Tutorial 2: Entrenamiento de modelos de riesgo crediticio: Machine Learning Studio (clásico)
SE APLICA A: Estudio de Machine Learning (clásico)
Estudio de Machine Learning (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este tutorial se explica con detalle el proceso de desarrollo de una solución de análisis predictivo. Va a desarrollar un modelo sencillo en Machine Learning Studio (clásico). Después puede implementar el modelo como un servicio web de Machine Learning. Este modelo implementado puede hacer predicciones con datos nuevos. Se trata de la segunda parte de un tutorial de tres.
Suponga que necesita predecir el riesgo de crédito de un individuo en función de la información que se proporcionó en una solicitud de crédito.
La evaluación de riesgos crediticios es un problema complejo, pero en este tutorial se simplificará un poco. Se utilizará como ejemplo de cómo puede crear una solución de análisis predictivo con Machine Learning Studio (clásico). En esta solución se usará Machine Learning Studio (clásico) y un servicio web Machine Learning.
En este tutorial de tres partes, vamos a comenzar con los datos de riesgo crediticio disponibles públicamente. Después, desarrollaremos y entrenaremos un modelo predictivo. Finalmente, vamos a implementar el modelo como servicio web.
En la parte uno del tutorial, creó un área de trabajo de Machine Learning Studio (clásico), cargó datos y creó un experimento.
En esta parte del tutorial, se va a ver lo siguiente:
- Entrenamiento de varios modelos
- Puntuación y evaluación de modelos
En la parte tres del tutorial se implementará el modelo como servicio web.
Requisitos previos
Completar la parte uno del tutorial.
Entrenamiento de varios modelos
Una de las ventajas del uso de Machine Learning Studio (clásico) para crear modelos de aprendizaje automático es la posibilidad de probar más de un tipo de modelo a la vez en un solo experimento y comparar los resultados. Este tipo de experimentación ayuda a encontrar la mejor solución al problema.
En el experimento que vamos a crear en este tutorial, crearemos dos tipos diferentes de modelos y después compararemos los resultados de su puntuación para decidir qué algoritmo usar en nuestro experimento final.
Existen varios modelos entre los que se puede elegir. Para ver cuáles están disponibles, expanda el nodo Machine Learning de la paleta de módulos y luego expanda Initialize Model (Inicializar modelo) y los nodos que incluye. Teniendo en cuenta el objetivo de este experimento, seleccione los módulos Two-Class Support Vector Machine (Máquina de vectores de soporte de dos clases, SVM) y Two-Class Boosted Decision Tree (Árbol de decisión promovido por dos clases).
Agregará tanto el módulo Two-Class Boosted Decision Tree (Árbol de decisión promovido por dos clases) como el módulo Two-Class Support Vector Machine (Máquina de vectores dos clases) en este experimento.
Two-Class Boosted Decision Tree (Árbol de decisión ampliado de dos clases).
En primer lugar, configure el modelo del árbol de decisión ampliado.
Busque el módulo Two-Class Boosted Decision Tree (Árbol de decisión promovido por dos clases) en la paleta de módulos y arrástrelo al lienzo.
Busque el módulo Train Model (Entrenar modelo), arrástrelo al lienzo y conecte la salida del módulo Two-Class Boosted Decision Tree (Árbol de decisión ampliados de dos clases) al puerto de entrada izquierdo del módulo Train Model (Entrenar modelo).
El módulo Two-Class Boosted Decision Tree (Árbol de decisión promovido por dos clases) inicializa el modelo genérico, y Entrenar modelo usa los datos de entrenamiento para entrenar el modelo.
Conecte la salida izquierda del módulo Execute R Script (Ejecutar script R) izquierdo al puerto de entrada de la derecha del módulo Train Model (Entrenar modelo) (en este tutorial usó los datos procedentes del lado izquierdo del módulo Split Data [Dividir datos] para el entrenamiento).
Sugerencia
No necesita dos de las entradas y una de las salidas del módulo Execute R Script (Ejecutar script R) para este experimento, así que las puede dejar desconectadas.
