Tutorial 1: Predicción del riesgo crediticio en Machine Learning Studio (clásico)
SE APLICA A: Estudio de Machine Learning (clásico)
Estudio de Machine Learning (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este tutorial se explica con detalle el proceso de desarrollo de una solución de análisis predictivo. Va a desarrollar un modelo sencillo en Machine Learning Studio (clásico). Después puede implementar el modelo como un servicio web de Machine Learning. Este modelo implementado puede hacer predicciones con datos nuevos. Este tutorial es el primero de una serie de tres partes.
Suponga que necesita predecir el riesgo de crédito de un individuo en función de la información que se proporcionó en una solicitud de crédito.
La evaluación de riesgos crediticios es un problema complejo, pero en este tutorial se simplificará un poco. Se utilizará como ejemplo de cómo puede crear una solución de análisis predictivo con Machine Learning Studio (clásico). En esta solución se usará Machine Learning Studio (clásico) y un servicio web Machine Learning.
En este tutorial de tres partes, vamos a comenzar con los datos de riesgo crediticio disponibles públicamente. Después, desarrollaremos y entrenaremos un modelo predictivo. Finalmente, vamos a implementar el modelo como servicio web.
En esta parte del tutorial, se va a ver lo siguiente:
- Creación de un área de trabajo de Machine Learning Studio (clásico)
- Carga de datos existentes
- Creación de un experimento
Después, puede usar este experimento para entrenar modelos en la parte 2 y, finalmente, implementarlos en la parte 3.
Requisitos previos
En este tutorial, se presupone que usó Machine Learning Studio (clásico) con anterioridad al menos una vez y que tiene ciertos conocimientos sobre los conceptos de aprendizaje automático. Pero no se asume de que sea un experto.
Si nunca ha utilizado Machine Learning Studio (clásico) , sería conveniente que realizara primero el inicio rápido Creación del primer experimento de ciencia de datos en Machine Learning Studio (clásico). Este inicio rápido lo guiará por primera vez por Machine Learning Studio (clásico). Aquí se muestran los conceptos básicos de cómo arrastrar y colocar módulos en el experimento, conectarlos, ejecutar el experimento y examinar los resultados.
Sugerencia
Puede encontrar una copia de trabajo del experimento que se ha desarrollado en este tutorial en Azure AI Gallery. Vaya Tutorial: predicción de riesgos de crédito y haga clic en Abrir en Studio para descargar una copia del experimento en el área de trabajo de Machine Learning Studio (clásico).
Creación de un área de trabajo de Machine Learning Studio (clásico)
Para usar Machine Learning Studio (clásico), debe tener un área de trabajo de Machine Learning Studio (clásico). Esta área de trabajo contiene las herramientas que necesita para crear, administrar y publicar experimentos.
Para crear un área de trabajo, consulte Creación y uso compartido de un área de trabajo de Machine Learning Studio (clásico).
Una vez haya creado el área de trabajo, abra Machine Learning Studio (clásico) (https://studio.azureml.net/Home). Si tiene más de un área de trabajo, puede seleccionar la que desee en la barra de herramientas de la esquina superior derecha de la ventana.
Sugerencia
Si es el propietario del área de trabajo, puede compartir los experimentos en los que esté trabajando invitando a otros al área. Para ello, en Machine Learning Studio (clásico), vaya a la página SETTINGS (CONFIGURACIÓN). Solo necesita la cuenta Microsoft o la cuenta de organización de cada usuario.
En la página CONFIGURACIÓN, haga clic en USUARIOS y, después, haga clic en INVITE MORE USERS (INVITAR A MÁS USUARIOS) en la parte inferior de la ventana.
Carga de datos existentes
Para desarrollar un modelo de predicción de riesgo de crédito, se necesitan datos para entrenar y probar el modelo. Para este tutorial, se usará el conjunto de datos "UCI Statlog (German Credit Data)" del repositorio de Machine Learning de UC Irvine. Puede encontrarlo aquí:
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Usaremos el archivo llamado german.data. Descargue este archivo en la unidad de disco duro local.
El conjunto de datos german.data contiene filas de 20 variables para 1000 solicitantes de crédito. Estas 20 variables representan el conjunto de características (el vector de características) del conjunto de datos que proporciona características de identificación de cada solicitante de crédito. Una columna adicional en cada fila representa el riesgo de crédito calculado del solicitante, donde 700 solicitantes se identificaron como de bajo riesgo y 300 como de alto riesgo.
