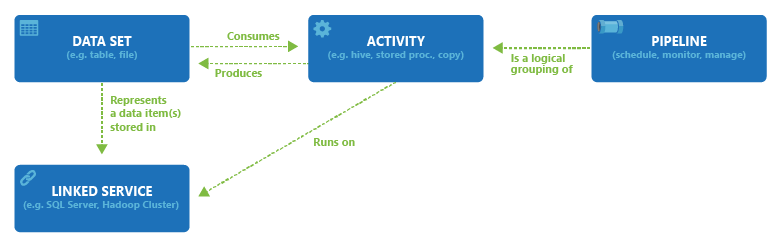
Azure Data Factory o un área de trabajo de Synapse puede tener una o varias canalizaciones. Una canalización es una agrupación lógica de actividades que realizan una tarea. Las actividades de una canalización definen las acciones que se van a realizar en los datos. Ahora, un conjunto de datos es una vista con nombre de los datos que simplemente apunta o hace referencia a los datos que desea usar en sus actividades como entradas y salidas. Los conjuntos de datos identifican datos en distintos almacenes de datos, como tablas, archivos, carpetas y documentos. Por ejemplo, un conjunto de datos de blob de Azure especifica el contenedor de blobs y la carpeta de Blob Storage de los que la actividad debe leer los datos.
Antes de crear un conjunto de datos, debe crear un servicio vinculado para vincular el almacén de datos al servicio. Los servicios vinculados son muy similares a las cadenas de conexión, que definen la información de conexión necesaria para que el servicio se conecte a recursos externos. Considérelos de esta forma: el conjunto de datos representa la estructura de los datos dentro de los almacenes de datos vinculados y el servicio vinculado define la conexión al origen de datos. Por ejemplo, un servicio vinculado de Azure Storage vincula una cuenta de almacenamiento. Un conjunto de datos de blobs de Azure representa el contenedor de blobs y la carpeta dentro de esa cuenta de Azure Storage que contiene los blobs de entrada que se van a procesar.
Este es un escenario de ejemplo. Para copiar datos de Blob Storage en SQL Database, se crean dos servicios vinculados: Azure Blob Storage y Azure SQL Database. Después, creará dos conjuntos de datos: el conjunto de datos de texto delimitado (que hace referencia al servicio vinculado de Azure Blob Storage, suponiendo que tiene archivos de texto como origen) y el conjunto de datos de Azure SQL Table (que hace referencia al servicio vinculado de Azure SQL Database). Los servicios vinculados de Azure Blob Storage y Azure SQL Database contienen cadenas de conexión que el servicio usa en tiempo de ejecución para conectarse a Azure Storage y Azure SQL Database, respectivamente. El conjunto de datos de texto delimitado especifica el contenedor de blobs y la carpeta de blobs que contiene los blobs de entrada de Blob Storage, junto con la configuración relacionada con el formato. El conjunto de datos Azure SQL Table especifica la tabla de SQL de SQL Database en la que se van a copiar los datos.
En el siguiente diagrama se muestran las relaciones entre canalización, actividad, conjunto de datos y servicios vinculados:
Cree un conjunto de datos con interfaz de usuario
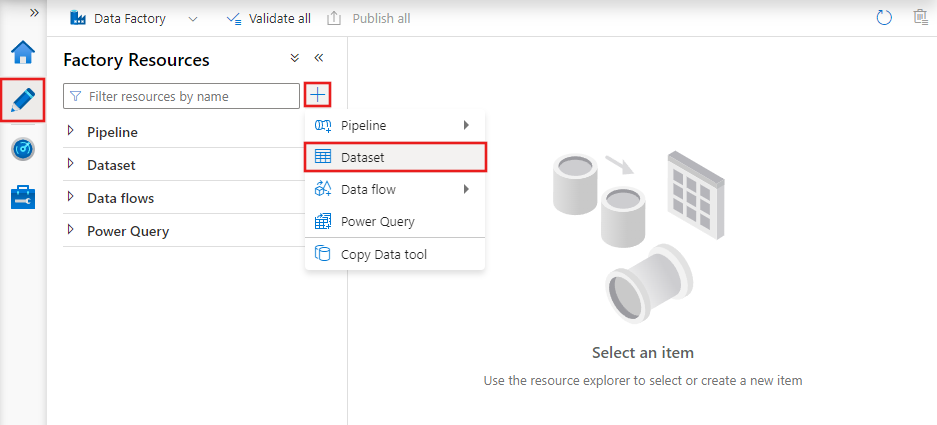
Para crear un conjunto de datos con Azure Data Factory Studio, seleccione la pestaña Autor (con el icono de lápiz) y, después, el icono de signo más para elegir Conjunto de datos.
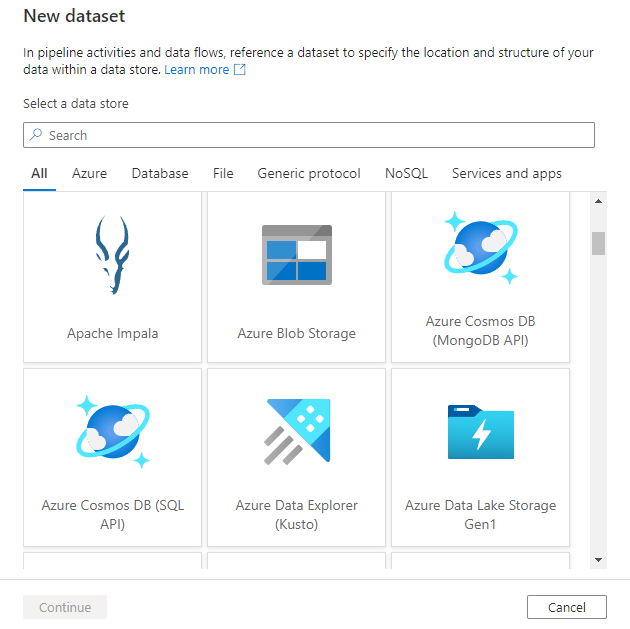
Verá la nueva ventana del conjunto de datos para elegir cualquiera de los conectores disponibles en Azure Data Factory, para configurar un servicio vinculado nuevo o existente.