Esta parte del experimento tiene ahora un aspecto similar al siguiente:
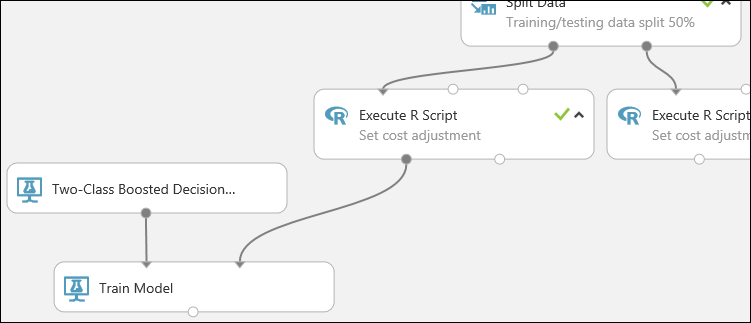
Ahora es necesario indicar al módulo Train Model (Entrenar modelo) que desea que el modelo prediga el valor del riesgo crediticio.
Seleccione el módulo Train Model (Entrenar modelo). En el panel Propiedades, haga clic en Launch column selector (Iniciar el selector de columnas).
En el cuadro de diálogo Select a single column (Seleccionar una sola columna), escriba "riesgo de crédito" en el campo de búsqueda en Columnas disponibles, seleccione "Riesgo de crédito" a continuación y haga clic en el botón de la flecha derecha ( > ) para mover "Riesgo de crédito" a Columnas seleccionadas.
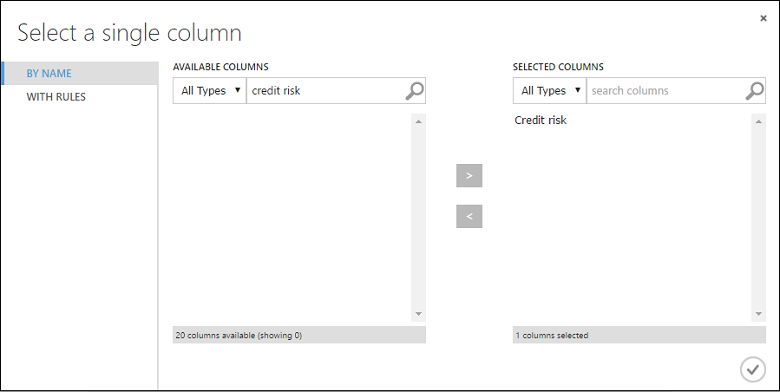
Haga clic en la marca de verificación Aceptar.
Máquina de vectores de soporte de dos clases
A continuación, configure el modelo SVM.
En primer lugar, una breve explicación sobre SVM. Los árboles de decisión ampliados funcionan bien con características de todo tipo. Sin embargo, dado que el módulo SVM genera un clasificador lineal, el modelo que genera tiene el mejor error de prueba cuando todas las características numéricas tienen la misma escala. Para convertir todas las características numéricas a la misma escala, utilice una transformación "Tanh", con el módulo Normalize Data (Normalizar datos). Esto transforma los números en el intervalo [0,1]. El módulo SVM convierte las características de cadena en características categóricas y luego en características binarias 0/1. Por lo tanto, no hace falta transformar manualmente las características de cadena. Además, no queremos transformar la columna Credit Risk (Riesgo crediticio, columna 21): es numérica, pero es el valor sobre cuya predicción estamos entrenando al modelo; por tanto, es necesario dejarla tal cual.
Para configurar el modelo SVM, realice lo siguiente:
Busque el módulo Two-Class Support Vector Machine (Máquina de vectores de soporte de dos clases) en la paleta de módulos y arrástrelo al lienzo.
Haga clic con el botón derecho en el módulo Train Model (Entrenar modelo), seleccione Copy (Copiar), haga clic con el botón derecho en el lienzo y seleccione Paste (Pegar). La copia del módulo Train Model (Entrenar modelo) tiene la misma selección de columnas que el original.
Conecte la salida del módulo Máquina de vectores de soporte de dos clases al puerto de entrada izquierdo del módulo Train Model (Entrenar modelo).
Busque el módulo Normalizar datos y arrástrelo al lienzo.
Conecte la salida de la izquierda del módulo Ejecutar script R de la izquierda a la entrada de este módulo (tenga en cuenta que el puerto de salida de un módulo puede estar conectado a más de un módulo distinto).
