Migrer des données d’Amazon S3 vers Azure Data Lake Storage Gen2
S’APPLIQUE À : Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Utilisez les modèles pour migrer des pétaoctets de données composées de centaines de millions de fichiers d’Amazon S3 vers Azure Data Lake Storage Gen2.
Notes
Si vous souhaitez copier un petit volume de données d’AWS S3 vers Azure (par exemple, moins de 10 To), il est plus efficace et plus simple d’utiliser l’outil Copier des données d’Azure Data Factory. Le modèle décrit dans cet article répond amplement à vos besoins.
À propos des modèles de solution
La partition de données est recommandée en particulier lors de la migration de plus de 10 To de données. Pour partitionner les données, utilisez le paramètre « Prefix » pour filtrer les dossiers et les fichiers sur Amazon S3 par nom. Ensuite, chaque travail de copie ADF peut copier une partition à la fois. Vous pouvez exécuter plusieurs tâches de copie ADF simultanément pour un meilleur débit.
Généralement, la migration de données nécessite une migration des données historiques unique et une synchronisation périodique des modifications d’AWS S3 vers Azure. Deux modèles sont abordés ci-dessous. L’un d’eux couvre la migration des données historiques unique et l’autre la synchronisation des modifications d’AWS S3 vers Azure.
Pour que le modèle migre les données historiques d’Amazon S3 vers Azure Data Lake Storage Gen2
Ce modèle (nom du modèle : Migrer les données historiques d’AWS S3 vers Azure Data Lake Storage Gen2) suppose que vous avez écrit une liste de partitions dans une table de contrôle externe dans Azure SQL Database. Il utilise une activité Lookup pour récupérer la liste de partitions à partir de la table de contrôle externe, effectuer une itération sur chaque partition et faire en sorte que chaque travail de copie ADF copie une partition à la fois. Quand un travail de copie s’achève, il utilise une activité StoredProcedure pour mettre à jour l’état de la copie de chaque partition dans la table de contrôle.
Le modèle contient cinq activités :
- L’activité Lookup récupère les partitions qui n’ont pas été copiées dans Azure Data Lake Storage Gen2 à partir d’une table de contrôle externe. Le nom de la table est s3_partition_control_table et la requête utilisée pour charger les données de la table est « SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0 » .
- L’activité ForEach récupère la liste de partitions à partir de l’activité Lookup et itère chaque partition sur l’activité TriggerCopy. Vous pouvez définir le batchCount pour exécuter plusieurs travaux de copie ADF simultanément. Nous en avons défini 2 dans ce modèle.
- L’activité ExecutePipeline exécute le pipeline CopyFolderPartitionFromS3. Nous créons un autre pipeline pour faire en sorte que chaque travail de copie effectue la copie d’une partition. Ainsi, vous pourrez réexécuter facilement le travail de copie qui a échoué pour recharger la partition concernée à partir d’AWS S3. Tous les autres travaux de copie qui chargent d’autres partitions ne seront pas affectés.
- L’activité Copy copie chaque partition d’AWS S3 vers Azure Data Lake Storage Gen2.
- L’activité SqlServerStoredProcedure met à jour l’état de la copie de chaque partition dans la table de contrôle.
Le modèle contient deux paramètres :
- AWS_S3_bucketName est le nom du compartiment sur AWS S3 dans lequel vous souhaitez migrer les données. Si vous souhaitez migrer des données à partir de plusieurs compartiments sur AWS S3, vous pouvez ajouter une colonne dans votre table de contrôle externe pour stocker le nom du compartiment pour chaque partition et mettre à jour votre pipeline pour récupérer les données de cette colonne de façon appropriée.
- Azure_Storage_fileSystem est le nom du système de fichiers sur Azure Data Lake Storage Gen2, vers lequel vous souhaitez migrer les données.
Pour que le modèle copie uniquement les fichiers modifiés d’Amazon S3 vers Azure Data Lake Storage Gen2
Ce modèle (nom du modèle : Copier les données delta d’AWS S3 vers Azure Data Lake Storage Gen2) utilise l’heure de dernière modification de chaque fichier pour copier uniquement les fichiers nouveaux ou mis à jour d’AWS S3 vers Azure. Notez que si vos fichiers ou dossiers ont déjà été partitionnés chronologiquement à l’aide d’informations de date/heure incluses dans leurs noms sur AWS S3 (par exemple, /aaaa/mm/jj/fichier.csv), vous pouvez accéder à ce tutoriel pour connaître l’approche la plus performante pour le chargement incrémentiel de nouveaux fichiers. Ce modèle suppose que vous avez écrit une liste de partitions dans une table de contrôle externe dans Azure SQL Database. Il utilise une activité Lookup pour récupérer la liste de partitions à partir de la table de contrôle externe, effectuer une itération sur chaque partition et faire en sorte que chaque travail de copie ADF copie une partition à la fois. Dès lors qu’un travail de copie commence à copier les fichiers à partir d’AWS S3, il s’appuie sur la propriété LastModifiedTime pour identifier et copier uniquement les fichiers nouveaux ou mis à jour. Quand un travail de copie s’achève, il utilise une activité StoredProcedure pour mettre à jour l’état de la copie de chaque partition dans la table de contrôle.
