Qu’est-ce que Model Builder et comment fonctionne-t-il ?
Model Builder ML.NET est une extension graphique intuitive de Visual Studio, qui permet de générer, d’entraîner et de déployer des modèles Machine Learning personnalisés. Celle-ci utilise le Machine Learning automatisé (AutoML) pour explorer différents algorithmes et paramètres Machine Learning afin de vous aider à trouver celui qui convient le mieux à votre scénario.
Vous n’avez pas besoin d’une expertise en machine learning pour utiliser Model Builder. Vous avez seulement besoin de quelques données et d’un problème à résoudre. Model Builder génère le code pour ajouter le modèle à votre application .NET.

Créer un projet Model Builder
Lorsque vous démarrez Model Builder pour la première fois, vous êtes invité à nommer le projet, puis un fichier config mbconfig est créé à l’intérieur du projet. Le fichier mbconfig effectue le suivi de toutes les opérations que vous effectuez dans Model Builder pour vous permettre de rouvrir la session.
Après l’entraînement, trois fichiers sont générés sous le fichier *.mbconfig :
- Model.consumption.cs : Ce fichier contient les schémas
ModelInputetModelOutputainsi que la fonctionPredictgénérée pour la consommation du modèle. - Model.training.cs : Ce fichier contient le pipeline d’entraînement (transformations de données, algorithme, hyperparamètres de l’algorithme) choisi par Model Builder pour entraîner le modèle. Vous pouvez utiliser ce pipeline pour réentraîner votre modèle.
- Model.zip : C’est un fichier zip sérialisé qui représente votre modèle ML.NET entraîné.
Quand vous créez votre fichier mbconfig, vous êtes invité à entrer un nom. Ce nom est appliqué aux fichiers de consommation, d’entraînement et de modèle. Dans le cas présent, le nom utilisé est Model.
Scénario
Vous pouvez soumettre de nombreux scénarios différents à Model Builder pour générer un modèle Machine Learning pour votre application.
Un scénario est une description du type de prédiction que vous voulez faire avec vos données. Par exemple :
- Prédire le volume futur des ventes d’un produit en fonction de l’historique des données des ventes.
- Classifier des sentiments comme étant positifs ou négatifs en fonction des avis des clients.
- Détecter si une transaction bancaire est frauduleuse.
- Acheminer les problèmes indiqués dans les commentaires des clients vers l’équipe appropriée dans votre entreprise.
Chaque scénario est mappé à une tâche Machine Learning différente, qui comprend :
| Tâche | Scénario |
|---|---|
| Classification binaire | Classification des données |
| Classification multiclasse | Classification des données |
| Classification d’images | Classification d’images |
| Classification de texte | Classification de texte |
| régression ; | Prédiction de valeur |
| Recommandation | Recommandation |
| Prévisions | Prévisions |
Par exemple, le scénario de classification des sentiments comme positifs ou négatifs relèverait de la tâche de classification binaire.
Pour plus d’informations sur les différentes tâches ML prises en charge par ML.NET consultez Tâches de machine learning dans ML.NET.
Quel est le bon scénario Machine Learning pour moi ?
Dans Model Builder, vous devez sélectionner un scénario. Le type de scénario dépend du type de prédiction que vous essayez de faire.
Tabulaire
Classification des données
La classification est utilisée pour classifier les données en catégories.
Exemple d’entrée
Exemple de sortie
| SepalLength | SepalWidth | Petal Length (Longueur des pétales) | Petal Width (Largeur des pétales) | Species (Espèce) |
|---|---|---|---|---|
| 5,1 | 3,5 | 1.4 | 0.2 | setosa |
| Espèces prédites |
|---|
| setosa |
Prédiction de valeur
La prédiction de valeur, qui relève de la tâche de régression, est utilisée pour prédire des nombres.

Exemple d’entrée
Exemple de sortie
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Tarif prédit |
|---|
| 4.5 |
Recommandation
Le scénario de recommandation prédit une liste d’éléments suggérés pour un utilisateur particulier, en fonction de la similitude de leurs évaluations « J’aime » et « Je n’aime pas » avec celles d’autres utilisateurs.
Vous pouvez utiliser le scénario de recommandation quand vous avez un ensemble d’utilisateurs et un ensemble de « produits », comme des articles à acheter, des films, des livres ou des émissions de télévision, avec un ensemble « d’évaluations » de ces produits par les utilisateurs.
Exemple d’entrée
Exemple de sortie
| UserId | ProductId | Rating |
|---|---|---|
| 1 | 2 | 4,2 |
| Évaluation prédite |
|---|
| 4.5 |
Prévisions
Le scénario de prévision utilise des données historiques avec une série chronologique ou un composant saisonnier.
Vous pouvez utiliser le scénario de prévision pour prévoir la demande ou la vente d’un produit.
Exemple d’entrée
Exemple de sortie
| Date | SaleQty |
|---|---|
| 1/1/1970 | 1 000 |
| Prévisions à 3 jours |
|---|
| [1000,1001,1002] |
Vision par ordinateur
Classification d’images
La classification d’images est utilisée pour identifier les images de différentes catégories. Par exemple, différents types de terrains, d’animaux ou de défauts de fabrication.
Vous pouvez utiliser le scénario de classification d’images si vous disposez d’un ensemble d’images et que vous voulez classifier les images en différentes catégories.
Exemple d’entrée
Exemple de sortie

| Étiquette prédite |
|---|
| Chien |
Détection d’objets
La détection d’objets est utilisée pour localiser et classifier des entités dans des images. Par exemple, la localisation et l’identification de voitures et de personnes dans une image.
Vous pouvez utiliser la détection d’objets quand les images contiennent plusieurs objets de différents types.
Exemple d’entrée
Exemple de sortie

Traitement en langage naturel
Classification de texte
La classification de texte catégorise les entrées de texte brut.
Vous pouvez utiliser le scénario de classification de texte si vous avez un ensemble de documents ou de commentaires, et que vous voulez les classifier en différentes catégories.
Exemple d’entrée
Exemple de sortie
| Révision |
|---|
| J’aime beaucoup ce steak ! |
| Sentiments |
|---|
| Positif |
Environnement
Vous pouvez entraîner votre modèle Machine Learning localement sur votre machine ou dans le cloud sur Azure, selon le scénario.
Quand vous entraînez localement, vous travaillez dans les limites des ressources de votre ordinateur (processeur, mémoire et disque). Quand vous vous entraînez dans le cloud, vous pouvez mettre à l’échelle vos ressources pour répondre aux exigences de votre scénario, en particulier pour les grands jeux de données.
| Scénario | Processeur local | GPU local | Azure |
|---|---|---|---|
| Classification des données | ✔️ | ❌ | ❌ |
| Prédiction de valeur | ✔️ | ❌ | ❌ |
| Recommandation | ✔️ | ❌ | ❌ |
| Prévisions | ✔️ | ❌ | ❌ |
| Classification des images | ✔️ | ✔️ | ✔️ |
| Détection des objets | ❌ | ❌ | ✔️ |
| Classification de texte | ✔️ | ✔️ | ❌ |
Données
Une fois que vous avez choisi votre scénario, Model Builder vous demande de fournir un jeu de données. Les données sont utilisées pour entraîner, évaluer et choisir le meilleur modèle pour votre scénario.
Model Builder prend en charge les jeux de données aux formats .tsv, .csv, .txt et de base de données SQL. Si vous avez un fichier .txt, les colonnes doivent être séparées par ,, ; ou \t.
Si le jeu de données est constitué d’images, les types de fichiers pris en charge sont .jpg et .png.
Pour plus d’informations, consultez Charger des données d’entraînement dans Model Builder.
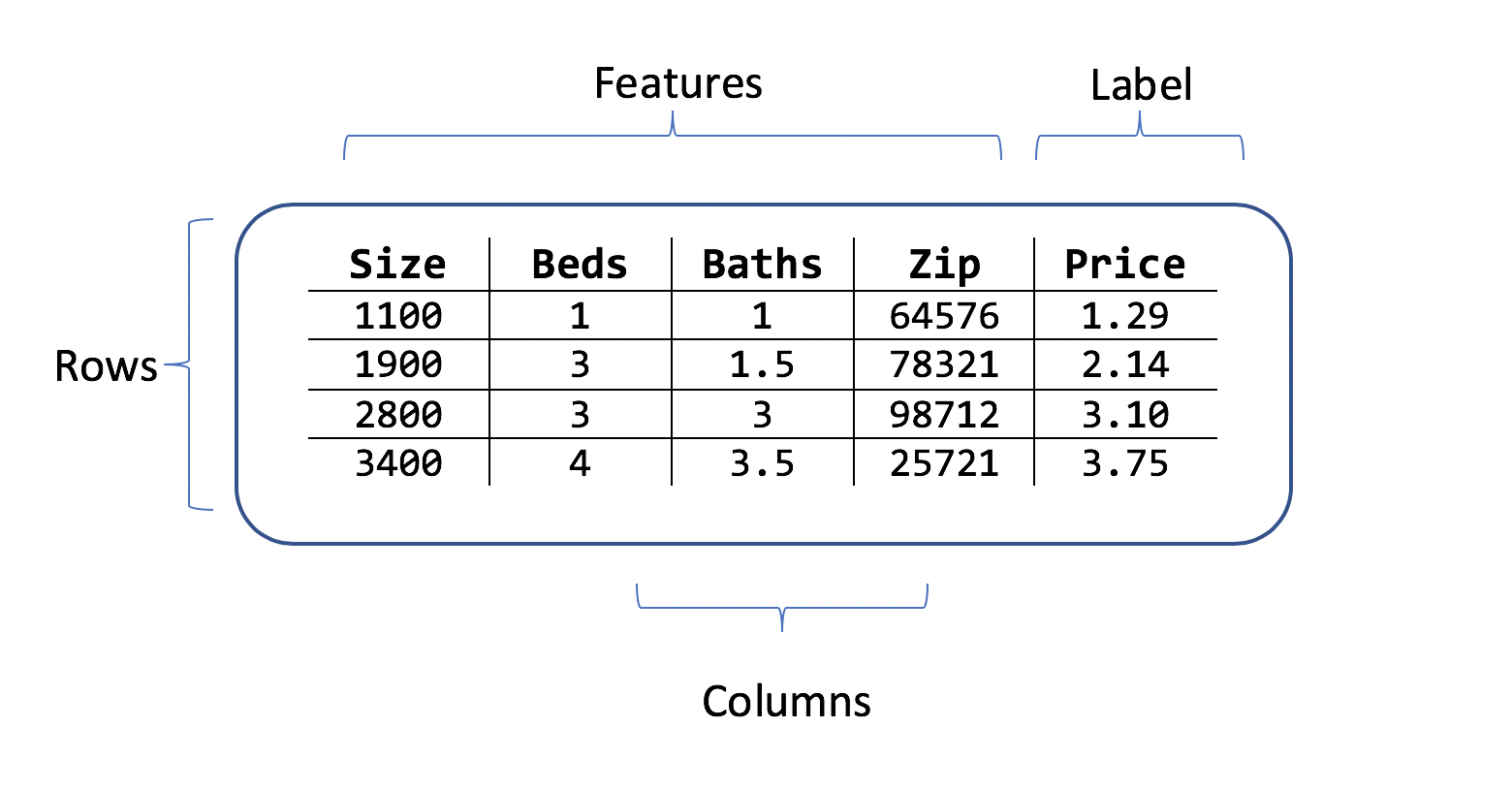
Choisir le résultat à prédire (étiquette)
Un jeu de données est une table de lignes d’exemples et de colonnes d’attributs pour l’entraînement. Chaque ligne a :
- une étiquette (l’attribut que vous voulez prédire)
- Des caractéristiques (attributs utilisés comme entrées pour prédire l’étiquette)
Pour le scénario de prédiction de prix d’une maison, les caractéristiques peuvent être :
- La superficie de la maison
- Le nombre de chambres et de salles de bain
- Le code postal
L’étiquette est l’historique des prix des maisons pour cette ligne de valeurs correspondant à la superficie, aux chambres et aux salles de bain, et au code postal.