Conecte el puerto de salida izquierdo del módulo Normalize Data (Normalizar datos) al puerto de entrada derecho del segundo módulo Entrenar modelo.
Esta parte de nuestro experimento debería tener ahora un aspecto similar al siguiente:
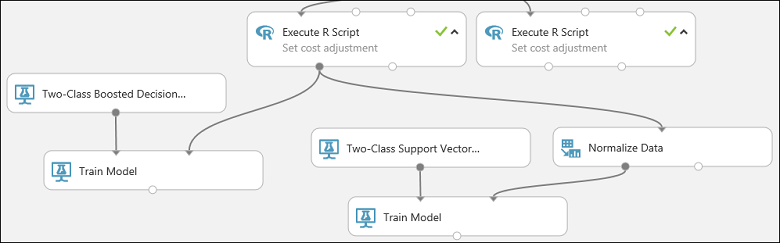
Configure ahora el módulo Normalize Data (Normalizar datos):
Haga clic para seleccionar el módulo Normalize Data (Normalizar datos). En el panel Propiedades, seleccione Tanh para el parámetro Transformation method (Método de transformación).
Haga clic en Launch column selector (Iniciar el selector de columnas), seleccione "No columns" (Sin columnas) en Comenzar con, seleccione Incluir en el primer menú desplegable, Tipo de columna en el segundo y Numérica en el tercero. Esto especifica que todas las columnas numéricas (y solo numéricas) se deben transformar.
Haga clic en el signo más (+) a la derecha de esta fila; de esta forma, se crea una fila de menús desplegables. Seleccione Excluir en la primera lista desplegable y Nombres de columna en la segunda, y escriba "Riesgo de crédito" en el campo de texto. Esto especifica que se debe ignorar la columna Credit Risk (Riesgo crediticio) (debemos hacerlo porque se trata de una columna numérica y, de lo contrario, se transformaría).
Haga clic en la marca de verificación Aceptar.
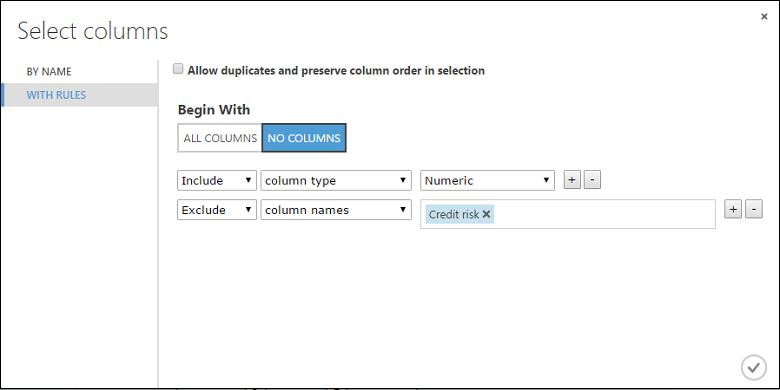
El módulo Normalize Data (Normalizar datos) está configurado ahora para realizar una transformación Tanh en todas las columnas numéricas excepto en la columna de riesgo de crédito.
Puntuación y evaluación de modelos
Se utilizan los datos de prueba que se separaron mediante el módulo Split Data (Dividir datos) para puntuar los modelos entrenados. A continuación podremos comparar los resultados de los dos modelos para ver cuál de ellos generó mejores resultados.
Agregar los módulos Score Model (Puntuar modelo)
Busque el módulo Score Model (Puntuar modelo) y arrástrelo al lienzo.
Conecte el módulo Train Model (Entrenar modelo) que está conectado al módulo Two-Class Boosted Decision Tree (Árbol de decisión ampliado de dos clases) al puerto de entrada izquierdo del módulo Score Model (Puntuar modelo).
Conecte el módulo derecho Ejecutar script R (los datos de prueba) al puerto de entrada derecho del módulo Score Model (Puntuar modelo).
