Agrupación en clústeres K-Means
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información sobre Azure Machine Learning.
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
Configura e inicializa un modelo de agrupación en clústeres K-means
Categoría: Machine Learning/Initialize Model/Clustering
Nota
Solo se aplica a: Machine Learning Studio ( clásico)
Hay módulos para arrastrar y colocar similares en el diseñador de Azure Machine Learning.
Información general sobre el módulo
En este artículo se describe cómo usar el módulo agrupación en clústeres K-Means en Machine Learning Studio (clásico) para crear un modelo de agrupación en clústeres K-means sin entrenar.
K-means es uno de los algoritmos de aprendizaje no supervisados más sencillos y conocidos, y se puede usar para una variedad de tareas de aprendizaje automático, como la detección de datos anómalos, la agrupación en clústeres de documentos de texto y el análisis de un conjunto de datos antes de usar otros métodos de clasificación o regresión. Para crear un modelo de agrupación en clústeres, agregue este módulo al experimento, conecte un conjunto de datos y establezca parámetros como el número de clústeres que espera, la métrica de distancia que se usará para crear los clústeres, etc.
Después de configurar los hiperparámetros del módulo, conecte el modelo no entrenado al modelo de entrenamiento de clústeres o a los módulos De agrupación en clústeres de barrido para entrenar el modelo en los datos de entrada que proporcione. Dado que el algoritmo K-means es un método de aprendizaje no supervisado, la columna de etiqueta es opcional.
- Si los datos incluyen una etiqueta, puede usar los valores de etiqueta para guiar la selección de los clústeres y optimizar el modelo.
- Si los datos no tienen ninguna etiqueta, el algoritmo crea clústeres que representan las categorías posibles, basadas únicamente en los datos.
Sugerencia
Si los datos de entrenamiento tienen etiquetas, considere la posibilidad de usar uno de los métodos de clasificación supervisados proporcionados en Machine Learning. Por ejemplo, puede comparar los resultados de la agrupación en clústeres con los resultados al usar uno de los algoritmos de árbol de decisión multiclase.
Descripción de la agrupación en clústeres k-means
En general, la agrupación en clústeres utiliza técnicas iterativas para agrupar casos en un conjunto de datos en clústeres que contengan características similares. Estas agrupaciones son útiles para explorar los datos, identificar anomalías en ellos y, finalmente, para realizar predicciones. Los modelos de agrupación en clústeres también pueden ayudarle a identificar las relaciones en un conjunto de datos que podrían no deducirse lógicamente mediante una simple observación o examen. Por estos motivos, la agrupación en clústeres se suele usar en las primeras fases de las tareas de aprendizaje automático, a fin de explorar los datos y detectar correlaciones inesperadas.
Al configurar un modelo de agrupación en clústeres mediante el método k-means, debe especificar un número de destino k que indique el número de centroides que desee en el modelo. El centroide es un punto que es representativo de cada clúster. El algoritmo K-means asigna cada punto de datos entrante a uno de los clústeres minimizando la suma en el clúster de cuadrados.
Al procesar los datos de entrenamiento, el algoritmo K-means comienza con un conjunto inicial de centroids elegidos aleatoriamente, que sirven como puntos iniciales para cada clúster y aplica el algoritmo de Lloyd para refinar de forma iterativa las ubicaciones de los centroides. El algoritmo K-means deja de generar y refinar los clústeres cuando cumplen una o varias de estas condiciones:
Los centroides se estabilizan, lo que significa que las asignaciones de clúster para puntos individuales ya no cambian y el algoritmo ha convergedo en una solución.
El algoritmo se completó ejecutando el número de iteraciones especificado.
Después de completar la fase de entrenamiento, use el módulo Asignar datos a clústeres para asignar nuevos casos a uno de los clústeres encontrados por el algoritmo k-means. La asignación de clúster se realiza calculando la distancia entre el nuevo caso y el centroide de cada clúster. Cada nuevo caso se asigna al clúster con el centroide más cercano.
