Cet article décrit une solution pour le déploiement de modules IoT (Internet of Things) Edge conteneurisés sur des connexions Internet intermittentes ou à faible bande passante.
Le traitement en périphérie est un modèle IoT clé pour fournir une connectivité à faible latence et conserver de la bande passante (par exemple, dans les scénarios mobiles). Les systèmes IoT approvisionnent habituellement les périphériques en déployant des images conteneur logicielles. Les déploiements de conteneurs interrompus sur des connexions Internet à faible bande passante ou intermittentes peuvent être à l’origine de défaillances dans le cadre des scénarios mobiles. Les scénarios impliquant une bande passante limitée, intermittente ou faible ont besoin de fonctionnalités de déploiement fiables et résilientes.
Dans cet exemple, une grande entreprise logistique cherchait à améliorer le suivi de ses expéditions de produits à l’international. L’entreprise expédiait ses marchandises par transport terrestre, aérien et maritime vers de nombreuses localités, y compris des zones avec une connectivité Internet intermittente ou à faible bande passante. Selon le type de marchandises, divers appareils IoT d’assurance, de sécurité ou de suivi dotés de différentes fonctionnalités étaient installés sur les colis (traceurs GPS, capteurs de température, outils de capture de données, etc.).
L’entreprise rencontrait des problèmes pour mettre à jour ses appareils via sa plateforme Azure IoT Edge récemment développée. Les principales difficultés étaient les suivantes :
- Consommation de bande passante élevée lors du déploiement de mises à jour logicielles sur les appareils.
- Aucun déploiement automatisé standardisé sur les appareils.
- Flexibilité limitée pour la sélection des technologies.
Pour résoudre ces problèmes, l’équipe de développement a créé une solution qui :
- Réduit la taille du déploiement sur chaque appareil, ce qui permet de réduire la bande passante.
- Implémente un déploiement de conteneur Docker standardisé à partir de la plateforme IoT Edge vers des appareils IoT distants hétérogènes.
- Exerce une surveillance fiable du déploiement.
- Tire parti de différents services Azure DevOps et cloud, et utilise les outils hérités privilégiés du client.
La solution a considérablement amélioré la fiabilité et la résilience du processus d’approvisionnement des appareils dans les environnements disposant d’une connectivité limitée. Cet article décrit la solution dans le détail et le processus d’évaluation des options de la solution.
Spécifications du client
Le client avait le cahier des charges suivant :
- La solution doit prendre en charge la connectivité cloud intermittente ou à faible bande passante.
- Les applications déployées doivent continuer de s’exécuter localement.
- Le personnel local doit utiliser des fonctionnalités hors connexion ou sans retard de boucle sur le cloud.
- Quand elle est connectée, la solution doit utiliser efficacement la connexion cloud.
- La solution doit hiérarchiser l’envoi des données en fonction de règles métier définies de manière uniformisée entre les produits.
Les spécifications détaillées suivantes ont également été formulées :
- Les fichiers image sont transférés via une connexion satellite intermittente ou à faible bande passante.
- La quantité de données transférées doit être réduite.
- Les transferts de fichiers vers des appareils utilisent l’application tierce préférée du client.
- Les charges de travail d’appareil utilisent des images Docker dans IoT Edge.
- La taille des images peut être comprise entre plusieurs dizaines de Mo et plusieurs Go.
- Les modules IoT Edge sont écrits en .NET Core 2.2.
Cas d’usage potentiels
Cette solution convient aux scénarios IoT où les conteneurs logiciels fournissent des solutions sur des connexions intermittentes ou à faible bande passante. Voici quelques exemples :
- Surveillance d’infrastructures pétrolières, gazières et minières
- Mises à jour d’automobiles par voie hertzienne
- Partout où une connexion forte n’est pas garantie
Architecture
Dans des scénarios à bande passante élevée, Azure IoT Edge extrait les images directement à partir d’un registre Docker accessible via internet, qu’il s’agisse d’un hub Docker ou d’un hub privé tel que Azure Container Registry. Cette fonctionnalité est équivalente à l’exécution de la commande docker pull <image_name>.