Le modèle contient sept activités :
- L’activité Lookup récupère les partitions à partir d’une table de contrôle externe. Le nom de la table est s3_partition_delta_control_table et la requête utilisée pour charger les données de la table est « select distinct PartitionPrefix from s3_partition_delta_control_table » .
- L’activité ForEach récupère la liste de partitions à partir de l’activité Lookup et itère chaque partition sur l’activité TriggerDeltaCopy. Vous pouvez définir le batchCount pour exécuter plusieurs travaux de copie ADF simultanément. Nous en avons défini 2 dans ce modèle.
- L’activité ExecutePipeline exécute le pipeline DeltaCopyFolderPartitionFromS3. Nous créons un autre pipeline pour faire en sorte que chaque travail de copie effectue la copie d’une partition. Ainsi, vous pourrez réexécuter facilement le travail de copie qui a échoué pour recharger la partition concernée à partir d’AWS S3. Tous les autres travaux de copie qui chargent d’autres partitions ne seront pas affectés.
- L’activité Lookup récupère l’heure d’exécution du dernier travail de copie à partir de la table de contrôle externe de sorte que les fichiers nouveaux ou mis à jour puissent être identifiés à l’aide de la propriété LastModifiedTime. Le nom de la table est s3_partition_delta_control_table et la requête utilisée pour charger les données de la table est « select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}' and SuccessOrFailure = 1 » .
- L’activité Copy copie uniquement les fichiers nouveaux ou modifiés de chaque partition d’AWS S3 vers Azure Data Lake Storage Gen2. La propriété modifiedDatetimeStart est définie sur l’heure d’exécution du dernier travail de copie. La propriété modifiedDatetimeEnd est définie sur l’heure d’exécution du travail de copie actuel. Notez que l’heure est basée sur le fuseau horaire UTC.
- L’activité SqlServerStoredProcedure met à jour l’état de la copie de chaque partition et copie l’heure d’exécution dans la table de contrôle en cas de réussite. La colonne SuccessOrFailure a la valeur 1.
- L’activité SqlServerStoredProcedure met à jour l’état de la copie de chaque partition et copie l’heure d’exécution dans la table de contrôle en cas d’échec. La colonne SuccessOrFailure a la valeur 0.
Le modèle contient deux paramètres :
- AWS_S3_bucketName est le nom du compartiment sur AWS S3 dans lequel vous souhaitez migrer les données. Si vous souhaitez migrer des données à partir de plusieurs compartiments sur AWS S3, vous pouvez ajouter une colonne dans votre table de contrôle externe pour stocker le nom du compartiment pour chaque partition et mettre à jour votre pipeline pour récupérer les données de cette colonne de façon appropriée.
- Azure_Storage_fileSystem est le nom du système de fichiers sur Azure Data Lake Storage Gen2, vers lequel vous souhaitez migrer les données.
Comment utiliser ces deux modèles de solution
Pour que le modèle migre les données historiques d’Amazon S3 vers Azure Data Lake Storage Gen2
Créez une table de contrôle dans Azure SQL Database pour stocker la liste de partitions d’AWS S3.
Notes
Le nom de la table est s3_partition_control_table. Le schéma de la table de contrôle inclut PartitionPrefix et SuccessOrFailure. PartitionPrefix est le paramètre de préfixe dans S3 pour filtrer les dossiers et les fichiers dans Amazon S3 par nom. SuccessOrFailure est l’état de la copie de chaque partition : 0 signifie que cette partition n’a pas été copiée sur Azure et 1 signifie qu’elle a été correctement copiée sur Azure. 5 partitions sont définies dans la table de contrôle. Par défaut, l’état de la copie de chaque partition est 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Créez une procédure stockée sur la même base de données SQL Azure pour la table de contrôle.
Notes
Le nom de la procédure stockée est sp_update_partition_success. Elle sera appelée par l’activité SqlServerStoredProcedure dans votre pipeline ADF.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOAccédez au modèle Migrer les données historiques d’AWS S3 vers Azure Data Lake Storage Gen2. Entrez les connexions à votre table de contrôle externe, AWS S3 en tant que magasin de source de données et Azure Data Lake Storage Gen2 en tant que magasin de destination. Notez que la table de contrôle externe et la procédure stockée font référence à la même connexion.
Cliquez sur Utiliser ce modèle.
