Tutoriel : Effectuer l’apprentissage d’un modèle dans Azure Machine Learning
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Découvrez comment un scientifique des données utilise Azure Machine Learning pour entraîner un modèle. Dans cet exemple, nous utilisons le jeu de données de carte de crédit associé pour montrer comment vous pouvez utiliser Azure Machine Learning pour résoudre un problème de classification. L’objectif est de prédire si un client a une forte probabilité d’utiliser par défaut un paiement par carte de crédit.
Le script d’entraînement gère la préparation des données, puis entraîne et inscrit un modèle. Ce tutoriel vous guide tout au long des étapes permettant d’envoyer un travail d’apprentissage basé sur le cloud (travail de commande). Si vous souhaitez en savoir plus sur le chargement de vos données dans Azure, consultez l’article Tutoriel : Charger, accéder et explorer vos données dans Azure Machine Learning. Les étapes à suivre sont les suivantes :
- Obtenir un handle dans votre espace de travail Azure Machine Learning
- Créer votre ressource de calcul et votre environnement de travail
- Créer votre script d’entraînement
- Créer et exécuter votre travail de commande pour exécuter le script d’apprentissage sur la ressource de calcul, configuré avec l’environnement de travail approprié et la source de données
- Afficher la sortie de votre script d’entraînement
- Déployer le modèle nouvellement entraîné en tant que point de terminaison.
- Appeler le point de terminaison Azure Machine Learning pour l’inférence
Cette vidéo montre comment démarrer dans Azure Machine Learning Studio afin que vous puissiez suivre les étapes du didacticiel. La vidéo montre comment créer un notebook, créer une instance de calcul et cloner le notebook. Les étapes sont également décrites dans les sections suivantes.
Prérequis
-
Pour utiliser Azure Machine Learning, vous avez d’abord besoin d’un espace de travail. Si vous n’en avez pas, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en savoir plus sur son utilisation.
-
Connectez-vous au studio et sélectionnez votre espace de travail s’il n’est pas déjà ouvert.
-
Ouvrez ou créez un notebook dans votre espace de travail :
- Créez un notebook si vous voulez copier/coller du code dans des cellules.
- Sinon, ouvrez tutorials/get-started-notebooks/train-model.ipynb dans la section Exemples de Studio. Sélectionnez ensuite Cloner pour ajouter le notebook à vos fichiers. (Découvrez où trouver les exemples.)
Définir votre noyau
Dans la barre supérieure au-dessus de votre notebook ouvert, créez une instance de calcul si vous n’en avez pas déjà une.

Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Assurez-vous que le noyau, situé en haut à droite, est
Python 3.10 - SDK v2. Si ce n’est pas le cas, utilisez la liste déroulante pour sélectionner ce noyau.
Si une bannière vous indique que vous devez être authentifié, sélectionnez Authentifier.



Important
Le reste de ce tutoriel contient des cellules du notebook du tutoriel. Copiez/collez-les dans votre nouveau notebook ou basculez vers le notebook maintenant si vous l’avez cloné.
Utiliser un travail de commande pour effectuer l’apprentissage d’un modèle dans Azure Machine Learning
Pour effectuer l’apprentissage d’un modèle, vous devez envoyer un travail. Le type de travail que vous allez envoyer dans ce tutoriel est un travail de commande. Azure Machine Learning propose différents types de travaux pour effectuer l’apprentissage des modèles. Vous pouvez sélectionner votre méthode d’apprentissage en fonction de la complexité du modèle, de la taille des données et des exigences de vitesse d’apprentissage. Dans ce tutoriel, vous allez apprendre à envoyer un travail de commande pour exécuter un script d’apprentissage.
Un travail de commande est une fonction qui vous permet d’envoyer un script d’apprentissage personnalisé pour effectuer l’apprentissage de votre modèle. Il peut également s’agir d’un travail d’apprentissage personnalisé. Un travail de commande dans Azure Machine Learning est un type de travail qui exécute un script ou une commande dans un environnement spécifique. Vous pouvez utiliser des travaux de commande pour effectuer l’apprentissage des modèles, traiter des données ou tout autre code personnalisé à exécuter dans le cloud.
