Uso de características en el almacén de características del área de trabajo
Nota:
En esta documentación, se describe el almacén de características del área de trabajo. Databricks recomienda el uso de la ingeniería de características en Unity Catalog. El almacén de características del área de trabajo quedará en desuso en el futuro.
En esta página se describe cómo crear y trabajar con tablas de características en el almacén de características del área de trabajo.
Nota:
Si el área de trabajo está habilitada para Unity Catalog, cualquier tabla administrada por Unity Catalog que tenga una clave principal es automáticamente una tabla de características que puede usar para el entrenamiento y la inferencia de modelos. Todas las funciones del Unity Catalog, como la seguridad, el linaje, el etiquetado y el acceso entre áreas de trabajo, están disponibles automáticamente para la tabla de características. Para más información sobre cómo trabajar con tablas de características en un área de trabajo habilitada para Unity Catalog, consulte Ingeniería de características en Unity Catalog.
Para obtener información sobre el seguimiento del linaje y la actualización de características, consulte Detección de características y seguimiento del linaje de características.
Nota:
Los nombres de bases de datos y de tablas de características solo pueden contener caracteres alfanuméricos y guiones bajos (_).
Creación de una base de datos para tablas de características
Antes de crear tablas de características, debe crear una base de datos para almacenarlas.
%sql CREATE DATABASE IF NOT EXISTS <database-name>
Las tablas de características se almacenan como tablas Delta. Al crear una tabla de características con create_table (cliente de Feature Store v0.3.6 y versiones posteriores) o create_feature_table (v0.3.5 y versiones posteriores), debes especificar el nombre de la base de datos. Por ejemplo, este argumento crea una tabla Delta denominada customer_features en la base de datos recommender_system.
name='recommender_system.customer_features'
Al publicar una tabla de características en un almacén en línea, los nombres predeterminados de la tabla y de la base de datos son los que especificó al crear la tabla. Para especificar otros nombres, use el método publish_table.
La interfaz de usuario del almacén de características de Databricks muestra el nombre de la tabla y de la base de datos en el almacén en línea, junto con otros metadatos.
Creación de una tabla de características en el Almacén de características de Databricks
Nota:
También puede registrar una tabla Delta existente como tabla de características. Consulte Registro de una tabla Delta existente como tabla de características.
Los pasos básicos para crear una tabla de características son los siguientes:
- Escriba las funciones de Python para procesar las características. La salida de cada función debe ser un objeto DataFrame de Apache Spark con una clave principal única. La clave principal puede constar de una o varias columnas.
- Crea una tabla de características mediante la creación de instancias de y
FeatureStoreClientmediantecreate_table(v0.3.6 y versiones posteriores) ocreate_feature_table(v0.3.5 y versiones posteriores). - Rellene la tabla de características con
write_table.
Para obtener más información sobre los comandos y parámetros usados en los ejemplos siguientes, consulte la referencia de Python API del almacén de características.
V0.3.6 y versiones posteriores
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
name='recommender_system.customer_features',
primary_keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_table` and specify the `df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_table(
# ...
# df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_table call
# customer_feature_table = fs.create_table(
# ...
# primary_keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
V0.3.5 y versiones anteriores
from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)from databricks.feature_store import feature_table
def compute_customer_features(data):
''' Feature computation code returns a DataFrame with 'customer_id' as primary key'''
pass
# create feature table keyed by customer_id
# take schema from DataFrame output by compute_customer_features
from databricks.feature_store import FeatureStoreClient
customer_features_df = compute_customer_features(df)
fs = FeatureStoreClient()
customer_feature_table = fs.create_feature_table(
name='recommender_system.customer_features',
keys='customer_id',
schema=customer_features_df.schema,
description='Customer features'
)
# An alternative is to use `create_feature_table` and specify the `features_df` argument.
# This code automatically saves the features to the underlying Delta table.
# customer_feature_table = fs.create_feature_table(
# ...
# features_df=customer_features_df,
# ...
# )
# To use a composite key, pass all keys in the create_feature_table call
# customer_feature_table = fs.create_feature_table(
# ...
# keys=['customer_id', 'date'],
# ...
# )
# Use write_table to write data to the feature table
# Overwrite mode does a full refresh of the feature table
fs.write_table(
name='recommender_system.customer_features',
df = customer_features_df,
mode = 'overwrite'
)
Registro de una tabla Delta existente como tabla de características
Con v0.3.8 y versiones posteriores, puedes registrar una tabla Delta existente como tabla de características. La tabla Delta debe existir en el metastore.
Nota:
Para actualizar una tabla de características registrada, debe usar la API de Python del almacén de características.
fs.register_table(
delta_table='recommender.customer_features',
primary_keys='customer_id',
description='Customer features'
)
Control del acceso a las tablas de características
Vea Control del acceso a las tablas de características.
Actualización de la tabla de características
Para actualizar una tabla de características, agregue características nuevas o modifique filas específicas en función de la clave principal.
No se pueden actualizar los metadatos siguientes de la tabla de características:
- Clave principal
- Clave de partición
- Nombre o tipo de una característica existente
Adición de características nuevas a una tabla de características existente
Puede agregar características nuevas a una tabla de características existente de alguna de estas dos formas:
- Actualice la función de cálculo de características existente y ejecute
write_tablecon el objeto DataFrame devuelto. Esto actualiza el esquema de la tabla de características y combina los valores de las características nuevas en función de la clave principal. - Cree una función de cálculo de características para calcular los valores de las características nuevas. El objeto DataFrame que esta nueva función de cálculo devuelve debe contener las claves principales y las claves de partición (si se han definido) de las tablas de características. Ejecute
write_tablecon el objeto DataFrame para escribir las características nuevas en la tabla de características existente, con la misma clave principal.
Actualización exclusiva de filas específicas de una tabla de características
Use mode = "merge" en write_table. Las filas cuya clave principal no existe en el objeto DataFrame enviado en la llamada a write_table permanecen sin cambios.
fs.write_table(
name='recommender.customer_features',
df = customer_features_df,
mode = 'merge'
)
Programación de un trabajo para actualizar una tabla de características
Para asegurarse de que las características de las tablas correspondientes siempre tengan los valores más recientes, Databricks le recomienda crear un trabajo que ejecute un cuaderno para actualizar la tabla de características de forma periódica, por ejemplo, cada día. Si ya ha creado un trabajo no programado, puede convertirlo en trabajo programado para asegurarse de que los valores de las característica estén siempre actualizados.
El código para actualizar una tabla de características usa mode='merge', como se muestra en el ejemplo siguiente.
fs = FeatureStoreClient()
customer_features_df = compute_customer_features(data)
fs.write_table(
df=customer_features_df,
name='recommender_system.customer_features',
mode='merge'
)
Almacenamiento de valores anteriores de características diarias
Defina una tabla de características con una clave principal compuesta. Incluya la fecha en la clave principal. Por ejemplo, en una tabla de características store_purchases, puede usar una clave principal compuesta (date, user_id) y una clave de partición date para realizar lecturas eficaces.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
partition_columns=['date'],
schema=customer_features_df.schema,
description='Customer features'
)
A continuación, puede crear código para leer desde la tabla de características con el filtrado de date hasta el período de tiempo de su interés.
También es posible crear una tabla de características de serie temporal especificando la columna date como una clave de marca de tiempo mediante el argumento timestamp_keys.
fs.create_table(
name='recommender_system.customer_features',
primary_keys=['date', 'customer_id'],
timestamp_keys=['date'],
schema=customer_features_df.schema,
description='Customer timeseries features'
)
Esto habilita las búsquedas a un momento dado cuando se usa create_training_set o score_batch. El sistema realiza una combinación de marca de tiempo as-of, utilizando el timestamp_lookup_key que especifique.
Para mantener la tabla de características actualizada, configure un trabajo programado periódicamente para escribir características o para hacer streaming de los valores de las características nuevas a la tabla de características.
Creación de una canalización de cálculo de características de streaming para actualizar características
Para crear una canalización de cálculo de características de streaming, pase como argumento un objeto DataFrame en streaming a write_table. Este método devuelve un objeto StreamingQuery.
def compute_additional_customer_features(data):
''' Returns Streaming DataFrame
'''
pass # not shown
customer_transactions = spark.readStream.load("dbfs:/events/customer_transactions")
stream_df = compute_additional_customer_features(customer_transactions)
fs.write_table(
df=stream_df,
name='recommender_system.customer_features',
mode='merge'
)
Lectura de una tabla de características
Use read_table para leer los valores de las características.
fs = feature_store.FeatureStoreClient()
customer_features_df = fs.read_table(
name='recommender.customer_features',
)
Búsqueda de tablas de características
Use la interfaz de usuario del Almacén de características para buscar o examinar tablas de características.
En la barra lateral, seleccione Machine Learning > Almacén de características para mostrar la interfaz de usuario del Almacén de características.
En el cuadro de búsqueda, escriba todo o parte del nombre de una tabla de características, una característica o un origen de datos usado para el cálculo de características. También puede escribir todo o parte de la clave o el valor de una etiqueta. En la búsqueda, no se distingue entre mayúsculas y minúsculas.

Obtención de metadatos de tabla de características
La API para obtener los metadatos de la tabla de características depende de la versión de Databricks Runtime que use. Con v0.3.6 y versiones posteriores, usa get_table. Con v0.3.5 y versiones posteriores, usa get_feature_table.
# this example works with v0.3.6 and above
# for v0.3.5, use `get_feature_table`
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.get_table("feature_store_example.user_feature_table")
Trabajo con etiquetas de tabla de características
Las etiquetas son pares clave-valor que puede crear y usar para buscar tablas de características. Puede crear, editar y eliminar etiquetas mediante la interfaz de usuario del almacén de características o la API de Python del Almacén de características.
Trabajo con etiquetas de tabla de características en la interfaz de usuario
Use la interfaz de usuario del Almacén de características para buscar o examinar tablas de características. Para acceder a la interfaz de usuario en la barra lateral, seleccione Machine Learning > Almacén de características.
Adición de una etiqueta mediante la interfaz de usuario del Almacén de características
Haga clic en el
 si no está abierto. Aparece la tabla de etiquetas.
si no está abierto. Aparece la tabla de etiquetas.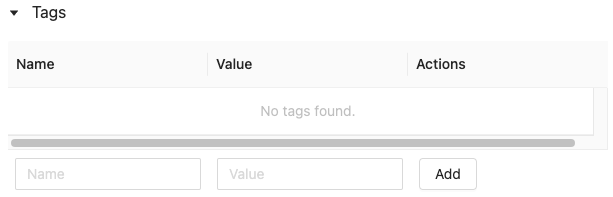
Haga clic en los campos Name (Nombre) y Value (Valor) y escriba la clave y el valor de la etiqueta.
Haga clic en Agregar.
Adición o eliminación de una etiqueta mediante la interfaz de usuario del Almacén de características
Para editar o eliminar una etiqueta, use los iconos de la columna Actions (Acciones).
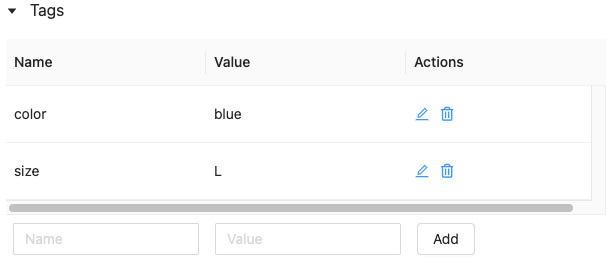
Trabajo con etiquetas de tabla de características mediante la API de Python del Almacén de características
En los clústeres que ejecutan v0.4.1 y versiones posteriores, puedes crear, editar y eliminar etiquetas mediante la API de Python del Almacén de características.
Requisitos
Característica Store client v0.4.1 y posteriores
Creación de una tabla de características con etiqueta mediante la API de Python del Almacén de características
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
customer_feature_table = fs.create_table(
...
tags={"tag_key_1": "tag_value_1", "tag_key_2": "tag_value_2", ...},
...
)
Adición, actualización y eliminación de etiquetas mediante la API de Python del Almacén de características
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Upsert a tag
fs.set_feature_table_tag(table_name="my_table", key="quality", value="gold")
# Delete a tag
fs.delete_feature_table_tag(table_name="my_table", key="quality")
Actualización de orígenes de datos para una tabla de características
El Almacén de características realiza un seguimiento automático de los orígenes de datos usados para procesar las características. También puede actualizar manualmente los orígenes de datos mediante la API de Python del Almacén de características.
Requisitos
Característica Store client v0.5.0 y posteriores
Adición de orígenes de datos mediante la API de Python del Almacén de características
A continuación, se incluyen algunos comandos de ejemplo. Para obtener más detalles, consulte la documentación de la API.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
# Use `source_type="table"` to add a table in the metastore as data source.
fs.add_data_sources(feature_table_name="clicks", data_sources="user_info.clicks", source_type="table")
# Use `source_type="path"` to add a data source in path format.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="dbfs:/FileStore/user_metrics.json", source_type="path")
# Use `source_type="custom"` if the source is not a table or a path.
fs.add_data_sources(feature_table_name="user_metrics", data_sources="user_metrics.txt", source_type="custom")
Eliminación de orígenes de datos mediante la API de Python del Almacén de características
Para obtener más detalles, consulte la documentación de la API.
Nota:
El siguiente comando elimina los orígenes de datos de todos los tipos ("table", "path" y "custom") que coinciden con los nombres de origen.
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
fs.delete_data_sources(feature_table_name="clicks", sources_names="user_info.clicks")
Eliminación de una tabla de características
Puede eliminar una tabla de características mediante la interfaz de usuario del almacén de características o la API de Python del almacén de características.
Nota:
- La eliminación de una tabla de características puede producir errores inesperados en los productores y los consumidores (modelos, puntos de conexión y trabajos programados). Debe eliminar los almacenes en línea publicados con el proveedor de nube.
- Al eliminar una tabla de características mediante la API, también se elimina la tabla Delta subyacente. Al eliminar una tabla de características de la interfaz de usuario, debe eliminar la tabla delta subyacente por separado.
Eliminación de una tabla de características mediante la interfaz de usuario
En la página de la tabla de características, haga clic en
 a la derecha del nombre de la tabla y seleccione Delete (Eliminar). Si no tiene el permiso CAN MANAGE para la tabla de características, no verá esta opción.
a la derecha del nombre de la tabla y seleccione Delete (Eliminar). Si no tiene el permiso CAN MANAGE para la tabla de características, no verá esta opción.
En el cuadro de diálogo Delete Feature Table (Eliminar tabla de características), haga clic en Delete (Eliminar) para confirmar la operación.
Si también quiere quitar la tabla Delta subyacente, ejecute el comando siguiente en un cuaderno.
%sql DROP TABLE IF EXISTS <feature-table-name>;
Eliminación de una tabla de características mediante la API de Python del Almacén de características
Con el cliente de Feature Store v0.4.1 y versiones posteriores, puede usar drop_table para eliminar una tabla de características. Cuando elimina una tabla con drop_table, también se elimina la tabla Delta subyacente.
fs.drop_table(
name='recommender_system.customer_features'
)