Evaluación del rendimiento de un modelo en Machine Learning Studio (clásico)
SE APLICA A:  Machine Learning Studio (clásico)
Machine Learning Studio (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este artículo puede obtener información sobre las métricas que puede usar para supervisar el rendimiento de un modelo en Machine Learning Studio (clásico). La evaluación del rendimiento de un modelo es una de las fases principales en el proceso de ciencia de datos. Indica el nivel de acierto de las puntuaciones (predicciones) de un conjunto de datos mediante un modelo entrenado. Machine Learning Studio (clásico) admite la evaluación de modelos por medio de dos de sus módulos principales de aprendizaje automático:
Estos módulos permiten ver el rendimiento del modelo como un número de métricas que se usan habitualmente en estadísticas y aprendizaje automático.
Los modelos de evaluación deben tenerse en cuenta junto con:
Se presentan tres escenarios comunes de aprendizaje supervisado:
- regresión
- clasificación binaria
- clasificación multiclase
Evaluación frente a Validación cruzada
La evaluación y la validación cruzada son métodos estándares para medir el rendimiento de un modelo. Ambos generan métricas de evaluación que puede inspeccionar o comparar con las de otros modelos.
El módulo Evaluar modelo espera un conjunto de datos puntuado como entrada (o dos en caso de que quiera comparar el rendimiento de dos modelos distintos). Por lo tanto, debe entrenar el modelo mediante el módulo Entrenar modelo y realizar predicciones sobre algún conjunto de datos con el módulo Puntuar modelo, antes de poder evaluar los resultados. La evaluación se basa en las etiquetas y probabilidades puntuadas junto con las etiquetas verdaderas, las cuales son el resultado del módulo Puntuar modelo.
De forma alternativa, es posible usar la validación cruzada para realizar automáticamente varias operaciones de entrenamiento, puntuación y evaluación (10 subconjuntos) en distintos subconjuntos de los datos de entrada. Los datos de entrada se dividen en 10 partes, donde una se reserva para las pruebas y las otras 9 para el entrenamiento. Este proceso se repite 10 veces y se calcula el promedio de las métricas de evaluación. Esto ayuda a determinar el nivel al que un modelo se podría generalizar para nuevos conjuntos de datos. El módulo Validar modelo de forma cruzada toma un modelo sin entrenar y algunos conjuntos de datos con etiquetas y genera los resultados de la evaluación de cada uno de los 10 subconjuntos, además de los resultados promediados.
En las siguientes secciones, se crearán modelos de clasificación y regresión simples, y se evaluará su rendimiento con los módulos Evaluar modelo y Validar modelo de forma cruzada.
Evaluación de un modelo de regresión
Supongamos que quiere predecir el precio de un automóvil mediante características, como sus dimensiones, caballos de potencia, especificaciones del motor, etc. Se trata de un problema de regresión típico, donde la variable objetivo (price) es un valor numérico continuo. Podemos generar un modelo de regresión lineal que, dados los valores de las características de un automóvil determinado, pueda predecir el precio de ese automóvil. Este modelo de regresión se puede usar para puntuar el mismo conjunto de datos con que se entrenó. Cuando se tienen los precios predichos del automóvil, se puede evaluar el rendimiento con una comparación de cuánto se desvían en promedio las predicciones de los precios reales. Para ilustrar esto, se usa el conjunto de datos Información sobre los precios de los automóviles (datos sin procesar) disponible en la sección Conjuntos de datos almacenados en Machine Learning Studio (clásico).
Creación del experimento
Agregue los módulos siguientes al área de trabajo en Machine Learning Studio (clásico):
- Información sobre los precios de los automóviles (datos sin procesar)
- Regresión lineal
- Train Model (entrenar modelo)
- Score Model (puntuar modelo)
- Evaluación de módulo
Conecte los puertos, tal y como se muestra en la Ilustración 1 y establezca la columna de etiqueta del módulo Entrenar modelo en price.
