Concepts de base
Quand Metrics Advisor sera-t-il déconseillé ?
Depuis le 20 septembre 2023, vous ne pouvez plus créer de ressources Metrics Advisor. Le service Metrics Advisor sera mis hors service le 1er octobre 2026.
Qu’est-ce que les données de séries chronologiques multidimensionnelles ?
Consultez la définition de la Métrique multidimensionnelle dans le glossaire.
Quelle quantité de données est nécessaire pour que Metrics Advisor démarrent la détection des anomalies ?
Au minimum, un point de données peut déclencher la détection d’anomalie. Toutefois, cela n’apporte pas la meilleure précision. Le service envisage une fenêtre de points de données précédents en utilisant la valeur que vous avez spécifiée comme règle de remplissage lors de la création du flux de données.
Nous vous recommandons d’avoir des données avant le timestamp sur lequel vous souhaitez effectuer la détection. En fonction de la granularité de vos données, la quantité de données recommandée varie comme indiqué ci-dessous.
| Granularité | Quantité de données recommandée pour la détection |
|---|---|
| moins de 5 minutes | 4 jours de données |
| de 5 minutes à 1 jour | 28 jours de données |
| de plus d’1 jour à 31 jours | 4 ans de données |
| plus de 31 jours | 48 jours de données |
Quelles sont les données traitées par le Metrics Advisor et comment les données sont-elles conservées ?
- Metrics Advisor traite les données de série chronologique collectées à partir de la source de données d’un client. Les données historiques sont utilisées pour la sélection du modèle et déterminent la limite de données attendue.
- Les données de série chronologique du client et les résultats de l’inférence seront stockés dans le service. Metrics Advisor ne stocke pas ou ne traite pas les données client situées en dehors de la région dans laquelle le client déploie l’instance de service.
Pourquoi Metrics Advisor ne détecte-t-il pas les anomalies à partir des données historiques ?
Metrics Advisor est conçu pour détecter les données de streaming en direct. Il existe une limitation de la longueur maximale des données d’historique que le service examinera pour exécuter la détection des anomalies. Cela signifie que seuls les points de données après un timestamp précédent donné auront des résultats de détection d’anomalie. Ce timestamp précédent dépend de la granularité de vos données.
En fonction de la granularité de vos données, les longueurs des données historiques qui auront des résultats de détection d’anomalie sont les suivantes.
| Granularité | Longueur maximale des données d’historique pour la détection d’anomalie |
|---|---|
| moins de 5 minutes | heure d’intégration : 13 heures |
| de 5 minutes à moins de 1 heure | heure d’intégration : 4 heures |
| de 1 heure à moins de 1 jour | heure d’intégration : 14 heures |
| 1 jour | heure d’intégration : 28 heures |
| de plus d’1 jour à moins de 31 jours | heure d’intégration : 2 heures |
| plus de 31 jours | heure d’intégration : 24 heures |
Quelles sont les limites de conservation des données et de Metrics Advisor ?
- Conservation des données : Metrics Advisor conserve au maximum 10 000 intervalles de temps (qu’est-ce qu’un intervalle ?) en comptant à partir de l’horodatage actuel, que des données soient disponibles ou non. Les données qui tombent en dehors de la fenêtre seront supprimées. Mappage de la conservation des données en nombre de jours pour différentes granularités de métriques.
| Granularité(min) | Rétention(jour) |
|---|---|
| 1 | 6,94 |
| 5 | 34,72 |
| 15 | 104,1 |
| 60(=horaire) | 416,67 |
| 1 440(=quotidienne) | 10 000 |
- Limite du nombre maximal de séries chronologiques dans une même métrique :
Il peut y avoir plusieurs dimensions dans une métrique, et chaque dimension peut avoir plusieurs valeurs. La combinaison maximale de dimensions pour une métrique ne doit pas dépasser 100 000.
- Les administrateurs de ressources Metrics Advisor et les propriétaires des flux de données seront avertis lorsque la limite de 80 % sera atteinte sur la page de détail du flux de données.
- Si la métrique a dépassé la limite, le flux de données sera suspendu et attendra que les clients effectuent des actions. Il est suggéré de diviser le flux de données en plusieurs flux de données en utilisant le filtrage.
- Limite du nombre maximum de points de données stockés dans une instance Metrics Advisor :
Metrics Advisor compte le total des points de données de tous les flux de données qui ont été intégrés à l’instance à partir du premier timestamp d’ingestion. Le nombre maximum de points de données pouvant être stockés dans une instance Metrics Advisor est de 2 milliards.
- Les administrateurs de ressources Metrics Advisor et tous les utilisateurs seront avertis lorsque la limite de 80 % sera atteinte sur la page de liste des flux de données et via la page d’ajout de nouveaux flux de données.
- Si le total des points de données a dépassé la limite, tous les flux de données seront suspendus et l’intégration de nouveaux flux sera également bloquée. Il est suggéré de supprimer les flux de données inutilisés ou de créer une nouvelle ressource Metrics Advisor dans votre abonnement.
Pourquoi ne puis-je pas me connecter à Metrics Advisor ? Le message d’erreur indique « La ressource est désactivée en raison d’une inactivité de 90 jours »
Il existe deux cas où une ressource est désactivée :
- Une ressource Metrics Advisor est créée, mais aucun flux de données n’a été intégré dans les 90 jours. La ressource sera désactivée après 90 jours en raison de l’inactivité.
- Si un ou plusieurs flux de données ont été créés mais qu’aucune nouvelle donnée n’est ingérée dans Metrics Advisor, le service entre en mode inactif sans aucune donnée à traiter. Le système va toujours essayer de récupérer régulièrement des données à partir de la source en fonction de la granularité des métriques. Toutefois, si aucune donnée n’est disponible ou qu’il n’y a aucune série chronologique unique à traiter pendant une période de 90 jours consécutifs, la ressource sera désactivée. Toutes les données historiques associées à la ressource seront perdues lorsqu’elles sont désactivées.
Si vous souhaitez redémarrer l’utilisation, il est recommandé de créer une nouvelle ressource et de supprimer l’ancienne.
Comment détecter des mines et pixels indépendants du périphérique comme des anomalies ?
Si des seuils définitifs sont prédéfinis, vous pouvez définir manuellement le « seuil définitif » dans configurations de la détection d’anomalie. S’il n’y a aucun seuil, vous pouvez utiliser la « détection intelligente » qui est alimentée par l’intelligence artificielle. Pour plus d’informations, reportez-vous à l’ajustement de la configuration de détection.
Comment faire détecter la non-conformité avec les modèles standard (saisonnier) comme des anomalies ?
La « Détection intelligente » peut apprendre le modèle de vos données, y compris les modèles saisonniers. Elle détecte ensuite les points de données qui ne sont pas conformes aux modèles standard comme des anomalies. Pour plus d’informations, reportez-vous à l’ajustement de la configuration de détection.
Metrics Advisor prend-il en charge les sources de données qui se trouvent derrière un réseau virtuel ?
Non, Metrics Advisor ne prend actuellement pas en charge les sources de données qui se trouvent derrière un réseau virtuel.
Comment détecter les lignes plates comme des anomalies ?
Si vos données sont normalement assez instables et fluctuent beaucoup et que vous souhaitez être alerté lorsqu’elles deviennent trop stables ou qu’elles se transforment en une ligne plate, le « Seuil de modification » peut être configuré pour détecter ces points de données lorsque la modification est trop légère. Pour plus d’informations, consultez les configurations de détection d’anomalie.
Comment configurer des paramètres de messagerie et activer les alertes par e-mail ?
Un utilisateur doté de privilèges d’administrateur d’abonnement ou d’administrateur de groupe de ressources a besoin d’accéder à la ressource Metrics Advisor créée dans le portail Azure, puis de sélectionner l’onglet Contrôle d’accès (IAM) .
Sélectionnez Ajouter des attributions de rôle.
Sélectionnez un rôle Administrateur Metrics Advisor Cognitive Services, puis sélectionnez votre compte comme dans l’image ci-dessous.
Sélectionnez le bouton Enregistrer et vous êtes ajouté en tant qu’administrateur de la ressource Metrics Advisor. Toutes les actions ci-dessus doivent être effectuées par un administrateur d’abonnement ou un administrateur de groupe de ressources.
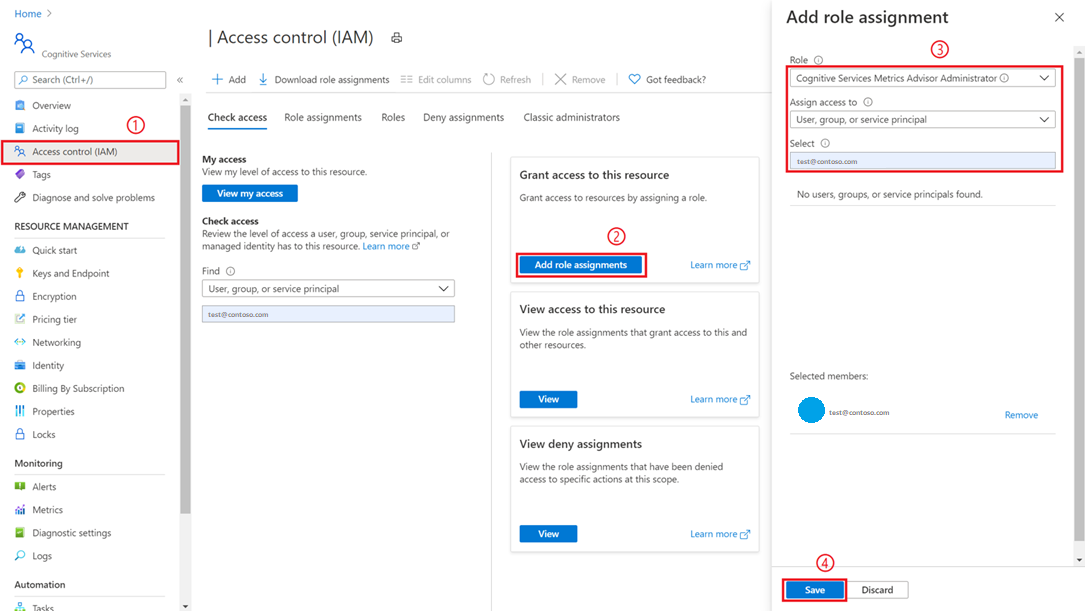
La propagation des autorisations peut prendre jusqu’à une minute. Ensuite, sélectionnez votre espace de travail Metrics Advisor, puis sélectionnez l’option Paramètre de messagerie dans le volet de navigation gauche. Renseignez les éléments nécessaires, en particulier les informations relatives au protocole SMTP.
