Servicios vinculados en Azure Data Factory y Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describe qué son los servicios vinculados, cómo se definen en formato JSON y cómo se usan en Azure Data Factory y Azure Synapse Analytics.
Para obtener más información, lea el artículo de introducción para Azure Data Factory o Azure Synapse.
Información general
Azure Data Factory y Azure Synapse Analytics pueden tener una o varias canalizaciones. Una canalización es una agrupación lógica de actividades que realizan una tarea. Las actividades de una canalización definen las acciones que se van a realizar en los datos. Por ejemplo, podría usar una actividad de copia para copiar datos de SQL Server en una instancia de Azure Blob Storage. Después, podría usar una actividad de Hive que ejecute un script de Hive en un clúster de Azure HDInsight para procesar datos de Blob Storage con el fin de generar datos de salida. Finalmente, podría usar segunda actividad de copia para copiar los datos de salida en Azure Synapse Analytics, en función de qué soluciones de generación de informes de inteligencia empresarial (BI) estén integradas. Para más información sobre canalizaciones y actividades, consulte el artículo Canalizaciones y actividades.
Ahora, un conjunto de datos es una vista con nombre de los datos que simplemente apunta o hace referencia a los datos que desea usar en sus actividades como entradas y salidas.
Antes de crear un conjunto de datos, debe crear un servicio vinculado para vincular su almacén de datos a Data Factory o al área de trabajo de Synapse. Los servicios vinculados son muy similares a las cadenas de conexión, que definen la información de conexión necesaria para que el servicio se conecte a recursos externos. Piénselo de esta forma: el conjunto de datos representa la estructura de los datos dentro de los almacenes de datos vinculados y el servicio vinculado define la conexión al origen de datos. Por ejemplo, un servicio vinculado Azure Storage vincula una cuenta de almacenamiento al servicio. Un conjunto de datos de blobs de Azure representa el contenedor de blobs y la carpeta dentro de esa cuenta de Azure Storage que contiene los blobs de entrada que se van a procesar.
Este es un escenario de ejemplo. Para copiar datos de Blob Storage en SQL Database, se crean dos servicios vinculados: Microsoft Azure Storage y Azure SQL Database. Después, creará dos conjuntos de datos: el conjunto de datos de un blob de Azure (que hace referencia al servicio vinculado Azure Storage) y el conjunto de datos de Azure SQL Table (que hace referencia al servicio vinculado Azure SQL Database). Los servicios vinculados de Azure Storage y Azure SQL Database contienen cadenas de conexión que el servicio usa en tiempo de ejecución para conectarse a Azure Storage y Azure SQL Database, respectivamente. El conjunto de datos Azure Blob especifica el contenedor de blobs y la carpeta de blobs que contiene los blobs de entrada de Blob Storage. El conjunto de datos Azure SQL Table especifica la tabla de SQL de SQL Database en la que se van a copiar los datos.
En el siguiente diagrama se muestra la relación entre la canalización, la actividad, el conjunto de datos y el servicio vinculado en el servicio:
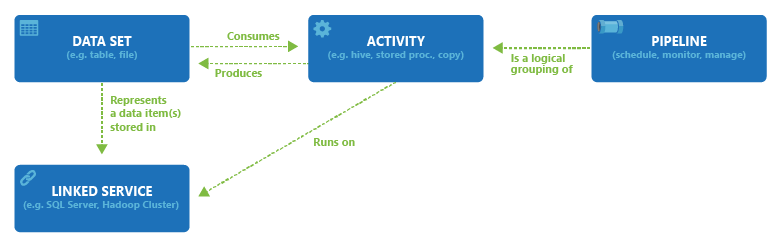
Servicio vinculado con interfaz de usuario
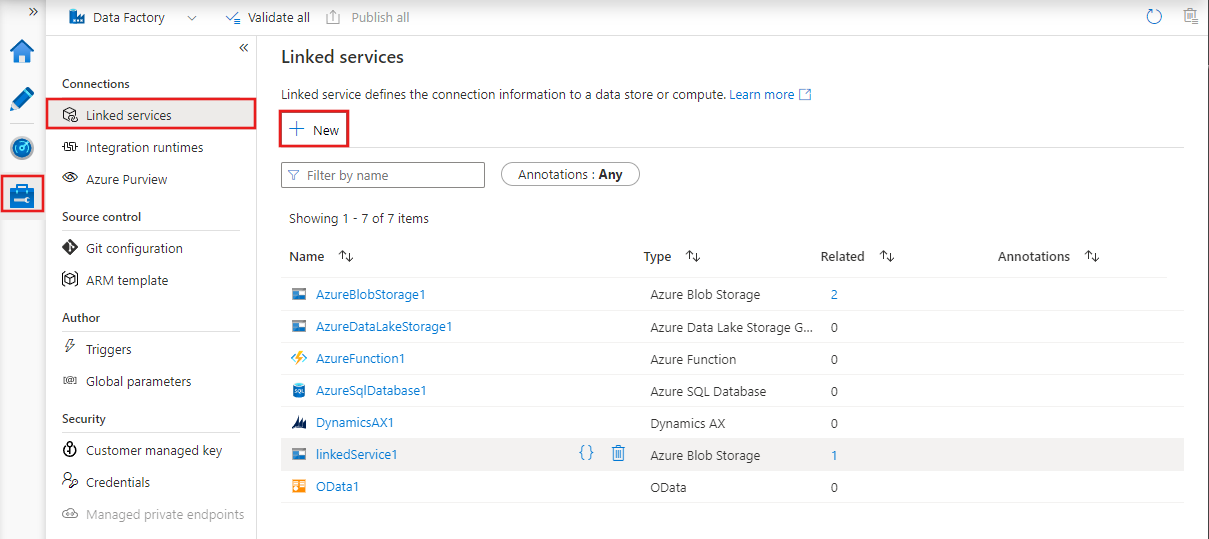
Para crear un nuevo servicio vinculado en Azure Data Factory Studio, seleccione la pestaña Administrar y, a continuación, los servicios vinculados, donde puede ver los servicios vinculados existentes que ha definido. Seleccione Nuevo para crear un servicio vinculado.
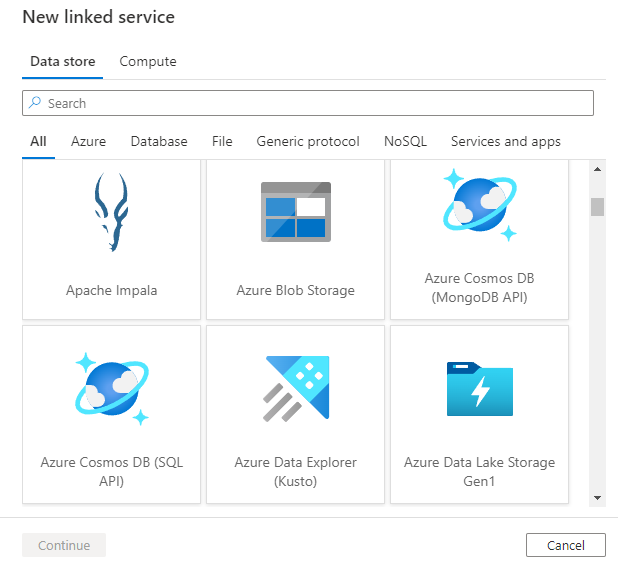
Después de seleccionar Nuevo para crear un nuevo servicio vinculado, podrá elegir cualquiera de los conectores admitidos y configurar sus detalles en consecuencia. A partir de ese momento, puede usar el servicio vinculado en las canalizaciones que cree.
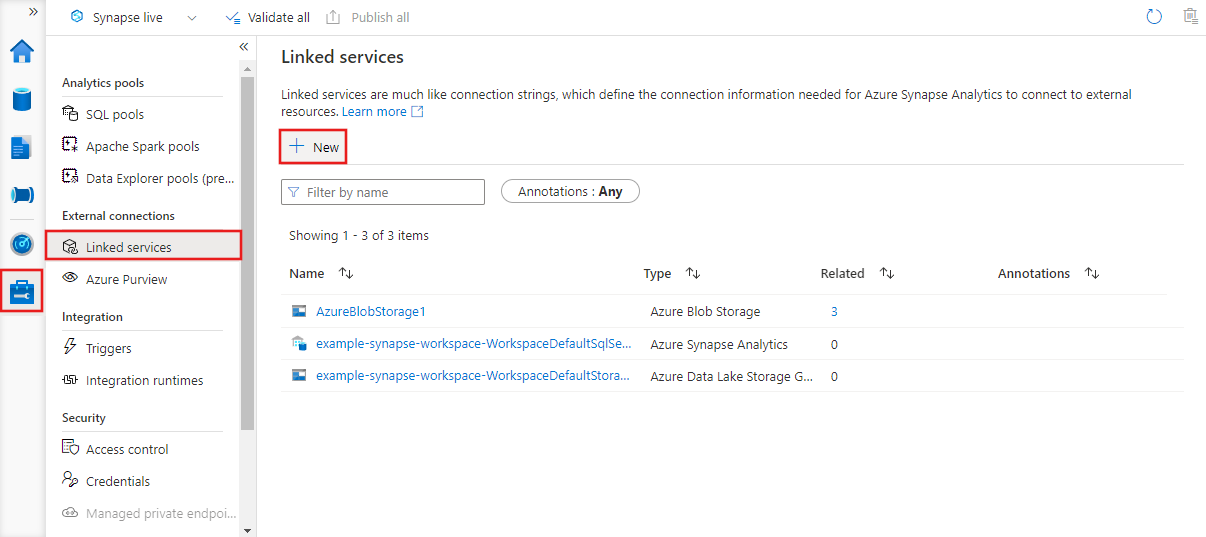
Servicio vinculado JSON
Un servicio vinculado se define con formato JSON de la manera siguiente:
{
"name": "<Name of the linked service>",
"properties": {
"type": "<Type of the linked service>",
"typeProperties": {
"<data store or compute-specific type properties>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
La tabla siguiente describe las propiedades del JSON anterior:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| name | Nombre del servicio vinculado. Vea Reglas de nomenclatura. | Sí |
| type | Tipo de servicio vinculado. Por ejemplo: AzureBlobStorage (almacén de datos) o AzureBatch (proceso). Vea la descripción de typeProperties. | Sí |
| typeProperties | Las propiedades de tipo son diferentes para cada almacén de datos o proceso. Para los tipos de almacenes de datos compatibles y sus propiedades de tipo, vea el artículo de información general sobre los conectores. Vaya al artículo del conector del almacén de datos para obtener información acerca de las propiedades de tipo específicas de un almacén de datos. Para los tipos de procesos compatibles y sus propiedades de tipo, vea Servicios de proceso vinculados. |
Sí |
| connectVia | El entorno Integration Runtime que se usará para conectarse al almacén de datos. Puede usar los entornos Integration Runtime (autohospedado) (si el almacén de datos se encuentra en una red privada) o Azure Integration Runtime. Si no se especifica, se usará Azure Integration Runtime. | No |
Ejemplo de servicio vinculado
El siguiente servicio vinculado no es un servicio vinculado de Azure Blob Storage. Tenga en cuenta que el tipo está establecido en Azure Blob Storage. Las propiedades de tipo del servicio vinculado de Azure Blob Storage incluyen una cadena de conexión. El servicio utiliza esta cadena de conexión para conectarse al almacén de datos en el entorno de ejecución.
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Crear servicios vinculados
Se pueden crear servicios vinculados en la experiencia de usuario de Azure Data Factory mediante el centro de administración y cualquier actividad, conjunto de datos o flujo de datos que haga referencia a ellos.
Los servicios vinculados se pueden crear mediante una de estas herramientas o SDK: API de .NET, PowerShell, API REST, plantilla de Azure Resource Manager y Azure Portal.
Al crear un servicio vinculado, el usuario necesita la autorización adecuada para el servicio designado. Si no se concede acceso suficiente, el usuario no podrá ver los recursos disponibles y tendrá que usar la entrada manual.
Servicios vinculados con almacenes de datos
Puede encontrar la lista de almacenes de datos admitidos en el artículo Introducción a los conectores. Haga clic en un almacén de datos para obtener información sobre las propiedades de conexión admitidas.
Servicios vinculados de proceso
Consulte Entornos de proceso compatibles para obtener detalles sobre los diferentes entornos de proceso a los que puede conectarse desde el servicio, así como las diferentes configuraciones.
Contenido relacionado
Vea los siguientes tutoriales para obtener instrucciones paso a paso sobre cómo crear canalizaciones y conjuntos de datos con una de estas herramientas o SDK.