Creación y ejecución de trabajos de Azure Databricks
En este artículo se detalla cómo crear y ejecutar trabajos de Azure Databricks mediante la interfaz de usuario de trabajos.
Para obtener información sobre las opciones de configuración de los trabajos y cómo editar los trabajos existentes, consulte Configuración de opciones para trabajos de Azure Databricks.
Para obtener información sobre cómo administrar y supervisar las ejecuciones de trabajos, consulte Visualización y administración de ejecuciones de trabajos.
Para crear el primer flujo de trabajo con un trabajo de Azure Databricks, consulte el inicio rápido.
Importante
- Un área de trabajo está limitada a 1000 ejecuciones de tareas simultáneas. Se devuelve una respuesta
429 Too Many Requestscuando se solicita una ejecución que no se puede iniciar inmediatamente. - El número de trabajos que puede crear un área de trabajo en una hora está limitado a 10000 (incluye "envío de ejecuciones"). Este límite también afecta a los trabajos creados por los flujos de trabajo de la API REST y del cuaderno.
Creación y ejecución de trabajos mediante la CLI, la API o los cuadernos
- Para obtener información sobre cómo usar la CLI de Databricks para crear y ejecutar trabajos, consulte ¿Qué es la CLI de Databricks?.
- Para obtener información sobre el uso de la API de trabajos para crear y ejecutar trabajos, consulte Trabajos en la referencia de la API de REST.
- Para obtener información sobre cómo ejecutar y programar trabajos directamente en un cuaderno de Databricks, consulte Creación y administración de trabajos de cuadernos programados.
Creación de un trabajo
Realice una de las siguientes acciones:
- Haga clic en
 Jobs en la barra lateral y haga clic en
Jobs en la barra lateral y haga clic en  .
. - En la barra lateral, haga clic en
 Nuevo y seleccione Trabajo.
Nuevo y seleccione Trabajo.
Aparece la pestaña Tareas con el cuadro de diálogo crear tarea junto con el panel lateral Detalles del trabajo que contiene la configuración de nivel de trabajo.
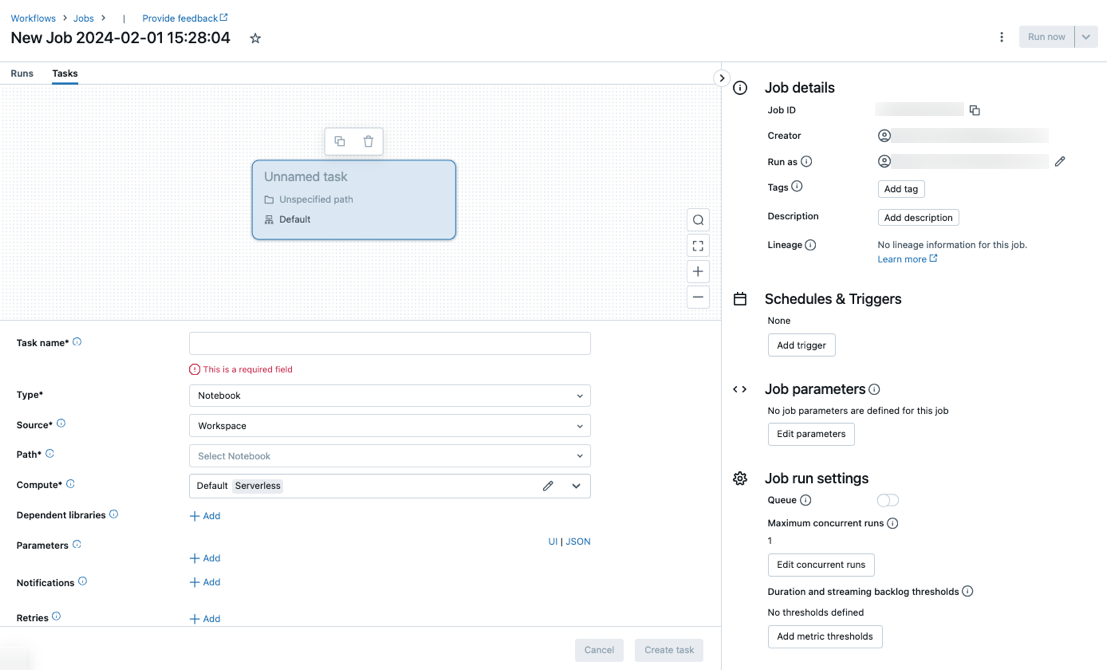
- Haga clic en
Reemplace Nuevo trabajo… por el nombre del trabajo.