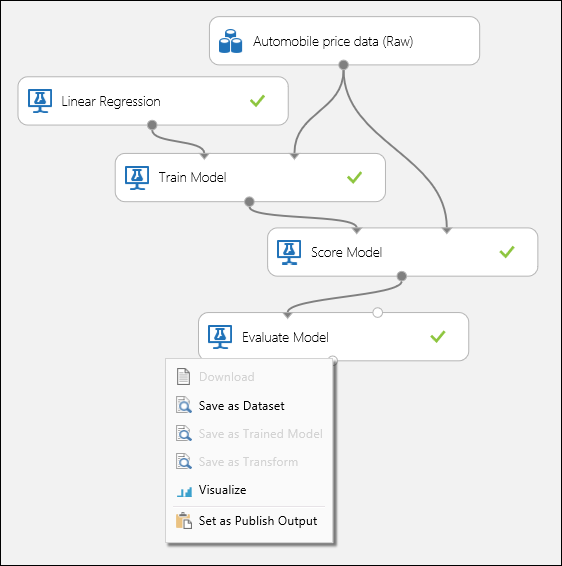
Figura 1. Evaluación de un modelo de regresión.
Inspección de los resultados de la evaluación
Después de ejecutar el experimento, puede hacer clic en el puerto de salida del módulo Evaluar modelo y seleccionar Visualizar para ver los resultados de la evaluación. Las métricas de evaluación disponibles para los modelos de regresión son: Mean Absolute Error, Root Mean Absolute Error, Relative Absolute Error, Relative Squared Error y Coefficient of Determination.
El término "error" representa aquí la diferencia entre el valor predicho y el valor verdadero. Normalmente, se calcula el valor absoluto o el cuadrado de esta diferencia para capturar la magnitud total de errores en todas las instancias, dado que la diferencia entre el valor real y el predicho puede ser negativa en algunos casos. Las métricas de error miden el rendimiento de predicción de un modelo de regresión en cuanto a la desviación media de sus predicciones a partir de los valores reales. Los valores de error más bajos implican que el modelo es más preciso a la hora de realizar predicciones. Una métrica de error general de cero significa que el modelo se ajusta a los datos perfectamente.
El coeficiente de determinación, que también se conoce como R cuadrado, es también una manera estándar de medir cuánto se adapta el modelo a los datos. Se puede interpretar como la proporción de la variación que explica el modelo. Una mayor proporción es mejor en este caso, donde 1 indica un ajuste perfecto.
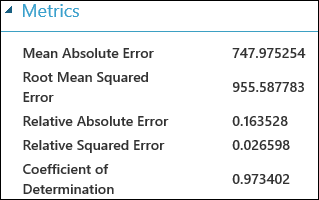
Ilustración 2. Métricas de evaluación de regresión lineal.
Uso de la validación cruzada
Tal como se mencionó anteriormente, puede realizar procesos de entrenamiento, puntuación y evaluación de forma repetida y automática mediante el módulo Validar modelo de forma cruzada. Lo único que necesita en este caso es un conjunto de datos, un modelo sin entrenar y un módulo Validar modelo de forma cruzada (consulte la ilustración siguiente). Debe establecer la columna de etiqueta en price en las propiedades del módulo Cross-Validate Model (Modelo de validación cruzada).
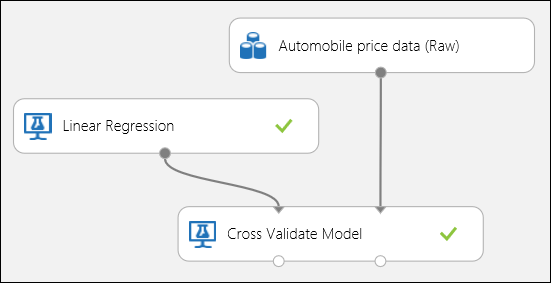
Figura 3. Validación cruzada de un modelo de regresión.
Después de ejecutar el experimento, puede inspeccionar los resultados de la evaluación haciendo clic en el puerto de salida derecho del módulo Validar modelo de forma cruzada. Esto proporcionará una vista detallada de las métricas de cada iteración (subconjunto) y los resultados promediados de cada una de las métricas (Figura 4).