Exemples de jeux de données
Si vous n’avez pas encore vos propres données, essayez un de ces jeux de données :
| Scénario | Exemple | Données | Étiquette | Fonctionnalités |
|---|---|---|---|---|
| classification ; | Prédire les anomalies des ventes | Données de ventes de produits | Ventes de produits | Month |
| Prédire le sentiment des commentaires de sites web | Données de commentaires de site web | Étiquette (0 quand le sentiment est négatif, 1 quand il est positif) | Commentaire, Année | |
| Prédire les transactions de carte de crédit frauduleuses | Données de carte de crédit | Classe (1 en cas de fraude, sinon 0) | Quantité, V1-V28 (caractéristiques anonymisées) | |
| Prédire le type de problème dans un dépôt GitHub | Données de problèmes GitHub | Domaine | Titre, Description | |
| Prédiction de valeur | Prédire le prix des courses des taxis | Données de courses de taxi | Fare | Heure, distance du trajet |
| Classification d’images | Prédire la catégorie d’une fleur | Images de fleurs | Le type de fleur : marguerite, pissenlit, roses, tournesols, tulipes | Les données de l’image elles-mêmes |
| Recommandation | Prédire les films que quelqu’un va aimer | Évaluations de films | Utilisateurs, Films | Évaluations |
Former
Une fois que vous avez sélectionné votre scénario, votre environnement, vos données et votre étiquette, Model Builder entraîne le modèle.
Qu’est-ce que l’entraînement ?
L’entraînement est un processus automatique par lequel Model Builder apprend à votre modèle comment répondre aux questions de votre scénario. Une fois entraîné, votre modèle peut faire des prédictions avec des données en entrée qu’il n’avait pas vues avant. Par exemple, si vous prédisez des prix de maisons et qu’une nouvelle maison apparaît sur le marché, vous pouvez prévoir son prix de vente.
Comme Model Builder utilise le Machine Learning automatisé (AutoML), il ne nécessite aucune entrée ou optimisation de votre part pendant l’entraînement.
Combien de temps doit durer l’entraînement ?
Model Builder utilise AutoML pour explorer plusieurs modèles afin de vous trouver le modèle le plus performant.
Des périodes d’entraînement plus longues permettent à AutoML d’explorer davantage de modèles avec une plage de paramètres plus large.
Le tableau ci-dessous résume la durée moyenne nécessaire pour obtenir de bonnes performances pour une suite d’exemples de jeux de données sur une machine locale.
| Taille du jeu de données | Durée moyenne d’entraînement |
|---|---|
| 0-10 Mo | 10 s |
| 10-100 Mo | 10 min |
| 100-500 Mo | 30 min |
| 500 - 1 Go | 60 min |
| + de 1 Go | + de 3 heures |
Ces chiffres sont uniquement à titre indicatif. La durée exacte de l’entraînement dépend des éléments suivants :
- Le nombre de caractéristiques (colonnes) utilisées comme entrée pour le modèle
- Type des colonnes.
- La tâche ML
- Les performances du processeur, du disque et de la mémoire de la machine utilisée pour la formation
Il est généralement conseillé d’utiliser plus de 100 lignes comme jeux de données ; les jeux de données avec moins de lignes peuvent ne produire aucun résultat.
Évaluer
L’évaluation est le processus de mesure de la qualité de votre modèle. Model Builder utilise le modèle entraîné pour faire des prédictions avec de nouvelles données de test, puis mesure la qualité des prédictions.
Model Builder divise les données d’entraînement en un jeu d’entraînement et un jeu de test. Les données d’entraînement (80 %) sont utilisées pour entraîner votre modèle et les données de test (20 %) sont conservées à part pour évaluer votre modèle.
Comment faire pour améliorer les performances de mon modèle ?
Un scénario est mappé à une tâche de machine learning. Chaque tâche ML a son propre ensemble de métriques d’évaluation.
Prédiction de valeur
La métrique par défaut pour les problèmes de prédiction de valeur est RSquared, qui est la valeur des plages RSquared comprises entre 0 et 1. 1 est la meilleure valeur possible : en d’autres termes, plus la valeur de RSquared est proche de 1, plus votre modèle est performant.
D’autres métriques, comme la perte absolue, la perte quadratique et la perte RMS, peuvent être utilisées pour comprendre les performances de votre modèle et le comparer à d’autres modèles de prédiction de valeur.
Classification (2 catégories)
La métrique par défaut pour les problèmes de classification est la justesse. La justesse définit la proportion de prédictions correctes faites par votre modèle par rapport au jeu de données de test. Plus elle est proche de 100 % ou de 1,0, plus elle est bonne.
D’autres métriques sont produites, comme Aire sous la courbe (AUC), qui mesure le taux de vrais positifs par rapport au taux de faux positifs, et qui doit être supérieure à 0,50 pour que les modèles soient acceptables.
Des métriques supplémentaires, comme le score F1, peuvent être utilisées pour contrôler l’équilibre entre Justesse et Rappel.
Classification (plus de 3 catégories)
La métrique par défaut pour la classification multiclasse est la microjustesse. Plus la microjustesse est proche de 100 % ou 1,0, plus elle est bonne.
Une autre métrique importante pour la classification multiclasse est la macrojustesse : de façon similaire à la microjustesse, plus elle est proche de 1,0, plus elle est bonne. Une bonne façon de se représenter ces deux types de justesse est :
- Microjustesse : Combien de fois un ticket entrant est-il classé dans la bonne équipe ?
- Macrojustesse : Pour une équipe moyenne, combien de fois un ticket entrant est-il correct pour son équipe ?
Plus d’informations sur les métriques d’évaluation
Pour plus d’informations, consultez Métriques d’évaluation des modèles.
Améliorer
Si le score de performances de votre modèle n’est pas aussi bon que souhaité, vous pouvez :
Entraîner sur une période de temps plus longue. Avec plus de temps, le moteur Machine Learning automatisé expérimente plus d’algorithmes et de paramètres.
Ajouter des données. Parfois, la quantité de données n’est pas suffisante pour entraîner un modèle Machine Learning de haute qualité. C’est particulièrement vrai pour les jeux de données qui ont un petit nombre d’exemples.
Équilibrer vos données. Pour les tâches de classification, vérifiez que le jeu d’entraînement est équilibré entre les différentes catégories. Par exemple, si vous avez quatre classes pour 100 exemples d’entraînement et que les deux premières classes (étiquette1 et étiquette2) sont utilisées pour 90 enregistrements, mais que les deux autres (étiquette3 et étiquette4) sont utilisées seulement sur les 10 enregistrements restants, l’absence de données équilibrées peut faire que votre modèle aura du mal à prédire correctement étiquette3 ou étiquette4.
Utiliser
Après la phase d’évaluation, Model Builder génère un fichier de modèle et du code que vous pouvez utiliser pour ajouter le modèle à votre application. Les modèles ML.NET sont enregistrés sous la forme d’un fichier zip. Le code pour charger et utiliser votre modèle est ajouté en tant que nouveau projet dans votre solution. Model Builder ajoute également un exemple d’application console que vous pouvez exécuter pour voir votre modèle en action.
En outre, Model Builder vous donne la possibilité de créer des projets qui consomment votre modèle. Actuellement, Model Builder crée les projets suivants :
- Application console : crée une application console .NET pour faire des prédictions à partir de votre modèle.
- API web : Crée une API web ASP.NET Core qui vous permet de consommer votre modèle sur Internet.
Quelle est l’étape suivante ?
Installez l’extension Visual Studio Model Builder.
Essayez le scénario de prédiction des prix ou un autre scénario de régression.
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour