Résumé des documents basé sur une requête
Ce guide montre comment effectuer le résumé des documents à l’aide du modèle Azure OpenAI GPT-3. Il décrit les concepts liés au processus de résumé des documents, les approches du processus et les recommandations sur le modèle à utiliser pour des cas d’usage spécifiques. Enfin, il présente deux cas d’usage, ainsi que des exemples d’extraits de code, pour vous aider à comprendre les concepts clés.
Architecture
Le diagramme suivant montre comment une requête utilisateur extrait les données pertinentes. L’outil de synthèse utilise GPT-3 pour générer un résumé du texte du document le plus pertinent. Dans cette architecture, le point de terminaison GPT-3 est utilisé pour résumer le texte.

Téléchargez un fichier PowerPoint de cette architecture.
Workflow
Ce flux de travail se produit quasiment en temps réel.
- Un utilisateur envoie une requête. Par exemple, un employé d’une entreprise de fabrication recherche des informations spécifiques sur le composant d’une machine sur le portail de l’entreprise. La requête est d’abord traitée par un module de reconnaissance d’intention, comme la Compréhension du langage courant. Les entités ou concepts pertinents dans la requête utilisateur sont utilisés pour sélectionner et présenter un sous-ensemble de documents à partir d’un base de connaissances remplie hors connexion (dans ce cas, la base de données de la base de connaissances de l’entreprise). La sortie est injectée dans un moteur de recherche et d’analyse telle qu’Azure Elastic Search, qui filtre les documents pertinents pour renvoyer un ensemble de centaines de documents, en lieu et place de milliers voire de dizaines de milliers de documents.
- La requête utilisateur est appliquée à nouveau sur un point de terminaison de recherche tel que Recherche cognitive Azure pour classer l’ensemble de documents récupéré par ordre de pertinence (classement des pages). Le document le mieux classé est sélectionné.
- Le document sélectionné est analysé pour détecter des phrases pertinentes. Ce processus d’analyse utilise une méthode grossière, comme l’extraction de toutes les phrases qui contiennent la requête utilisateur, ou une méthode plus sophistiquée, comme les incorporations GPT-3, pour trouver les éléments sémantiquement similaires dans le document.
- Une fois le texte approprié extrait, le point de terminaison d’achèvement GPT-3 avec l’outil de synthèse résume le contenu extrait. Dans cet exemple, le résumé des détails importants sur le composant spécifié par l’employé dans la requête est retourné.
Cet article se concentre sur le composant d’outil de synthèse de l’architecture.
Détails du scénario
Les entreprises créent et gèrent fréquemment une base de connaissances sur les processus métier, les clients, les produits et les informations. Toutefois, le retour de contenu pertinent sur la base d’une requête utilisateur d’un jeu de données volumineux est souvent difficile. L’utilisateur peut interroger le base de connaissances et trouver un document applicable à l’aide de méthodes telles que le classement des pages, mais la recherche d’informations pertinentes plus en profondeur dans le document devient généralement une tâche manuelle qui prend du temps. Toutefois, avec les récentes avancées en matière de modèles de transformateur de base comme celui développé par OpenAI, le mécanisme de requête a été affiné par des méthodes de recherche sémantique qui utilisent des informations d’encodage telles que les incorporations pour trouver les informations pertinentes. Ces développements permettent de résumer le contenu et de le présenter à l’utilisateur de manière concise et succincte.
Le résumé des documents est le processus de création de résumés à partir de volumes de données importants tout en garantissant des éléments d’information et une valeur de contenu significatifs. Cet article montre comment utiliser les fonctionnalités Azure OpenAI Service GPT-3 pour votre cas d’usage spécifique. GPT-3 est un outil puissant que vous pouvez utiliser pour toute une gamme de tâches de traitement du langage naturel, notamment la traduction linguistique, les chatbots, la synthèse de texte et la création de contenu. Les méthodes et l’architecture décrites ici sont personnalisables et peuvent être appliquées à de nombreux jeux de données.
Cas d’usage potentiels
Le résumé des documents s’applique à tout domaine d’organisation qui nécessite que les utilisateurs recherchent de grandes quantités de données de référence et génèrent un résumé qui décrit les informations pertinentes de manière concise. Les domaines courants incluent les organisations juridiques et financières, les organismes de presse, les établissements de soins de santé, ainsi que les instituts universitaires. Les cas d’usage potentiels de la synthèse sont les suivants :
- Générer des résumés pour mettre en évidence des informations clés sur les actualités, les rapports financiers, etc.
- Créer une référence rapide pour étayer un argument, par exemple, dans le cadre d’une procédure judiciaire.
- Fournir un contexte pour une thèse, comme dans un cadre universitaire.
- Rédiger un avis littéraire.
- Annoter une bibliographie.
Voici quelques avantages de l’utilisation d’un service de résumé pour les cas d’usage :
- Réduction du temps de lecture.
- Amélioration de l’efficacité de la recherche de volumes importants de données disparates.
- Réduction du risque de biais des techniques de résumé humaines. (Cet avantage dépend de l’ampleur des données d’entraînement non biaisées.)
- Fourniture d’une analyse plus approfondie aux employés et aux utilisateurs.
Apprentissage dans le contexte
Azure OpenAI Service utilise un modèle d’achèvement génératif. Le modèle utilise des instructions en langage naturel pour identifier la tâche demandée et la compétence requise. Ce processus est appelé « ingénierie d’invite ». Lorsque vous utilisez cette approche, la première partie de l’invite inclut des instructions en langage naturel ou des exemples de la tâche souhaitée. Le modèle réalise la tâche en prédisant le texte suivant le plus probable. Cette technique est appelée « apprentissage dans le contexte ».
Grâce à l’apprentissage dans le contexte, les modèles de langage peuvent apprendre des tâches à partir de quelques exemples seulement. Le modèle de langage est fourni avec une invite qui contient une liste de paires entrée-sortie qui illustrent une tâche, puis avec une entrée de test. Le modèle effectue une prédiction en conditionnant l’invite et en prédisant les jetons suivants.
Il existe trois approches principales dans le cadre de l’apprentissage dans le contexte : l’apprentissage zéro coup, l’apprentissage en quelques coups et les méthodes d’ajustement qui modifient et améliorent la sortie. Ces approches varient en fonction de la quantité de données spécifiques à la tâche fournies au modèle.
Zéro coup : dans cette approche, aucun exemple n’est fourni au modèle. Seule la requête de tâche est fournie en tant qu’entrée. Dans l’apprentissage zéro coup, le modèle dépend de concepts précédemment entraînés. Il répond uniquement en fonction des données avec lesquelles il est entraîné. Il ne comprend pas nécessairement la signification sémantique, mais il a une compréhension statistique basée sur tout ce qu’il a appris d’Internet sur la suite qui devrait être générée. Le modèle tente de lier la tâche donnée à des catégories existantes qu’il a déjà apprises et répond en conséquence.
Quelques coups : dans cette approche, plusieurs exemples qui illustrent le format et le contenu de réponse attendus sont inclus dans l’invite d’appel. Le modèle est fourni avec un jeu de données d’entraînement très restreint pour guider ses prédictions. L’apprentissage à l’aide d’un petit ensemble d’exemples permet au modèle de généraliser et de comprendre des tâches non liées, mais auparavant invisibles. La création d’exemples de quelques coups peut être difficile, car vous devez articuler avec précision la tâche que le modèle doit effectuer. L’un des problèmes fréquemment constaté est que les modèles sont sensibles au style d’écriture utilisé dans les exemples d’entraînement, en particulier les petits modèles.
Ajustement : il s’agit d’un processus d’adaptation des modèles à vos propres jeux de données. Dans cette étape de personnalisation, vous pouvez améliorer le processus en :
- Incluant un plus grand jeu de données (au moins 500 exemples).
- Utilisant des techniques d’optimisation traditionnelles avec rétropropagation pour réajuster les pondérations du modèle. Ces techniques permettent d’obtenir des résultats de meilleure qualité qu’avec l’approche zéro coup ou en quelques coups.
- Améliorant l’approche en quelques coups en entraînant les pondérations du modèle avec des invites et une structure spécifiques. Cette technique vous permet d’obtenir de meilleurs résultats sur un plus grand nombre de tâches sans avoir à fournir d’exemples dans l’invite. Il en résulte moins de texte envoyé et moins de jetons.
Quand vous créez une solution GPT-3, l’effort principal réside dans la conception et le contenu de l’invite d’apprentissage.
Demander à l’ingénierie
L’ingénierie d’invite est une discipline de traitement du langage naturel qui consiste à découvrir les entrées qui produisent des sorties souhaitables ou utiles. Quand un utilisateur invite le système, la façon dont le contenu est exprimé peut modifier considérablement la sortie. La conception d’invite est le processus le plus important pour garantir que le modèle GPT-3 fournit une réponse souhaitable et contextuelle.
L’architecture décrite dans cet article utilise le point de terminaison d’achèvement pour le résumé. Le point de terminaison est une API Azure AI services qui accepte une invite partielle ou un contexte en entrée et renvoie une ou plusieurs sorties qui continuent ou complètent le texte d’entrée. Un utilisateur fournit du texte d’entrée en tant qu’invite, et le modèle génère du texte qui tente de correspondre au contexte ou au modèle fourni. La conception d’invite dépend fortement de la tâche et des données concernées. L’incorporation de l’ingénierie d’invite dans un jeu de données d’ajustement et l’examen de ce qui convient le mieux avant d’utiliser le système en production nécessitent beaucoup de temps et d’efforts.
Conception d’invite
Les modèles GPT-3 peuvent effectuer plusieurs tâches. Vous devez donc être explicite dans les objectifs de la conception. Les modèles estiment la sortie souhaitée en fonction de l’invite fournie.