En cas d’accès réseau potentiellement intermittent, tel qu’une connexion Internet par satellite, la méthode docker pull n’est pas fiable. La progression n’est pas mise en cache si la connexion Internet est interrompue pendant que Docker extrait l’image. Lorsque la connexion Internet reprend, Docker doit recommencer à extraire l’image depuis le début.
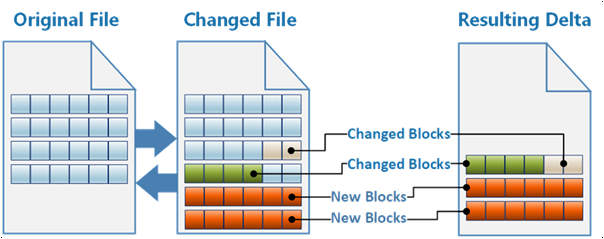
La solution utilise un mécanisme de déploiement alternatif, un correctif binaire des fichiers image Docker, pour réduire la bande passante et compenser l’intermittence de la connectivité.
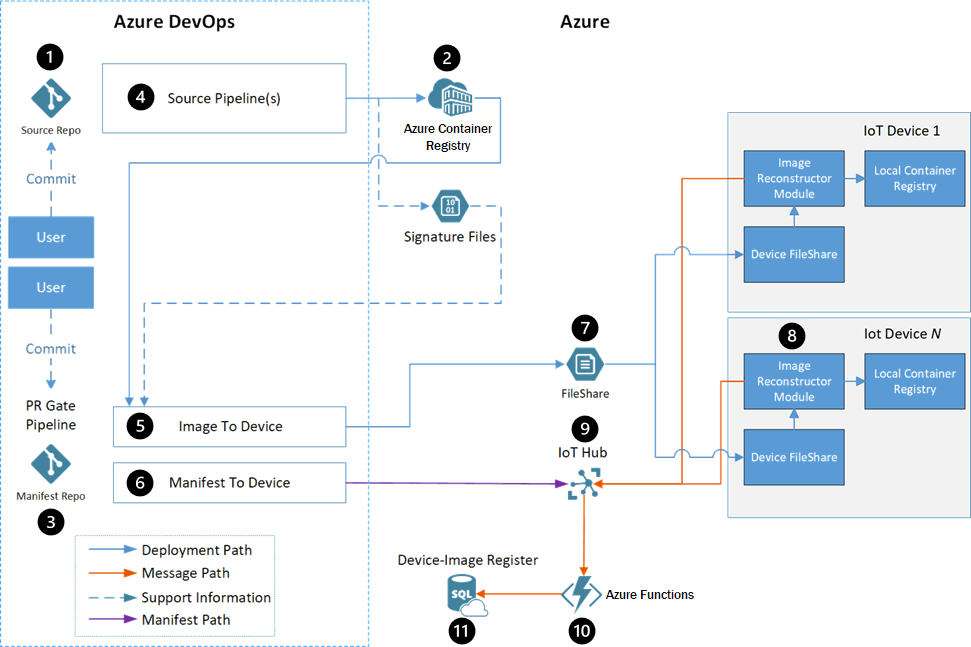
Dataflow
- Les développeurs interagissent avec un code source de module Edge dans un référentiel de code source.
- Container Registry stocke les images Docker de chaque module.
- Le référentiel de manifestes contient les manifestes de déploiement pour tous les flux de travail.
- Chaque module inclut un pipeline de build Azure Pipelines qui utilise une build Docker générique pour créer et inscrire automatiquement des modules.
- Le pipeline image à appareil déploie les images Docker sur les appareils ciblés, comme défini par le fichier manifeste.
- Le pipeline manifeste à appareil envoie le manifeste de déploiement au service Azure IoT Hub approprié pour mettre à jour l’appareil.
- Une solution de transfert de fichiers rapide tierce transfère les fichiers d’un compte Stockage Azure vers l’appareil.
- Le module IoT Edge Image Reconstruction applique les correctifs reçus sur les appareils.