Vous voyez les 2 pipelines et les 3 jeux de données créés comme illustré dans l’exemple suivant :
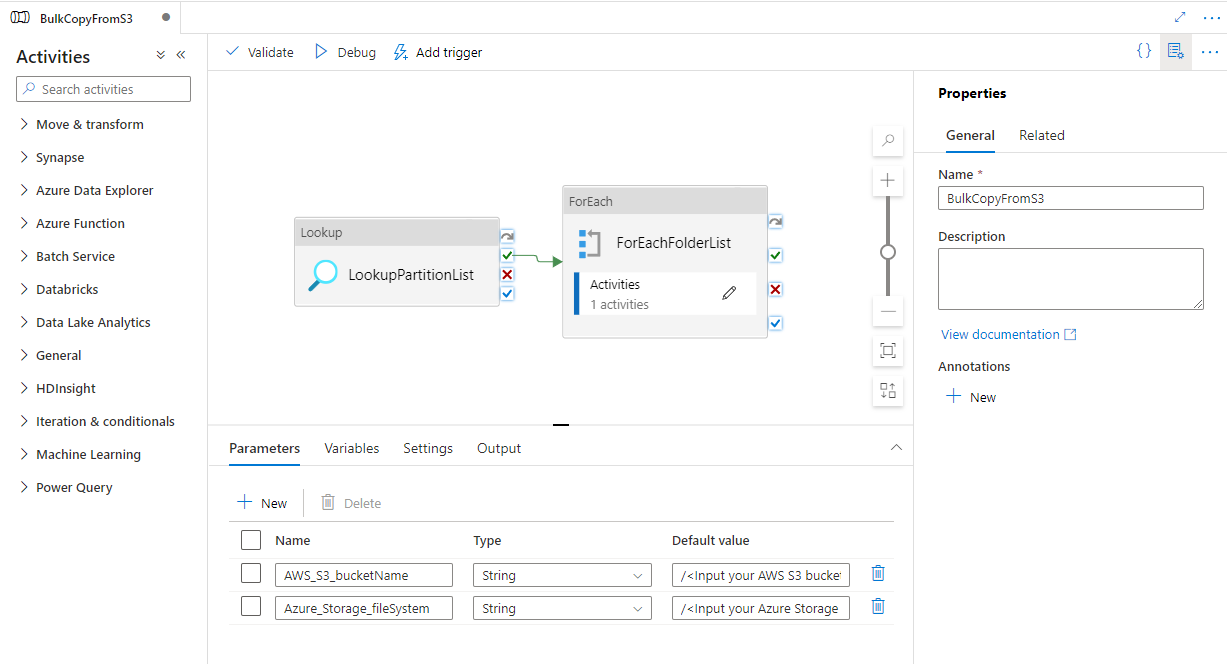
Accédez au pipeline « BulkCopyFromS3 » et sélectionnez Déboguer, puis entrez les paramètres. Ensuite, sélectionnez Finish.
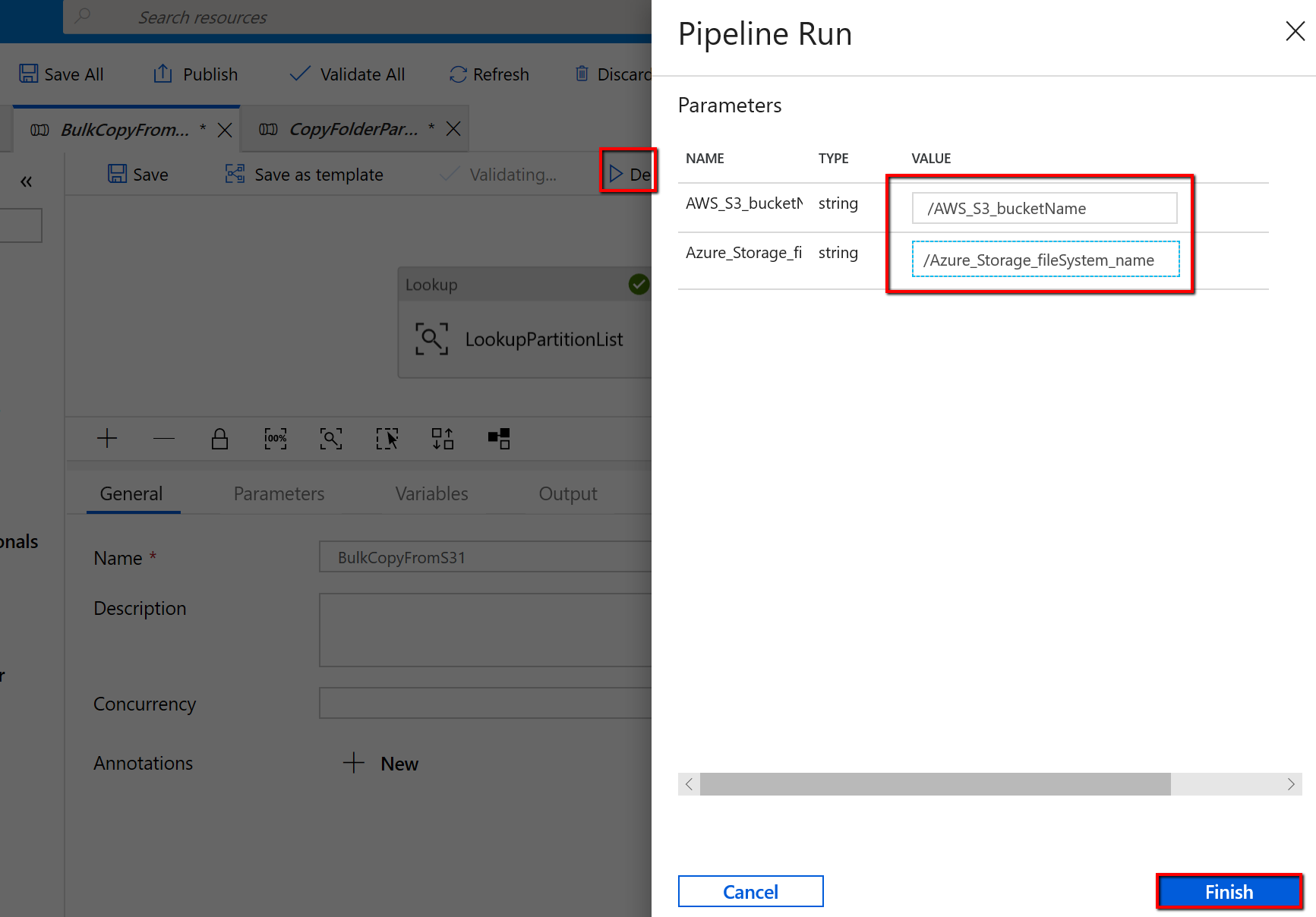
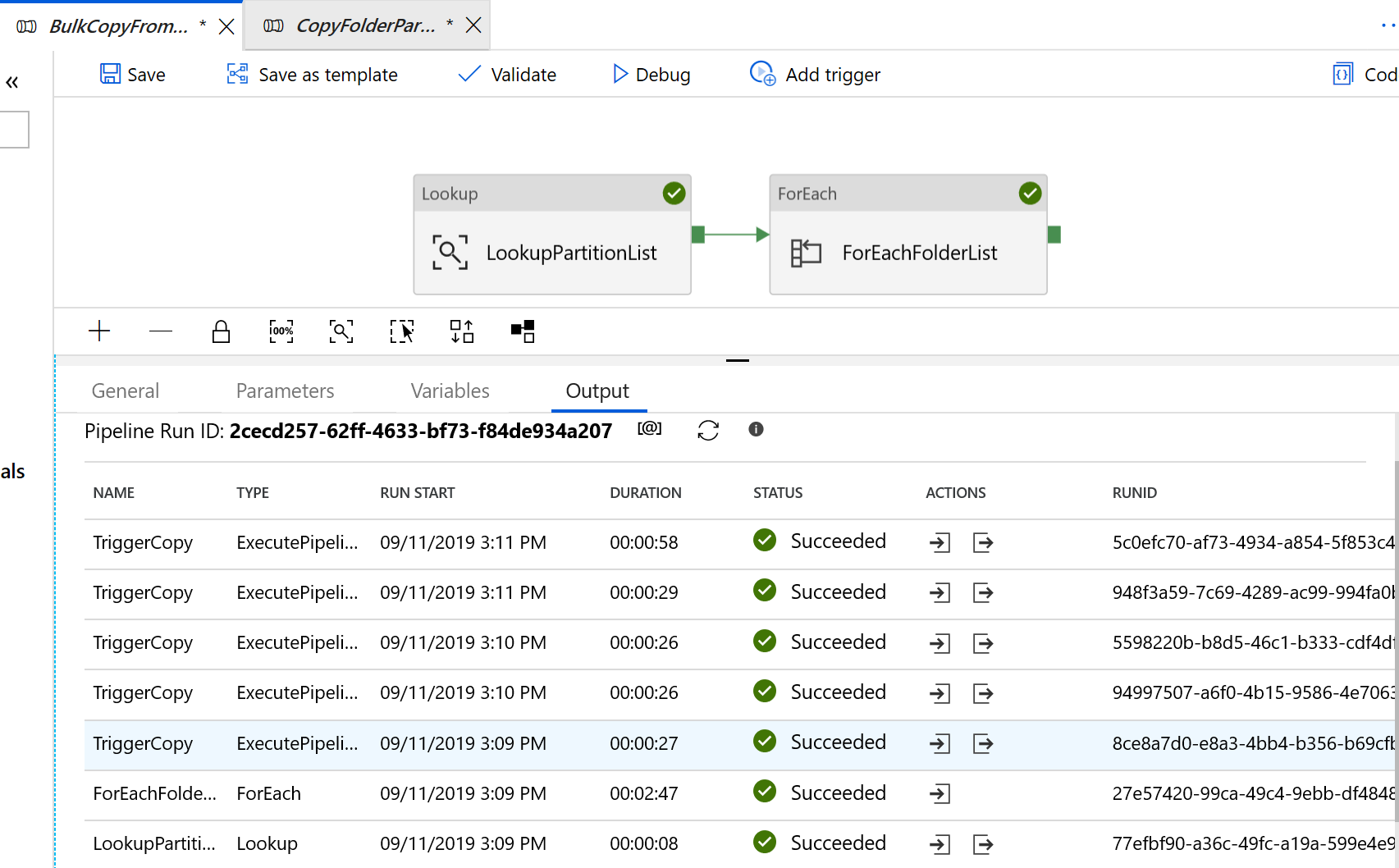
Les résultats ressemblent à l’exemple qui suit :
Pour que le modèle copie uniquement les fichiers modifiés d’Amazon S3 vers Azure Data Lake Storage Gen2
Créez une table de contrôle dans Azure SQL Database pour stocker la liste de partitions d’AWS S3.
Notes
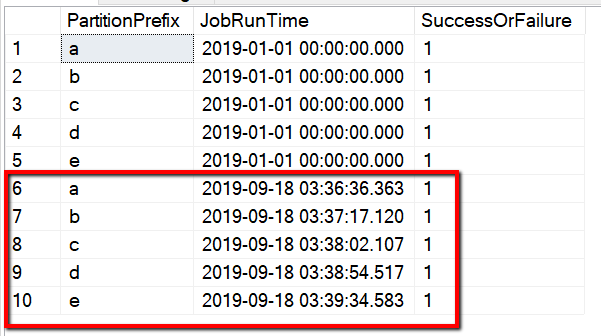
Le nom de la table est s3_partition_delta_control_table. Le schéma de la table de contrôle inclut PartitionPrefix, JobRunTime et SuccessOrFailure. PartitionPrefix est le paramètre de préfixe dans S3 pour filtrer les dossiers et les fichiers dans Amazon S3 par nom. JobRunTime est la valeur de date et heure d’exécution des travaux de copie. SuccessOrFailure est l’état de la copie de chaque partition : 0 signifie que cette partition n’a pas été copiée sur Azure et 1 signifie qu’elle a été correctement copiée sur Azure. 5 partitions sont définies dans la table de contrôle. La valeur par défaut de JobRunTime peut être l’heure de début de la migration des données historiques unique. L’activité de copie ADF copie les fichiers d’AWS S3 dont la dernière modification a été effectuée ultérieurement. Par défaut, l’état de la copie de chaque partition est 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Créez une procédure stockée sur la même base de données SQL Azure pour la table de contrôle.
Notes
Le nom de la procédure stockée est sp_insert_partition_JobRunTime_success. Elle sera appelée par l’activité SqlServerStoredProcedure dans votre pipeline ADF.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOAccédez au modèle Copier les données delta d’AWS S3 vers Azure Data Lake Storage Gen2. Entrez les connexions à votre table de contrôle externe, AWS S3 en tant que magasin de source de données et Azure Data Lake Storage Gen2 en tant que magasin de destination. Notez que la table de contrôle externe et la procédure stockée font référence à la même connexion.
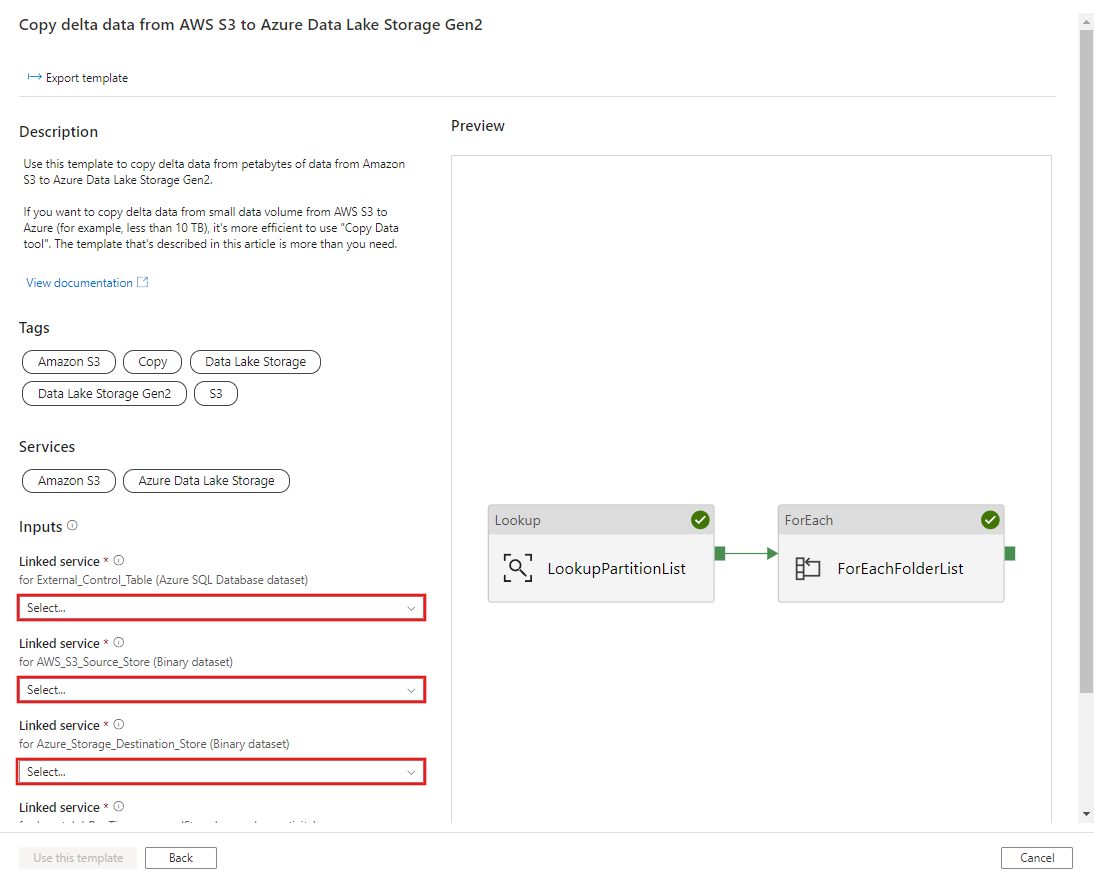
Cliquez sur Utiliser ce modèle.
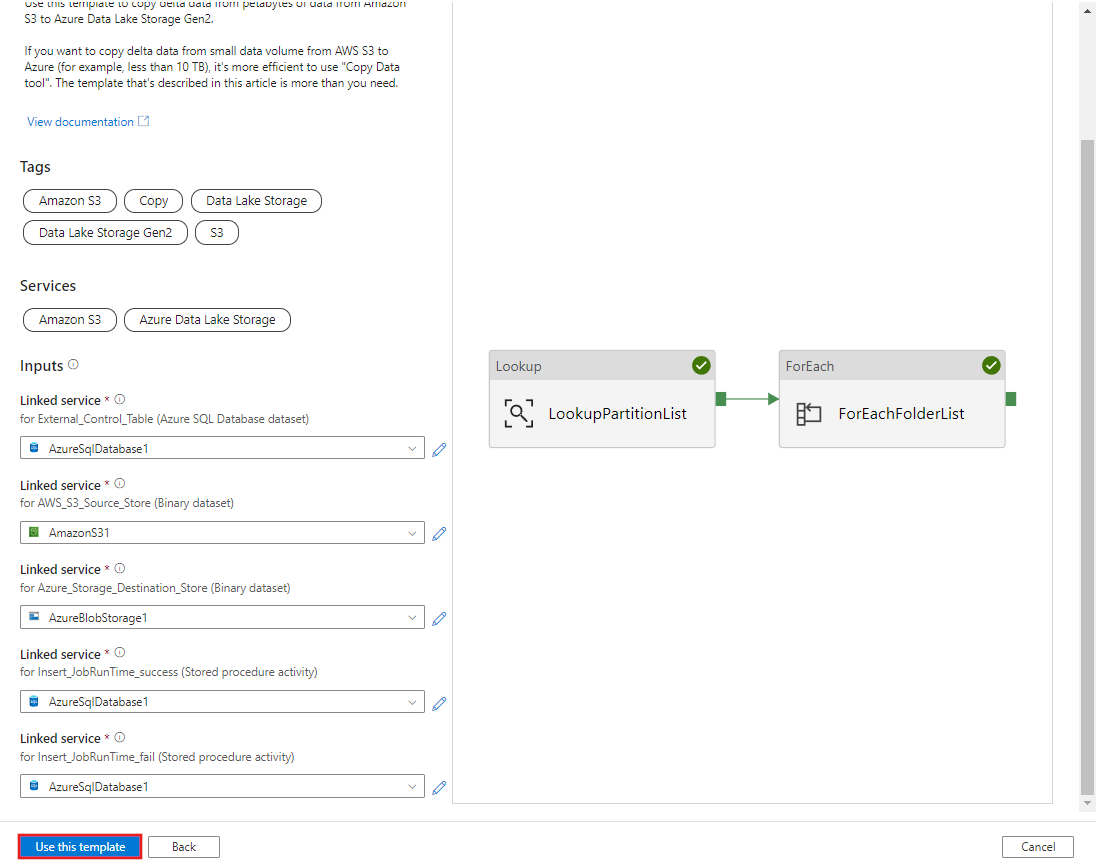
Vous voyez les 2 pipelines et les 3 jeux de données créés comme illustré dans l’exemple suivant :
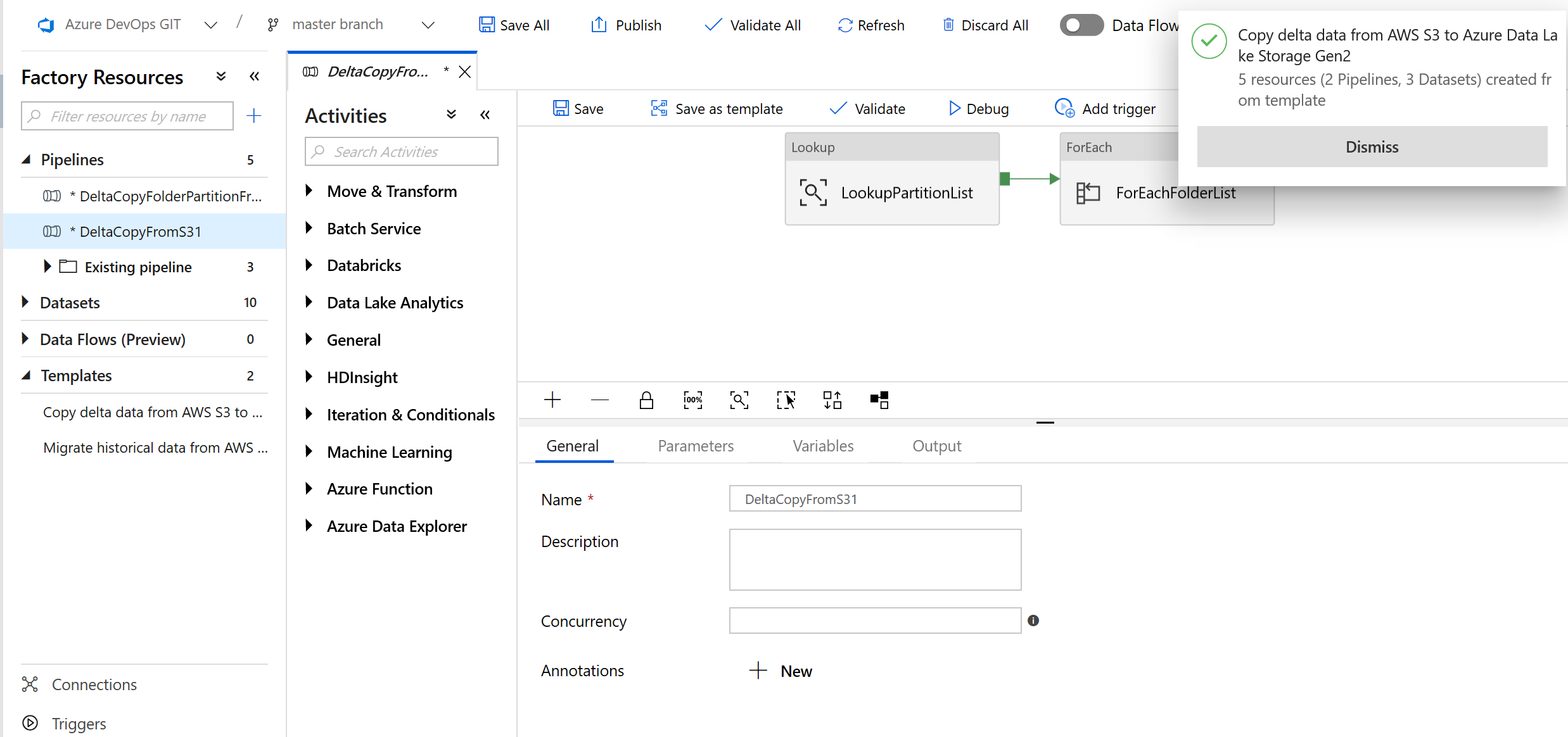
