Implementación en una máquina virtual Linux
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2020
Aprenda a configurar una canalización de Azure DevOps para las implementaciones de máquinas múltiples que usan un entorno y recursos de máquina virtual.
Siga las instrucciones de este artículo para cualquier aplicación que publique un paquete de implementación web.
Requisitos previos
- Una cuenta de Azure con una suscripción activa. Cree una cuenta gratuita.
- Una organización activa de Azure DevOps. Suscribirse a Azure Pipelines.
- Una máquina virtual Linux hospedada en Azure.
- Para instalar una aplicación de JavaScript o Node.js, configure una máquina virtual Linux con Nginx en Azure. Consulte Creación de una máquina virtual Linux con la CLI de Azure.
- Para implementar aplicaciones basadas en Java Spring Boot y Spring Cloud, cree una máquina virtual Linux en Azure mediante la plantilla Java 13 en Ubuntu 20.04, que proporciona un entorno de ejecución basado en OpenJDK totalmente compatible.
Obtención del código de ejemplo
Si ya tiene una aplicación en GitHub que quiere implementar, puede intentar crear una canalización para ese código.
Si es un nuevo usuario, bifurque este repositorio en GitHub:
https://github.com/MicrosoftDocs/pipelines-javascript
Creación de un entorno con máquinas virtuales
Puede agregar máquinas virtuales como recursos dentro de entornos y dirigirse a ellas para las implementaciones de varias máquinas virtuales. La vista del historial de implementación proporciona rastreabilidad de la máquina virtual a la confirmación.
Inicie sesión en su organización de Azure DevOps y vaya a su proyecto.
Vaya a la página Canalizaciones y seleccione Entornos>Crear entorno.
Especifique un valor de Name (Nombre) (obligatorio) para el entorno y un valor de Description (Descripción).
Elija Virtual Machines como recurso que se agregará al entorno y, a continuación, seleccione Next (Siguiente).
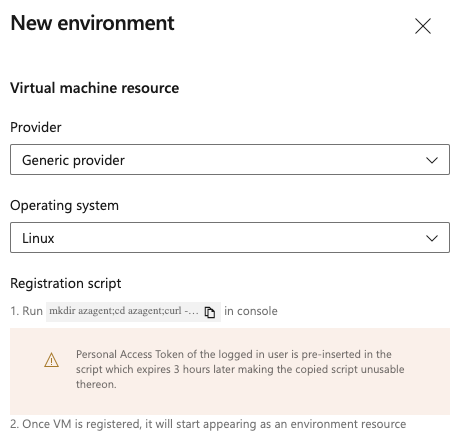
Elija el sistema operativo Linux y copie el script de registro.
Ejecute el script de registro en cada una de las máquinas virtuales de destino registradas en el entorno.
Nota:
- El token de acceso personal (PAT) del usuario que inició sesión se inserta previamente en el script y expira después de tres horas.
- Si la máquina virtual ya tiene un agente en ejecución, proporcione un nombre único para registrarlo en el entorno.
Una vez registrada la máquina virtual, comenzará a aparecer como recurso del entorno en Recursos.
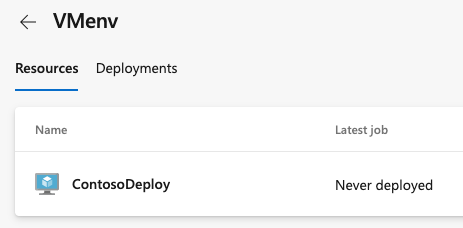
Para agregar más máquinas virtuales, vuelva a copiar el script. Seleccione Agregar recurso y, después, Máquinas virtuales. Este script es el mismo para todas las máquinas virtuales que desea agregar al mismo entorno.
Cada máquina interactúa con Azure Pipelines para coordinar la implementación de la aplicación.
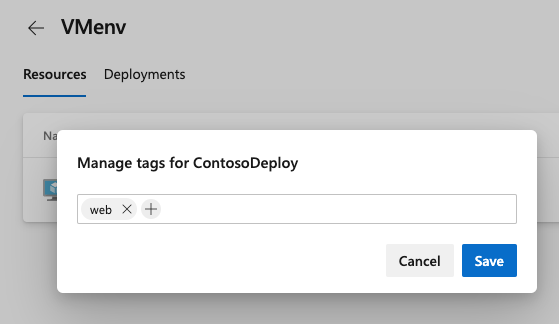
Puede agregar o quitar etiquetas para la máquina virtual. Seleccione los puntos al final de cada recurso de máquina virtual que aparecen en Recursos.
Las etiquetas limitan la implementación en máquinas virtuales específicas cuando el entorno se usa en un trabajo de implementación. Cada etiqueta está limitada a 256 caracteres. No hay ningún límite para el número de etiquetas que se pueden crear.
Definición de la canalización de compilación de CI
Necesita una canalización de compilación de CI que publique la aplicación web. También necesita un script de implementación que se pueda ejecutar localmente en el servidor Ubuntu. Configure una canalización de compilación de CI basada en el tiempo de ejecución que quiera usar.
