Copier et transformer des données dans la Base de données Azure pour PostgreSQL à l’aide d’Azure Data Factory
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article indique comment utiliser l’activité de copie dans Azure Data Factory et les pipelines Synapse Analytics pour copier des données depuis et vers la Base de données Azure pour PostgreSQL, et utiliser Data Flow pour transformer les données dans la Base de données Azure pour PostgreSQL. Pour en savoir plus, lisez les articles d’introduction d’Azure Data Factory et d’Azure Synapse Analytics.
Ce connecteur est spécialisé pour le service Azure Database pour PostgreSQL. Pour copier des données à partir d’une base de données PostgreSQL générique locale ou située dans le cloud, utilisez le connecteur PostgreSQL.
Fonctionnalités prises en charge
Ce connecteur Azure Database pour PostgreSQL est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR | Point de terminaison privé managé |
|---|---|---|
| Activité de copie (source/récepteur) | ✓ | |
| Mappage de flux de données (source/récepteur) | 0 | ✓ |
| Activité de recherche | ✓ |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Les trois activités fonctionnent sur toutes les options de déploiement Azure Database pour PostgreSQL :
Prise en main
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créer un service lié à Azure Database pour PostgreSQL en utilisant l'interface utilisateur
Utilisez les étapes suivantes pour créer un service lié à Azure Database pour MySQL dans l’interface utilisateur du portail Azure.
Accédez à l’onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse et sélectionnez Services liés, puis cliquez sur Nouveau :
Recherchez PostgreSQL et sélectionnez le connecteur Azure Database pour PostgreSQL.
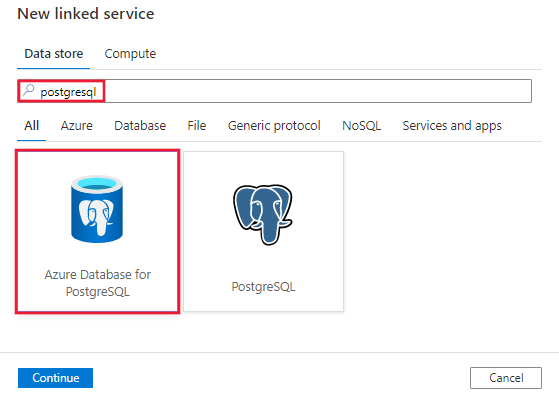
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
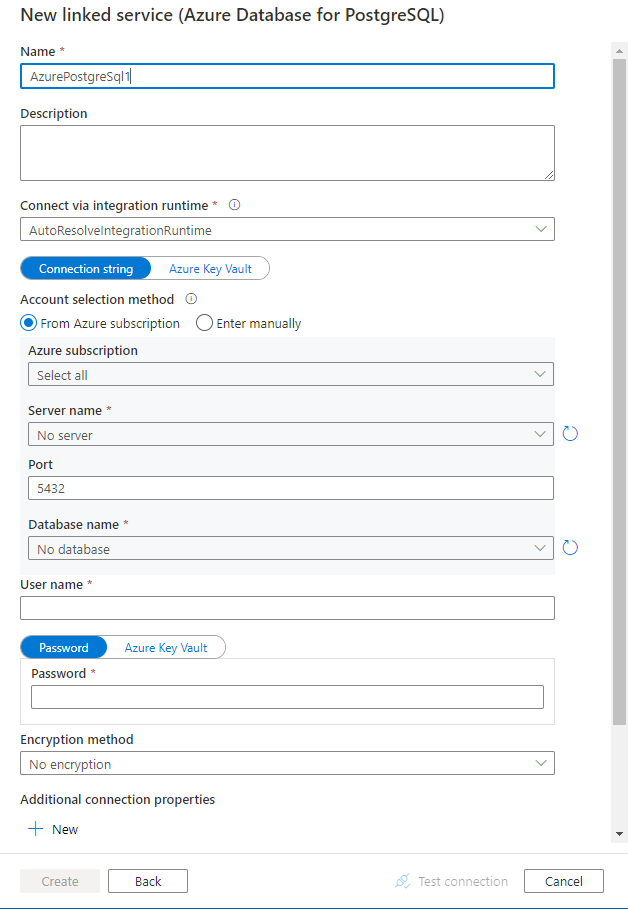
Informations de configuration des connecteurs
Les sections suivantes détaillent les propriétés utilisées pour définir des entités Data Factory propres au connecteur Azure Database pour PostgreSQL.
Propriétés du service lié
Les propriétés suivantes sont prises en charge pour le service lié Azure Database pour PostgreSQL :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type doit être définie sur : AzurePostgreSql. | Oui |
| connectionString | Chaîne de connexion ODBC permettant de se connecter à Azure Database pour PostgreSQL. Vous pouvez également définir un mot de passe dans Azure Key Vault et extraire la configuration password de la chaîne de connexion. Pour plus d’informations, consultez les exemples suivants et Stocker des informations d’identification dans Azure Key Vault. |
Oui |
| connectVia | Cette propriété correspond au runtime d’intégration à utiliser pour la connexion à la banque de données. Vous pouvez utiliser runtime d’intégration Azure ou un runtime d’intégration auto-hébergé (si votre banque de données se trouve dans un réseau privé). À défaut de spécification, le runtime d’intégration Azure par défaut est utilisé. | Non |
Voici un exemple de chaîne de connexion typique : Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>. Selon votre cas de figure, vous pouvez définir d’autres propriétés :
| Propriété | Description | Options | Obligatoire |
|---|---|---|---|
| EncryptionMethod (EM) | La méthode utilisée par le pilote pour chiffrer les données envoyées entre le pilote et le serveur de base de données. Par exemple : EncryptionMethod=<0/1/6>; |
0 (aucun chiffrement) (par défaut) / 1 (SSL) / 6 (RequestSSL) | Non |
| ValidateServerCertificate (VSC) | Détermine si le pilote valide le certificat envoyé par le serveur de base de données lorsque le chiffrement SSL est activé (EncryptionMethod = 1). Par exemple : ValidateServerCertificate=<0/1>; |
0 (désactivé) (par défaut) / 1 (activé) | Non |
Exemple :
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
Exemple :
Stockage du mot de passe dans Azure Key Vault
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
Propriétés du jeu de données
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données. Cette section fournit la liste des propriétés qu’Azure Database pour PostgreSQL prend en charge dans les jeux de données.
Pour copier des données d’Azure Database pour PostgreSQL, affectez la valeur AzurePostgreSqlTable à la propriété type du jeu de données. Les propriétés prises en charge sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur AzurePostgreSqlTable | Oui |
| tableName | Nom de la table | Non (si « query » dans la source de l’activité est spécifié) |
Exemple :
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
Propriétés de l’activité de copie
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition des activités, consultez Pipelines et activités. Cette section fournit la liste des propriétés prises en charge par une source Azure Database pour PostgreSQL.