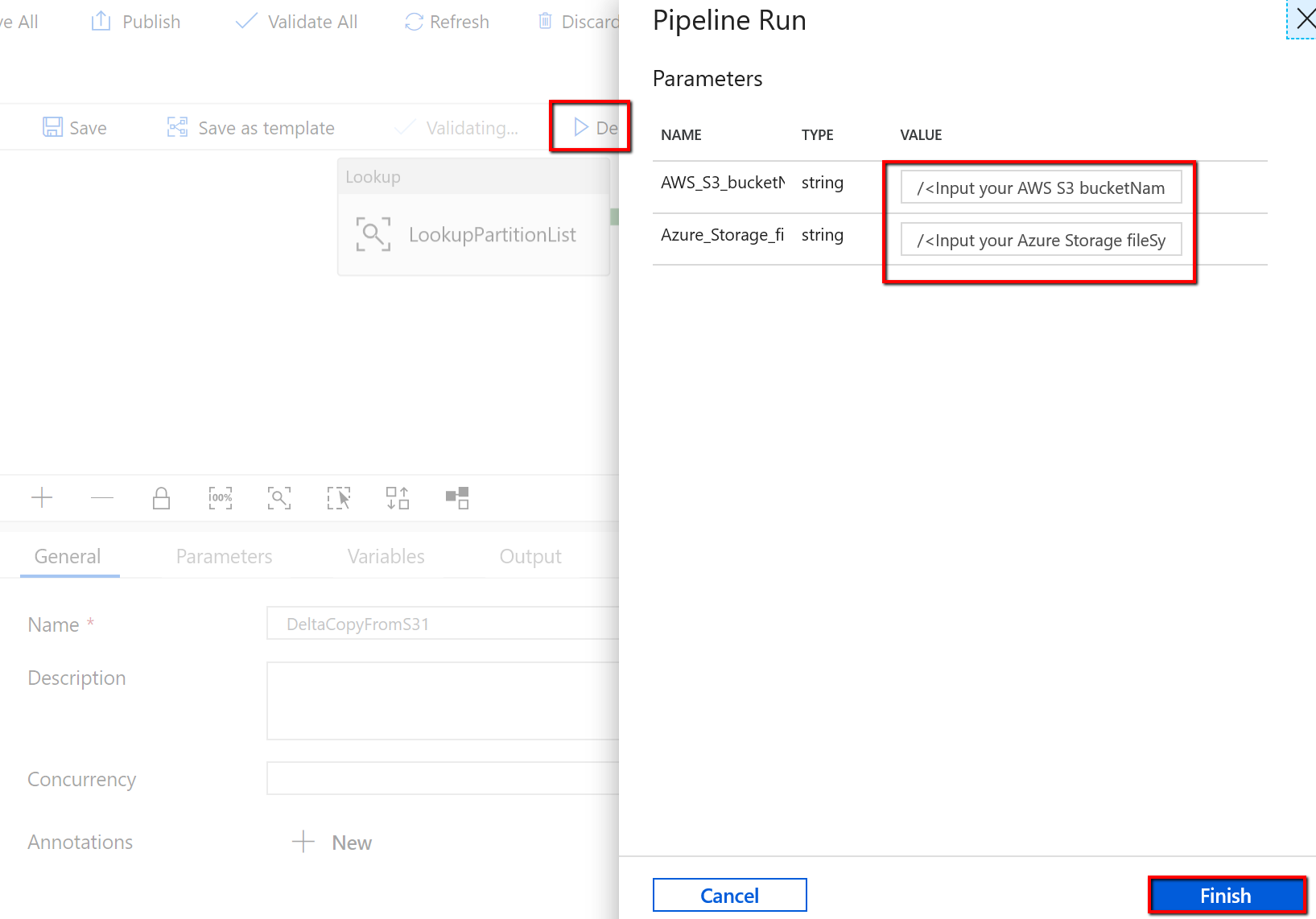
Accédez au pipeline « DeltaCopyFromS3 » et sélectionnez Déboguer, puis entrez les paramètres. Ensuite, sélectionnez Finish.
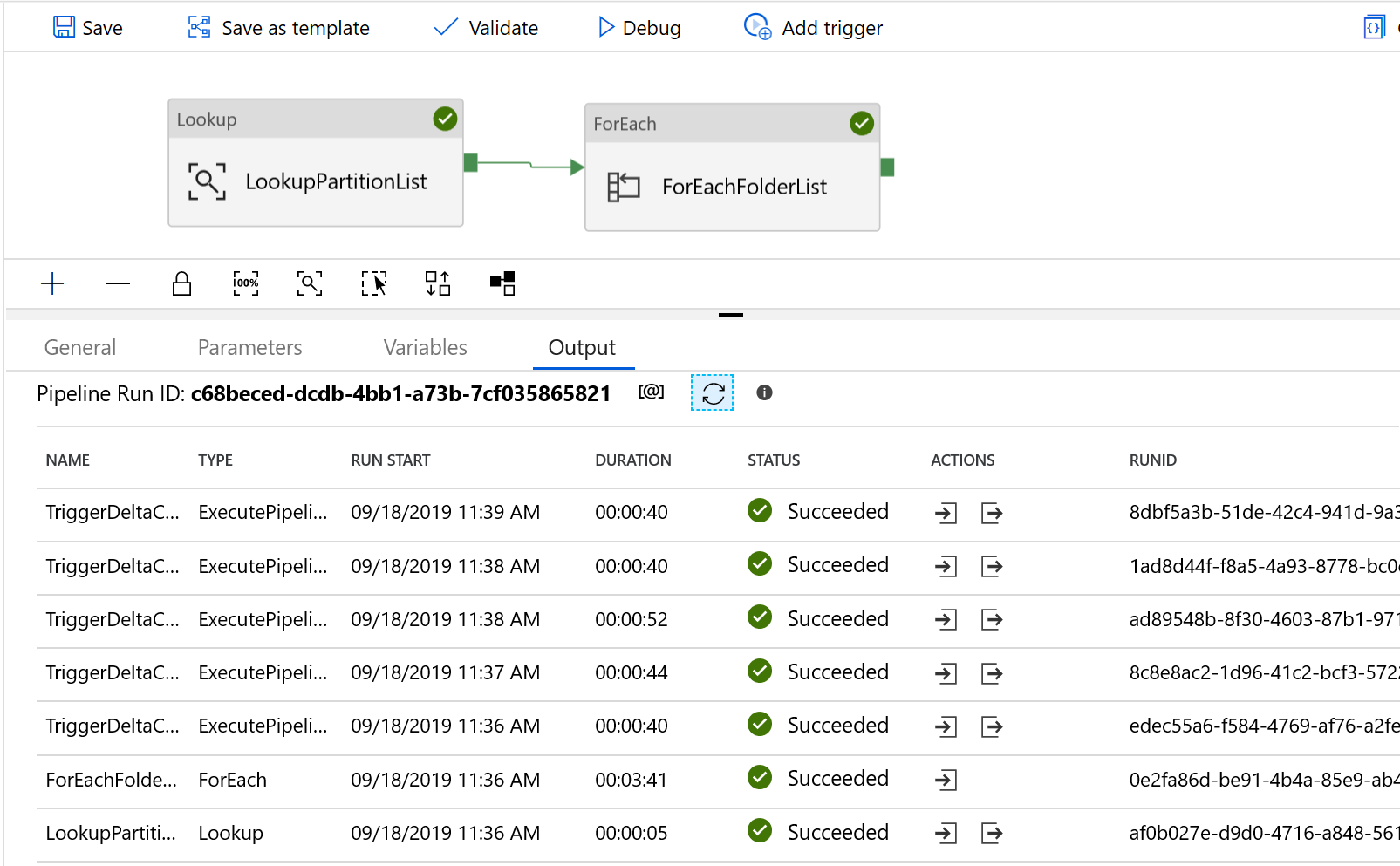
Les résultats ressemblent à l’exemple qui suit :
Vous pouvez également vérifier les résultats de la table de contrôle à l’aide de la requête « select * from s3_partition_delta_control_table » . La sortie est similaire à l’exemple suivant :