El sitio web de UCI proporciona una descripción de los atributos del vector de características de estos datos. Entre estos datos figuran la información financiera, el historial de crédito, el estado de empleo y la información personal. A cada solicitante se le ha dado una calificación binaria para indicar si son de riesgo de crédito alto o bajo.
Estos datos se usarán para entrenar un modelo de análisis predictivo. Cuando se haya terminado, el modelo debe poder aceptar un vector de características para una nueva persona y predecir si esta presenta un alto o bajo riesgo de crédito.
Aquí hay un giro interesante.
La descripción del conjunto de datos en el sitio web de UCI menciona lo que cuesta si se clasifica erróneamente el riesgo de crédito de una persona. Si el modelo predice un riesgo de crédito alto para un usuario que realmente tiene un riesgo de crédito bajo, el modelo ha realizado una clasificación incorrecta.
Pero las clasificaciones inversas incorrectas son cinco veces más costosas para la institución financiera: si el modelo predice un riesgo de crédito bajo para un usuario que realmente tiene un riesgo de crédito alto.
Por lo tanto, es deseable entrenar el modelo para que el costo de este último tipo de clasificación incorrecta sea cinco veces mayor que clasificar erróneamente de la otra forma.
Una forma sencilla de hacerlo al entrenar el modelo en el experimento es duplicar (cinco veces) esas entradas que representan a alguien con un riesgo de crédito alto.
A continuación, si el modelo clasifica erróneamente a una persona como de riesgo de crédito bajo cuando realmente tiene un riesgo alto, el modelo realiza esa misma clasificación incorrecta cinco veces, una vez para cada duplicado. Esto aumentará el coste de este error en los resultados del entrenamiento.
Conversión del formato del conjunto de datos
El conjunto de datos original utiliza un formato separado por espacios en blanco. Machine Learning Studio (clásico) funciona mejor con un archivo de valores separados por comas (CSV), así que va a convertir el conjunto de datos y reemplazará los espacios por comas.
Hay muchas maneras de convertir los datos. En primer lugar, es posible convertirlos con el siguiente comando de Windows PowerShell:
cat german.data | %{$_ -replace " ",","} | sc german.csv
También se puede hacer con el comando sed de Unix:
sed 's/ /,/g' german.data > german.csv
En cualquier caso, se creará una versión separada por comas de los datos en un archivo denominado german.csv que se puede usar en el experimento.
Carga del conjunto de datos en Machine Learning Studio (clásico)
Una vez que los datos se han convertido al formato CSV, hay que cargarlos en Machine Learning Studio (clásico).
Abra la página principal de Machine Learning Studio (clásico) (https://studio.azureml.net).
Haga clic en el menú
 de la esquina superior izquierda de la ventana, haga clic en Azure Machine Learning, seleccione Studio e inicie sesión.
de la esquina superior izquierda de la ventana, haga clic en Azure Machine Learning, seleccione Studio e inicie sesión.Haga clic en +NUEVO en la parte inferior de la página.
Seleccione CONJUNTO DE DATOS.
Seleccione DE ARCHIVO LOCAL.
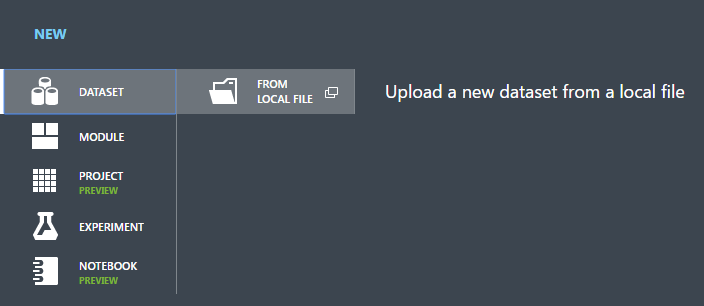
En el diálogo Cargar un nuevo conjunto de datos, haga clic en Examinar y busque el archivo german.csv que ha creado.
Escriba un nombre para el conjunto de datos. En este tutorial, se denominará "UCI German Credit Card Data".
Para el tipo de datos, seleccione Archivo CSV genérico sin encabezado (.nh.csv) .
Agregue una descripción si lo desea.
Haga clic en la marca de verificación Aceptar.
De esta manera los datos se cargan en un módulo de conjunto de datos que se pueden usar en un experimento.