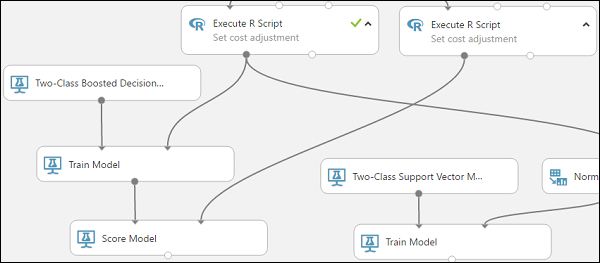
El módulo Score Model (Puntuar modelo) ahora puede utilizar la información de crédito de los datos de prueba, ejecutarla a través del modelo y comparar las predicciones que el modelo genera con la columna de riesgo de crédito real de los datos de prueba.
Copie y pegue el módulo Score Model (Puntuar modelo) para crear una segunda copia.
Conecte la salida del modelo SVM; es decir, el puerto de salida del módulo Train Model (Entrenar modelo) que está conectado al módulo Two-Class Support Vector Machine (Máquina de vectores de soporte de dos clases), al puerto de entrada del segundo módulo Score Model (Puntuar modelo).
En cuanto al modelo SVM, tiene que realizar la misma transformación en los datos de prueba que la que realizó con los datos de entrenamiento. Así pues, copie y pegue el módulo Normalize Data (Normalizar datos) para crear una segunda copia y conéctelo al módulo derecho Ejecutar script R.
Conecte la salida izquierda del segundo módulo Normalize Data (Normalizar datos) al puerto de salida derecho del segundo módulo Score Model (Puntuar modelo).
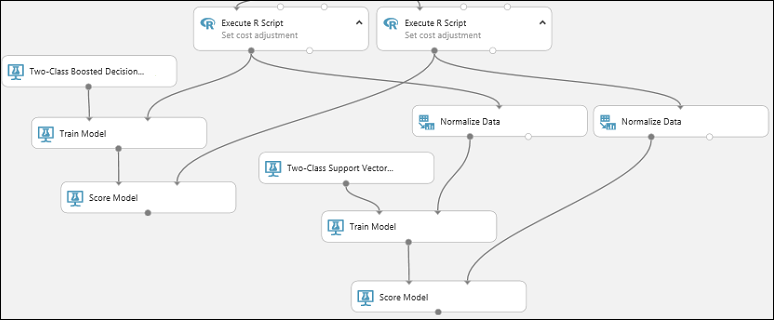
Agregar el módulo Evaluate Model (Evaluar modelo)
Para evaluar los dos resultados de puntuación y compararlos, use un módulo Evaluate Model (Evaluar modelo).
Busque el módulo Evaluate Model (Evaluar modelo) y arrástrelo al lienzo.
Conecte el puerto de salida del módulo Score Model (Puntuar modelo) asociado al modelo del árbol de decisión ampliado al puerto de entrada izquierdo del módulo Evaluate Model (Evaluar modelo).
Conecte el otro módulo Score Model (Puntuar modelo) al puerto de entrada derecho.
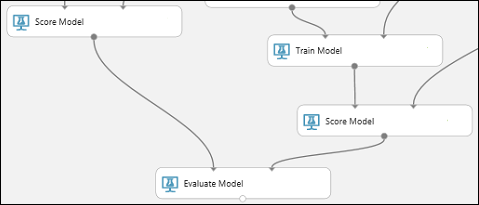
Ejecutar el experimento y comprobar los resultados
Para ejecutar el experimento, haga clic en el botón EJECUTAR bajo el lienzo. Esto puede tardar unos minutos. Aparece un indicador giratorio en cada módulo para indicar que está en ejecución y, cuando el módulo acaba, aparece una marca de verificación de color verde. Cuando todos los módulos tengan una marca de verificación, habrá finalizado la ejecución del experimento.