Azure Database pour PostgreSQL en tant que source
Pour copier des données d’Azure Database pour PostgreSQL, affectez la valeur AzurePostgreSqlSource au type source de l’activité de copie. Les propriétés prises en charge dans la section source de l’activité de copie sont les suivantes :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source de l’activité de copie doit être définie sur AzurePostgreSqlSource | Oui |
| query | Utiliser la requête SQL personnalisée pour lire les données. Par exemple, SELECT * FROM mytable ou SELECT * FROM "MyTable". Notez que dans PostgreSQL, le nom de l’entité est traité comme insensible à la casse s’il n’est pas placé entre guillemets. |
Non (si la propriété tableName du jeu de données est spécifiée) |
| partitionOptions | Spécifie les options de partitionnement des données utilisées pour charger des données à partir d’Azure SQL Database. Les valeurs autorisées sont les suivantes : None (valeur par défaut), PhysicalPartitionsOfTable et DynamicRange. Lorsqu’une option de partition est activée (autrement dit, pas None), le degré de parallélisme pour charger simultanément des données à partir d’une instance Azure SQL Database est contrôlé par le paramètre parallelCopies de l’activité de copie. |
Non |
| partitionSettings | Spécifiez le groupe de paramètres pour le partitionnement des données. S’applique lorsque l’option de partitionnement n’est pas None. |
Non |
Sous partitionSettings : |
||
| partitionNames | La liste des partitions physiques qui doivent être copiées. S’applique lorsque l’option de partitionnement est PhysicalPartitionsOfTable. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfTabularPartitionName dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL. |
Non |
| partitionColumnName | Spécifiez le nom de la colonne source en type entier ou date/DateHeure (int, smallint, bigint, date, timestamp without time zone, timestamp with time zoneou time without time zone) qu’utilisera le partitionnement par plages de valeurs pour la copie en parallèle. S’il n’est pas spécifié, la clé primaire de la table sera automatiquement détectée et utilisée en tant que colonne de partition.S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionColumnName dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL. |
Non |
| partitionUpperBound | Valeur maximale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionUpbound dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL. |
Non |
| partitionLowerBound | Valeur minimale de la colonne de partition à partir de laquelle copier des données. S’applique lorsque l’option de partitionnement est DynamicRange. Si vous utilisez une requête pour récupérer des données sources, utilisez ?AdfRangePartitionLowbound dans la clause WHERE. Pour obtenir un exemple, consultez la section Copier en parallèle à partir de la Base de données pour PostgreSQL. |
Non |
Exemple :
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Azure Database pour PostgreSQL en tant que récepteur
Pour copier des données vers Azure Database pour PostgreSQL, les propriétés suivantes sont prises en charge dans la section sink de l’activité de copie :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du récepteur d’activité de copie doit être définie sur AzurePostgreSQLSink. | Oui |
| preCopyScript | Spécifiez une requête SQL pour l’activité de copie à exécuter avant d'écrire des données dans Azure Database pour PostgreSQL à chaque exécution. Vous pouvez utiliser cette propriété pour nettoyer des données préchargées. | Non |
| writeMethod | Méthode utilisée pour écrire des données dans Azure Database pour PostgreSQL. Les valeurs autorisées sont CopyCommand (valeur par défaut et la plus performante) et BulkInsert. |
Non |
| writeBatchSize | Nombre de lignes chargées dans Azure Database pour PostgreSQL par lot. La valeur autorisée est un entier qui représente le nombre de lignes. |
Non (valeur par défaut : 1 000 000) |
| writeBatchTimeout | Temps d’attente pour que l’opération d’insertion de lot soit terminée avant d’expirer. Les valeurs autorisées sont des intervalles de temps. Exemple : 00:30:00 (30 minutes). |
Non (valeur par défaut : 00:30:00) |
Exemple :
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Copie parallèle à partir de la Base de données Azure pour PostgreSQL
Le connecteur de la Base de données Azure dans l’activité de copie propose un partitionnement de données intégré pour copier des données en parallèle. Vous trouverez des options de partitionnement de données dans l’onglet Source de l’activité de copie.
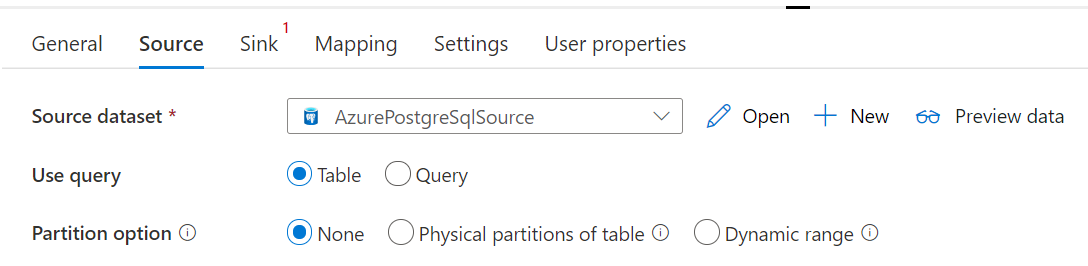
Lorsque vous activez la copie partitionnée, l’activité de copie exécute des requêtes en parallèle sur la Base de données Azure pour la source PostgreSQL afin de charger des données par partitions. Le degré de parallélisme est contrôlé via le paramètre parallelCopies sur l’activité de copie. Par exemple, si vous définissez parallelCopies sur quatre, le service génère et exécute simultanément quatre requêtes en fonction de l’option de partition et des paramètres que vous avez spécifiés, et chaque requête récupère une partie des données à partir de votre Base de données Azure pour PostgreSQL.
Il vous est recommandé d’activer la copie en parallèle avec partitionnement des données, notamment lorsque vous chargez une grande quantité de données à partir de votre Base de données Azure pour PostgreSQL. Voici quelques suggestions de configurations pour différents scénarios. Lors de la copie de données dans un magasin de données basé sur un fichier, il est recommandé d’écrire les données dans un dossier sous la forme de plusieurs fichiers (spécifiez uniquement le nom du dossier). Les performances seront meilleures qu’avec l’écriture de données dans un seul fichier.
| Scénario | Paramètres suggérés |
|---|---|
| Chargement complet à partir d’une table volumineuse, avec des partitions physiques. | Option de partition : Partitions physiques de la table. Pendant l’exécution, le service détecte automatiquement les partitions physiques et copie les données par partition. |
| Chargement complet d’une table volumineuse, sans partitions physiques, avec une colonne entière pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Si la valeur n’est pas spécifiée, la colonne de la clé primaire est utilisée. |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, avec des partitions physiques. | Option de partition : Partitions physiques de la table. Requête: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>.Nom de la partition : Spécifiez le(s) nom(s) de partition à copier. Si ce n’est pas spécifié, le service détecte automatiquement les partitions physiques de la table que vous avez spécifiée dans le jeu de données PostgreSQL. Pendant l’exécution, le service remplace ?AdfTabularPartitionName par le nom réel de la partition et l’envoie à Azure Database pour PostgreSQL. |
| Chargement d’une grande quantité de données à l’aide d’une requête personnalisée, sans partitions physiques, et avec une colonne entière pour le partitionnement des données. | Options de partition : Partition dynamique par spécification de plages de valeurs. Requête: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Colonne de partition : Spécifiez la colonne utilisée pour partitionner les données. Vous pouvez procéder au partitionnement par rapport à la colonne avec le type de données entier ou date/DateHeure. Limite supérieure de partition et limite inférieure de partition : Indiquez si vous souhaitez filtrer le contenu par rapport à la colonne de partition pour récupérer uniquement les données entre les plages inférieure et supérieure. Lors de l’exécution, le service remplace ?AdfRangePartitionColumnName?AdfRangePartitionUpbound, et ?AdfRangePartitionLowbound par le nom réel de la colonne et les plages de valeurs de chaque partition et les envoie à Azure Database pour PostgreSQL. Par exemple, si votre colonne de partition « ID » est définie sur une limite inférieure de 1 et une limite supérieure de 80, avec une copie en parallèle définie sur 4, le service récupère les données via 4 partitions. Les ID sont inclus entre [1,20], [21, 40], [41, 60] et [61, 80], respectivement. |
Meilleures pratiques pour charger des données avec l’option de partition :
- Choisissez une colonne distinctive comme colonne de partition (p. ex. : clé primaire ou clé unique) pour éviter l’asymétrie des données.
- Si la table possède une partition intégrée, utilisez l’option de partition « Partitions physiques de la table » pour obtenir de meilleures performances.
- Si vous utilisez Azure Integration Runtime pour copier des données, vous pouvez définir des « unités d’intégration de données (DIU) » plus grandes (>4) pour utiliser davantage de ressources de calcul. Vérifiez les scénarios applicables ici.
- Le « degré de parallélisme de copie » contrôle le nombre de partitions : un nombre trop élevé nuit parfois aux performances. Il est recommandé de définir ce nombre selon (DIU ou nombre de nœuds d'IR auto-hébergé) * (2 à 4).
Exemple : chargement complet à partir d’une table volumineuse, avec des partitions physiques
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemple : requête avec partition dynamique par spécification de plages de valeurs
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Propriétés du mappage de flux de données
Lors de la transformation de données dans le flux de données de mappage, vous pouvez lire et écrire dans des tables à partir d’Azure Database pour PostgreSQL. Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage. Vous pouvez choisir d’utiliser un jeu de données Azure Database pour PostgreSQL ou un jeu de données inlined en tant que type de source et de récepteur.
Transformation de la source
Le tableau ci-dessous répertorie les propriétés prises en charge par une source Azure Database pour PostgreSQL. Vous pouvez modifier ces propriétés sous l’onglet Options de la source.
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Table de charge de travail | Si vous sélectionnez Table comme entrée, le flux de données extrait toutes les données de la table spécifiée dans le jeu de données. | Non | - | (pour le jeu de données inlined uniquement) tableName |
| Requête | Si vous sélectionnez Requête comme entrée, spécifiez une requête SQL pour extraire des données de la source, qui remplace toute table que vous spécifiez dans le jeu de données. L’utilisation de requêtes est un excellent moyen de réduire le nombre de lignes pour les tests ou les recherches. La clause Order By n’est pas prise en charge, mais vous pouvez définir une instruction SELECT FROM complète. Vous pouvez également utiliser des fonctions de table définies par l’utilisateur. select * from udfGetData() est une fonction UDF dans SQL qui retourne une table que vous pouvez utiliser dans le flux de données. Exemple de requête : select * from mytable where customerId > 1000 and customerId < 2000 ou select * from "MyTable". Notez que dans PostgreSQL, le nom de l’entité est traité comme insensible à la casse s’il n’est pas placé entre guillemets. |
Non | String | query |
| Nom du schéma | Si vous sélectionnez Procédure stockée comme entrée, spécifiez un nom de schéma de la procédure stockée, ou sélectionnez Actualiser pour demander au service de découvrir les noms de schéma. | Non | String | schemaName |
| Procédure stockée | Si vous sélectionnez Procédure stockée comme entrée, spécifiez un nom de procédure stockée pour lire les données de la table source, ou sélectionnez Actualiser pour demander au service de découvrir les noms des procédures. | Oui (si vous sélectionnez Procédure stockée comme entrée) | String | procedureName |
| Paramètres de procédure | Si vous sélectionnez Procédure stockée comme entrée, spécifiez les paramètres d’entrée de la procédure stockée dans l’ordre défini dans la procédure, ou sélectionnez Importer pour importer tous les paramètres de procédure sous la forme @paraName. |
Non | Array | inputs |
| Taille du lot | Spécifiez la taille que doivent avoir les lots créés à partir d’un large volume de données. | Non | Integer | batchSize |
| Niveau d’isolation | Choisissez l’un des niveaux d’isolation suivants : – Lecture validée. – Lecture non validée (par défaut). – Lecture renouvelable. – Sérialisable. – Aucun (ignorer le niveau d’isolation). |
Non | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Exemple de script de source Azure Database pour PostgreSQL
Quand vous utilisez Azure Database pour PostgreSQL comme type de source, le script de flux de données associé est le suivant :
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
Transformation du récepteur
Le tableau ci-dessous répertorie les propriétés prises en charge par un récepteur Azure Database pour PostgreSQL. Vous pouvez modifier ces propriétés sous l’onglet Options du récepteur.
| Name | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Mettre à jour la méthode | Spécifiez les opérations autorisées sur la destination de votre base de données. Par défaut, seules les insertions sont autorisées. Pour mettre à jour, effectuer un upsert ou supprimer des lignes, une transformation de modification de ligne est requise afin de baliser les lignes relatives à ces actions. |
Oui | true ou false |
deletable insertable updateable upsertable |
| Colonnes clés | Pour les mises à jour, les opérations upsert et les suppressions, une ou plusieurs colonnes clés doivent être définies afin de déterminer la ligne à modifier. Le nom de colonne que vous choisissez comme clé sera utilisé dans le cadre des opérations suivantes de mise à jour, d’upsert et de suppression. Vous devez donc choisir une colonne qui existe dans le mappage du récepteur. |
Non | Array | clés |
| Ignorer l’écriture des colonnes clés | Si vous ne souhaitez pas écrire la valeur dans la colonne clé, sélectionnez « Ignorer l’écriture des colonnes clés ». | Non | true ou false |
skipKeyWrites |
| Action table | Détermine si toutes les lignes de la table de destination doivent être recréées ou supprimées avant l’écriture. - Aucun : Aucune action ne sera effectuée sur la table. - Recréer : La table sera supprimée et recréée. Obligatoire en cas de création dynamique d’une nouvelle table. - Tronquer : Toutes les lignes de la table cible seront supprimées. |
Non | true ou false |
recreate truncate |
| Taille du lot | Spécifiez le nombre de lignes écrites dans chaque lot. Les plus grandes tailles de lot améliorent la compression et l’optimisation de la mémoire, mais risquent de lever des exceptions de type mémoire insuffisante lors de la mise en cache des données. | Non | Integer | batchSize |
| Sélectionner le schéma de base de données de l'utilisateur | Par défaut, une table temporaire est créée sous le schéma récepteur en tant que table intermédiaire. Vous pouvez également décocher l’option Utiliser le schéma de récepteur et spécifier à la place un nom de schéma sous lequel Data Factory crée une table intermédiaire pour charger des données en amont et les nettoyer automatiquement une fois l’opération terminée. Vérifiez que vous disposez d’une autorisation de création de table dans la base de données et modifiez l’autorisation sur le schéma. | Non | String | stagingSchemaName |
| Pré et post-scripts SQL | Spécifiez des scripts SQL multilignes qui s’exécutent avant (prétraitement) et après (post-traitement) l’écriture de données dans votre base de données de réception. | Non | String | preSQLs postSQLs |
Conseil
- Il est recommandé de diviser les scripts de commandes par lot uniques contenant plusieurs commandes en plusieurs lots.
- Seules des instructions DDL (Data Definition Language, langage de définition de données) et DML (Data Manipulation Language, langage de manipulation de données) qui retournent un seul nombre de mises à jour peuvent être exécutées dans un lot. Pour en savoir plus, consultez Exécution d’opérations par lot
Activer l’extraction incrémentielle : utilisez cette option pour indiquer à ADF de traiter seulement les lignes qui ont changé depuis la dernière exécution du pipeline.
Colonne incrémentielle : quand vous utilisez la fonctionnalité d’extraction incrémentielle, vous devez choisir la colonne date/heure ou numérique que vous souhaitez utiliser comme filigrane dans votre table source.
Commencer la lecture à partir du début : la définition de cette option avec l’extraction incrémentielle indique à ADF de lire toutes les lignes lors de la première exécution d’un pipeline avec l’extraction incrémentielle activée.
Exemple de script de récepteur Azure Database pour PostgreSQL
Quand vous utilisez Azure Database pour PostgreSQL comme type de récepteur, le script de flux de données associé est le suivant :
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Propriétés de l’activité Lookup
Pour plus d’informations sur les propriétés, consultez Activité de recherche.
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.