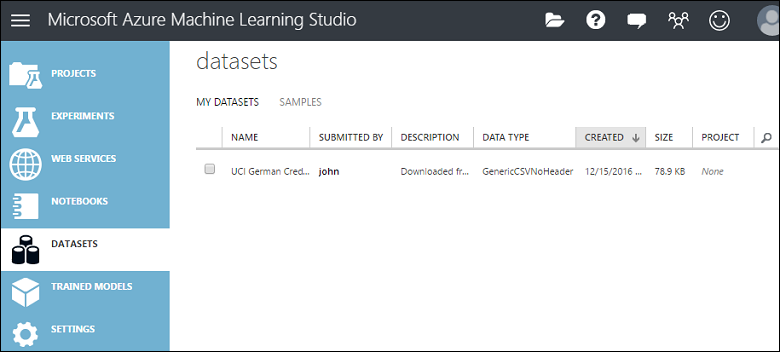
Para administrar los conjuntos de datos que cargó en Studio (clásico), haga clic en la pestaña CONJUNTOS DE DATOS a la izquierda de la ventana de Studio (clásico).
Para más información sobre la importación de diversos tipos de datos a un experimento, consulte Importación de datos de entrenamiento en Machine Learning Studio (clásico).
Creación de un experimento
El siguiente paso de este tutorial es crear un experimento en Machine Learning Studio (clásico) que use el conjunto de datos cargado.
En Studio (clásico), haga clic en +NUEVO en la parte inferior de la ventana.
Seleccione EXPERIMENTO y luego ''Experimento en blanco''.

Seleccione el nombre del experimento predeterminado en la parte superior del lienzo y cámbielo por uno significativo.

Sugerencia
Se recomienda rellenar los campos Resumen y Descripción del experimento en el panel Propiedades. Estas propiedades ofrecen la oportunidad para documentar el experimento para que cualquier persona que lo vea posteriormente entienda sus objetivos y la metodología.

En la paleta de módulos, a la izquierda del lienzo de experimentos, expanda Conjuntos de datos guardados.
Busque el conjunto de datos que ha creado en Mis conjuntos de datos y arrástrelo al lienzo. También puede buscar el conjunto de datos escribiendo su nombre en el cuadro Buscar que está encima de la paleta.
Preparación de los datos
Para ver las primeras 100 filas de datos y alguna información estadística de todo el conjunto de datos: haga clic en el puerto de salida del conjunto de datos (el círculo pequeño de la parte inferior) y seleccione Visualizar.
Dado que el archivo de datos no incluye encabezados de columna, Studio (clásico) ha proporcionado encabezados genéricos (Col1, Col2, etc. ). No es esencial que los encabezados sean perfectos para crear un modelo, pero facilitan el trabajo con los datos del experimento. Además, cuando finalmente se publique este modelo en un servicio web, los encabezados ayudarán al usuario del servicio a identificar las columnas.
Se pueden agregar encabezados de columna mediante el módulo Edit Metadata (Editar metadatos).
Use el módulo Edit Metadata (Editar metadatos) para cambiar los metadatos asociados a un conjunto de datos. En este caso, se usa para proporcionar nombres más descriptivos para los encabezados de las columnas.
Para usar Edit Metadata (Editar metadatos), especifique primero las columnas que desea modificar (en este caso, todas). A continuación, especifique la acción que desea realizar en esas columnas (en este caso, cambiar los encabezados de las columnas).
En la paleta de módulos, escriba "metadatos" en el cuadro Buscar . El módulo Edit Metadata (Editar metadatos) aparece en la lista de módulos.
Haga clic en el módulo Edit Metadata (Editar metadatos), arrástrelo al lienzo y colóquelo bajo el conjunto de datos agregado anteriormente.
Conecte el conjunto de datos al módulo Edit Metadata (Editar metadatos): haga clic en el puerto de salida del conjunto de datos (el círculo pequeño de la parte inferior del conjunto de datos), arrástrelo al puerto de entrada del módulo Edit Metadata (Editar metadatos) (el círculo pequeño de la parte superior del módulo) y luego suelte el botón del ratón. El conjunto de datos y el módulo permanecen conectados aunque se desplace por el lienzo.
El experimento debería tener ahora un aspecto similar al siguiente:
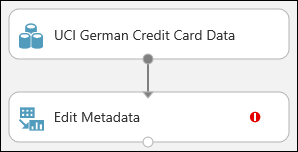
El signo de exclamación rojo indica que no se han configurado aún las propiedades de este módulo. Se hará a continuación.
Sugerencia
Puede agregar un comentario a un módulo; para ello, haga doble clic en el módulo y escriba algún texto. Esto puede ayudarle a ver de un vistazo lo que el módulo hace en el experimento. En este caso, haga doble clic en el módulo Edit Metadata (Editar metadatos) y escriba el comentario "Agregar encabezados de columna". Haga clic en cualquier lugar del lienzo para cerrar el cuadro de texto. Para mostrar el comentario, haga clic en la flecha abajo en el módulo.
Seleccione Edit Metadata (Editar metadatos) y, en el panel Propiedades a la derecha del lienzo, haga clic en Launch column selector (Iniciar el selector de columnas).
En el cuadro de diálogo Seleccionar columnas, elija todas las filas de Columnas disponibles y haga clic en > para moverlas a Columnas seleccionadas. El cuadro de diálogo debe ser similar al siguiente:
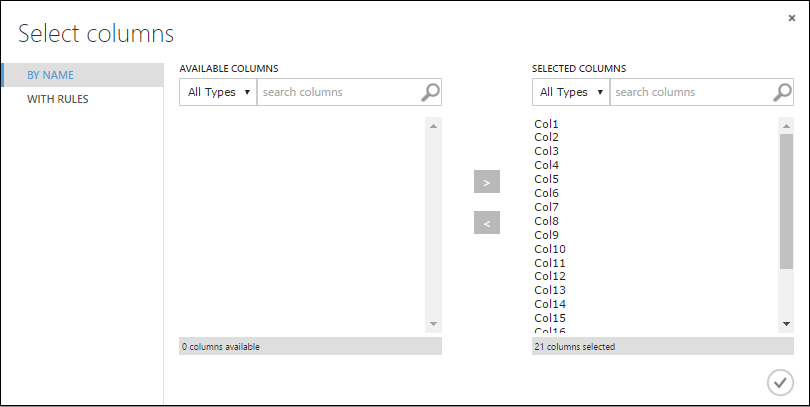
Haga clic en la marca de verificación Aceptar.
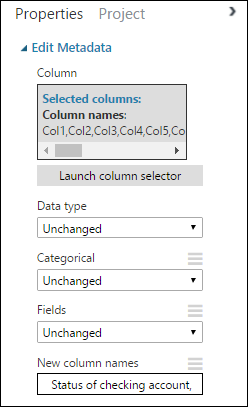
En el panel Propiedades, busque el parámetro Nuevo nombre de columna. En este campo, escriba la lista de nombres de las 21 columnas del conjunto de datos, separadas por comas y en el orden de las columnas. Puede obtener los nombres de las columnas en la documentación del conjunto de datos en el sitio web de UCI o, para mayor comodidad, puede copiar y pegar la siguiente lista:
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskEl panel Propiedades tiene un aspecto similar al siguiente:
Sugerencia
Si desea comprobar los encabezados de columna, ejecute el experimento (haga clic en EJECUTAR debajo del lienzo del experimento). Cuando termine de ejecutarse —aparece una marca de verificación verde en Edit Metadata (Editar metadatos)—, haga clic en el puerto de salida del módulo Edit Metadata (Editar metadatos) y seleccione Visualizar. Puede ver el resultado de cualquier módulo de la misma manera, para visualizar el progreso de los datos a lo largo del experimento.
Creación de conjuntos de datos de entrenamiento y prueba
Se necesitan algunos datos para entrenar el modelo y otros tantos para probarlo. De este modo, en el siguiente paso del experimento, se divide el conjunto de datos en dos conjuntos de datos independientes: uno para el entrenamiento de nuestro modelo y el otro para probarlo.
Para ello, se usa el módulo Split Data (Dividir datos).
Busque el módulo Split Data (Dividir datos), arrástrelo al lienzo y conéctelo al módulo Edit Metadata (Editar metadatos).
De manera predeterminada, la proporción de división es 0,5 y se establece el parámetro División aleatoria . Esto significa que una mitad aleatoria de los datos sale por un puerto del módulo Split Data (Dividir datos) y la otra mitad, por el otro. Puede cambiar estos parámetros, así como el parámetro Valor de inicialización aleatorio, para cambiar la división entre datos de entrenamiento y de prueba. En este ejemplo, se dejan tal cual.
Sugerencia
La propiedad Fraction of rows in the first output dataset (Fracción de filas del primer conjunto de datos de salida) determina la cantidad de datos que salen a través del puerto de salida de la izquierda. Por ejemplo, si establece la proporción en 0,7, el 70 % de los datos sale por el puerto de la izquierda y el 30 % por el puerto de la derecha.
Haga doble clic en el módulo Split Data (Dividir datos) y escriba el comentario "Dividir 50 % de los datos de entrenamiento y pruebas".
Se pueden utilizar las salidas del módulo Split Data (Dividir datos) como se quiera, pero se va a optar por utilizar la salida de la izquierda como datos de entrenamiento y la salida de la derecha como datos de pruebas.
Como se menciona en el paso anterior, el costo de clasificar erróneamente un riesgo de crédito alto como bajo es cinco veces más alto que el costo de clasificar erróneamente un riesgo de crédito bajo como alto. Para tener esto en cuenta, se debe generar un nuevo conjunto de datos que refleje esta función de costo. En el nuevo conjunto de datos, cada ejemplo de alto riesgo se replica cinco veces, mientras que los ejemplos de bajo riesgo no se replican.
Podemos conseguir esta replicación mediante el código R:
Busque el módulo Execute R Script (Ejecutar script R) y arrástrelo al lienzo del experimento.
Conecte el puerto de salida de la izquierda del módulo Split Data(Dividir datos) al primer puerto de entrada ("Dataset1") del módulo Execute R Script (Ejecutar script R).
Haga doble clic en el módulo Execute R Script (Ejecutar script R) y escriba el comentario "Establecer ajuste de costos".
En el panel Propiedades, elimine el texto predeterminado del parámetro Script R y escriba este script:
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")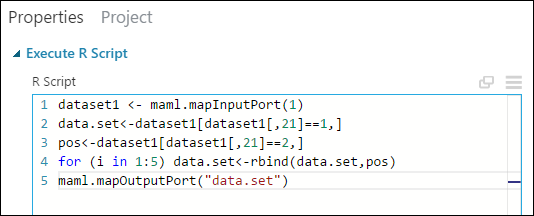
Hay que hacer esta misma operación de replicación para cada salida del módulo Split Data (Dividir datos) para que los datos de entrenamiento y prueba tengan el mismo ajuste con relación al costo. La forma más sencilla de hacerlo consiste en duplicar el módulo Execute R Script (Ejecutar script R) que se acaba de crear y conectarlo al otro puerto de salida del módulo Split Data (Dividir datos).
Haga clic con el botón derecho en el módulo Execute R Script (Ejecutar script R) y seleccione Copy (Copiar).
Haga clic con el botón derecho en el lienzo del experimento y seleccione Pegar.
Arrastre el nuevo módulo a la posición correspondiente y luego conecte el puerto de salida de la derecha del módulo Split Data (Dividir datos) al primer puerto de entrada de este nuevo módulo Execute R Script (Ejecutar script R).
En la parte inferior del lienzo, haga clic en Ejecutar.
Sugerencia
La copia del módulo Ejecutar script R contiene el mismo script que el módulo original. Al copiar y pegar un módulo en el lienzo, la copia retiene todas las propiedades del original.
Nuestro experimento tiene ahora un aspecto similar al siguiente:
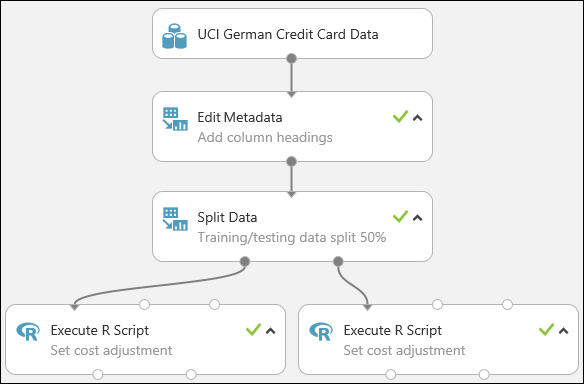
Para obtener más información sobre cómo usar los scripts de R en sus experimentos, consulte Extender el experimento con R.
Limpieza de recursos
Si ya no necesita los recursos que creó en este artículo, elimínelos para evitar incurrir en cualquier cargo. Aprenda a hacerlo en el artículo sobre la Exportación y eliminación de datos de usuario integrados.
Pasos siguientes
En este tutorial ha completado estos pasos:
- Creación de un área de trabajo de Machine Learning Studio (clásico)
- Carga de datos existentes en el área de trabajo
- Creación de un experimento
Ahora está preparado para entrenar y evaluar modelos para estos datos.