Introducción a los flujos de trabajo de Azure Databricks
Los flujos de trabajo de Azure Databricks orquestan el procesamiento de datos, el aprendizaje automático y las canalizaciones de análisis en la plataforma Data Intelligence de Databricks. Los flujos de trabajo tienen servicios de orquestación totalmente administrados integrados con la plataforma Databricks, incluidos los trabajos de Azure Databricks para ejecutar código no interactivo en el área de trabajo de Azure Databricks y Delta Live Tables para crear canalizaciones ETL confiables y fáciles de mantener.
Para más información sobre las ventajas de orquestar los flujos de trabajo con la plataforma Databricks, consulte Flujos de trabajo de Databricks.
Un ejemplo de flujo de trabajo de Azure Databricks
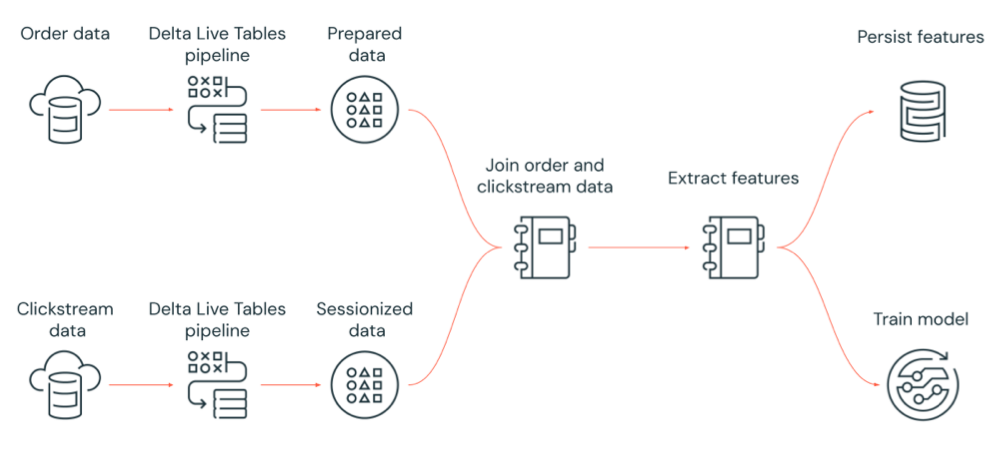
En el diagrama siguiente se muestra un flujo de trabajo orquestado por un trabajo de Azure Databricks para:
- Ejecutar una canalización de Delta Live Tables que ingiere datos de secuencia de clic sin procesar desde el almacenamiento en la nube, limpiar y preparar los datos, sesionar los datos y conservar el conjunto de datos sesionados final en Delta Lake.
- Ejecutar una canalización de Delta Live Tables que ingiere datos de pedido del almacenamiento en la nube, limpiar y transformar los datos para su procesamiento y conservar el conjunto de datos final en Delta Lake.
- Unir el pedido y los datos de secuencia de clic sesionados para crear un nuevo conjunto de datos para su análisis.
- Extraer características de los datos preparados.
- Realizar tareas en paralelo para conservar las características y entrenar un modelo de Machine Learning.
¿Qué son los trabajos de Azure Databricks?
Un trabajo de Azure Databricks es una manera de ejecutar las aplicaciones de procesamiento y análisis de datos en un área de trabajo de Azure Databricks. El trabajo puede consistir en una sola tarea o puede ser un gran flujo de trabajo de varias tareas con dependencias complejas. Azure Databricks administra la orquestación de tareas, la administración de clústeres, la supervisión y la generación de informes de errores en todos los trabajos. Puede ejecutar los trabajos inmediatamente, periódicamente a través de un sistema de programación fácil de usar, siempre que los nuevos archivos lleguen a una ubicación externa o de forma continua para asegurarse de que una instancia del trabajo siempre se está ejecutando. También puede ejecutar trabajos de forma interactiva en la interfaz de usuario del cuaderno.
Puede crear y ejecutar un trabajo mediante la interfaz de usuario de trabajos, la CLI de Databricks o invocando la API de trabajos. Puede reparar y volver a ejecutar un trabajo con errores o cancelados mediante la interfaz de usuario o la API. Puede supervisar los resultados de la ejecución de trabajos mediante la interfaz de usuario, la CLI, la API y las notificaciones (por ejemplo, correo electrónico, destino de webhook o notificaciones de Slack).
Para obtener información sobre cómo usar la CLI de Databricks, consulte ¿Qué es la CLI de Databricks? Para más información sobre el uso de la API de trabajos, consulte la API de trabajos.
En las secciones siguientes se tratan las características importantes de los trabajos de Azure Databricks.