Sélectionnez Enregistrer et vous avez terminé de configurer la messagerie. Vous pouvez créer des hooks et vous abonner à des anomalies de métrique pour obtenir des alertes en quasi-temps réel.

Concepts avancés
Comment Metrics Advisor crée-t-il un arbre de diagnostic pour les métriques multidimensionnelles ?
Une métrique peut être fractionnée en plusieurs séries chronologiques par dimensions. Par exemple, la métrique Response latency est surveillée pour tous les services appartenant à l’équipe. La catégorie Service peut être utilisée comme dimension pour enrichir la métrique, de sorte que Response latency est fractionnée par Service1, Service2, etc. Chaque service pouvant être déployé sur différents ordinateurs dans plusieurs centres de données, la métrique peut être divisée davantage par Machine et Data center.
| Service | Centre de données | Machine |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
À partir de la Response latency totale, nous pouvons explorer la mesure au niveau du détail par Service, Data center et Machine. Toutefois, il est peut-être plus judicieux pour les propriétaires de service d’utiliser le chemin d’accès Service ->Data center ->Machine, ou plus logique pour les ingénieurs d’infrastructure d’utiliser le chemin d’accès Data Center ->Machine ->Service. Tout dépend des besoins professionnels de vos utilisateurs.
Dans Metric Advisor, les utilisateurs peuvent spécifier n’importe quel chemin d’accès qu’ils veulent explorer au niveau du détail ou dont ils veulent remonter à partir d’un nœud de la topologie hiérarchique. Plus précisément, la topologie hiérarchique est un graphe orienté acyclique plutôt qu’une arborescence. Il existe une topologie hiérarchique complète qui se compose de toutes les combinaisons de dimensions potentielles, comme celle-ci :

En théorie, si la dimension Service a Ls valeurs distinctes, que la dimension Data center a Ldc valeurs distinctes et que la dimension Machine a Lm valeurs distinctes, alors il peut y avoir (Ls + 1) * (Ldc + 1) * (Lm + 1) combinaisons de dimensions dans la topologie hiérarchique.
Mais généralement, toutes les combinaisons de dimensions ne sont pas valides, ce qui peut réduire considérablement la complexité. Actuellement, si les utilisateurs agrègent eux-mêmes la métrique, nous ne limitons pas le nombre de dimensions. Si vous devez utiliser les fonctionnalités de cumul fournies par Metrics Advisor, le nombre de dimensions ne devrait pas être supérieur à 6. Toutefois, nous limitons à moins de 10 000 le nombre de séries chronologiques développées par des dimensions pour une métrique.
L’outil Arbre de diagnostic de la page de diagnostics affiche uniquement les nœuds dans lesquels une anomalie a été détectée, plutôt que la topologie entière. Cela vous permet de vous concentrer sur le problème actuel. Il se peut également qu’il ne montre pas toutes les anomalies dans la métrique et affiche plutôt les principales anomalies en fonction de leur contribution. De cette façon, nous pouvons rapidement déterminer l’impact, la portée et le chemin de propagation des données anormales. Cela réduit considérablement le nombre d’anomalies sur lesquelles nous devons nous concentrer et aide les utilisateurs à comprendre et à localiser leurs problèmes clés.
Par exemple, lorsqu’une anomalie se produit sur Service = S2 | Data Center = DC2 | Machine = M5, l’écart de l’anomalie a un impact sur le nœud parent Service= S2 qui a également détecté l’anomalie, mais l’anomalie ne concerne pas l’ensemble du centre de données au niveau de DC2 ni tous les services sur M5. L’arborescence de l’incident est générée comme dans la capture d’écran ci-dessous : la première anomalie est capturée sur Service = S2 et la cause racine peut être analysée dans deux chemins qui mènent tous deux à Service = S2 | Data Center = DC2 | Machine = M5.