Par exemple, si vous saisissez les mots « Donne-moi une liste de races de chats », le modèle ne suppose pas automatiquement que vous demandez une liste de races de chats. Vous pourriez demander au modèle de continuer une conversation dont les premiers mots sont « Donne-moi une liste de races de chats » et les suivants sont « et je vous dirai ceux que j’aime ». Si le modèle suppose uniquement que vous vouliez une liste de chats, il ne serait pas aussi efficace pour la création de contenu, la classification ou d’autres tâches.
Comme décrit dans l’article Découvrir comment générer ou manipuler du texte, il existe trois instructions de base pour créer des invites :
- Montrez et dites. Améliorez la clarté de ce que vous voulez en fournissant des instructions, des exemples ou une combinaison des deux. Si vous souhaitez que le modèle classe une liste d’éléments dans l’ordre alphabétique ou qu’il classe un paragraphe par sentiment, indiquez-lui que c’est ce que vous voulez.
- Fournissez des données de qualité. Si vous créez un classifieur ou si vous souhaitez qu’un modèle suive un modèle, veillez à fournir suffisamment d’exemples. Vous devez également vérifier vos exemples. Le modèle peut généralement reconnaître les fautes d’orthographe et retourner une réponse, mais il peut supposer que les fautes d’orthographe sont intentionnelles, ce qui peut affecter la réponse.
- Enregistrer vos paramètres. Les paramètres
temperatureettop_pdéterminent la façon dont le degré de déterminisme avec lequel le modèle génère une réponse. Si vous lui demandez une réponse qui n’a qu’une seule réponse correcte, configurez ces paramètres à un niveau inférieur. Si vous souhaitez obtenir des réponses plus diversifiées, vous pouvez configurer ces paramètres à un niveau supérieur. Une erreur courante consiste à supposer que ces paramètres sont des contrôles « d’intelligence » ou de « créativité ».
Autres solutions
La compréhension du langage courant Azure est une solution alternative à l’outil de synthèse utilisé ici. L’objectif principal de la compréhension du langage courant est de créer un modèle qui prédit l’intention globale d’un énoncé entrant, en extrait les informations utiles et produit une réponse qui correspond au sujet. Ce principe est utile dans les applications de chatbot quand il peut faire référence à un base de connaissances existante pour trouver la suggestion qui correspond le mieux à l’énoncé entrant. Toutefois, cela n’aide pas beaucoup lorsque le texte d’entrée ne nécessite pas de réponse. L’intention de cette architecture est de générer un bref résumé d’un long contenu textuel. L’essence du contenu est décrite de manière concise et toutes les informations importantes sont représentées.
Exemples de scénarios
Cas d’usage : résumé de documents juridiques
Dans ce cas d’usage, une collection de projets de loi adoptés par le Congrès est résumée. Le résumé est affiné pour le rapprocher d’un résumé généré par l’homme, appelé résumé de réalité de terrain.
L’ingénierie d’invite zéro coup est utilisée pour résumer les projets de loi. L’invite et les paramètres sont ensuite modifiés pour générer différentes sorties récapitulatives.
Dataset
Le premier jeu de données, BillSum, correspond au résumé des projets de loi du Congrès américain et de l’État de Californie. Cet exemple utilise uniquement les projets de loi du Congrès. Les données sont divisées en 18 949 projets de loi à utiliser pour l’apprentissage et 3 269 projets de loi à utiliser à des fins de test. Le jeu de données BillSum se concentre sur les projets de loi de longueur moyenne comprise entre 5 000 et 20 000 caractères. Il est nettoyé et prétraité.
Pour plus d’informations sur le jeu de données et les instructions de téléchargement, consultez la page FiscalNote/BillSum sur GitHub.
Schéma du jeu de données BillSum
Le schéma du jeu de données BillSum comprend les éléments suivants :
bill_id. Identificateur du projet de loi.text. Texte du projet de loi.summary. Résumé du projet de loi rédigé par l’homme.title. Titre du projet de loi.text_len. Longueur du projet de loi, en nombre de caractères.sum_len. Longueur du résumé du projet de loi, en nombre de caractères.
Dans ce cas d’usage, les éléments text et summary sont utilisés.
Zéro coup
L’objectif est ici de former le modèle GPT-3 à apprendre les entrées de type conversation. Le point de terminaison d’achèvement est utilisé pour créer une API Azure OpenAI et une invite qui génère le meilleur résumé du projet de loi. Il est important de créer les invites avec soin afin qu’elles extraient les informations pertinentes. Pour extraire des résumés généraux d’un projet de loi donné, le format suivant est utilisé.
- Préfixe : action à réaliser.
- Initiation de contexte : contexte.
- Contexte : informations nécessaires pour fournir une réponse. Dans ce cas, il s’agit du texte à résumer.