Escriba un nombre para la tarea en el campo Nombre de la tarea.
En el menú desplegable Type, seleccione el tipo de tarea que se va a ejecutar. Consulte Opciones de tipo de tarea.
Configure el clúster donde se ejecuta la tarea. De forma predeterminada, el proceso sin servidor se selecciona si el área de trabajo está en un área de trabajo habilitada para Unity Catalog y ha seleccionado una tarea compatible con el proceso sin servidor para los flujos de trabajo. Consulte Ejecución del trabajo de Azure Databricks con proceso sin servidor para flujos de trabajo. Si el proceso sin servidor no está disponible o desea usar otro tipo de proceso, puede seleccionar un nuevo clúster de trabajos o un clúster de uso completo existente en el menú desplegable Proceso.
- New Job Cluster: Haga clic en Edit en el menú desplegable Cluster y complete la configuración del clúster.
- Existing All-Purpose Cluster: seleccione un clúster existente en el menú desplegable Cluster. Para abrir el clúster en una página nueva, haga clic en el icono
 situado a la derecha del nombre y la descripción del clúster.
situado a la derecha del nombre y la descripción del clúster.
Para más información sobre cómo seleccionar y configurar clústeres para ejecutar tareas, consulte Uso del proceso de Azure Databricks para los trabajos.
Para agregar bibliotecas dependientes, haga clic en + Agregar junto a Bibliotecas dependientes. Consulte Configuración de bibliotecas dependientes.
Puede pasar parámetros para la tarea. Para obtener información sobre los requisitos para dar formato y pasar parámetros, consulte Paso de parámetros a una tarea de trabajo de Azure Databricks.
Para recibir notificaciones opcionales para el inicio, el éxito o el error de la tarea, haga clic en + Agregar junto a Correos electrónicos. Las notificaciones de error se envían en caso de error en la tarea inicial y los reintentos posteriores. Para filtrar las notificaciones y reducir el número de correos electrónicos enviados, active Silenciar notificaciones para ejecuciones omitidas, Silenciar notificaciones para ejecuciones canceladas o Silenciar notificaciones hasta el último reintento.
Para configurar opcionalmente una directiva de reintentos para la tarea, haga clic en + Agregar junto a Reintentos. Consulte Configuración de una directiva de reintentos para una tarea.
Para configurar opcionalmente la duración o el tiempo de espera esperados de la tarea’, haga clic en + Agregar junto a umbral de duración. Consulte Configurar un tiempo de finalización esperado o un tiempo de espera para una tarea.
Haga clic en Crear.
Después de crear la primera tarea, puede configurar las opciones de nivel de trabajo, como notificaciones, desencadenadores de trabajos y permisos. Consulte Edición de trabajos.
Para agregar otra tarea, haga clic en el  en la vista de DAG. Se proporciona una opción de clúster compartido si ha seleccionado proceso sin servidor o ha configurado un nuevo clúster de trabajos para una tarea anterior. También puede configurar un clúster para cada tarea al crear o editar una tarea. Para más información sobre cómo seleccionar y configurar clústeres para ejecutar tareas, consulte Uso del proceso de Azure Databricks para los trabajos.
en la vista de DAG. Se proporciona una opción de clúster compartido si ha seleccionado proceso sin servidor o ha configurado un nuevo clúster de trabajos para una tarea anterior. También puede configurar un clúster para cada tarea al crear o editar una tarea. Para más información sobre cómo seleccionar y configurar clústeres para ejecutar tareas, consulte Uso del proceso de Azure Databricks para los trabajos.
Opcionalmente, puede configurar opciones de nivel de trabajo, como notificaciones, desencadenadores de trabajos y permisos. Consulte Edición de trabajos. También puede configurar parámetros de nivel de trabajo que se comparten con las tareas del trabajo. Consulte Agregar parámetros para todas las tareas de trabajo.
Opciones de tipo de tarea
A continuación se muestran los tipos de tarea que puede agregar al trabajo de Azure Databricks y las opciones disponibles para los distintos tipos de tarea:
Notebook: En el menú desplegable origen de, seleccione área de trabajo para usar un cuaderno ubicado en una carpeta del área de trabajo de Azure Databricks o proveedor de Git para un cuaderno ubicado en un repositorio de Git remoto.
Área de trabajo: use el explorador de archivos para buscar el cuaderno, haga clic en el nombre y luego en Confirmar.
Proveedor de Git: Haga clic en Editar o Agregar una referencia de Git y escriba la información del repositorio de Git. Consulte Uso de un cuaderno desde un repositorio de Git remoto.
Nota:
La salida total de la celda del cuaderno (la salida combinada de todas las celdas del cuaderno) está sujeta a un límite de tamaño de 20 MB. Además, la salida de celda individual está sujeta a un límite de tamaño de 8 MB. Si el tamaño de la salida total de la celda supera los 20 MB, o si la salida de una celda individual es mayor que 8 MB, la ejecución se cancela y se marca como con errores.
Si necesita ayuda para encontrar las celdas que están cerca o fuera del límite, ejecute el cuaderno en un clúster de uso general y use esta técnica de autoguardado del cuaderno.
JAR: especifique la clase Main. Use el nombre completo de la clase que contiene el método Main, por ejemplo,
org.apache.spark.examples.SparkPi. Después, haga clic en Add (Agregar) en Dependent Libraries (Bibliotecas dependientes) para agregar las bibliotecas necesarias para ejecutar la tarea. Una de estas bibliotecas debe contener la clase Main.Para más información sobre las tareas JAR, consulte Uso de un archivo JAR en un trabajo de Azure Databricks.
Spark Submit: en el cuadro de texto Parameters (Parámetros), especifique la clase Main, la ruta de acceso al archivo JAR de la biblioteca y todos los argumentos, con el formato de una matriz de cadenas JSON. En el ejemplo siguiente se configura una tarea spark-submit para ejecutar
DFSReadWriteTestdesde los ejemplos de Apache Spark:["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Importante
Hay varias limitaciones para las tareas spark-submit:
- Solo se pueden ejecutar las tareas spark-submit en clústeres nuevos.
- Spark-submit no admite el escalado automático del clúster. Para más información sobre el escalado automático, consulte Escalado automático de clústeres.
- Spark-submit no admite referencia de utilidades de Databricks (dbutils). Para usar utilidades de Databricks, use tareas JAR en su lugar.
- Si usa un clúster habilitado para Unity Catalog, solo se admite spark-submit si el clúster usa el modo de acceso asignado. No se admite el modo de acceso compartido.
- No se debe establecer nunca el número máximo de ejecuciones simultáneas de los trabajos de Spark Streaming en mayor que 1. Los trabajos de streaming deben establecerse para ejecutarse mediante la expresión cron
"* * * * * ?"(cada minuto). Dado que una tarea de streaming se ejecuta continuamente, siempre debe ser la tarea final en un trabajo.
Script de Python: en el menú desplegable Source, seleccione una ubicación para el script de Python; Workspace para un script en el área de trabajo local, DBFS para un script ubicado en DBFS o Git provider para un script ubicado en un repositorio de Git. En el cuadro de texto Path, escriba la ruta de acceso al script de Python:
Workspace: en el cuadro de diálogo Select Python File, vaya al script de Python y haga clic en Confirm.
DBFS: escriba el URI de un script de Python en DBFS o en almacenamiento en la nube; por ejemplo,
dbfs:/FileStore/myscript.py.Proveedor de Git: haga clic en Editar y escriba la información del repositorio de Git. Consulte Uso de código de Python desde un repositorio de Git remoto.
Canalización de Delta Live Tables: en el menú desplegable de Pipeline, seleccione una canalización de Delta Live Tables existente.
Importante
Solo puede usar canalizaciones desencadenadas con la tarea Canalización. Las canalizaciones continuas no se admiten como una tarea de trabajo. Para más información sobre las canalizaciones desencadenadas y continuas, consulte Canalizaciones continuas y desencadenadas.
Python Wheel: en el cuadro de texto Package name (Nombre del paquete), escriba el paquete que se importará, por ejemplo,
myWheel-1.0-py2.py3-none-any.whl. En el cuadro de texto Punto de entrada, escriba la función a la que se llamará al iniciar el archivo wheel de Python. Haga clic en Add (Agregar) en Dependent Libraries (Bibliotecas dependientes) para agregar las bibliotecas necesarias para ejecutar la tarea.SQL: en el menú desplegable Tarea de SQL, seleccione Consulta, Panel heredado, Alerta o Archivo.
Nota:
- La tarea SQL requiere Databricks SQL y un almacén de SQL sin servidor o pro.
Consulta: En el menú desplegable consulta SQL de, seleccione la consulta que se ejecutará cuando se ejecute la tarea.
Panel: en el menú desplegable Panel de SQL, seleccione un panel que se actualizará cuando se ejecute la tarea.
Alert: en el menú desplegable SQL alert, seleccione una alerta que se desencadene para la evaluación.
Archivo: Para usar un archivo SQL ubicado en una carpeta del área de trabajo de Azure Databricks, en el menú desplegable Origen, seleccione Área de trabajo, use el explorador de archivos para buscar el archivo SQL, haga clic en el nombre de archivo y haga clic en Confirmar. Para usar un archivo SQL ubicado en un repositorio de Git remoto, seleccione proveedor de Git, haga clic en Editar o Agregar una referencia de Git y escriba los detalles del repositorio de Git. Vea Uso de consultas SQL desde un repositorio de Git remoto.
En el menú desplegable SQL warehouse, seleccione un almacén pro SQL o sin servidor para ejecutar la tarea.
dbt: Vea Uso de transformaciones dbt en un trabajo de Azure Databricks para obtener un ejemplo detallado de configuración de una tarea dbt.
Run Job: en el menú desplegable Job, seleccione un trabajo que ejecutará la tarea. Para buscar el trabajo que se va a ejecutar, empiece a escribir el nombre del trabajo en el menú Trabajo.
Importante
No debe crear trabajos con dependencias circulares al usar la tarea
Run Jobo los trabajos que anidan más de tres tareasRun Job. Las dependencias circulares son tareasRun Jobque se desencadenan directa o indirectamente entre sí. Por ejemplo, el trabajo A desencadena el trabajo B y el trabajo B desencadena el trabajo A. Databricks no admite trabajos con dependencias circulares o que anidan más de tres tareasRun Joby podrían no permitir la ejecución de estos trabajos en futuras versiones.If/else: para aprender cómo usar la tarea
If/else condition, consulte Agregar lógica de rama al trabajo con la tarea de condición if/else.
Paso de parámetros a una tarea de trabajo de Azure Databricks
Puede pasar parámetros a muchos de los tipos de tareas de trabajo. Cada tipo de tarea tiene diferentes requisitos para dar formato y pasar los parámetros.
Para obtener acceso a información sobre la tarea actual, como el nombre de la tarea, o pasar contexto sobre la ejecución actual entre tareas de trabajo, como la hora de inicio del trabajo o el identificador de la ejecución del trabajo actual, use referencias de valor dinámico. Para ver una lista de referencias de valor dinámico disponibles, haga clic en Examinar valores dinámicos.
Si los parámetros de trabajo están configurados en el trabajo al que pertenece una tarea, esos parámetros se muestran al agregar parámetros de tarea. Si los parámetros de trabajo y tarea comparten una clave, el parámetro de trabajo tiene prioridad. Se muestra una advertencia en la interfaz de usuario si intenta agregar un parámetro de tarea con la misma clave que un parámetro de trabajo. Para pasar parámetros de trabajo a tareas que no están configuradas con parámetros clave-valor, como las tareas JAR o Spark Submit, dé formato a argumentos como {{job.parameters.[name]}}, reemplazando [name] por el key que identifica el parámetro.
Notebook (Cuaderno): haga clic en Add (Agregar) y especifique la clave y el valor de cada parámetro que se pasará a la tarea. Puede invalidar o agregar parámetros adicionales al ejecutar manualmente una tarea mediante la opción Run a job with different parameters (Ejecutar un trabajo con parámetros diferentes). Los parámetros establecen el valor del widget de cuaderno especificado por la clave del parámetro.
JAR: use una matriz de cadenas con formato JSON para especificar los parámetros. Estas cadenas se pasan como argumentos al método Main de la clase Main. Consulte Configuración de parámetros de trabajos JAR.
Spark Submit: los parámetros se especifican como una matriz de cadenas con formato JSON. Conforme a la convención Apache Spark spark-submit, los parámetros de la ruta de acceso JAR se pasan al método Main de la clase Main.
Python Wheel: en el menú desplegable Parameters, seleccione Positional arguments para escribir los parámetros como una matriz de cadenas con formato JSON o seleccione Keyword arguments > Add para escribir la clave y el valor de cada parámetro. Los argumentos posicionales y de palabra clave se pasan a la tarea de Python Wheel como argumentos de línea de comandos. Para ver un ejemplo de lectura de argumentos en un script de Python empaquetado en un archivo wheel de Python, consulte Uso de un archivo wheel de Python en un trabajo de Azure Databricks.
Ejecutar trabajo: escriba la clave y el valor de cada parámetro de trabajo para pasar al trabajo.
Python script: use una matriz de cadenas con formato JSON para especificar los parámetros. Estas cadenas se pasan como argumentos y se pueden leer como argumentos posicionales o analizar mediante el módulo argparse en Python. Para ver un ejemplo de lectura de argumentos posicionales en un script de Python, consulte Paso 2: Creación de un script para capturar datos de GitHub.
SQL: si la tarea ejecuta una consulta con parámetros o un panel con parámetros, escriba los valores de los parámetros en los cuadros de texto proporcionados.
Copiar la ruta de acceso de una tarea
Algunos tipos de tareas, por ejemplo, las tareas de cuaderno, permiten copiar la ruta de acceso al código fuente de la tarea:
- Haga clic en la pestaña Tareas.
- Seleccione la tarea que contiene la ruta de acceso que se copiará.
- Haga clic en
 junto a la clave principal para copiarla en el portapapeles.
junto a la clave principal para copiarla en el portapapeles.
Creación de un trabajo a partir de un trabajo existente
Puede crear rápidamente un nuevo trabajo clonando uno existente. La clonación de un trabajo crea una copia idéntica del trabajo, excepto el identificador del trabajo. En la página del trabajo, haga clic en More... (Más...) junto al nombre del trabajo y seleccione Clone (Clonar) en el menú desplegable.
Crear una tarea a partir de una tarea existente
Puede crear rápidamente una nueva tarea clonando una existente.
- En la página del trabajo, haga clic en la pestaña Tasks (Tareas).
- Seleccione la tarea que quiere clonar.
- Haga clic en
 y seleccione Clone task (Clonar tarea).
y seleccione Clone task (Clonar tarea).
Eliminación de un trabajo
Para eliminar un trabajo, en la página del trabajo, haga clic en More... (Más...) junto al nombre del trabajo y seleccione Delete (Eliminar) en el menú desplegable.
Eliminar una tarea
Para eliminar una tarea:
- Haga clic en la pestaña Tareas.
- Seleccione la tarea que se va a eliminar.
- Haga clic en y seleccione Remove task (Eliminar tarea).
Ejecución de un trabajo
- Haga clic en Trabajos en la barra lateral.
- Seleccione un trabajo y haga clic en la pestaña Runs (Ejecuciones). Puede ejecutar un trabajo inmediatamente o programar el trabajo para que se ejecute más adelante.
Si una o varias tareas de un trabajo con varias tareas no son correctas, puede volver a ejecutar el subconjunto de tareas incorrectas. Consulte Error en la repetición de la ejecución y tareas omitidas.
Ejecución inmediata de un trabajo
Para ejecutar el trabajo inmediatamente, haga clic en el botón  .
.
Sugerencia
Puede realizar una ejecución de prueba de un trabajo con una tarea de cuaderno haciendo clic en Run Now (Ejecutar ahora). Si necesita realizar cambios en el cuaderno, al volver a hacer clic en Run Now (Ejecutar ahora) después de editar el cuaderno, se ejecutará automáticamente la nueva versión del cuaderno.
Ejecución de un trabajo con parámetros diferentes
Puede usar Run Now with Different Parameters (Ejecutar ahora con parámetros diferentes) para volver a ejecutar un trabajo con otros parámetros o valores diferentes para los parámetros existentes.
Nota:
No se pueden invalidar los parámetros de trabajo si un trabajo que se ejecutó antes de la introducción de parámetros de trabajo reemplaza los parámetros de tarea con la misma clave.
- Haga clic en
 junto a Run Now (Ejecutar ahora) y seleccione Run Now with Different Parameters (Ejecutar ahora con parámetros diferentes) o, en la tabla Active Runs (Ejecuciones activas), haga clic en Run Now with Different Parameters (Ejecutar ahora con parámetros diferentes). Escriba los nuevos parámetros en función del tipo de tarea. Consulte Pasar parámetros a una tarea de trabajo de Azure Databricks.
junto a Run Now (Ejecutar ahora) y seleccione Run Now with Different Parameters (Ejecutar ahora con parámetros diferentes) o, en la tabla Active Runs (Ejecuciones activas), haga clic en Run Now with Different Parameters (Ejecutar ahora con parámetros diferentes). Escriba los nuevos parámetros en función del tipo de tarea. Consulte Pasar parámetros a una tarea de trabajo de Azure Databricks. - Haga clic en Ejecutar.
Ejecutar trabajo como una entidad de servicio
Nota:
Si el trabajo ejecuta consultas SQL mediante la tarea SQL, la identidad que se usa para ejecutar las consultas viene determinada por la configuración de uso compartido de cada consulta, incluso aunque el trabajo se ejecute como una entidad de servicio. Si una consulta está configurada en Run as owner, siempre se ejecutará mediante la identidad del propietario y no la identidad de la entidad de servicio. Si la consulta está configurada en Run as viewer, se ejecutará mediante la identidad de la entidad de servicio. Para más información sobre la configuración de uso compartido de consultas, consulte Configuración de permisos de consulta.
De forma predeterminada, los trabajos se ejecutan como la identidad del propietario del trabajo. Esto significa que el trabajo asume los permisos del propietario del trabajo. El trabajo solo puede acceder a datos y objetos de Azure Databricks a los que el propietario del trabajo tiene permisos para acceder. Puede cambiar la identidad en la que se ejecuta el trabajo a una entidad de servicio. A continuación, el trabajo asume los permisos de esa entidad de servicio en lugar del propietario.
Para cambiar la configuración Ejecutar como, debe tener el permiso CAN MANAGE o IS OWNER en el trabajo. Puede establecer la opción Ejecutar como en usted mismo o en cualquier entidad de servicio del área de trabajo en la que tenga el rol usuario de entidad de servicio. Para más información, consulte Roles para administrar entidades de servicio.
Nota:
Cuando la configuración RestrictWorkspaceAdmins de un área de trabajo está establecida en ALLOW ALL, los administradores del área de trabajo también pueden cambiar la opción Ejecutar como a cualquier usuario de su área de trabajo. Para restringir que los administradores del área de trabajo solo cambien la opción Ejecutar como a sí mismos o a las entidades de servicio en las que tienen el rol de usuario de entidad de servicio, consulte Restringir los administradores del área de trabajo.
Para cambiar el campo de ejecutar como, haga lo siguiente:
- En la barra lateral, haga clic en Áreas de trabajo.
- En la columna Name (Nombre), haga clic en el nombre de trabajo.
- En el panel lateral Detalles del trabajo, haga clic en el icono de lápiz situado junto al campo Ejecutar como.
- Busque y seleccione la entidad de servicio.
- Haga clic en Save(Guardar).
También puede enumerar las entidades de servicio en las que tiene el rol Usuario mediante la API de entidades de servicio del área de trabajo. Para obtener más información, vea Enumerar las entidades de servicio que puede usar.
Ejecución de un trabajo según una programación
Puede usar una programación para ejecutar automáticamente el trabajo de Azure Databricks en horas y períodos especificados. Consulte Agregar una programación de trabajo.
Ejecución de un trabajo continuo
Puede asegurarse de que siempre haya una ejecución activa del trabajo. Consulte Ejecutar un trabajo continuo.
Ejecución de un trabajo cuando llegan nuevos archivos
Para desencadenar una ejecución de trabajo cuando llegan nuevos archivos en una ubicación externa o volumen de Unity Catalog, use un desencadenador de llegada de archivos.
Visualización y ejecución de un trabajo creado con un conjunto de recursos de Databricks
Puede usar la interfaz de usuario de trabajos de Azure Databricks para ver y ejecutar trabajos implementados por un conjunto de recursos de Databricks. De forma predeterminada, estos trabajos son de solo lectura en la interfaz de usuario Trabajos. Para editar un trabajo implementado por una agrupación, cambie el archivo de configuración del lote y vuelva a implementar el trabajo. La aplicación de cambios solo a la configuración de agrupación garantiza que los archivos de origen del lote siempre capturen la configuración del trabajo actual.
Sin embargo, si debe realizar cambios inmediatos en un trabajo, puede desconectar el trabajo de la configuración de agrupación para habilitar la edición de la configuración del trabajo en la interfaz de usuario. Para desconectar el trabajo, haga clic en Desconectar del origen. En el cuadro de diálogo Desconectar del origen, haga clic en Desconectar para confirmar.
Los cambios realizados en el trabajo de la interfaz de usuario no se aplican a la configuración de agrupación. Para aplicar los cambios realizados en la interfaz de usuario a la agrupación, debe actualizar manualmente la configuración de agrupación. Para volver a conectar el trabajo a la configuración de agrupación, vuelva a implementar el trabajo mediante la agrupación.
¿Qué ocurre si mi trabajo no se puede ejecutar debido a los límites de simultaneidad?
Nota:
La puesta en cola está habilitada de forma predeterminada cuando se crean trabajos en la interfaz de usuario.
Para evitar que se omitan las ejecuciones de un trabajo debido a los límites de simultaneidad, puede habilitar la puesta en cola para el trabajo. Cuando la puesta en cola está habilitada, si los recursos no están disponibles para una ejecución de trabajo, la ejecución se pone en cola durante hasta 48 horas. Cuando la capacidad está disponible, la ejecución del trabajo se quita y se ejecuta. Las ejecuciones en cola se muestran en la lista de ejecuciones para el trabajo y la lista de ejecuciones de trabajos recientes.
Una ejecución se pone en cola cuando se alcanza uno de los límites siguientes:
- Número máximo de ejecuciones activas simultáneas en el área de trabajo.
- La tarea simultánea máxima
Run Jobse ejecuta en el área de trabajo. - Número máximo de ejecuciones simultáneas del trabajo.
La cola es una propiedad de nivel de trabajo que las colas solo se ejecutan para ese trabajo.
Para habilitar o deshabilitar la puesta en cola, haga clic en Configuración avanzada y haga clic en el botón de alternancia Cola en el panel lateral Detalles del trabajo.