Depuración del script de puntuación con el servidor HTTP de inferencia de Azure Machine Learning
El servidor HTTP de inferencia de Azure Machine Learning es un paquete de Python que expone su función de puntuación como un punto de conexión HTTP y envuelve el código y las dependencias del servidor Flask en un paquete singular. Se incluye en las imágenes de Docker precompiladas para inferencia que se usan al implementar un modelo con Azure Machine Learning. El uso del paquete por sí solo le permite implementar el modelo localmente para la producción, y también puede validar fácilmente su script de puntuación (entrada) en un entorno de desarrollo local. Si hay un problema con el script de puntuación, el servidor devolverá un error y la ubicación donde se produjo el error.
El servidor también puede usarse para crear puertas de validación en una canalización continua de integración e implementación. Puede, por ejemplo, iniciar el servidor con el script candidato y ejecutar el conjunto de pruebas en el punto de conexión local.
Este artículo está dirigido principalmente a los usuarios que quieren usar el servidor de inferencia para depurar localmente, pero también le ayudará a entender cómo usar el servidor de inferencia con puntos de conexión en línea.
Depuración local de puntos de conexión en línea
Depurar puntos de conexión localmente antes de implementarlos en la nube puede ayudarle a detectar antes errores en el código y en la configuración. Para depurar puntos de conexión localmente, puede usar:
- el servidor HTTP de inferencia de Azure Machine Learning
- un punto de conexión local
Este artículo se centra en el servidor HTTP de inferencia de Azure Machine Learning.
En la tabla siguiente encontrará información general sobre los escenarios que le ayudarán a elegir lo que le funcione mejor en su caso.
| Escenario | Servidor HTTP de inferencia | Punto de conexión local |
|---|---|---|
| Actualización del entorno de Python local, sin recompilación de imágenes de Docker | Sí | No |
| Actualización del script de puntuación | Sí | Sí |
| Actualización de las configuraciones de implementación (implementación, entorno, código, modelo) | No | Sí |
| Integración del depurador de VS Code | Sí | Sí |
Al ejecutar el servidor HTTP de inferencia localmente, puede centrarse en depurar el script de puntuación sin verse afectado por las configuraciones del contenedor de implementación.
Requisitos previos
- Requiere: Python >=3.8
- Anaconda
Sugerencia
El servidor HTTP de inferencia de Azure Machine Learning se ejecuta en Windows y en los sistemas operativos basados en Linux.
Instalación
Nota
Para evitar conflictos con los paquetes, instale el servidor en un entorno virtual.
Para instalar azureml-inference-server-http package, ejecute el siguiente comando en cmd/terminal:
python -m pip install azureml-inference-server-http
Depuración local del script de puntuación
Para depurar el script de puntuación localmente, puede probar cómo se comporta el servidor con un script de puntuación ficticio, usar VS Code para depurar con el paquete azureml-inference-server-http o probar el servidor con un script de puntuación real, un archivo de modelo y un archivo de entorno de nuestro repositorio de ejemplos.
Prueba del comportamiento del servidor con un script de puntuación ficticio
Cree un directorio para almacenar los archivos:
mkdir server_quickstart cd server_quickstartPara evitar conflictos con los paquetes, cree un entorno virtual y actívelo:
python -m venv myenv source myenv/bin/activateSugerencia
Después de las pruebas, ejecute
deactivatepara desactivar el entorno virtual de Python.Instale el paquete
azureml-inference-server-httpdesde la fuente pypi:python -m pip install azureml-inference-server-httpCreación del script de entrada (
score.py). En el ejemplo siguiente se crea un script de entrada básico:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyInicie el servidor (azmlinfsrv) y establezca
score.pycomo script de entrada:azmlinfsrv --entry_script score.pyNota
El servidor se hospeda en 0.0.0.0, lo que significa que escuchará todas las direcciones IP del equipo host.
Envíe una solicitud de puntuación al servidor mediante
curl:curl -p 127.0.0.1:5001/scoreEl servidor debe responder de esta manera.
{"message": "Hello, World!"}
Después de las pruebas, puede presionar Ctrl + C para finalizar el servidor.
Ahora puede modificar el script de puntuación (score.py) y probar sus cambios ejecutando de nuevo el servidor (azmlinfsrv --entry_script score.py).
Procedimiento para la integración con Visual Studio Code
Hay dos formas de usar Visual Studio Code (VS Code) y la Extensión de Python para depurar con el paquete azureml-inference-server-http (modos Iniciar y Adjuntar).
Modo Iniciar: configure el archivo
launch.jsonen VS Code e inicie el servidor HTTP de inferencia de Azure Machine Learning dentro de VS Code.Inicie VS Code y abra la carpeta que contiene el script (
score.py).Agregue la siguiente configuración a
launch.jsonpara esa área de trabajo en VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Inicie una sesión de depuración en VS Code. Seleccione "Ejecutar" -> "Iniciar depuración" (o
F5).
Modo Adjuntar: inicie el servidor HTTP de inferencia de Azure Machine Learning en una línea de comandos y use VS Code y la extensión de Python para adjuntarlo al proceso.
Nota
Si está usando un entorno Linux, instale primero el paquete
gdbejecutandosudo apt-get install -y gdb.Agregue la siguiente configuración a
launch.jsonpara esa área de trabajo en VS Code:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Inicie el servidor de inferencia mediante la CLI (
azmlinfsrv --entry_script score.py).Inicie una sesión de depuración en VS Code.
- En VS Code, seleccione "Ejecutar" -> "Iniciar depuración" (o
F5). - Escriba el id de proceso del
azmlinfsrv(no delgunicorn) usando los registros (del servidor de inferencia) mostrados en la CLI.
Nota
Si no aparece el selector de procesos, introduzca manualmente el id. del proceso en el campo
processIddellaunch.json.- En VS Code, seleccione "Ejecutar" -> "Iniciar depuración" (o
De ambas formas, puede establecer el punto de interrupción y depurar paso a paso.
Ejemplo de un extremo a otro
En esta sección, ejecutaremos el servidor localmente con archivos de ejemplo (script de puntuación, archivo de modelo y entorno) en nuestro repositorio de ejemplo. Los archivos de ejemplo también se usan en nuestro artículo para Implementar y puntuar un modelo de Machine Learning mediante un punto de conexión en línea.
Clone el repositorio de ejemplo.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Cree y active un entorno virtual con conda. En este ejemplo, el paquete
azureml-inference-server-httpse instala automáticamente porque está incluido como biblioteca dependiente del paqueteazureml-defaultsenconda.ymlde la siguiente manera.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envRevise el script de puntuación.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Ejecute el servidor de inferencia con la especificación del script de puntuación y el archivo de modelo. El directorio del modelo especificado (parámetro
model_dir) se definirá como variableAZUREML_MODEL_DIRy se recuperará en el script de puntuación. En este caso, se especifica el directorio actual (./), ya que el subdirectorio se especifica en el script de puntuación comomodel/sklearn_regression_model.pkl.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./El registro de inicio de ejemplo se mostrará si el servidor se inició y el script de puntuación se invocó correctamente. De lo contrario, habrá mensajes de error en el registro.
Pruebe el script de puntuación con datos de ejemplo. Abra otro terminal y vaya al mismo directorio de trabajo para ejecutar el comando. Use el comando
curlpara enviar una solicitud de ejemplo al servidor y recibir un resultado de puntuación.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonEl resultado de puntuación se devolverá si no hay ningún problema en el script de puntuación. Si encuentra algún problema, puede intentar actualizar el script de puntuación e iniciar el servidor de nuevo para probar el script actualizado.
Rutas de servidor
El servidor escucha en el puerto 5001 (como predeterminado) en estas rutas.
| Nombre | Ruta |
|---|---|
| Sondeo de ejecución | 127.0.0.1:5001/ |
| Puntuación | 127.0.0.1:5001/score |
| OpenAPI (swagger) | 127.0.0.1:5001/swagger.json |
Parámetros del servidor
La tabla siguiente contiene los parámetros que acepta el servidor:
| Parámetro | Obligatorio | Valor predeterminado | Descripción |
|---|---|---|---|
| entry_script | True | N/D | Ruta de acceso relativa o absoluta al script de puntuación. |
| model_dir | Falso | N/D | Ruta de acceso relativa o absoluta al directorio que contiene el modelo utilizado para la inferencia. |
| port | False | 5001 | Puerto de servicio del servidor. |
| worker_count | False | 1 | Número de subprocesos de trabajo que procesarán solicitudes simultáneas. |
| appinsights_instrumentation_key | Falso | N/D | Clave de instrumentación de Application Insights donde se publicarán los registros. |
| access_control_allow_origins | Falso | N/D | Habilite CORS para los orígenes especificados. Separe varios orígenes con ",". Ejemplo: "microsoft.com, bing.com" |
Flujo de las solicitudes
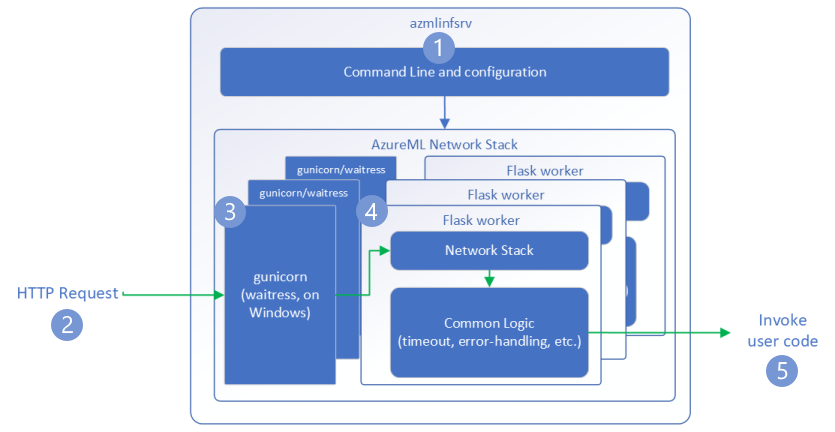
Los siguientes pasos explican cómo el servidor HTTP de inferencia de Azure Machine Learning (azmlinfsrv) gestiona las solicitudes entrantes:
- Alrededor de la pila de red del servidor, un contenedor de la CLI de Python inicia el servidor.
- Un cliente envía una solicitud al servidor.
- Cuando se recibe una solicitud, pasa por el servidor WSGI y se envía a uno de los trabajadores.
- Las solicitudes se controlan a continuación mediante una aplicación de Flask, que carga el script de entrada y las dependencias.
- Por último, la solicitud se envía al script de entrada. A continuación, el script de entrada realiza una llamada de inferencia al modelo cargado y devuelve una respuesta.
Comprender los registros
Aquí, se describen los registros del servidor HTTP de inferencia de Azure Machine Learning. Puede obtener el registro cuando ejecute el azureml-inference-server-http localmente u obtener los registros del contenedor si está usando puntos de conexión en línea.
Nota
El formato de registro ha cambiado desde la versión 0.8.0. Si encuentra su registro con un estilo diferente, actualice el paquete azureml-inference-server-http a la última versión.
Sugerencia
Si usa puntos de conexión en línea, el registro del servidor de inferencia comienza por Azure Machine Learning Inferencing HTTP server <version>.
Registros de inicio
Cuando se inicia el servidor, los registros muestran primero la configuración del servidor de la siguiente manera:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
Por ejemplo, al iniciar el servidor seguido del ejemplo de de un extremo a otro:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Formato de registro
Los registros del servidor de inferencia se generan en el siguiente formato, excepto en los scripts del iniciador, ya que no forman parte del paquete de Python:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Aquí <pid> es el id. del proceso y <level> es el primer carácter del nivel de registro: E para ERROR, I para INFO, etc.
Hay seis niveles de registro en Python, con números asociados a la gravedad:
| Nivel de registro | Valor numérico |
|---|---|
| CRÍTICO | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
Guía de solución de problemas
En esta sección, proporcionaremos sugerencias básicas de solución de problemas para el servidor HTTP de inferencia de Azure Machine Learning. Si quiere solucionar problemas de puntos de conexión en línea, vea también Solución de problemas de implementación de puntos de conexión en línea
Pasos básicos
Los pasos básicos para solucionar problemas son:
- Recopile información de versión para el entorno de Python.
- Asegúrese de que la versión del paquete de Python azureml-inference-server-http especificada en el archivo de entorno coincide con la versión del servidor HTTP de inferencia de AzureML que se muestra en el registro de inicio. A veces, el solucionador de dependencias de PIP conduce a versiones inesperadas de paquetes instalados.
- Si especifica Flask (o sus dependencias) en el entorno, quítelos. Las dependencias incluyen
Flask,Jinja2,Werkzeugitsdangerous,MarkupSafeyclick. Flask aparece como una dependencia en el paquete de servidor y es mejor permitir que nuestro servidor lo instale. De este modo, cuando el servidor admita nuevas versiones de Flask, las obtendrá automáticamente.
Versión del servidor
El paquete azureml-inference-server-http de servidor se publica en PyPI. Puede encontrar nuestro registro de cambios y todas las versiones anteriores en nuestra página de PyPI. Actualice a la versión más reciente si usa una versión anterior.
- 0.4.x: la versión que se incluye en imágenes de entrenamiento ≤
20220601y enazureml-defaults>=1.34,<=1.43.0.4.13es la última versión estable. Si usa el servidor antes de la versión0.4.11, puede ver problemas de dependencia de Flask, como que no se puede importar el nombreMarkupdesdejinja2. Se recomienda actualizar a0.4.13o0.8.x(la versión más reciente), si es posible. - 0.6.x: versión preinstalada en imágenes de inferencia ≤ 20220516. La versión estable más reciente es
0.6.1. - 0.7.x: la primera versión que admite Flask 2. La versión estable más reciente es
0.7.7. - 0.8.x: el formato de registro ha cambiado y se ha eliminado la compatibilidad con Python 3.6.
Dependencias de paquetes
Los paquetes más relevantes para el servidor azureml-inference-server-http son los siguientes:
- flask
- opencensus-ext-azure
- inference-schema
Si especificó azureml-defaults en su entorno Python, el paquete azureml-inference-server-http es dependiente y se instalará automáticamente.
Sugerencia
Si está usando Python SDK v1 y no especifica explícitamente azureml-defaults en su entorno Python, el SDK puede añadir el paquete por usted. Sin embargo, se bloqueará en la versión en la que se encuentra el SDK. Por ejemplo, si la versión del SDK es 1.38.0, se agregará azureml-defaults==1.38.0 a los requisitos de pip del entorno.
Preguntas más frecuentes
1. He encontrado el siguiente error durante el inicio del servidor:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
Tiene Flask 2 instalado en el entorno de Python, pero ejecuta una versión de azureml-inference-server-http que no admite Flask 2. La compatibilidad con Flask 2 se agrega en azureml-inference-server-http>=0.7.0, que también está en azureml-defaults>=1.44.
Si no usa este paquete en una imagen de Docker de AzureML, use la versión más reciente de
azureml-inference-server-httpoazureml-defaults.Si usa este paquete con una imagen de Docker de AzureML, asegúrese de que usa una imagen integrada o posterior a julio de 2022. La versión de la imagen está disponible en los registros de contenedor. Debería poder encontrar un registro similar al siguiente:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |La fecha de compilación de la imagen aparece después de "Compilación de materialización", que en el ejemplo anterior es
20220708, o el 8 de julio de 2022. Esta imagen es compatible con Flask 2. Si no ve un banner como este en el registro de contenedor, la imagen no está actualizada y debe actualizarse. Si usa una imagen CUDA y no encuentra una imagen más reciente, compruebe si la imagen está en desuso en AzureML-Containers. Si es así, debería poder encontrar reemplazos.Si está usando el servidor con un punto de conexión en línea, también puede encontrar los registros en "Registros de implementación" en la página del punto de conexión en línea en Estudio de Azure Machine Learning. Si implementa con SDK v1 y no especifica explícitamente una imagen en la configuración de implementación, el valor predeterminado es usar una versión de
openmpi4.1.0-ubuntu20.04que coincida con el conjunto de herramientas del SDK local, que puede que no sea la versión más reciente de la imagen. Por ejemplo, SDK 1.43 usaráopenmpi4.1.0-ubuntu20.04:20220616de forma predeterminada, que es incompatible. Asegúrese de usar el SDK más reciente para la implementación.Si por algún motivo no puede actualizar la imagen, puede evitar temporalmente el problema anclando
azureml-defaults==1.43oazureml-inference-server-http~=0.4.13, que instalará el servidor de versiones anterior conFlask 1.0.x.
2. He encontrado un ImportError o ModuleNotFoundError en los módulos opencensus, jinja2, MarkupSafe o click durante el inicio, como el mensaje siguiente:
ImportError: cannot import name 'Markup' from 'jinja2'
Las versiones anteriores (<= 0.4.10) del servidor no anclaban la dependencia de Flask a versiones compatibles. Este problema se ha corregido en la versión más reciente del servidor.
Pasos siguientes
- Para más información sobre cómo crear un script de entrada e implementar modelos, consulte Implementación de un modelo mediante Azure Machine Learning.
- Más información sobre las imágenes de Docker precompiladas para la inferencia