Configuración de clústeres K-Means
Agregue el módulo Agrupación en clústeres K-Means al experimento.
Especifique cómo quiere que se entrene el modelo, estableciendo la opción Create trainer mode (Crear modo entrenador).
Single Parameter (Parámetro único): si conoce los parámetros exactos que desea usar en el modelo de agrupación en clústeres, puede proporcionar un conjunto específico de valores como argumentos.
Intervalo de parámetros: si no está seguro de los mejores parámetros, puede encontrar los parámetros óptimos especificando varios valores y usando el módulo De agrupación en clústeres de barrido para encontrar la configuración óptima.
El instructor recorre en iteración varias combinaciones de la configuración proporcionada y determina la combinación de valores que genera los resultados óptimos de agrupación en clústeres.
En Número de centroides, escriba el número de clústeres con los que desea que comience el algoritmo.
No se garantiza que el modelo genere exactamente este número de clústeres. Algorithn comienza con este número de puntos de datos y recorre en iteración la configuración óptima, como se describe en la sección Notas técnicas .
Si va a realizar un barrido de parámetros, el nombre de la propiedad cambia a Range for Number of Centroids (Intervalo para número de centroides). Puede usar el Generador de rangos para especificar un intervalo o puede escribir una serie de números que representan distintos números de clústeres que se van a crear al inicializar cada modelo.
Las propiedades Initialization o Initialization for sweep se usan para especificar el algoritmo que se usa para definir la configuración inicial del clúster.
Primera N: se elige un número inicial de puntos de datos del conjunto de datos y se usa como medio inicial.
También se denomina método Forgy.
Random (Aleatorio): el algoritmo coloca aleatoriamente un punto de datos en un clúster y, a continuación, calcula la media inicial para que sea el centroide de los puntos asignados de forma aleatoria del clúster.
También se denomina método de partición aleatoria .
K-Means++ : este es el método predeterminado para inicializar los clústeres.
El algoritmo K-means ++ fue propuesto en 2007 por David Arthur y Sergio Vassilvitskii para evitar una agrupación deficiente en clústeres por el algoritmo k-means estándar. K-means ++ mejora los K-means estándar mediante un método diferente para elegir los centros de clúster iniciales.
K-Means++Fast: variante del algoritmo K-means ++ optimizado para una agrupación en clústeres más rápida.
Uniformemente: los centroideos se encuentran equidistantes entre sí en el espacio dimensional d de n puntos de datos.
Usar columna de etiqueta: los valores de la columna de etiqueta se usan para guiar la selección de centroides.
Como Random number seed (Valor de inicialización aleatorio), puede escribir el valor que se usará como el inicial para la inicialización de clúster. Este valor puede tener un efecto significativo en la selección del clúster.
Si usa un barrido de parámetros, puede especificar que se creen varias semillas iniciales para buscar el mejor valor de inicialización. Para Número de semillas que se van a barrir, escriba el número total de valores de inicialización aleatorios que se van a usar como puntos iniciales.
En Metric (Métrica), elija la función que se usará para medir la distancia entre los vectores de clúster o entre los nuevos puntos de datos y el centroide elegido al azar. Machine Learning admite las siguientes métricas de distancia de clúster:
Euclidian (Euclidiana): la distancia Euclidiana se utiliza normalmente como una medida de dispersión de clúster para la agrupación en clústeres K-means. Se prefiere el uso de esta métrica porque minimiza la distancia media entre los puntos y los centroides.
Coseno: la función coseno se usa para medir la similitud del clúster. La similitud coseno es útil en los casos en los que no le importa la longitud de un vector, solo su ángulo.
En Iteraciones, escriba el número de veces que el algoritmo debe iterar los datos de entrenamiento antes de finalizar la selección de centroides.
Puede ajustar este parámetro para equilibrar la precisión frente al tiempo de entrenamiento.
En Asignar modo de etiqueta, elija una opción que especifique cómo se debe controlar una columna de etiqueta, si está presente en el conjunto de datos.