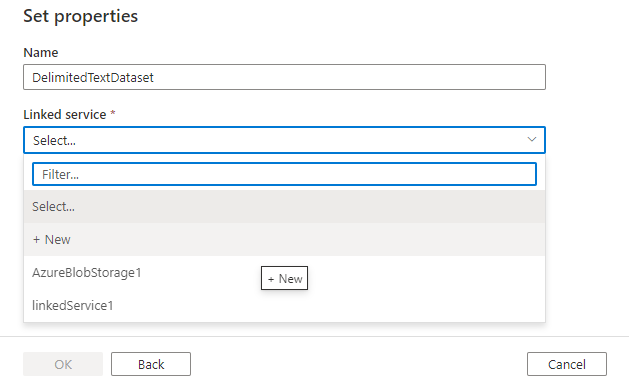
A continuación, se le pedirá que elija el formato del conjunto de datos.

Por último, puede elegir un servicio vinculado existente del tipo seleccionado para el conjunto de datos o crear uno nuevo si aún no está definido.
Una vez creado el conjunto de datos, puede usarlo dentro de las canalizaciones de Azure Data Factory.

Conjunto de datos JSON
Un conjunto de datos se define en el siguiente formato JSON:
{
"name": "<name of dataset>",
"properties": {
"type": "<type of dataset: DelimitedText, AzureSqlTable etc...>",
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference",
},
"schema":[
],
"typeProperties": {
"<type specific property>": "<value>",
"<type specific property 2>": "<value 2>",
}
}
}
La tabla siguiente describe las propiedades del JSON anterior:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| name | Nombre del conjunto de datos. Vea Reglas de nomenclatura. | Sí |
| type | Tipo de conjunto de datos. Especifique uno de los tipos admitidos por Data Factory (por ejemplo: DelimitedText, AzureSqlTable). Para más información, consulte Dataset types (Tipo de conjunto de datos). |
Sí |
| esquema | Esquema del conjunto de datos. Representa la forma y tipo de datos físico. | No |
| typeProperties | Las propiedades de tipo son diferentes para cada tipo. Para más información sobre los tipos admitidos y sus propiedades, consulte Tipo de conjunto de datos. | Sí |
Cuando importe el esquema de un conjunto de datos, seleccione el botón Importar esquema y elija Importar desde el origen o desde un archivo local. En la mayoría de los casos, importará el esquema directamente desde el origen. Pero si ya tiene un archivo de esquema local (un archivo Parquet o CSV con encabezados), puede indicarle al servicio que base el esquema en ese archivo.
En la actividad de copia, los conjunto de datos se usan en el origen y el receptor. El esquema definido en el conjunto de datos es opcional como referencia. Si quiere aplicar la asignación de campos o columnas entre el origen y el receptor, consulte Asignación de esquemas y tipos de datos.
En Data Flow, los conjuntos de datos se usan en las transformaciones de origen y receptor. Los conjuntos de datos definen los esquemas de datos básicos. Si los datos no tienen un esquema, puede utilizar un desfase de esquema para el origen y receptor. Los metadatos de los conjuntos de datos aparecen en la transformación de origen como la proyección de origen. La proyección en la transformación de origen representa los datos de Data Flow con nombres y tipos definidos.
Tipo de conjunto de datos
El servicio admite muchos tipos diferentes de conjuntos de datos, según los almacenes de datos que se usen. Puede encontrar la lista de almacenes de datos admitidos en el artículo Introducción a los conectores. Seleccione un almacén de datos para obtener información sobre cómo crear un servicio vinculado y un conjunto de datos para ese almacén de datos.
Por ejemplo, para un conjunto de datos de texto delimitado, el tipo de conjunto de datos se establece en DelimitedText, como se muestra en el siguiente ejemplo de JSON:
{
"name": "DelimitedTextInput",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorage",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "input.log",
"folderPath": "inputdata",
"container": "adfgetstarted"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
Creación de conjuntos de datos
Puede crear conjuntos de datos mediante una de estas herramientas o SDK: API de .NET, PowerShell, API de REST, plantilla de Azure Resource Manager y Azure Portal
Conjuntos de datos de la versión actual frente a los de la versión 1
Estas son algunas diferencias entre los conjuntos de datos de la versión actual de Data Factory (y Azure Synapse) y la versión 1 de Data Factory heredada:
- La propiedad externa no se admite en la versión actual. Se sustituye por un desencadenador.
- Las propiedades de directiva y disponibilidad no se admiten en la versión actual. La hora de inicio de una canalización depende de desencadenadores.
- Los conjuntos de datos de ámbito (conjuntos de datos definidos en una canalización) no se admiten en la versión actual.
Contenido relacionado
Consulte el siguiente tutorial para obtener instrucciones paso a paso sobre cómo crear canalizaciones y conjuntos de datos con una de estas herramientas o SDK.
- Inicio rápido: create a data factory using .NET (Crear una factoría de datos mediante .NET)
- Inicio rápido: create a data factory using PowerShell (Crear una factoría de datos mediante PowerShell)
- Inicio rápido: create a data factory using REST API (Crear una factoría de datos mediante la API de REST)
- Inicio rápido: creación de una factoría de datos mediante Azure Portal