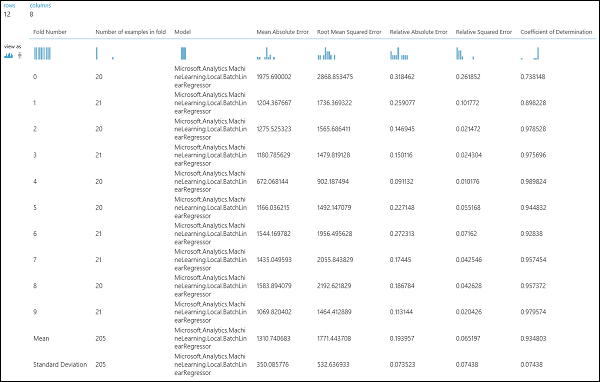
Figura 4. Resultados de la validación cruzada de un modelo de regresión.
Evaluación de un modelo de clasificación binaria
En un escenario de clasificación binaria, la variable objetivo tiene solo dos resultados posibles, por ejemplo: {0, 1} o {false, true}, {negative, positive}. Suponga que tiene un conjunto de datos de empleados adultos con algunas variables demográficas y de empleo, y se le pide que prediga el nivel de ingresos, una variable binaria con los valores {"<=50 K", ">50 K"}. En otras palabras, la clase negativa representa a los empleados que tienen un sueldo menor o igual a 50 000 al año y la clase positiva representa a los demás empleados. Al igual que en el escenario de regresión, se entrenaría un modelo, se puntuarían algunos datos y se evaluarían los resultados. La principal diferencia es la elección de las métricas que Machine Learning Studio (clásico) calcula y genera. Para ilustrar el escenario de predicción del nivel de ingresos, se usará el conjunto de datos Adult para crear un experimento de Studio (clásico) y evaluar el rendimiento de un modelo de regresión logística de dos clases, un clasificador binario que se usa con frecuencia.
Creación del experimento
Agregue los módulos siguientes al área de trabajo en Machine Learning Studio (clásico):
- Conjunto de datos de clasificación binaria de ingresos en el censo de adultos
- Regresión logística de dos clases
- Train Model (entrenar modelo)
- Score Model (puntuar modelo)
- Evaluación de módulo
Conecte los puertos tal y como se muestra en la Ilustración 5 y establezca la columna de etiqueta del módulo Entrenar modelo en income.
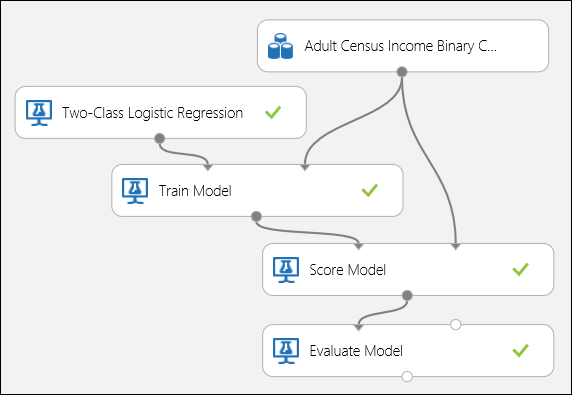
Figura 5. Evaluación de un modelo de clasificación binaria.
Inspección de los resultados de la evaluación
Después de ejecutar el experimento, puede hacer clic en el puerto de salida del módulo Evaluar modelo y seleccionar Visualizar para ver los resultados de la evaluación (ilustración 7). Las métricas de evaluación disponibles para los modelos de clasificación binaria son: Accuracy, Precision, Recall, F1 Score y AUC. Además, el módulo genera una matriz de confusión que muestra el número de positivos verdaderos, falsos negativos, falsos positivos y negativos verdaderos, así como curvas ROC, Precision/Recall y Lift.
La precisión es simplemente la proporción de instancias clasificadas correctamente. Suele ser la primera métrica que se comprueba al evaluar un clasificador. Sin embargo, si los datos de prueba están descompensados (en el caso en que la mayoría de las instancias pertenezcan a una de las clases) o está más interesado en el rendimiento de una de las clases, la precisión no captura realmente la eficacia de un clasificador. En el escenario de clasificación del nivel de ingresos, suponga que está realizando pruebas en datos donde el 99 % de las instancias representan personas con un sueldo menor o igual a 50.000 al año. Es posible conseguir una precisión de 0,99 al predecir la clase "<=50 K" para todas las instancias. En este caso, el clasificador parece hacer un buen trabajo global, pero en realidad no clasifica correctamente ninguno de las personas con ingresos elevados (1 %) correctamente.