- IoT Hub reçoit les messages d’état du module Image Reconstruction et définit le manifeste de déploiement de l’appareil. Le reste du flux de pipeline utilise ce manifeste de déploiement.
- Azure Functions surveille le flux de messages IoT Hub, met à jour la base de données SQL et avertit l’utilisateur de la réussite ou de l’échec.
- Azure SQL Database effectue le suivi des occurrences sur les appareils cibles et les services Azure, pendant et après le déploiement.
Composants
- Azure IoT Edge exécute des charges de travail conteneurisées sur des appareils, et fournit une connectivité à faible latence et conserve la bande passante ce faisant.
- Azure IoT Hub est un service managé hébergé sur le cloud qui joue le rôle de hub de messages central entre les applications IoT et les appareils qu’ils contrôlent.
- Azure Container Registry est un service de registre privé basé sur le cloud qui permet de stocker et gérer des images conteneur Docker privées et des artefacts associés.
- Azure Pipelines combine l’intégration continue (CI) et la livraison continue (CD) afin de tester et générer automatiquement du code et l’expédier vers n’importe quelle cible.
- Azure Functions est une plateforme de calcul serverless qui permet d’exécuter du code déclenché par des événements sans approvisionner ou gérer l’infrastructure.
- Stockage Azure fournit un stockage hautement évolutif, sécurisé, performant et économique pour tous les types de données métier, d’objets et de fichiers.
- Azure SQL Database est un service de base de données relationnelle multimodèle complètement managé, conçu pour le cloud.
- Docker est une plateforme ouverte pour le développement, l’expédition et l’exécution d’applications conteneurisées.
Autres solutions
L’équipe de développement a évalué plusieurs options avant de se décider pour la solution de transfert delta des images Docker complète. Les sections suivantes décrivent les alternatives d’évaluation et les résultats.
L’équipe a pris en compte les critères d’évaluation suivants pour chaque option :
- Adéquation ou non de la solution aux spécifications.
- Nécessité d’implémenter une quantité de logique faible, moyenne ou élevée sur les appareils.
- Nécessité d’implémenter une quantité de logique faible, moyenne ou élevée dans Azure.
- Efficacité de la bande passante ou ratio des données transférées par rapport à la taille totale d’une image pour le transfert d’une image conteneur.
L’efficacité de la bande passante inclut les scénarios dans lesquels :
- Aucune image n’existait sur l’appareil.
- Une image avec la même base existait sur l’appareil.
- Une image d’une version d’application précédente existait sur l’appareil.
- Une image de l’application générée sur une image de base précédente existait sur l’appareil.
L’équipe a utilisé les scénarios suivants pour évaluer l’efficacité de la bande passante :
| Scénario | Description |
|---|---|
| Transférer une image avec une couche de base figurant déjà sur l’appareil | Le transfert d’une nouvelle image lorsqu’une autre image figurait déjà sur l’appareil entraîne le partage de l’image de base. Ce scénario représente le déploiement d’une nouvelle application pour la première fois, alors qu’il existe déjà une autre application dans les mêmes système d’exploitation et infrastructure. |
| Mettre à jour la couche d’application | Modifier le code uniquement pour l’image d’une application existante. Ce scénario représente une modification classique quand un utilisateur valide une nouvelle fonctionnalité. |
| Mettre à jour l’image de base | Modifier la version de l’image de base sur laquelle l’application est construite. |
Option de transfert des couches Docker
Une image conteneur Docker est un montage UnionFS de différences de système de fichiers en lecture seule, avec une autre couche accessible en écriture pour les modifications apportées pendant l’exécution du conteneur. Les systèmes de fichiers sont appelés couches. Il s’agit essentiellement de dossiers et de fichiers. Les couches sont empilées pour former la base du système de fichiers racine du conteneur. Les couches étant en lecture seule, diverses images peuvent partager la même couche si celle-ci leur est commune.