Dado que la agrupación en clústeres K-means es un método de aprendizaje de automático no supervisado, las etiquetas son opcionales. Sin embargo, si el conjunto de datos ya tiene una columna de etiqueta, puede usar esos valores para guiar la selección de los clústeres, o puede especificar que se omitan los valores.
Ignore label column (Ignorar la columna de etiqueta): los valores de la columna de etiqueta se omiten y no se usan en la creación del modelo.
Fill missing values (Completar los valores que faltan: los valores de la columna de etiqueta se usan como características para ayudar a crear los clústeres. Si en alguna de las filas falta una etiqueta, el valor se deduce con otras características.
Overwrite from closest to center (Sobrescribir desde la más cercana al centro): los valores de la columna de etiqueta son reemplazados por los valores de la etiqueta predicha, utilizando la etiqueta del punto más cercana al centroide actual.
Entrene el modelo.
Si establece Create trainer mode (Crear modo de entrenador) en Single Parameter (Parámetro único), agregue un conjunto de datos etiquetado y entrene el modelo con el módulo Train Clustering Model (Entrenamiento del modelo de agrupación en clústeres).
Si establece Crear modo instructor en Intervalo de parámetros, agregue un conjunto de datos etiquetado y entrene el modelo mediante el agrupamiento en clústeres de barrido. Puede usar el modelo entrenado con esos parámetros o puede tomar una nota de los valores de parámetro que usará al configurar un aprendiz.
Results
Una vez que haya terminado de configurar y entrenar el modelo, tiene un modelo que puede usar para generar puntuaciones. Sin embargo, hay varias formas de entrenar el modelo y varias maneras de ver y usar los resultados:
Captura de una instantánea del modelo en el área de trabajo
Si usó el módulo Entrenar modelo de agrupación en clústeres
- Haga clic con el botón secundario en el módulo Train Clustering Model clústeres (Entrenamiento del modelo de agrupación en clústeres).
- Seleccione Modelo entrenado y, a continuación, haga clic en Guardar como modelo entrenado.
Si usó el módulo De agrupación en clústeres de barrido para entrenar el modelo
- Haga clic con el botón derecho en el módulo Agrupación en clústeres de barrido .
- Seleccione Mejor modelo entrenado y, a continuación, haga clic en Guardar como modelo entrenado.
El modelo guardado representará los datos de entrenamiento en el momento en que guardó el modelo. Si posteriormente actualiza los datos de entrenamiento usados en el experimento, no actualizará el modelo guardado.
Ver una representación visual de los clústeres en el modelo
Si usó el módulo Entrenar modelo de agrupación en clústeres
- Haga clic con el botón derecho en el módulo y seleccione Conjunto de datos resultados.
- Seleccione Visualize (Visualizar).
Si usó el módulo De agrupación en clústeres de barrido
Agregue una instancia del módulo Asignar datos a clústeres y genere puntuaciones mediante el modelo mejor entrenado.
Haga clic con el botón derecho en el módulo Asignar datos a clústeres , seleccione Conjunto de datos de resultados y seleccione Visualizar.
El gráfico se genera mediante el análisis de componentes principales, que es una técnica de ciencia de datos para comprimir el espacio de características de un modelo. En el gráfico se muestran algunos conjuntos de características, comprimidos en dos dimensiones, que mejor caracterizan la diferencia entre los clústeres. Al revisar visualmente el tamaño general del espacio de características de cada clúster y cuánto se superponen los clústeres, puede obtener una idea de cómo puede funcionar el modelo.
Por ejemplo, los siguientes gráficos de PCA representan los resultados de dos modelos entrenados con los mismos datos: el primero se configuró para generar dos clústeres y el segundo se configuró para generar tres clústeres. A partir de estos gráficos, puede ver que el aumento del número de clústeres no ha mejorado necesariamente la separación de las clases.