Por ese motivo, es útil calcular métricas adicionales que capturen aspectos más específicos de la evaluación. Antes de entrar a los detalles de dichas métricas, es importante comprender la matriz de confusión de una evaluación de clasificación binaria. Las etiquetas de clase en el conjunto de entrenamiento pueden tomar solo dos valores posibles, a los que normalmente podemos referirnos como positivo o negativo. Las instancias positivas y negativas que un clasificador predice correctamente se denominan positivos verdaderos (TP) y negativos verdaderos (TN), respectivamente. De forma similar, las instancias clasificadas incorrectamente se denominan falsos positivos (FP) y falsos negativos (FN). La matriz de confusión es simplemente una tabla que muestra el número de instancias que se encuentran bajo cada una de estas cuatro categorías. Machine Learning Studio (clásico) decide automáticamente cuál de las dos clases del conjunto de datos es la clase positiva. Si las etiquetas de clase son valores booleanos o enteros, se asignan las instancias etiquetadas como "true" o "1" a la clase positiva. Si las etiquetas son cadenas, como en el conjunto de datos de ingresos, las etiquetas se ordenan alfabéticamente y se elige que el primer nivel sea la clase negativa, mientras que el segundo nivel es la clase positiva.
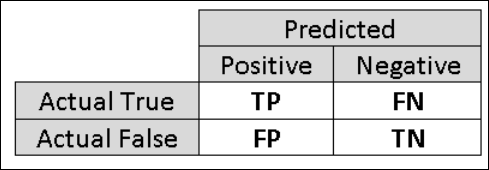
Figura 6. Matriz de confusión de la clasificación binaria.
Volviendo al problema de clasificación de ingresos, existen varias preguntas de evaluación que querríamos preguntar para ayudarnos a comprender el rendimiento del clasificador utilizado. Una pregunta natural es: "De las personas a las que el modelo predijo que > ganaban 50 000 (TP+FP), ¿cuántas se clasificaron correctamente (TP)?" Puede responder esta pregunta observando la precisión del modelo, que es la proporción de positivos que se han clasificado correctamente: TP/(TP+FP). Otra pregunta común es "De todos los empleados con ingresos >50 000 (TP+FN), ¿cuántos predijo el clasificador correctamente (TP)?" Esto es en realidad la recuperación o la tasa de positivos verdaderos: TP/(TP+FN) del clasificador. Observará que hay una evidente compensación entre la precisión y la recuperación. Por ejemplo, dado un conjunto de datos relativamente equilibrado, un clasificador que prediga principalmente instancias positivas tendría una recuperación alta, pero una precisión más baja, ya que muchas de las instancias negativas se clasificarían incorrectamente y se produciría un número mayor de falsos positivos. Para ver un gráfico de cómo varían estas dos métricas, haga clic en la curva de PRECISIÓN/RECUPERACIÓN en la página de salida de resultados de evaluación (parte superior izquierda de la Figura 7).
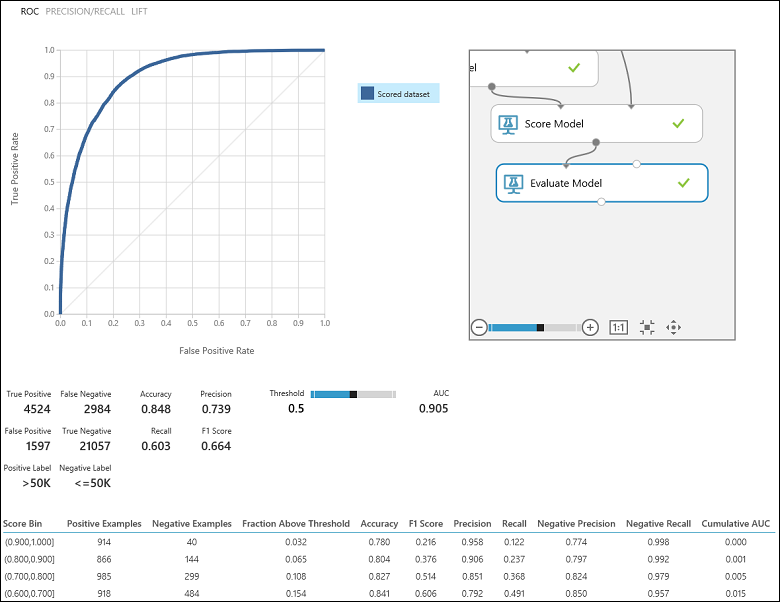
Ilustración 7. Resultados de la evaluación de clasificación binaria.