- Suffixe : forme prévue de la réponse. Par exemple, une réponse, un achèvement ou un résumé.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = " -- # SET A LINK TO YOUR RESOURCE ENDPOINT -- "
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
prompt_i = 'Summarize the legislative bill given the title and the text.\n\nTitle:\n'+" ".join([normalize_text(bill_title_1)])+ '\n\nText:\n'+ " ".join([normalize_text(bill_text_1)])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001
prompt=prompt_i,
temperature=0.4,
max_tokens=500,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
stop=['\n\n###\n\n'], # The ending token used during inference. Once it reaches this token, GPT-3 knows the completion is over.
best_of=1
)
= 1
Réalité de terrain : la loi « National Science Education Tax Incentive for Businesses Act » de 2007, qui modifie le code des impôts sur les revenus (Internal Revenue Code) afin d’autoriser un crédit d’impôt commercial général pour contributions de biens ou de services aux établissements scolaires primaires et secondaires et pour la formation des enseignants afin de promouvoir l’enseignement dans les domaines des sciences, des technologies, de l’ingénierie ou des mathématiques.
Résumé du modèle zéro coup : la loi « National Science Education Tax Incentive for Businesses Act » de 2007 crée un nouveau crédit d’impôt pour les entreprises qui contribuent à l’enseignement dans les domaines des sciences, des technologies, de l’ingénierie et des mathématiques (STEM) aux niveaux scolaires primaire et secondaire. Le crédit est égal à 100 pour cent des contributions STEM admissibles du contribuable pour l’exercice d’imposition. Les contributions STEM admissibles incluent les contributions scolaires STEM, les dépenses de stage des enseignants STEM et les dépenses de formation des enseignants STEM.
Observations : le modèle zéro coup génère un résumé générique succinct du document. Il est similaire à la réalité de terrain rédigée par l’homme et capture les mêmes points clés. Il est organisé comme un résumé écrit par l’homme et reste axé sur le thème.
Optimisation
L’ajustement améliore l’apprentissage zéro coup par la formation sur plus d’exemples que vous ne pouvez inclure dans l’invite, de sorte que vous obtenez de meilleurs résultats sur un plus grand nombre de tâches. Une fois qu’un modèle est ajusté, vous n’avez plus besoin de fournir d’exemples dans l’invite. L’ajustement permet d’économiser de l’argent en réduisant le nombre de jetons requis, ainsi que d’effectuer des requêtes à faible latence.
À un niveau élevé, l’ajustement comprend les étapes suivantes :
- Préparer et charger les données d’entraînement.
- Effectuer l’apprentissage d’un nouveau modèle ajusté.
- Utiliser le modèle ajusté.
Pour plus d’informations, consultez l’article Comment personnaliser un modèle avec Azure OpenAI Service.
Préparer les données pour l’ajustement
Cette étape vous permet d’améliorer le modèle zéro coup en incorporant l’ingénierie d’invite dans les invites utilisées pour l’ajustement. Vous pouvez ainsi donner au modèle des instructions sur la façon d’aborder les paires invite/achèvement. Dans un modèle ajusté, les invites fournissent un point de départ d’apprentissage du modèle, qu’il peut utiliser pour effectuer des prédictions. Ce processus permet au modèle de commencer par une compréhension de base des données, qui peut ensuite être améliorée progressivement à mesure que le modèle est exposé à davantage de données. En outre, les invites peuvent aider le modèle à identifier les modèles dans les données qu’il risque de manquer autrement.
La même structure d’ingénierie d’invite est également utilisée pendant l’inférence, une fois l’apprentissage du modèle terminé, afin que le modèle reconnaisse le comportement qu’il a appris pendant l’entraînement et puisse générer des achèvements comme indiqué.
#Adding variables used to design prompts consistently across all examples
#You can learn more here: https://learn.microsoft.com/azure/cognitive-services/openai/how-to/prepare-dataset
LINE_SEP = " \n "
PROMPT_END = " [end] "
#Injecting the zero-shot prompt into the fine-tune dataset
def stage_examples(proc_df):
proc_df['prompt'] = proc_df.apply(lambda x:"Summarize the legislative bill. Do not make up facts.\n\nText:\n"+" ".join([normalize_text(x['prompt'])])+'\n\nSummary:', axis=1)
proc_df['completion'] = proc_df.apply(lambda x:" "+normalize_text(x['completion'])+PROMPT_END, axis=1)
return proc_df
df_staged_full_train = stage_examples(df_prompt_completion_train)
df_staged_full_val = stage_examples(df_prompt_completion_val)
Maintenant que les données sont indexées pour l’ajustement dans le format approprié, vous pouvez commencer à exécuter les commandes d’ajustement.
Ensuite, vous pouvez utiliser l’interface CLI OpenAI pour faciliter certaines étapes de préparation des données. L’outil OpenAI valide les données, fournit des suggestions et reformate les données.
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_train.csv
openai tools fine_tunes.prepare_data -f data/billsum_v4_1/prompt_completion_staged_val.csv
Ajuster le jeu de données
payload = {
"model": "curie",
"training_file": " -- INSERT TRAINING FILE ID -- ",
"validation_file": "-- INSERT VALIDATION FILE ID --",
"hyperparams": {
"n_epochs": 1,
"batch_size": 200,
"learning_rate_multiplier": 0.1,
"prompt_loss_weight": 0.0001
}
}
url = RESOURCE_ENDPOINT + "openai/fine-tunes?api-version=2022-12-01-preview"
r = requests.post(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
},
json = payload
)
data = r.json()
print(data)
fine_tune_id = data['id']
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning job ID: {id}'.format(id=fine_tune_id))
print('Response Information \n\n {text}'.format(text=r.text))
Évaluer le modèle ajusté
Cette section montre comment évaluer le modèle ajusté.
#Run this cell to check status
url = RESOURCE_ENDPOINT + "openai/fine-tunes/<--insert fine-tune id-->?api-version=2022-12-01-preview"
r = requests.get(url,
headers={
"api-key": API_KEY,
"Content-Type": "application/json"
}
)
data = r.json()
print('Endpoint Called: {endpoint}'.format(endpoint = url))
print('Status Code: {status}'.format(status= r.status_code))
print('Fine tuning ID: {id}'.format(id=fine_tune_id))
print('Status: {status}'.format(status = data['status']))
print('Response Information \n\n {text}'.format(text=r.text))
Réalité de terrain : la loi « National Science Education Tax Incentive for Businesses Act » de 2007, qui modifie le code des impôts sur les revenus (Internal Revenue Code) afin d’autoriser un crédit d’impôt commercial général pour contributions de biens ou de services aux établissements scolaires primaires et secondaires et pour la formation des enseignants afin de promouvoir l’enseignement dans les domaines des sciences, des technologies, de l’ingénierie ou des mathématiques.
Résumé du modèle ajusté : ce projet de loi prévoit un crédit d’impôt pour les contributions aux établissements scolaires primaires et secondaires qui profitent à l’enseignement des sciences, des technologies, de l’ingénierie et des mathématiques. Le crédit est égal à 100 % des contributions STEM admissibles effectuées par les contribuables au cours de l’exercice d’imposition. Les contributions STEM admissibles incluent : 1) les contributions scolaires STEM, 2) les dépenses de stage des enseignants STEM et 3) les dépenses de formation des enseignants STEM. Le projet de loi prévoit également un crédit d’impôt pour les contributions aux établissements scolaires primaires et secondaires qui profitent à l’enseignement des sciences, des technologies, de l’ingénierie et des mathématiques. Le crédit est égal à 100 % des contributions de service STEM admissibles effectuées par les contribuables au cours de l’exercice d’imposition. Les contributions de service STEM admissibles comprennent : 1) les contributions de service STEM payées ou engagées au cours de l’exercice d’imposition pour des services fournis aux États-Unis ou sur une base militaire en dehors des États-Unis ; et (2) les biens d’inventaire STEM versés au cours de l’exercice d’imposition qui sont utilisés par un établissement d’enseignement situé aux États-Unis ou sur une base militaire en dehors des États-Unis pour dispenser un enseignement en sciences, en technologies, en ingénierie ou en mathématiques jusqu’au niveau secondaire.
Observations : dans l’ensemble, le modèle ajusté fait un excellent travail de résumé du projet de loi. Il capture le jargon propre au domaine et les points clés qui sont représentés, mais qui ne sont pas expliqués dans la réalité de terrain rédigée par l’homme. Il se différencie du modèle zéro coup en fournissant un résumé plus détaillé et complet.
Cas d’usage : rapports financiers
Dans ce cas d’usage, l’ingénierie d’invite zéro coup est utilisée pour créer des résumés de rapports financiers. Un approche de résumé des résumés est ensuite utilisé pour générer les résultats.
Approche de résumé des résumés
Quand vous écrivez des invites, le total GPT-3 de l’invite et de l’achèvement qui en résulte doivent inclure moins de 4 000 jetons. Vous êtes donc limité à quelques pages de texte récapitulatif. Pour les documents qui contiennent généralement plus de 4 000 jetons (environ 3 000 mots), vous pouvez utiliser une approche de résumé des résumés. Quand vous utilisez cette approche, le texte entier est tout d’abord divisé pour répondre aux contraintes de jetons. Des résumés des textes plus courts sont ensuite dérivés. À l’étape suivante, un résumé des résumés est créé. Ce cas d’usage illustre l’approche de résumé des résumés avec un modèle zéro coup. Cette solution est utile pour les documents longs. En outre, cette section décrit comment les résultats varient en fonction des différentes pratiques d’ingénierie d’invite.
Notes
L’ajustement n’est pas appliqué dans le cas d’usage financier, car les données disponibles ne sont pas suffisantes pour effectuer cette étape.
Dataset
Le jeu de données de ce cas d’usage est technique et comprend des métriques quantitatives clés pour évaluer les performances d’une entreprise.
Le jeu de données financier comprend les éléments suivants :
url: URL du rapport financier.pages: page du rapport qui contient les informations clés à résumer (index 1).completion: résumé de réalité de terrain du rapport.comments: toutes les informations supplémentaires nécessaires.
Dans ce cas d’usage, le rapport financier de Rathbones, du jeu de données, est résumé. Rathbones est une société de gestion de placements et de patrimoine pour des clients privés. Le rapport met en évidence les performances de Rathbones pour l’exercice 2020 et mentionne des métriques de performance telles que le bénéfice, les fonds sous gestion et administrés (FUMA), ainsi que les recettes. Les principales informations à résumer se trouvent à la page 1 du fichier PDF.
API_KEY = # SET YOUR OWN API KEY HERE
RESOURCE_ENDPOINT = "# SET A LINK TO YOUR RESOURCE ENDPOINT"
openai.api_type = "azure"
openai.api_key = API_KEY
openai.api_base = RESOURCE_ENDPOINT
openai.api_version = "2022-12-01-preview"
name = os.path.abspath(os.path.join(os.getcwd(), '---INSERT PATH OF LOCALLY DOWNLOADED RATHBONES_2020_PRELIM_RESULTS---')).replace('\\', '/')
pages_to_summarize = [0]
# Using pdfminer.six to extract the text
# !pip install pdfminer.six
from pdfminer.high_level import extract_text
t = extract_text(name
, page_numbers=pages_to_summarize
)
print("Text extracted from " + name)
t
Approche zéro coup
Quand vous utilisez l’approche zéro coup, vous ne fournissez pas d’exemples résolus. Vous fournissez uniquement la commande et l’entrée non résolue. Dans cet exemple, le modèle Instruct est utilisé. Ce modèle est spécifiquement conçu pour prendre une instruction et à enregistrer une réponse sans contexte supplémentaire, ce qui est idéal pour l’approche zéro coup.
Après avoir extrait le texte, vous pouvez utiliser différentes invites pour déterminer leur impact sur la qualité du résumé :
#Using the text from the Rathbone's report, you can try different prompts to see how they affect the summary
prompt_i = 'Summarize the key financial information in the report using qualitative metrics.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) reached £54.7 billion at 31 December 2020, up 8.5% from £50.4 billion at 31 December 2019
- Operating income totalled £366.1 million, 5.2% ahead of the prior year (2019: £348.1 million)
- Underlying1 profit before tax totalled £92.5 million, an increase of 4.3% (2019: £88.7 million); underlying operating margin of 25.3% (2019: 25.5%)
# Different prompt
prompt_i = 'Extract most significant money related values of financial performance of the business like revenue, profit, etc. from the below text in about two hundred words.\n\nText:\n'+" ".join([normalize_text(t)])+'\n\nKey metrics:\n'
response = openai.Completion.create(
engine="davinci-instruct",
prompt=prompt_i,
temperature=0,
max_tokens=2048-int(len(prompt_i.split())*1.5),
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(response.choices[0].text)
>>>
- Funds under management and administration (FUMA) grew by 8.5% to reach £54.7 billion at 31 December 2020
- Underlying profit before tax increased by 4.3% to £92.5 million, delivering an underlying operating margin of 25.3%
- The board is announcing a final 2020 dividend of 47 pence per share, which brings the total dividend to 72 pence per share, an increase of 2.9% over 2019
Défis
Comme vous pouvez le constater, le modèle peut produire des métriques qui ne sont pas mentionnées dans le texte d’origine.
Solution proposée : vous pouvez résoudre ce problème en modifiant l’invite.
Le résumé peut se concentrer sur une section de l’article et négliger d’autres informations importantes.
Solution proposée : vous pouvez essayer une approche de résumé des résumés. Divisez le rapport en sections et créez des résumés plus petits que vous pouvez ensuite résumer pour créer le résumé de sortie.
Le code ci-dessous implémente les solutions proposées :
# Body of function
from pdfminer.high_level import extract_text
text = extract_text(name
, page_numbers=pages_to_summarize
)
r = splitter(200, text)
tok_l = int(2000/len(r))
tok_l_w = num2words(tok_l)
res_lis = []
# Stage 1: Summaries
for i in range(len(r)):
prompt_i = f'Extract and summarize the key financial numbers and percentages mentioned in the Text in less than {tok_l_w}
words.\n\nText:\n'+normalize_text(r[i])+'\n\nSummary in one paragraph:'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=tok_l,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
t = trim_incomplete(response.choices[0].text)
res_lis.append(t)
# Stage 2: Summary of summaries
prompt_i = 'Summarize the financial performance of the business like revenue, profit, etc. in less than one hundred words. Do not make up values that are not mentioned in the Text.\n\nText:\n'+" ".join([normalize_text(res) for res in res_lis])+'\n\nSummary:\n'
response = openai.Completion.create(
engine=TEXT_DAVINCI_001,
prompt=prompt_i,
temperature=0,
max_tokens=200,
top_p=1.0,
frequency_penalty=0.5,
presence_penalty=0.5,
best_of=1
)
print(trim_incomplete(response.choices[0].text))
L’invite d’entrée inclut le texte d’origine du rapport financier de Rathbones pour un exercice spécifique.
Réalité de terrain : Rathbones a enregistré un chiffre d’affaires de 366,1 millions de livres sterling (£) en 2020, contre 348,1 millions £ en 2019, et une augmentation du bénéfice sous-jacent avant impôts de 88,7 millions £ à 92,5 millions £. Les actifs sous gestion ont augmenté de 8,5 %, passant de 50,4 milliards £ à 54,7 milliards £, les actifs de gestion de patrimoine augmentant de 4,4 % à 44,9 milliards £. Les entrées nettes ont été de 2,1 milliards £ en 2020, contre 600 millions £ l’exercice précédent, principalement tirées par des entrées de fonds de 1,5 milliard £ et 400 millions £ dus à la cession d’actifs de Barclays Wealth.