Inicie sesión en su organización de Azure DevOps y vaya a su proyecto.
En el proyecto, vaya a la página Canalizaciones y elija la acción para crear una canalización.
Seleccione GitHub como ubicación del código fuente.
Puede que se le redirija a GitHub para iniciar sesión. Si es así, escriba sus credenciales de GitHub.
Cuando aparezca la lista de repositorios, seleccione el repositorio de aplicaciones de ejemplo que desee.
Azure Pipelines analiza el repositorio y recomienda una plantilla de canalización adecuada.
Seleccione la plantilla de inicio y copie este fragmento de código YAML para compilar un proyecto de Node.js general con npm. Lo agregará a este YAML en pasos futuros.
trigger: - main pool: vmImage: ubuntu-latest stages: - stage: Build displayName: Build stage jobs: - job: Build displayName: Build steps: - task: UseNode@1 inputs: version: '16.x' displayName: 'Install Node.js' - script: | npm install npm run build --if-present npm run test --if-present displayName: 'npm install, build and test' - task: ArchiveFiles@2 displayName: 'Archive files' inputs: rootFolderOrFile: '$(System.DefaultWorkingDirectory)' includeRootFolder: false archiveType: zip archiveFile: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip replaceExistingArchive: true - upload: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip artifact: dropPara obtener más instrucciones, revise los pasos mencionados en Compilación de la aplicación Node.js con gulp para crear una compilación.
Seleccione Guardar y ejecutar>Confirmar directamente en la rama principal> Guardar y ejecutar.
Se iniciará una nueva ejecución. Espere a que la ejecución se complete.
Definición de los pasos de CD para realizar la implementación en la máquina virtual Linux
Edite la canalización y agregue un trabajo de implementación haciendo referencia al entorno y a los recursos de máquina virtual que creó. Actualice
tagspara hacer referencia a las etiquetas de la máquina virtual.jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine tags: web1 # Update or remove value to match your tag strategy:
Para obtener más información sobre la palabra clave environment y los recursos destinados a un trabajo de implementación, consulte el esquema YAML.
Seleccione conjuntos específicos de máquinas virtuales del entorno para recibir la implementación especificando las etiquetas definidas para cada máquina virtual del entorno.
Para obtener más información, consulte el esquema YAML completo para el trabajo de implementación.
Especifique
runOnceorollingcomo estrategia de implementación.runOncees la estrategia de implementación más sencilla. Todos los enlaces del ciclo de vida (es decir,preDeploydeploy,routeTrafficypostRouteTraffic) se ejecutan una vez. A continuación se ejecutaon:successoon:failure.Consulte el ejemplo siguiente de un trabajo de implementación para
runOnce:jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine strategy: runOnce: deploy: steps: - script: echo my first deploymentConsulte el ejemplo siguiente de un fragmento de código YAML para la estrategia gradual con una canalización de Java. Puede actualizar hasta cinco destinos en cada iteración.
maxParalleldetermina el número de destinos que se pueden implementar en paralelo. La selección tiene en cuenta el número absoluto o el porcentaje de destinos que deben permanecer disponibles en cualquier momento, excluyendo los destinos en los que se está realizando la implementación. También se usa para determinar las condiciones de acierto y error durante la implementación.jobs: - deployment: VMDeploy displayName: web environment: name: <environment name> resourceType: VirtualMachine strategy: rolling: maxParallel: 2 #for percentages, mention as x% preDeploy: steps: - download: current artifact: drop - script: echo initialize, cleanup, backup, install certs deploy: steps: - task: Bash@3 inputs: targetType: 'inline' script: | # Modify deployment script based on the app type echo "Starting deployment script run" sudo java -jar '$(Pipeline.Workspace)/drop/**/target/*.jar' routeTraffic: steps: - script: echo routing traffic postRouteTraffic: steps: - script: echo health check post-route traffic on: failure: steps: - script: echo Restore from backup! This is on failure success: steps: - script: echo Notify! This is on successCon cada ejecución de este trabajo, el historial de implementación se registra en el entorno
<environment name>en el que se hayan creado y registrado las máquinas virtuales.
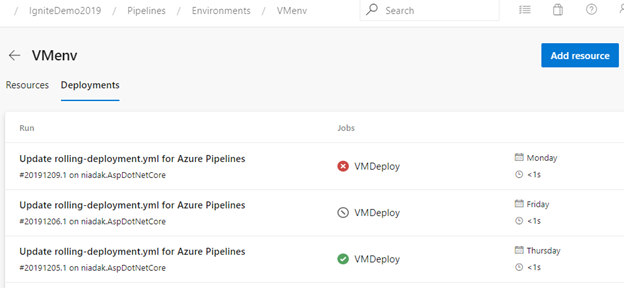
Vistas de rastreabilidad de canalización en un entorno
La vista Implementaciones proporciona una completa rastreabilidad de las confirmaciones y los elementos de trabajo, y un historial de implementación entre canalizaciones por entorno.
Pasos siguientes
Artículos relacionados
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de