Otra métrica relacionada que se usa con frecuencia es F1 Score, que tiene en cuenta la precisión y la recuperación. Es la media armónica de estas dos métricas y se calcula como tal: F1 = 2 (precisión x recuperación) / (precisión + recuperación). La puntuación de F1 es una buena forma de resumir la evaluación en un número único, pero siempre es recomendable comprobar la precisión y la recuperación juntas para comprender mejor cómo se comporta un clasificador.
Además, es posible inspeccionar la tasa de positivos verdaderos frente a la de falsos positivos en la curva Característica operativa del receptor (ROC) y el valor del área bajo la curva (AUC) correspondiente. Cuanto más se acerque esta curva a la esquina superior izquierda, mejor será el rendimiento del clasificador (es decir, se maximiza la tasa de positivos verdaderos a la vez que se minimiza la de falsos positivos). Las curvas que están cerca de la diagonal del gráfico son el resultado de los clasificadores que tienden a realizar predicciones que se acercan a una estimación aleatoria.
Uso de la validación cruzada
Como en el ejemplo de regresión, podemos realizar una validación cruzada para entrenar, puntuar y evaluar de forma repetida y automática diferentes subconjuntos de datos. De manera similar, es posible usar el módulo Validar modelo de forma cruzada, un modelo de regresión logística sin entrenar y un conjunto de datos. La columna de etiqueta debe establecerse en income en las propiedades del módulo Cross-Validate Model (Modelo de validación cruzada). Después de ejecutar el experimento y hacer clic en el puerto de la salida derecha del módulo Validar modelo de forma cruzada, es posible ver los valores de métricas de clasificación binaria de cada subconjunto, además de las desviaciones media y estándar de cada uno.
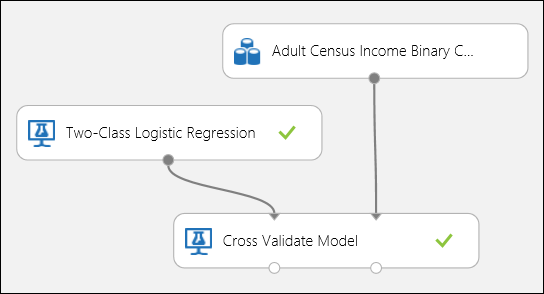
Figura 8. Validación cruzada de un modelo de clasificación binaria.
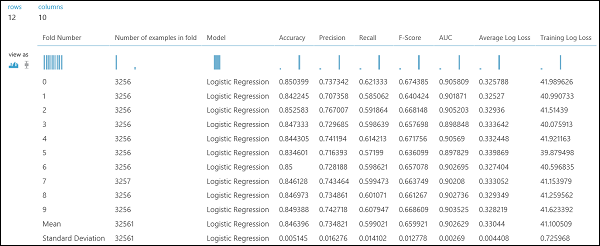
Figura 9. Resultados de la validación cruzada de un clasificador binario.
Evaluación de un modelo de clasificación multiclase
En este experimento, utilizaremos el popular conjunto de datos Iris, que contiene instancias de tres tipos (clases) diferentes de la planta de iris. Hay cuatro valores de características (longitud y ancho del sépalo y del pétalo) para cada instancia. En los experimentos anteriores se entrenaron y probaron los modelos con los mismos conjuntos de datos. Aquí usaremos el módulo Dividir datos para crear dos subconjuntos de los datos, con el fin de entrenar en el primero y puntuar y evaluar en el segundo. El conjunto de datos Iris está disponible públicamente en UCI Machine Learning Repository (Repositorio de aprendizaje automático de UCI) y se puede descargar mediante un módulo Importar datos.
Creación del experimento
Agregue los módulos siguientes al área de trabajo en Machine Learning Studio (clásico):
- Import Data
- Bosque de decisión multiclase
- División de datos
- Train Model (entrenar modelo)
- Score Model (puntuar modelo)
- Evaluación de módulo
Conecte los puertos tal como se muestra a continuación en la Figura 10.
Establezca el índice de la columna de etiqueta del módulo Entrenar modelo en 5. El conjunto de datos no tiene fila de encabezado, pero se sabe que las etiquetas de clase están en la quinta columna.
Haga clic en el módulo Importar datos y establezca la propiedad Origen de datos en la dirección URL web a través de HTTP y la dirección URL en http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Establezca la fracción de instancias que se usará para el entrenamiento en el módulo Dividir datos (por ejemplo, 0,7).
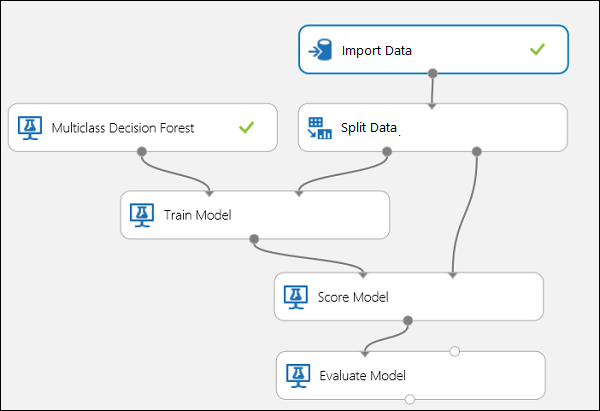
Figura 10. Evaluar un clasificador multiclase
Inspección de los resultados de la evaluación
Ejecute el experimento y haga clic en el puerto de salida de Evaluar modelo. En este caso, los resultados de la evaluación se presentan en forma de una matriz de confusión. La matriz muestra las instancias reales frente a las predichas para las tres clases.
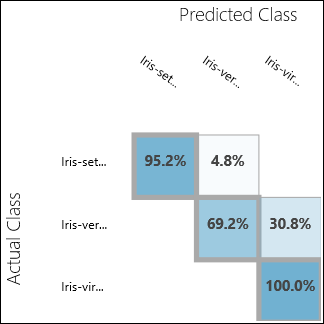
Figura 11. Resultados de la evaluación de clasificación multiclase.
Uso de la validación cruzada
Tal como se mencionó anteriormente, puede realizar procesos de entrenamiento, puntuación y evaluación de forma repetida y automática mediante el módulo Validar modelo de forma cruzada. Necesitaría un conjunto de datos, un modelo sin entrenar y un módulo Validar modelo de forma cruzada (consulte la ilustración siguiente). De nuevo, debe establecer la columna de etiqueta del módulo Evaluar modelo de forma cruzada (en este caso, índice 5 de columna). Después de ejecutar el experimento y hacer clic en el puerto de salida derecho de Validar modelo de forma cruzada, puede inspeccionar los valores de métricas de cada subconjunto, así como las desviaciones media y estándar. Las métricas que se muestran aquí son similares a las descritas en el caso de clasificación binaria. Sin embargo, en la clasificación multiclase, se realiza el cálculo de los positivos y negativos verdaderos, y de los falsos positivos y negativos con un recuento por clase, ya que no existe ninguna clase general positiva o negativa. Por ejemplo, al calcular la precisión o la recuperación de la clase 'Iris-setosa', se supone que se trata de la clase positiva y que todas las demás son negativas.
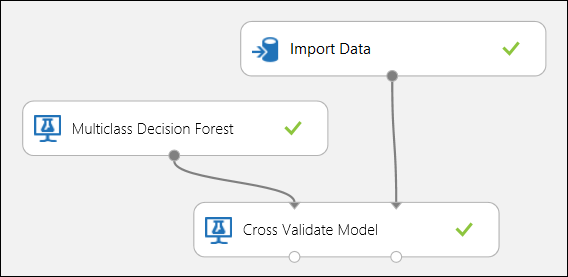
Ilustración 12. Validación cruzada de un modelo de clasificación multiclase.

Ilustración 13. Resultados de una validación cruzada de un modelo de clasificación multiclase.