L’option de transfert des couches Docker réutilise les couches entre les images et transfère uniquement de nouvelles couches vers l’appareil. Cette option serait plus utile pour les images qui partagent la même couche de base, généralement le système d’exploitation ou pour mettre à jour les versions des images existantes.
Cette méthode présente les inconvénients suivants :
- L’orchestrateur doit maintenir les informations concernant les couches qui existent sur les différents appareils.
- Les modifications apportées à la couche de base entraînent la modification des codes de hachage de toutes les couches suivantes.
- La comparaison nécessite des hachages de couche cohérents.
- Il peut y avoir des dépendances lors de l’enregistrement Docker et de la charge Docker.
Option de modification du client Docker
Cette option se concentre sur la modification ou l’inclusion dans un wrapper du client Docker afin qu’il reprenne le téléchargement des couches après une interruption. Par défaut, une commande Docker pull reprend un téléchargement si la connexion Internet est restaurée dans un délai d’environ 30 minutes après l’interruption. Sinon, le client quitte et perd toute la progression du téléchargement.
Cette méthode est viable, mais peut présenter des complications, notamment :
- Toutes les images sur l’appareil doivent être inscrites auprès du démon Docker qui extraie les images afin d’optimiser l’efficacité de la bande passante.
- Le projet Docker open source doit être changé pour prendre en charge cette fonctionnalité, ce qui présente un risque de rejet par les chargés de maintenance open source.
- Le transfert des données via HTTP plutôt qu’à l’aide de la solution de transfert de fichiers rapide privilégiée du client nécessiterait le développement d’une logique de nouvelle tentative personnalisée.
- Toutes les couches doivent être retransmises en cas de modification d’une image de base.
Option de génération sur un périphérique
Cette approche déplace l’environnement de build d’image sur les appareils. Les données suivantes sont envoyées à l’appareil :
- code source de l’application en cours de génération ;
- copie de tous les packages NuGet dont le code dépend ;
- images de base Docker pour l’environnement et le runtime de build .NET Core ;
- métadonnées relatives à l’image de fin.
Un agent de build sur l’appareil génère ensuite l’image et l’inscrit auprès du gestionnaire Docker de l’appareil.
Cette solution a été rejetée pour les raisons suivantes :
- Elle nécessite encore de disposer d’un moyen de déplacer des images Docker volumineuses vers l’appareil. Les images permettant de générer des applications .NET sont plus volumineuses que les images d’application elles-mêmes.
- Cette méthode fonctionne uniquement pour les applications pour lesquelles l’équipe dispose du code source, de telle sorte qu’elle ne peut pas utiliser d’images tierces.
- L’option nécessite l’empaquetage des packages NuGet et le suivi de leur mouvement vers les appareils.
- Si la génération d’une image échoue sur l’appareil, l’équipe devrait effectuer un débogage à distance de l’environnement de build et de l’image créée. Le débogage à distance nécessiterait une utilisation élevée de la connexion Internet potentiellement limitée.
Option de transfert delta d’image complet
L’approche choisie traite une image Docker comme un fichier binaire unique. La commande Docker save exporte l’image en tant que fichier .tar. La solution exporte les images Docker existantes et nouvelles, et calcule le delta binaire qui, lorsqu’il est appliqué, transforme l’image existante en image nouvelle.
La solution suit les images Docker existantes sur les appareils et génère des correctifs delta binaires pour transformer les images existantes en nouvelles images. Le système transfère uniquement les correctifs delta sur la connexion Internet à faible bande passante. Cette solution nécessitait une logique personnalisée pour générer les correctifs binaires, mais a envoyé la quantité minimale de données aux appareils.
Evaluation results
Le tableau suivant présente la manière dont chacune des solutions ci-dessus a été classée par rapport aux critères d’évaluation.
| Adéquation aux spécifications | Logique d’appareil | Logique Azure | Transport | Première image | Base sur l’appareil | Mise à jour de la couche d’application | Mise à jour la couche de base | |
|---|---|---|---|---|---|---|---|---|
| Transfert des couches Docker | Yes | Faible | Moyenne | FileCatalyst | 100 % | 10,5 % | 22,4 % | 100 % |
| Modification du client Docker | Yes | Moyenne | Faible | HTTP | 100 % | 10,5 % | 22,4 % | 100 % |
| Génération sur un périphérique | Non | Élevé | Moyenne | FileCatalyst | N/A | N/A | N/A | N/A |
| Transfert de delta d’image complet | Yes | Faible | Élevé | FileCatalyst | 100 % | 3,2 % | 0.01 | 16,1 % |
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework, un ensemble de principes directeurs qui permettent d’améliorer la qualité des charges de travail. Pour plus d'informations, consultez Microsoft Azure Well-Architected Framework.
Efficacité des performances
Cette solution a considérablement réduit la bande passante consommée par les mises à jour des appareils IoT. Les tableaux suivants détaillent les différences liées à l’efficacité des transferts.
Image Reconstructor en tant que source :
| Nom de l’image | Taille de l'image | Taille du correctif | Réduction des données |
|---|---|---|---|
| Visualisation des données | 228 Mo | 79,6 Mo | 65,1 % |
| WCD simulé | 188 Mo | 1,5 Mo | 99,2 % |
| Proxy | 258 Mo | 29,9 Mo | 88,4 % |
Version précédente en tant que source :
| Nom de l’image | Taille de l'image | Taille du correctif | Réduction des données |
|---|---|---|---|
| Visualisation des données | 228 Mo | 0,01 Mo | 99,9 % |
| WCD simulé | 188 Mo | 0,5 Mo | 99,7 % |
| Proxy | 258 Mo | 0,04 Mo | 99,9 % |
Excellence opérationnelle
Les sections suivantes fournissent une description détaillée de la solution.
Référentiel du code source
Les développeurs interagissent avec un code source de module Edge dans un référentiel de code source. Le référentiel est constitué de dossiers qui contiennent le code de chaque module, comme suit :
\- repository root
- modulea
- modulea.csproj
- module.json
- Program.cs
- Dockerfile
\- moduleb
- moduleb.csproj
- module.json
- Program.cs
- Dockerfile
Le nombre de référentiels de code source suivant est recommandé :
- Un référentiel pour tous les modules dans tous les flux de travail.
- Un référentiel de code source pour chaque flux de travail.
Instances Container Registry
Container Registry stocke les images Docker de chaque module. Il existe deux configurations possibles pour Container Registry :
- Instance Container Registry unique qui stocke toutes les images.
- Deux instances Container Registry, une pour stocker les images de développement, de test et de débogage, et une autre qui contient uniquement les images marquées comme prêtes pour la production.
Référentiel de manifestes
Le référentiel de manifestes contient les manifestes de déploiement pour tous les flux de travail. Les modèles se trouvent dans des dossiers basés sur leur flux de travail. Dans cet exemple, les deux flux de travail sont l’infrastructure partagée et l’application conteneurisée.
\- repository root
- Workstream1
- deployment.template.json
- Workstream2
- deployment.template.json
Pipeline de build d’images Docker
Chaque module dispose d’un pipeline de build Azure Pipelines. Le pipeline utilise un build Docker générique pour créer et inscrire des modules. Le pipeline est responsable des opérations suivantes :
- Analyse de la sécurité du code source.
- Analyse de la sécurité de l’image de base pour la génération de l’image Docker.
- Exécution de tests unitaires pour le module.
- Génération de la source dans une image Docker. L’étiquette d’image contenant le
BUILD_BUILDID, l’image peut toujours être reliée au code source qui l’a créée. - Envoi (push) de l’image à une instance Container Registry.
- Création du fichier delta.
- Création d’un fichier de signature pour l’image et enregistrement du fichier dans un compte de stockage Azure.
Toutes les instances de pipeline sont basées sur une définition de pipeline YAML unique. Le pipeline peut agir sur les modules à l’aide de variables d’environnement. Les filtres déclenchent chaque pipeline uniquement lorsque les modifications sont validées dans un certain dossier. Ce filtre évite de générer tous les modules quand un seul module est mis à jour.
Pipeline image à appareil
Le pipeline image à appareil déploie les images Docker sur les appareils ciblés, comme défini par un fichier manifeste. Le déclenchement du pipeline démarre manuellement le déploiement.
La définition de pipeline spécifie l’exécution de ces déploiements dans un conteneur. Les pipelines prennent en charge l’entrée de variables pour les images sur lesquels baser les conteneurs. Une variable unique peut contrôler les déploiements pour tous les pipelines.
L’image contient le code qui détermine les correctifs à générer, génère les correctifs et les distribue au côté Azure de l’outil de transfert de fichiers.
L’outil de distribution d’images a besoin des informations suivantes :
- Image(s) à déployer, fournies par le manifeste dans le référentiel.
- Appareils sur lesquels effectuer le déploiement, fournis par l’utilisateur déclenchant le pipeline.
- Image(s) déjà présentes sur les appareils ciblés, fournies par une base de données Azure SQL.
Les sorties du pipeline sont les suivantes :
- Packs de correctifs envoyés au côté Azure de l’outil de transfert de fichiers pour être distribués aux appareils.
- Entrées de base de données SQL qui marquent les images qui ont commencé à être transférées vers chaque appareil.
- Entrées de base de données SQL pour les nouveaux jeux de déploiement. Ces entrées incluent le nom et l’adresse e-mail de l’utilisateur qui a ordonné le déploiement.
Ce pipeline effectue les opérations suivantes :
- Déterminer les images nécessaires, en fonction du manifeste de déploiement.
- Interroger SQL pour voir quelles images sont déjà sur les appareils. Si toutes les images sont déjà présentes, le pipeline se termine correctement.
- Déterminer les bundles de correctifs à créer. L’algorithme détermine l’image de départ qui génère le plus petit pack de correctifs.
- Entrées : un fichier .tar contenant la nouvelle image à déployer et les fichiers de signature des images existantes sur les appareils.
- Sortie : un classement des images existantes pour déterminer le plus petit correctif à créer.
- Créer les bundles de correctifs nécessaires pour chaque appareil. Générer des correctifs similaires une seule fois et les copier sur tous les appareils qui en ont besoin.
- Distribuer les correctifs au compte de stockage de l’outil de transfert de fichiers pour le déploiement.
- Mettre à jour SQL pour marquer les nouvelles images comme étant
in transitsur chacun des appareils ciblés. - Ajouter les informations du jeu de déploiement à SQL, ainsi que le nom et l’adresse e-mail de contact de la personne qui déploie l’image.
Pipeline manifeste à appareil
Le pipeline manifeste à appareil envoie (push) le manifeste de déploiement vers la connexion IoT Hub appropriée pour l’appareil en cours de mise à jour. Un utilisateur déclenche le pipeline manuellement et spécifie une variable d’environnement que l’instance IoT Hub doit cibler.
Le pipeline effectue les opérations suivantes :
- Déterminer les images nécessaires au déploiement.
- Interroger SQL pour s’assurer que les images nécessaires se trouvent déjà sur les appareils ciblés. Si ce n’est pas le cas, le pipeline se termine avec l’état
failed. - Envoyer (push) le nouveau manifeste de déploiement vers la connexion Hub IoT appropriée.
Solution de transfert de fichiers rapide
Le client voulait continuer à utiliser sa solution de transfert de fichiers rapide tierce (FileCatalyst) pour fournir la connexion entre Azure et ses appareils IoT. Cette solution est un outil de transfert de fichiers finalement cohérents. Cela signifie qu’un transfert peut prendre beaucoup de temps, mais finira par se terminer sans perte d’informations de fichier.
La solution a utilisé un compte Stockage Azure du côté Azure de la connexion et la machine virtuelle hôte de transfert des fichiers existante du client pour chaque appareil recevant des images. Les bundles de correctifs sont transférés vers une machine virtuelle Linux qui exécute IoT Hub.
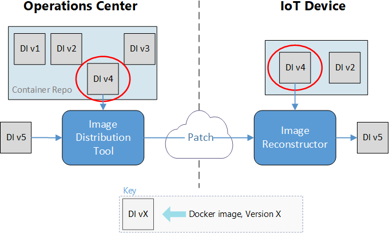
Module Image Reconstruction
Le module IoT Edge Image Reconstruction applique les correctifs reçus sur les appareils. Chaque appareil héberge son propre registre de conteneurs local, à l’aide du registre open source Docker. Le processus Image Reconstruction est exécuté sur la machine virtuelle hôte, laquelle est identique à la machine virtuelle de transfert de fichiers.
Le module :
- reçoit le pack de correctifs dans un dossier monté sur le conteneur.
- décompresse le contenu du correctif pour lire le fichier de configuration.
- extrait (pull) l’image de base du registre de conteneurs local par hachage.
- enregistre l’image de base sous la forme d’un fichier .tar.
- applique le correctif à l’image de base.
- charge sur Docker le fichier .tar contenant la nouvelle image.
- envoie (push) la nouvelle image au registre de conteneurs local, avec un fichier de configuration incluant un nom convivial et une balise.
- envoie un message de réussite à IoT Hub.
Si le processus échoue à un moment quelconque, le module envoie un message d’échec à IoT Hub afin que l’utilisateur qui a ordonné le déploiement puisse être averti.
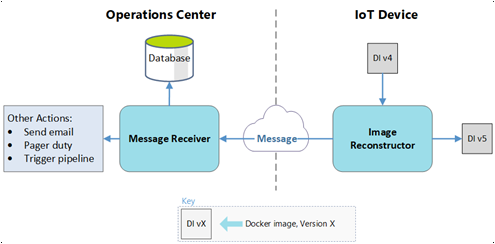
IoT Hub
Plusieurs des processus de déploiement utilisent IoT Hub. Outre la réception des messages d’état du module Image Reconstruction, IoT Hub définit le manifeste de déploiement de l’appareil. Le reste du flux de pipeline utilise ce manifeste.
Azure Functions
Azure Functions surveille le flux de messages provenant de IoT Hub et prend des mesures dans le cloud.
Pour un message de réussite :
- La fonction met à jour l’état de l’entrée SQL pour l’image sur l’appareil, qui passe de
in transitàsucceeded. - S’il s’agit de la dernière image à arriver dans un jeu de déploiement :
- La fonction avertit l’utilisateur de la réussite du déploiement.
- La fonction met à jour le pipeline manifeste à appareil pour commencer à utiliser les nouvelles images.
Pour un message d’échec :
- La fonction met à jour l’état de l’entrée SQL pour l’image sur l’appareil, qui passe de
in transitàfailed. - La fonction avertit l’utilisateur de l’échec du transfert d’image.
SQL Database
Une base de données SQL effectue le suivi des occurrences sur les appareils cibles et les services de déploiement Azure pendant et après le déploiement. Azure Functions et Azure Pipelines utilisent tous deux un package NuGet privé créé pour interagir avec la base de données.
SQL Database stocke les données suivantes :
- quelles images se trouvent sur chaque appareil ;
- quelles images sont en transit vers chaque appareil ;
- quelles images en cours de déploiement appartiennent à un jeu ;
- utilisateur ayant ordonné les déploiements.
L’objectif de cet exemple était de s’assurer que le système a généré les données nécessaires pour les tableaux de bord de données futurs. L’interrogation de IoT Hub peut fournir les données suivantes sur le pipeline manifeste à appareil :
- État d’un déploiement.
- Images sur un appareil donné.
- Les appareils qui ont une image.
- Données de série chronologique sur les transferts qui ont réussi et échoué.
- Requêtes de déploiements basées sur l’utilisateur.
Contributeurs
Cet article est géré par Microsoft. Il a été écrit à l’origine par les contributeurs suivants.
Auteur principal :
- Kanio Dimitrov | Responsable d’ingénierie de logiciel principal
Étapes suivantes
- Déployer votre premier module IoT Edge sur un appareil virtuel Linux
- Développement de modules IoT Edge avec des conteneurs Linux