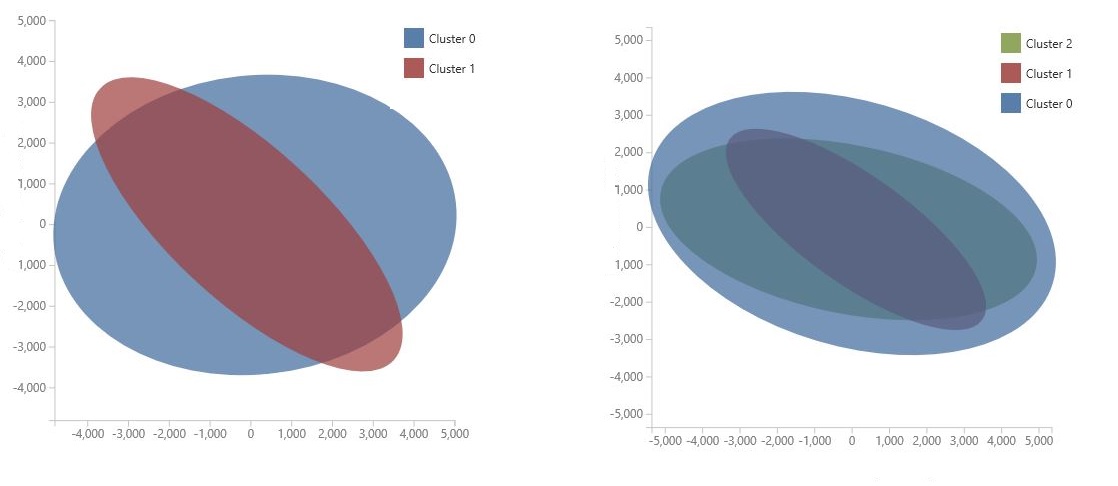
Sugerencia
Use el módulo De agrupación en clústeres de barrido para elegir el conjunto óptimo de hiperparámetros, incluida la inicialización aleatoria y el número de centroides iniciales.
Consulte la lista de puntos de datos y los clústeres a los que pertenecen.
Hay dos opciones para ver el conjunto de datos con resultados, en función de cómo entrene el modelo:
Si usó el módulo De agrupación en clústeres de barrido para entrenar el modelo
- Use la casilla del módulo Agrupación en clústeres de barrido para especificar si desea ver los datos de entrada junto con los resultados o ver solo los resultados.
- Una vez completado el entrenamiento, haga clic con el botón derecho en el módulo y seleccione Conjunto de datos resultados (número de salida 2)
- Haga clic en Visualizar.
Si usó el módulo Entrenar modelo de agrupación en clústeres
- Agregue el módulo Asignar datos a clústeres y conecte el modelo entrenado a la entrada izquierda. Conecte un conjunto de datos a la entrada de la derecha.
- Agregue el módulo Convertir al conjunto de datos al experimento y conéctelo a la salida de Asignar datos a clústeres.
- Use la casilla del módulo Asignar datos a clústeres para especificar si desea ver los datos de entrada junto con los resultados o ver solo los resultados.
- Ejecute el experimento o ejecute solo el módulo Convertir en conjunto de datos .
- Haga clic con el botón derecho en Convertir en conjunto de datos, seleccione Conjunto de datos de resultados y haga clic en Visualizar.
La salida contiene primero las columnas de datos de entrada, si las incluyó y las columnas siguientes para cada fila de datos de entrada:
Asignación: la asignación es un valor entre 1 y n, donde n es el número total de clústeres del modelo. Cada fila de datos solo se puede asignar a un clúster.
DistancesToClusterCenter no.n: este valor mide la distancia desde el punto de datos actual hasta el centroide del clúster. Una columna independiente en la salida de cada clúster del modelo entrenado.
Los valores de distancia del clúster se basan en la métrica de distancia seleccionada en la opción Métrica para medir el resultado del clúster. Incluso si realiza un barrido de parámetros en el modelo de agrupación en clústeres, solo se puede aplicar una métrica durante el barrido. Si cambia la métrica, puede obtener valores de distancia diferentes.
Visualización de distancias dentro del clúster
En el conjunto de datos de resultados de la sección anterior, haga clic en la columna de distancias de cada clúster. Studio (clásico) muestra un histograma que visualiza la distribución de distancias para los puntos del clúster.
Por ejemplo, los histogramas siguientes muestran la distribución de distancias de clúster desde el mismo experimento, con cuatro métricas diferentes. Todas las demás configuraciones para el barrido de parámetros eran las mismas. Cambiar la métrica dio lugar a un número diferente de clústeres en un modelo.
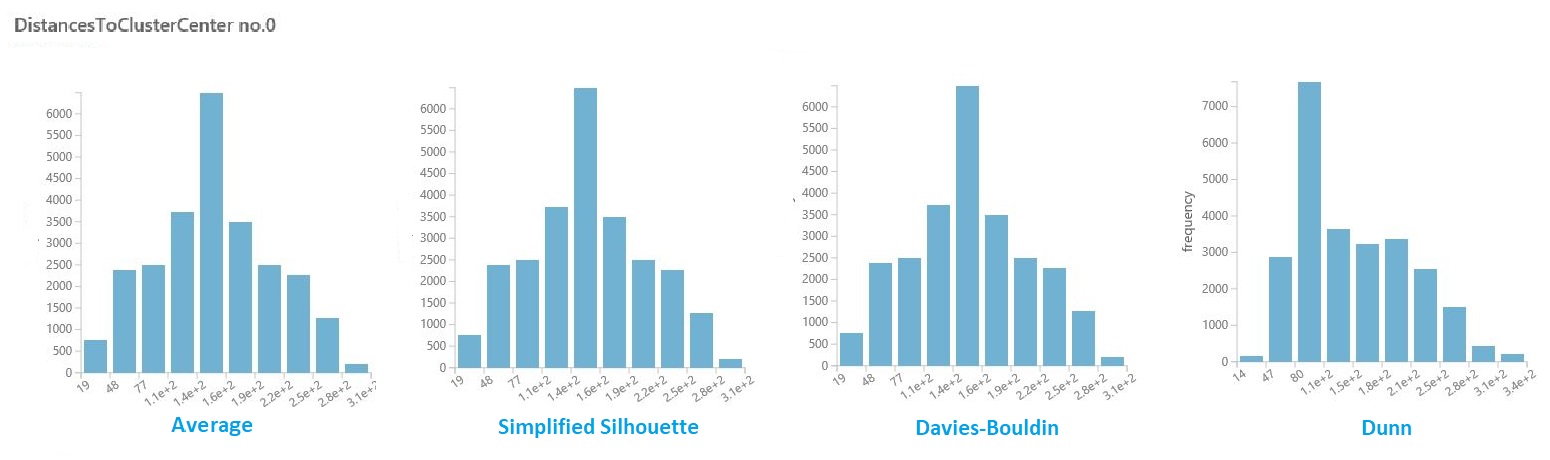
En general, debe elegir una métrica que maximice la distancia entre los puntos de datos de diferentes clases y minimice las distancias dentro de una clase. Puede usar los medios predefinidos y otros valores en el panel Estadísticas para guiarle en esta decisión.
Sugerencia
Puede extraer medios y otros valores usados en visualizaciones mediante el módulo de PowerShell para Machine Learning.
O bien, use el módulo Ejecutar script de R para calcular una matriz de distancia personalizada.
Sugerencias para generar el mejor modelo de agrupación en clústeres
Se sabe que el proceso de propagación usado durante la agrupación en clústeres puede afectar significativamente al modelo. La propagación significa la colocación inicial de puntos en centroides potentes.
Por ejemplo, si el conjunto de datos contiene muchos valores atípicos y se elige un valor atípico para inicializar los clústeres, ningún otro punto de datos se ajustaría bien con ese clúster y el clúster podría ser un singleton: es decir, un clúster con un solo punto.
Hay varias maneras de evitar este problema:
Use un barrido de parámetros para cambiar el número de centroides y probar varios valores de inicialización.
Cree varios modelos, variando la métrica o la iteración más.
Use un método como PCA para buscar variables que tengan un efecto perjudicial en la agrupación en clústeres. Consulte el ejemplo Buscar empresas similares para ver una demostración de esta técnica.
En general, con los modelos de agrupación en clústeres, es posible que cualquier configuración determinada dé lugar a un conjunto de clústeres optimizado localmente. En otras palabras, el conjunto de clústeres devueltos por el modelo solo se adapta a los puntos de datos actuales y no es generalizable para otros datos. Si usa una configuración inicial diferente, el método k-means puede encontrar una configuración diferente y quizás superior.
Importante
Se recomienda experimentar siempre con los parámetros, crear varios modelos y comparar los modelos resultantes.
Ejemplos
Para obtener ejemplos de cómo se usa la agrupación en clústeres K-means en Machine Learning, consulte estos experimentos en la Galería de Azure AI:
Datos de iris de grupo: compara los resultados de la agrupación en clústeres K-Means y la regresión logística multiclase para una tarea de clasificación.
Ejemplo de cuantificación de color: compila varios modelos K-means con diferentes parámetros para encontrar la compresión óptima de la imagen.
Agrupación en clústeres: empresas similares: varía el número de centroides para encontrar grupos de empresas similares en el S&P500.
Notas técnicas
Con un número específico de clústeres (K) para buscar un conjunto de puntos de datos de dimensión D con N puntos de datos, el método k-means genera los clústeres como sigue:
El módulo inicializa una matriz K-by-D con los centroides finales que definen los clústeres K encontrados.
De forma predeterminada, el módulo asigna los primeros puntos de datos K para los clústeres K .
A partir de un conjunto inicial de K centroides, el método usa el algoritmo de Lloyd para refinar de manera iterativa las ubicaciones de los centroides.
El algoritmo termina cuando los centroides se estabilizan o cuando un número especificado de iteraciones se completa.
Una métrica similar (de forma predeterminada, la distancia euclidiana) se usa para asignar cada punto de datos al clúster que tiene el centroide más cercano.
Advertencia
- Si pasa un intervalo de parámetros a Entrenar modelo de agrupación en clústeres, solo usa el primer valor de la lista de intervalos de parámetros.
- Si pasa un único conjunto de valores de parámetro al módulo Agrupación en clústeres de barrido , cuando espera un intervalo de valores para cada parámetro, omite los valores y usa los valores predeterminados para el aprendiz.
- Si selecciona la opción Parameter Range (Intervalo de parámetros) y especifica un valor único para algún parámetro, ese valor único que haya especificado se utilizará en todo el barrido, incluso si otros parámetros cambian en un intervalo de valores.
Parámetros del módulo
| Nombre | Intervalo | Tipo | Valor predeterminado | Descripción |
|---|---|---|---|---|
| Número de centroides | >=2 | Entero | 2 | Número de centroides |
| Métrica | Lista (subconjunto) | Métrica | Euclidiana | Métrica seleccionada |
| Inicialización | List | Método de inicialización del centroide | K-means++ | Algoritmo de inicialización |
| Iteraciones | >=1 | Entero | 100 | Número de iteraciones |
Salidas
| Nombre | Tipo | Descripción |
|---|---|---|
| Modelo no entrenado | Interfaz ICluster | Modelo de agrupación en clústeres k-means no entrenado |
Excepciones
Para obtener una lista de todas las excepciones, consulte Códigos de error del módulo machine Learning.
| Excepción | Descripción |
|---|---|
| Error 0003 | Se produce una excepción si una o varias de las entradas son NULL o están vacías. |
Consulte también
Clustering
Assign Data to Clusters (asignar datos a los clústeres)
Entrenamiento del modelo de agrupación en clústeres
Agrupación en clústeres de barrido