Importante
- Un área de trabajo está limitada a 1000 ejecuciones de tareas simultáneas. Se devuelve una respuesta
429 Too Many Requestscuando se solicita una ejecución que no se puede iniciar inmediatamente. - El número de trabajos que puede crear un área de trabajo en una hora está limitado a 10000 (incluye "envío de ejecuciones"). Este límite también afecta a los trabajos creados por los flujos de trabajo de la API REST y del cuaderno.
Implementación del procesamiento y el análisis de datos con tareas de trabajo
Implemente el flujo de trabajo de procesamiento y análisis de datos mediante tareas. Un trabajo se compone de una o varias tareas. Puede crear las tareas de los trabajos que ejecutan cuadernos, JARS, canalizaciones de Delta Live Tables o aplicaciones de Python, Scala, Spark submit y Java. Las tareas de trabajo también pueden orquestar consultas, alertas y paneles de Databricks SQL para crear análisis y visualizaciones, o puede usar la tarea dbt para ejecutar transformaciones de dbt en el flujo de trabajo. También se admiten las aplicaciones de Spark Submit heredadas.
También puede agregar una tarea a un trabajo que ejecute otro trabajo. Esta característica permite dividir un proceso grande en varios trabajos más pequeños o crear módulos generalizados que varios trabajos puedan reutilizar.
Usted controla el orden de ejecución de las tareas al especificar las dependencias entre las tareas. Puede configurar tareas para que se ejecuten en secuencia o en paralelo.
Ejecutar trabajos de forma interactiva, continua o mediante desencadenadores de trabajo
Puede ejecutar los trabajos de forma interactiva desde la interfaz de usuario de trabajos, la API o la CLI, o bien puede ejecutar un trabajo continuo. Puede crear una programación para ejecutar el trabajo periódicamente o ejecutar el trabajo cuando llegan nuevos archivos a una ubicación externa, como Amazon S3 o Azure Storage o Google Cloud Storage.
Supervisión del progreso del trabajo con notificaciones
Puede recibir notificaciones cuando se inicia un trabajo o tarea, se completa o se produce un error. Puede enviar notificaciones a una o varias direcciones de correo electrónico o destinos del sistema (por ejemplo, destinos de webhook o Slack). Consulte Adición de notificaciones por correo electrónico y sistema para eventos de trabajo.
Ejecución de trabajos con recursos de proceso de Azure Databricks
Los clústeres de Databricks y el almacén de SQL proporcionan los recursos de cálculo para los trabajos. Puede ejecutar los trabajos con un clúster de trabajos, un clúster de todo propósito o un almacén de SQL:
- Un clúster de trabajos es un clúster dedicado para el trabajo o las tareas de trabajo individuales. El trabajo puede usar un clúster de trabajos compartido por todas las tareas o puede configurar un clúster para tareas individuales al crear o editar una tarea. Se crea un clúster de trabajos cuando se inicia y finaliza la tarea o el trabajo cuando finaliza el trabajo o la tarea.
- Un clúster de uso completo es un clúster compartido que se inicia y finaliza manualmente y que puede compartir varios usuarios y trabajos.
Para optimizar el uso de recursos, Databricks recomienda usar un clúster de trabajos para los trabajos. Para reducir el tiempo dedicado a esperar el inicio del clúster, considere la posibilidad de usar un clúster de uso completo. Consulte Uso del proceso de Azure Databricks con los trabajos.
Una instancia de almacén de SQL se usa para ejecutar tareas SQL de Databricks, como consultas, paneles o alertas. También puede usar una instancia de SQL Warehouse para ejecutar transformaciones dbt con la tarea dbt.
Pasos siguientes
Para introducirse en los trabajos de Azure Databricks:
Cree su primer trabajo de Azure Databricks con el inicio rápido.
Obtenga información sobre cómo crear y ejecutar flujos de trabajo con la interfaz de usuario de trabajos de Azure Databricks.
Aprenda a ejecutar un trabajo sin tener que configurar recursos de proceso de Azure Databricks con flujos de trabajo sin servidor.
Obtenga información sobre las ejecuciones de trabajos de supervisión en la interfaz de usuario de Trabajos de Azure Databricks.
Obtenga información sobre las opciones de configuración de los trabajos.
Obtenga más información sobre la creación, administración y solución de problemas de flujos de trabajo con trabajos de Azure Databricks:
- Aprenda a comunicar información entre tareas en un trabajo de Azure Databricks con valores de tarea.
- Obtenga información sobre cómo pasar contexto sobre las ejecuciones de trabajos en tareas de trabajo con variables de parámetros de tarea.
- Obtenga información sobre cómo configurar las tareas de trabajo para que se ejecuten condicionalmente en función del estado de las dependencias de la tarea.
- Aprenda a solucionar problemas y corregir trabajos con errores.
- Reciba una notificación cuando se inicie la ejecución del trabajo, complete o produzca un error con las notificaciones de ejecución del trabajo.
- Desencadene los trabajos según una programación personalizada o ejecute un trabajo continuo.
- Aprenda a ejecutar el trabajo de Azure Databricks cuando llegan nuevos datos con desencadenadores de llegada de archivos.
- Aprenda a usar los recursos de proceso de Databricks para ejecutar los trabajos.
- Obtenga información sobre las actualizaciones de Jobs API para admitir la creación y administración de flujos de trabajo con trabajos de Azure Databricks.
- Use guías y tutoriales de procedimientos para obtener más información sobre la implementación de flujos de trabajo de datos con trabajos de Azure Databricks.
¿Qué es Delta Live Tables?
Nota:
Las tablas de Delta Live requiere el plan Premium. Póngase en contacto con el equipo de la cuenta de Databricks para obtener más información.
Delta Live Tables es un marco que simplifica el procesamiento de datos ETL y streaming. Delta Live Tables proporciona una ingesta eficaz de datos con compatibilidad integrada con interfaces de Auto Loader, SQL y Python que admiten la implementación declarativa de transformaciones de datos y compatibilidad con la escritura de datos transformados en Delta Lake. Defina las transformaciones que se realizarán en los datos y Delta Live Tables administrará la orquestación de tareas, la administración de clústeres, la supervisión, la calidad de los datos y el control de errores.
Para empezar, consulte ¿Qué es Delta Live Tables?.
Trabajos de Azure Databricks y tablas dinámicas delta
Los trabajos de Azure Databricks y Delta Live Tables proporcionan un marco completo para compilar e implementar flujos de trabajo de análisis y procesamiento de datos de un extremo a otro.
Use Delta Live Tables para toda la ingesta y transformación de datos. Use trabajos de Azure Databricks para orquestar cargas de trabajo compuestas por una sola tarea o varias tareas de procesamiento y análisis de datos en la plataforma Databricks, incluida la ingesta y transformación de Delta Live Tables.
Como sistema de orquestación de flujos de trabajo, los trabajos de Azure Databricks también admiten:
- Ejecutar trabajos de forma desencadenada, por ejemplo, ejecutar un flujo de trabajo según una programación.
- Análisis de datos a través de consultas SQL, aprendizaje automático y análisis de datos con cuadernos, scripts o bibliotecas externas, etc.
- Ejecutar un trabajo compuesto por una sola tarea, por ejemplo, ejecutando un trabajo de Apache Spark empaquetado en un archivo JAR.
Orquestación de flujos de trabajo con Apache AirFlow
Aunque Databricks recomienda usar trabajos de Azure Databricks para orquestar los flujos de trabajo de datos, también puede usar Apache Airflow para administrar y programar los flujos de trabajo de datos. Con Airflow, define el flujo de trabajo en un archivo de Python y Airflow administra la programación y la ejecución del flujo de trabajo. Consulte Orquestación de trabajos de Azure Databricks con Apache Airflow.
Orquestación de flujos de trabajo con Azure Data Factory
Azure Data Factory (ADF) es un servicio de integración de datos en la nube que permite componer servicios de almacenamiento, traslado y procesamiento de datos en canalizaciones de datos automatizadas. Puede usar ADF para organizar un trabajo de Azure Databricks como parte de una canalización de ADF.
Para obtener información sobre cómo ejecutar un trabajo mediante la actividad web de ADF, incluido cómo autenticarse en Azure Databricks desde ADF, consulte Aprovechamiento de la orquestación de trabajos de Azure Databricks desde Azure Data Factory.
ADF también proporciona compatibilidad integrada para ejecutar cuadernos de Databricks, scripts de Python o código empaquetado en JAR en una canalización de ADF.
Para obtener información sobre cómo ejecutar un cuaderno de Databricks en una canalización de ADF, consulte Ejecución de un cuaderno de Databricks con la actividad del cuaderno de Databricks en Azure Data Factory, seguido de Transformación de datos mediante la ejecución de un cuaderno de Databricks.
Para obtener información sobre cómo ejecutar un script de Python en una canalización de ADF, consulte Transformación de datos mediante la ejecución de una actividad de Python en Azure Databricks.
Para más información sobre cómo ejecutar código empaquetado en un archivo JAR en una canalización de ADF, consulte Transformación de datos mediante la ejecución de una actividad JAR en Azure Databricks.