Sortie de résumé des résumés zéro coup : Rathbones a réalisé une solide performance en 2020, les fonds sous gestion et administrés (FUMA) augmentant de 8,5 % pour atteindre 54,7 milliards £ à la fin de l’exercice. Le bénéfice sous-jacent avant impôts a augmenté de 4,3 % à 92,5 millions £, offrant une marge opérationnelle sous-jacente de 25,3 %. Les entrées nettes totales du groupe ont été de 2,1 milliards £, ce qui représente un taux de croissance de 4,2 %. Le bénéfice avant impôts pour l’année s’est élevé à 43,8 millions £, avec un bénéfice de base par action de 49,6 p. Le résultat d’exploitation pour l’exercice a augmenté de 5,2 % par rapport à l’année précédente, soit 366,1 millions £.
Observations : l’approche de résumé des résumés génère un excellent jeu de résultats qui résout les défis rencontrés initialement lorsqu’un résumé plus détaillé et complet a été fourni. Il excelle dans la capture du jargon spécifique au domaine et des points clés, qui sont représentés dans la réalité de terrain, mais qui ne sont pas bien expliqués.
Le modèle zéro coup fonctionne bien pour résumer les documents standard. Si les données sont spécifiques d’un secteur ou d’un sujet, qu’elles contiennent un jargon spécifique d’un secteur ou qu’elles nécessitent des connaissances spécifiques d’un secteur, l’ajustement est la solution la plus performante. Par exemple, cette approche fonctionne bien pour les revues médicales, les textes juridiques et les états financiers. Vous pouvez utiliser l’approche en quelques coups au lieu de l’approche zéro coup pour fournir au modèle des exemples de formulation d’un résumé, afin qu’il puisse apprendre à imiter le résumé fourni. Pour l’approche zéro coup, cette solution ne provoque pas un nouvel entraînement du modèle. Les connaissances du modèle sont basées sur l’entraînement GPT-3. GPT-3 est entraîné avec presque toutes les données disponibles sur Internet. Il fonctionne bien pour les tâches qui ne nécessitent pas de connaissances spécifiques.
Recommandations
Il existe de nombreuses façons d’aborder le résumé à l’aide de GPT-3, notamment zéro coup, quelques coups et ajustement. Les approches produisent des résumés de qualité variable. Vous pouvez déterminer l’approche qui produit les meilleurs résultats pour votre cas d’usage prévu.
D’après les observations sur les tests présentés dans cet article, voici quelques recommandations :
- L’approche zéro coup est idéale pour les documents standard qui ne nécessitent pas de connaissances spécifiques d’un domaine. Cette approche tente de capturer toutes les informations de haut niveau de manière succincte et humaine, et fournit un résumé de ligne de base de haute qualité. L’approche zéro coup crée un résumé de haute qualité pour le jeu de données juridique utilisé dans les tests de cet article.
- L’approche en quelques coups est difficile à utiliser pour résumer des documents longs, car la limite de jetons est dépassée quand un exemple de texte est fourni. En lieu et place, vous pouvez utiliser une approche de résumé des résumés zéro coup pour les documents longs ou augmenter le jeu de données pour permettre un ajustement réussi. L’approche de résumé des résumés génère d’excellents résultats pour le jeu de données financier utilisé dans ces tests.
- L’ajustement est tout particulièrement utile pour les cas d’usage techniques ou spécifiques d’un domaine, quand les informations ne sont pas facilement disponibles. Pour obtenir les meilleurs résultats avec cette approche, vous avez besoin d’un jeu de données qui contient quelques milliers d’exemples. L’ajustement capture le résumé de quelques manières modélisées, en essayant de respecter la façon dont le jeu de données présente les résumés. Pour le jeu de données juridique, cette approche génère un résumé de meilleure qualité que celui créé par l’approche zéro coup.
Évaluation du résumé
Il existe plusieurs techniques pour évaluer les performances des modèles de résumé.
En voici quelques-uns :
ROUGE (Recall-Oriented Understudy for Gisting Evaluation). Cette technique comprend des mesures permettant de déterminer automatiquement la qualité d’un résumé en le comparant aux résumés idéaux créés par des humains. Les mesures comptent le nombre d’unités qui se chevauchent, comme les n-grammes, les séquences de mots et les paires de mots, entre le résumé généré par ordinateur évalué et les résumés idéaux.
Voici un exemple :
reference_summary = "The cat ison porch by the tree"
generated_summary = "The cat is by the tree on the porch"
rouge = Rouge()
rouge.get_scores(generated_summary, reference_summary)
[{'rouge-1': {'r':1.0, 'p': 1.0, 'f': 0.999999995},
'rouge-2': {'r': 0.5714285714285714, 'p': 0.5, 'f': 0.5333333283555556},
'rouge-1': {'r': 0.75, 'p': 0.75, 'f': 0.749999995}}]
BERTScore. Cette technique calcule des scores de similarité en alignant les résumés générés et de référence au niveau de jetons. Les alignements de jetons sont calculés avidement pour optimiser la similarité cosinus entre les incorporations de jetons contextualisées à partir de BERT.
Voici un exemple :
import torchmetrics
from torchmetrics.text.bert import BERTScore
preds = "You should have ice cream in the summer"
target = "Ice creams are great when the weather is hot"
bertscore = BERTScore()
score = bertscore(preds, target)
print(score)
Matrice de similarité. Une matrice de similarité est une représentation des similitudes entre différentes entités dans une évaluation de résumé. Vous pouvez l’utiliser pour comparer différents résumés d’un même texte et mesurer leur similarité. Elle est représentée par une grille à deux dimensions, où chaque cellule contient une mesure de la similarité entre deux résumés. Vous pouvez mesurer la similarité à l’aide de différentes méthodes, comme la similarité cosinus, la similarité Jaccard et la distance d’édition. Vous utilisez ensuite la matrice pour comparer les résumés et déterminer lequel correspond à la représentation la plus précise du texte d’origine.
Voici un exemple de commande qui obtient la matrice de similarité d’une comparaison BERTScore de deux phrases similaires :
bert-score-show --lang en -r "The cat is on the porch by the tree"
-c "The cat is by the tree on the porch"
-f out.png
La première phrase, « The cat is on the porch by the tree » (Le chat est sur le porche près de l’arbre), est appelée candidat. La seconde phrase est appelée référence. La commande utilise BERTScore pour comparer les phrases et générer une matrice.
La matrice suivante affiche la sortie générée par la commande précédente :
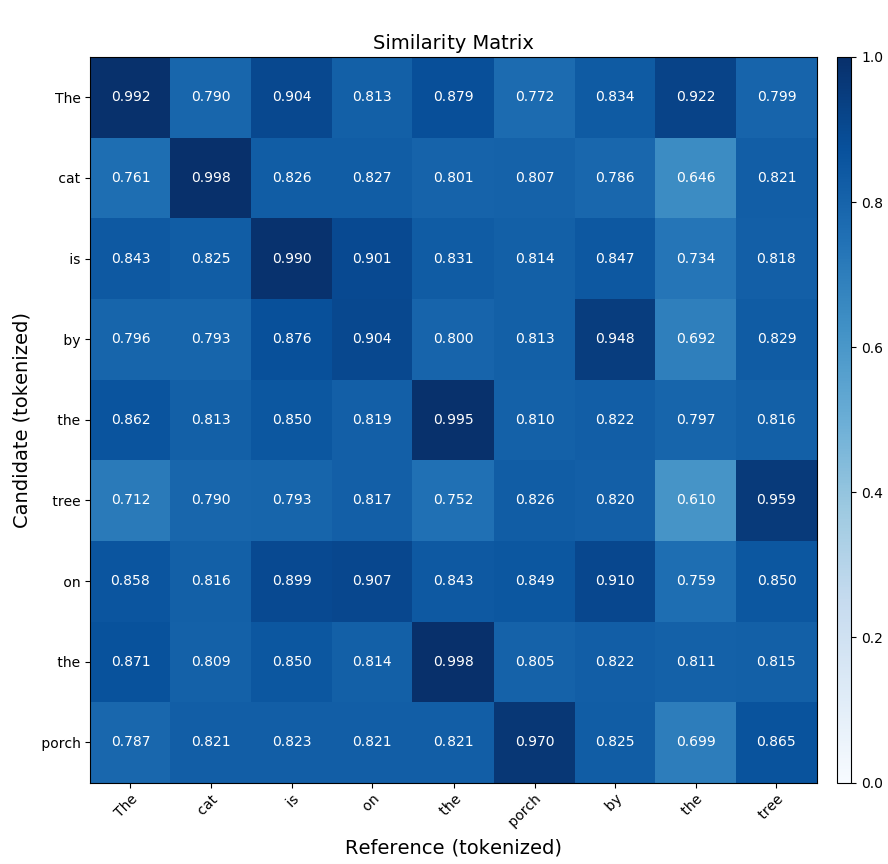
Pour plus d’informations, consultez l’article SummEval: Reevaluating Summarization Evaluation (en anglais uniquement). Pour obtenir un kit de ressources PyPI pour le résumé, consultez la page Summ-eval 0.892.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Noa Ben-Efraim | Data & Applied Scientist
Autres contributeurs :
- Mick Alberts | Rédacteur technique
- Rania Bayoumy | Responsable de programme technique senior
- Harsha Viswanath | Responsable principal en sciences appliquées
Pour afficher les profils LinkedIn non publics, connectez-vous à LinkedIn.
Étapes suivantes
- Azure OpenAI - Documentation, guides de démarrage rapide, informations de référence sur l’API
- Intentions dans LUIS
- Compréhension du langage courant
Ressources associées
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour