OneLaken integrointi Azure HDInsightiin
Azure HDInsight on hallittu pilvipohjainen massadata-analytiikan palvelu, joka auttaa organisaatioita käsittelemään suuria määriä tietoja. Tässä opetusohjelmassa kerrotaan, miten voit muodostaa yhteyden OneLakeen Azure HDInsight -klusterin Jupyter-muistikirjalla.
Azure HDInsightin käyttäminen
Yhteyden muodostaminen OneLakeen HDInsight-klusterin Jupyter-muistikirjalla:
Luo HDInsight (HDI) Spark -klusteri. Noudata näitä ohjeita: Määritä klusterit HDInsightissa.
Muista klusterin tiedot tarjotessasi klusterin kirjautumisnimi ja salasana, sillä tarvitset niitä käyttämään klusteria myöhemmin.
Luo käyttäjä, jolle on määritetty hallitut käyttäjätiedot (UAMI): Luo Azure HDInsightille - UAMI ja valitse se käyttäjätietoina Tallennus näytössä.
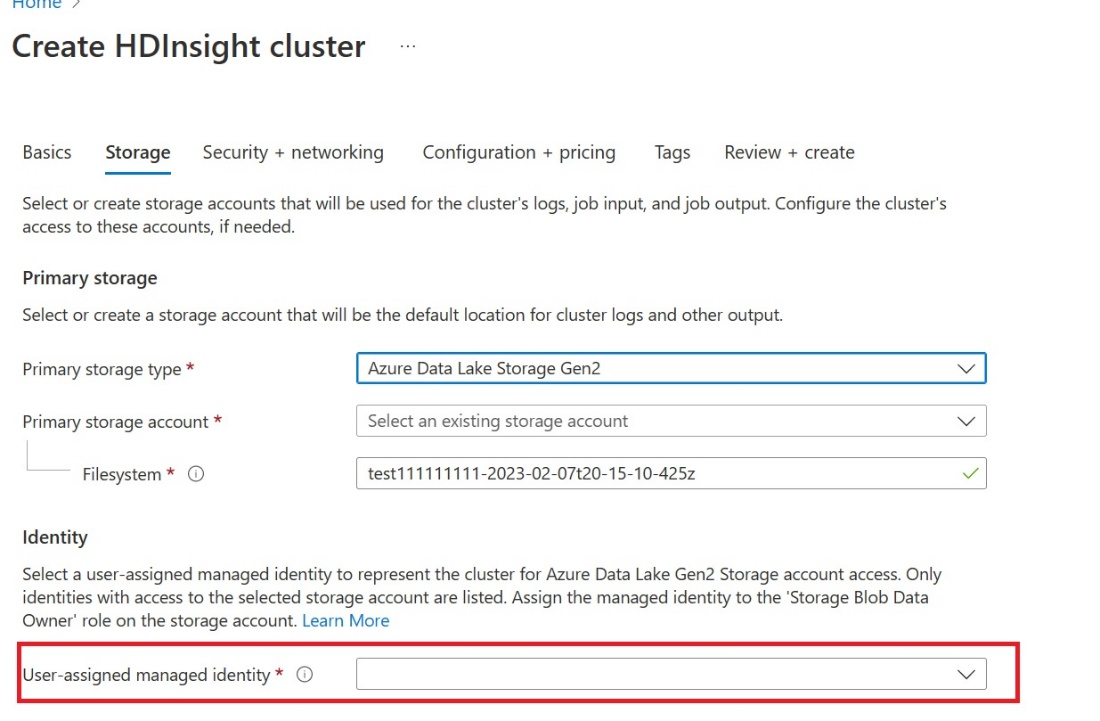
Anna tälle UAMI-käyttöoikeudelle fabric-työtila, joka sisältää kohteesi. Jos haluat lisätietoja siitä, mikä rooli on paras, katso Työtilan roolit.

Siirry Lakehouse-laitteeseesi ja etsi työtilasi nimi ja Lakehouse. Ne löytyvät Lakehousen URL-osoitteesta tai tiedoston Ominaisuudet-ruudusta .
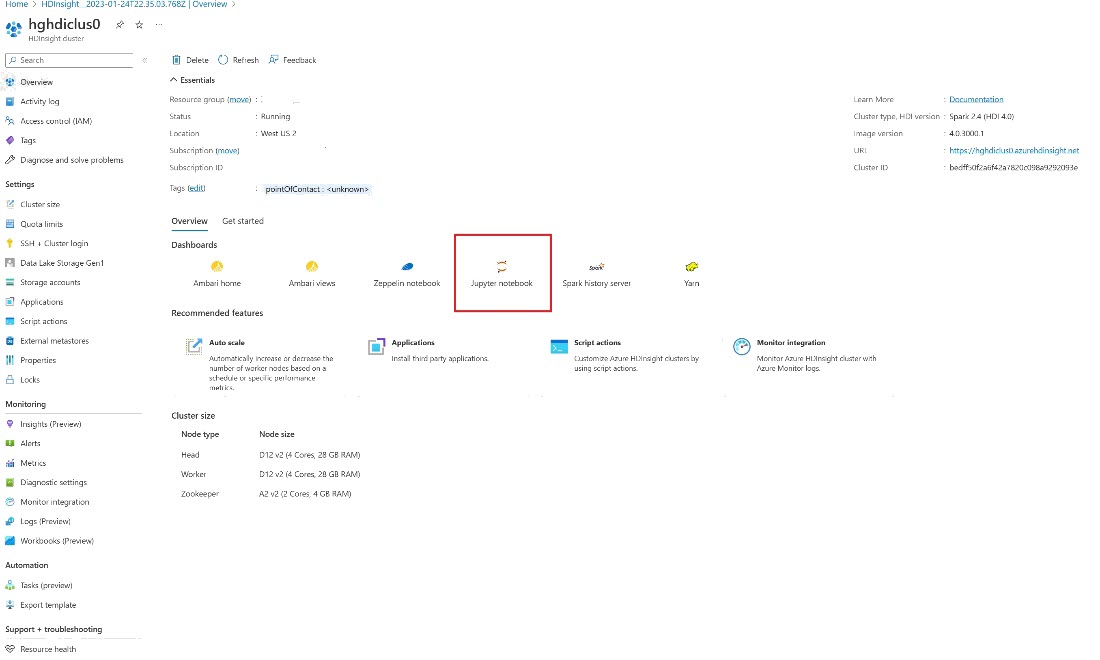
Etsi Azure-portaali klusterisi ja valitse muistikirja.
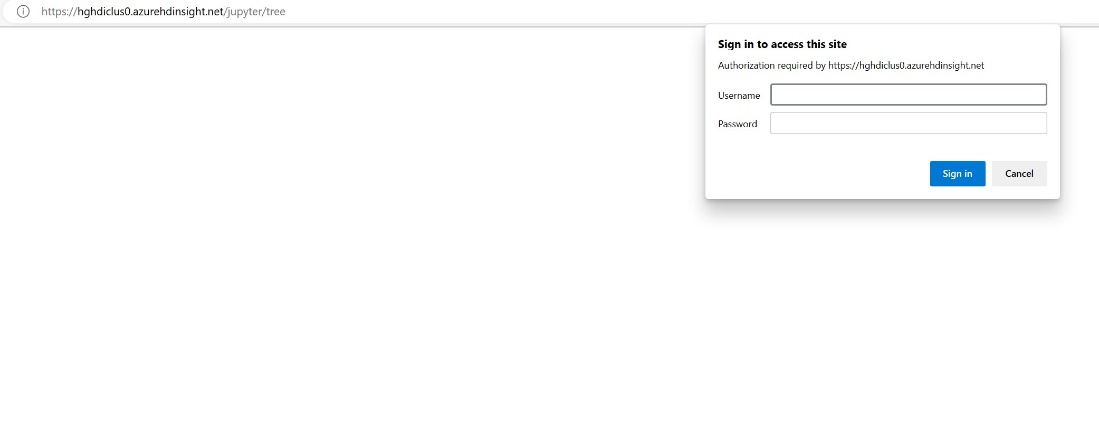
Anna klusterin luomisen aikana antamasi tunnistetiedot.
Luo uusi Spark-muistikirja.
Kopioi työtilan ja Lakehousen nimet muistikirjaasi ja luo OneLake-URL-osoite Lakehouseasi varten. Nyt voit lukea minkä tahansa tiedoston tästä tiedostopolusta.
fp = 'abfss://' + 'Workspace Name' + '@onelake.dfs.fabric.microsoft.com/' + 'Lakehouse Name' + '/Files/' df = spark.read.format("csv").option("header", "true").load(fp + "test1.csv") df.show()Yritä kirjoittaa tietoja Lakehouseen.
writecsvdf = df.write.format("csv").save(fp + "out.csv")Testaa, että tietosi on kirjoitettu onnistuneesti tarkistamalla Lakehouse-tallennustilasi tai lukemalla juuri ladattu tiedostosi.




Voit nyt lukea ja kirjoittaa tietoja OneLakessa käyttämällä Jupyter-muistikirjaasi HDI Spark -klusterissa.
Liittyvä sisältö
Palaute
Tulossa pian: Vuoden 2024 aikana poistamme asteittain GitHub Issuesin käytöstä sisällön palautemekanismina ja korvaamme sen uudella palautejärjestelmällä. Lisätietoja on täällä: https://aka.ms/ContentUserFeedback.
Lähetä ja näytä palaute kohteelle