El experimento debería tener ahora un aspecto similar al siguiente:
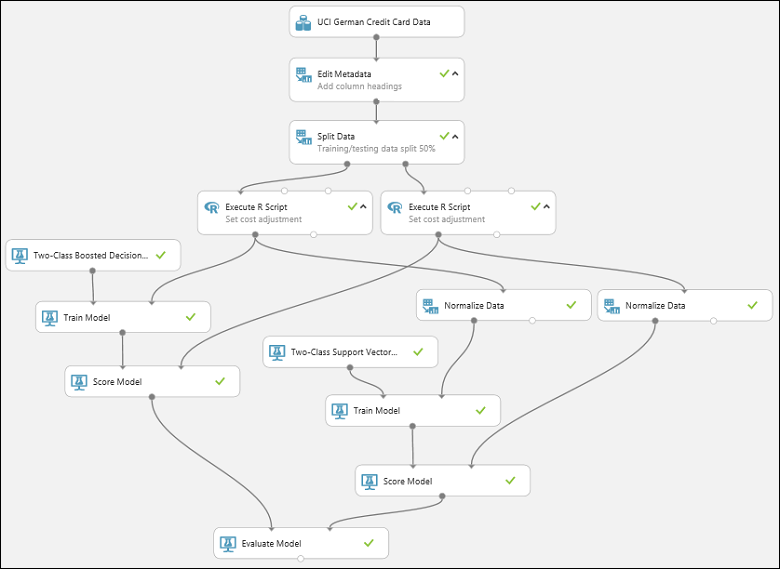
Para comprobar los resultados, haga clic en el puerto de salida del módulo Evaluate Model (Evaluar modelo) y seleccione Visualizar.
El módulo Evaluate Model (Evaluar modelo) produce un par de curvas y métricas que permiten comparar los resultados de los dos modelos de puntuación. Puede ver los resultados como curvas de características operativas del receptor (ROC), curvas de precisión/sensibilidad o curvas de elevación. También se muestran otros datos como la matriz de confusión y los valores del área bajo la curva (AUC) acumulados, entre otras métricas. También puede cambiar el valor del umbral moviendo el control deslizante a la izquierda o a la derecha, y comprobar cómo afecta esta acción al conjunto de métricas.
A la derecha del gráfico, haga clic en Scored dataset (Conjunto de datos puntuados) o en Scored dataset to compare (Conjunto de datos puntuados para comparar) con el fin de resaltar la curva asociada y mostrar debajo las métricas asociadas. En la leyenda de las curvas, "Conjunto de datos puntuados" corresponde al puerto de entrada izquierdo del módulo Evaluate Model (Evaluar modelo); en este caso, se trata del modelo del árbol de decisión ampliado. "Conjunto de datos puntuados para comparar" corresponde al puerto de entrada derecho (el modelo SVM en nuestro caso). Al hacer clic en una de estas etiquetas, la curva del modelo correspondiente se resalta y muestra las métricas correspondientes tal y como se muestra en el gráfico siguiente.

Si examina estos valores, podrá decidir cuál es el modelo que más se acerca a ofrecerle los resultados que busca. Puede volver y repetir el experimento cambiando valores de parámetros en los diferentes modelos.
La ciencia y el arte de interpretar estos resultados y de ajustar el rendimiento del modelo están fuera del ámbito de este tutorial. Para obtener ayuda adicional, puede leer los artículos siguientes:
- Procedimientos para evaluar el rendimiento de un modelo en Machine Learning Studio (clásico)
- Selección de parámetros para optimizar los algoritmos de Machine Learning Studio (clásico)
- Interpretación de los resultados de un modelo en Machine Learning Studio (clásico)
Sugerencia
Cada vez que ejecute el experimento, se guardará un registro de esa iteración en el Historial de ejecuciones. Puede ver estas iteraciones y volver a cualquiera de ellas haciendo clic en VER HISTORIAL DE EJECUCIÓN bajo el lienzo. También puede hacer clic en Prior Run (Ejecución anterior) en el panel Propiedades para volver a la iteración inmediatamente anterior a la que ha abierto.
Puede hacer una copia de cualquier iteración de su experimento si hace clic en GUARDAR COMO bajo el lienzo. Utilice las propiedades Resumen y Descripción para mantener un registro de lo que ha tratado de hacer en las iteraciones del experimento.
Para más información, consulte Administrar iteraciones de experimentos en Machine Learning Studio (clásico).
Limpieza de recursos
Si ya no necesita los recursos que creó en este artículo, elimínelos para evitar incurrir en cualquier cargo. Aprenda a hacerlo en el artículo sobre la Exportación y eliminación de datos de usuario integrados.
Pasos siguientes
En este tutorial ha completado estos pasos:
- Creación de un experimento
- Entrenamiento de varios modelos
- Puntuación y evaluación de modelos
Ahora está listo para implementar modelos para estos datos.