Formato Excel en Azure Data Factory y Azure Synapse Analytics
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. ¡Obtenga más información sobre cómo iniciar una nueva evaluación gratuita!
Siga este artículo cuando desee analizar los archivos de Excel. El servicio admite ".xls" y ".xlsx".
El formato Excel se admite para los conectores siguientes: Amazon S3, Amazon S3 Compatible Storage, blob de Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, sistema de archivos, FTP, Google Cloud Storage, HDFS, HTTP, Oracle Cloud Storage y SFTP. Se admite como origen, pero no como receptor.
Nota
No se admite el formato ".xls" al usar HTTP.
Propiedades del conjunto de datos
Si desea ver una lista completa de las secciones y propiedades disponibles para definir conjuntos de datos, consulte el artículo sobre conjuntos de datos. En esta sección se proporciona una lista de las propiedades compatibles con el conjunto de datos de Excel.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del conjunto de datos debe establecerse en Excel. | Sí |
| ubicación | Configuración de ubicación de los archivos. Cada conector basado en archivos tiene su propio tipo de ubicación y propiedades compatibles en location. |
Sí |
| sheetName | Nombre de la hoja de cálculo de Excel para leer los datos. | Especifique sheetName o sheetIndex. |
| sheetIndex | Índice de hojas de cálculo de Excel para leer datos, empezando por 0. | Especifique sheetName o sheetIndex. |
| range | Intervalo de celdas de la hoja de cálculo especificada para localizar los datos selectivos, por ejemplo: - Sin especificar: lee toda la hoja de cálculo como una tabla desde la primera fila y columna que no están vacías. - A3: lee una tabla a partir de la celda dada y detecta dinámicamente todas las filas debajo y todas las columnas a la derecha.- A3:H5: lee este intervalo fijo como una tabla.- A3:A3: lee esta celda sola. |
No |
| firstRowAsHeader | Especifica si se debe tratar la primera fila del rango o la hoja de cálculo determinados como una línea de encabezado con nombres de columnas. Los valores permitidos son true y false (predeterminado). |
No |
| nullValue | Especifica la representación de cadena del valor null. El valor predeterminado es una cadena vacía. |
No |
| compression | Grupo de propiedades para configurar la compresión de archivo. Configure esta sección si desea realizar la compresión o descompresión durante la ejecución de la actividad. | No |
| type (en compression ) |
El códec de compresión usado para leer y escribir archivos JSON. Los valores permitidos son bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy o Iz4. La opción predeterminada no se comprime. Tenga en cuenta que actualmente la actividad de copia no admite "snappy" ni "lz4", y que el flujo de datos de asignación no admite "ZipDeflate", "TarGzip" ni "Tar". Tenga en cuenta que cuando utilice la actividad de copia para descomprimir archivos ZipDeflate y escribir en el almacén de datos de receptores basado en archivos, los archivos se extraerán a la carpeta <path specified in dataset>/<folder named as source zip file>/. |
No. |
| level (en compression ) |
La razón de compresión. Los valores permitidos son Optimal o Fastest. - Fastest: la operación de compresión debe completarse tan pronto como sea posible, incluso si el archivo resultante no se comprime de forma óptima. - Optimal: la operación de compresión se debe comprimir óptimamente, incluso si tarda más tiempo en completarse. Para más información, consulte el tema Nivel de compresión . |
No |
A continuación, se muestra un ejemplo de un conjunto de datos de Excel en Azure Blob Storage:
{
"name": "ExcelDataset",
"properties": {
"type": "Excel",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"sheetName": "MyWorksheet",
"range": "A3:H5",
"firstRowAsHeader": true
}
}
}
Propiedades de la actividad de copia
Si desea ver una lista completa de las secciones y propiedades disponibles para definir actividades, consulte el artículo sobre canalizaciones. En esta sección se proporciona una lista de las propiedades compatibles con el origen de Excel.
Excel como origen
En la sección *source* de la actividad de copia se admiten las siguientes propiedades.
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| type | La propiedad type del origen de la actividad de copia debe establecerse en ExcelSource. | Sí |
| storeSettings | Un grupo de propiedades sobre cómo leer datos de un almacén de datos. Cada conector basado en archivos tiene su propia configuración de lectura admitida en storeSettings. |
No |
"activities": [
{
"name": "CopyFromExcel",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ExcelSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
...
}
...
}
]
Propiedades de Asignación de instancias de Data Flow
En los flujos de datos de asignación, puede leer el formato Excel en los almacenes de datos siguientes: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Amazon S3 y SFTP. Puede apuntar a archivos de Excel mediante un conjunto de datos de Excel o mediante un conjunto de datos alineado.
Propiedades de origen
En la tabla siguiente se enumeran las propiedades que admite un origen Excel. Puede editar estas propiedades en la pestaña Opciones del origen. Al usar un conjunto de valores alineados, verá configuraciones de archivo adicionales que son iguales a las propiedades descritas en la sección Propiedades del conjunto de datos.
| Nombre | Descripción | Obligatorio | Valores permitidos | Propiedad de script de flujo de datos |
|---|---|---|---|---|
| Rutas de acceso comodín | Se procesarán todos los archivos que coincidan con la ruta de acceso comodín. Reemplaza a la carpeta y la ruta de acceso del archivo establecidas en el conjunto de datos. | no | String[] | wildcardPaths |
| Ruta de acceso raíz de la partición | En el caso de datos de archivos con particiones, puede especificar una ruta de acceso raíz de la partición para leer las carpetas con particiones como columnas. | no | String | partitionRootPath |
| Lista de archivos | Si el origen apunta a un archivo de texto que enumera los archivos que se van a procesar. | no | true o false |
fileList |
| Columna para almacenar el nombre de archivo | Se crea una nueva columna con el nombre y la ruta de acceso del archivo de origen. | no | String | rowUrlColumn |
| Después de finalizar | Se eliminan o mueven los archivos después del procesamiento. La ruta de acceso del archivo comienza en la raíz del contenedor. | no | Borrar: true o false Mover: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrar por última modificación | Elija si desea filtrar los archivos en función de cuándo se modificaron por última vez. | no | Marca de tiempo | modifiedAfter modifiedBefore |
| No permitir que se encuentren archivos | Si es true, no se devuelve un error si no se encuentra ningún archivo. | no | true o false |
ignoreNoFilesFound |
Ejemplo de origen
En la imagen siguiente se presenta un ejemplo de una configuración de origen Excel en flujos de datos de asignación mediante un modo de conjunto de datos.
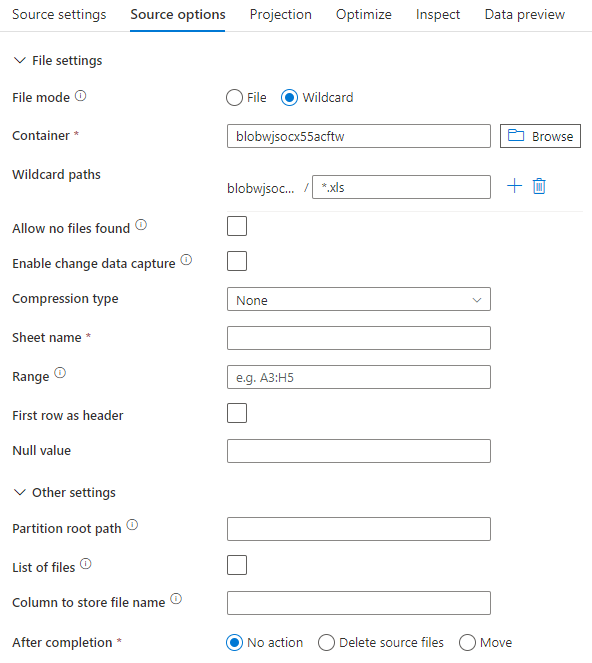
El script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
wildcardPaths:['*.xls']) ~> ExcelSource
Si usa un conjunto de datos alineado, verá las siguientes opciones de origen en el flujo de datos de asignación.
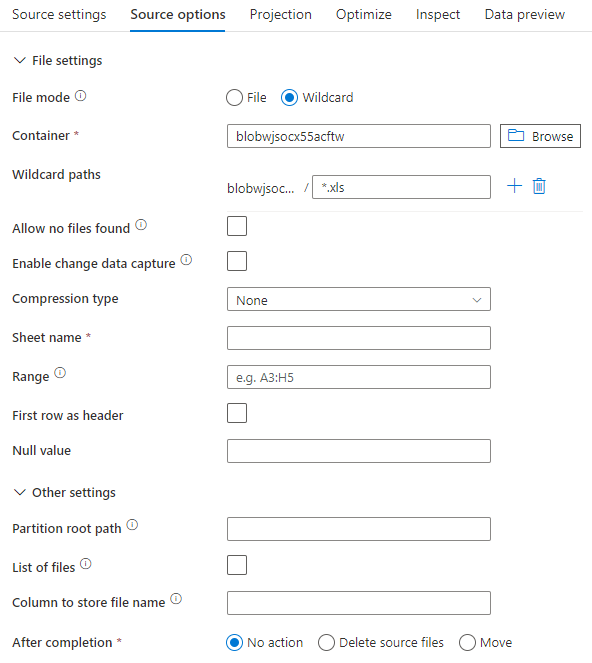
El script de flujo de datos asociado es:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'excel',
fileSystem: 'container',
folderPath: 'path',
fileName: 'sample.xls',
sheetName: 'worksheet',
firstRowAsHeader: true) ~> ExcelSourceInlineDataset
Control de archivos de Excel muy grandes
El conector de Excel no admite la lectura de streaming para la actividad de copia y debe cargar todo el archivo en la memoria para que se puedan leer los datos. Para importar el esquema, obtener una vista previa de los datos o actualizar un conjunto de Excel, los datos deben devolverse antes del tiempo de espera de la solicitud HTTP (100 s). En el caso de los archivos de Excel grandes, es posible que estas operaciones no finalicen en ese plazo, lo que produce un error de tiempo de espera. Si desea mover archivos de Excel grandes (>100 MB) a otro almacén de datos, puede usar una de las siguientes opciones para evitar esta limitación:
- Use el entorno de ejecución de integración autohospedado (SHIR) y la actividad de copia para mover el archivo de Excel grande a otro almacén de datos con el SHIR.
- Divida el archivo de Excel grande en varios más pequeños y use la actividad de copia para mover la carpeta que contiene los archivos.
- Use una actividad de flujo de datos para mover el archivo de Excel grande a otro almacén de datos. El flujo de datos admite la lectura de streaming para Excel y puede mover o transferir archivos grandes rápidamente.
- Convierta manualmente el archivo de Excel grande a formato CSV y use una actividad de copia para mover el archivo.