Dans ce tutoriel, nous allons nous concentrer sur l’utilisation d’un travail de commande pour créer un travail d’apprentissage personnalisé que nous utiliserons pour effectuer l’apprentissage d’un modèle. Pour un travail d’apprentissage personnalisé, les éléments ci-dessous sont requis :
- Environnement
- data
- Travail de commande
- script d’apprentissage
Dans ce tutoriel, nous allons fournir tous ces éléments pour notre exemple : création d’un classifieur pour prédire les clients qui ont une forte probabilité d’utiliser par défaut des paiements par carte de crédit.
Créer un descripteur vers l’espace de travail
Avant de se lancer dans la rédaction du code, il faut trouver un moyen de référencer l’espace de travail. Vous allez créer ml_client pour un descripteur vers l’espace de travail. Vous utiliserez ensuite ml_client pour gérer les ressources et les travaux.
Dans la cellule suivante, entrez votre ID d’abonnement, le nom du groupe de ressources et le nom de l’espace de travail. Pour rechercher ces valeurs :
- Dans la barre d’outils supérieure droite d’Azure Machine Learning Studio, sélectionnez le nom de votre espace de travail.
- Copiez la valeur de l’espace de travail, du groupe de ressources et de l’ID d’abonnement dans le code.
- Vous devez copier une valeur, fermer la zone et coller, puis revenir pour la suivante.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Notes
La création de MLClient n’établit pas de connexion à l’espace de travail. L’initialisation du client est lente, elle attendra la première fois qu’elle aura besoin de passer un appel (ce qui se produira dans la prochaine cellule de code).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Créer un environnement de travail
Pour exécuter votre travail Azure Machine Learning sur votre ressource de calcul, vous avez besoin d’un environnement. Un environnement répertorie le runtime logiciel et les bibliothèques que vous souhaitez installer sur le calcul où vous allez vous former. Il est similaire à votre environnement Python sur votre ordinateur local.
Azure Machine Learning fournit de nombreux environnements organisés ou prêts à l’utilisation, qui sont utiles pour les scénarios courants d’apprentissage et d’inférence.
Dans cet exemple, vous allez créer un environnement conda pour vos travaux à l’aide d’un fichier yaml conda.
Tout d’abord, créez un répertoire dans lequel stocker le fichier.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
La cellule ci-dessous utilise IPython magic pour écrire le fichier conda dans le répertoire que vous venez de créer.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
La spécification contient certains packages habituels que vous utiliserez dans votre travail (numpy, pip).
Utilisez le fichier yaml pour créer et inscrire cet environnement personnalisé dans votre espace de travail :
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Configurer un travail d’apprentissage à l’aide de la fonction de commande
Vous créez un travail de commande Azure Machine Learning pour effectuer l’apprentissage d’un modèle à des fins de prédiction de défaillance de crédit. Le travail de commande exécute un script d’apprentissage dans un environnement spécifié sur une ressource de calcul spécifique. Vous avez déjà créé l’environnement et le cluster de calcul. Ensuite, vous allez créer le script d’entraînement. Dans notre cas spécifique, nous effectuons l’apprentissage de notre jeu de données pour produire un classifieur à l’aide du modèle GradientBoostingClassifier.
Le script d’entraînement gère la préparation des données, l’entraînement et l’inscription du modèle entraîné. La méthode train_test_split gère le fractionnement du jeu de données en données de test et d’apprentissage. Dans ce tutoriel, vous allez créer un script d’entraînement Python.
Les travaux de commande peuvent être exécutés à partir de l’interface CLI, du SDK Python ou de Studio. Dans ce tutoriel, vous allez utiliser le Kit de développement logiciel (SDK) Python Azure Machine Learning v2 pour créer et exécuter le travail de commande.
Créer un script d’entraînement
Commençons par créer le script d’entraînement : le fichier python main.py.
Tout d’abord, créez un dossier source pour le script :
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ce script gère le prétraitement des données, le fractionnant en données de test et d’apprentissage. Il consomme ensuite ces données pour entraîner un modèle basé sur une arborescence et retourner le modèle de sortie.
MLFlow est utilisé pour consigner les paramètres et les métriques pendant le travail. Le package MLFlow vous permet de suivre les métriques et les résultats pour chaque modèle dont Azure effectue l’apprentissage. Nous allons d’abord utiliser MLFlow pour obtenir le meilleur modèle pour nos données, puis nous consulterons les métriques du modèle dans Azure Studio.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Dans ce script, une fois le modèle entraîné, le fichier de modèle est enregistré et inscrit auprès de l’espace de travail. L’inscription de votre modèle vous permet de stocker vos modèles dans le cloud Azure, au sein de votre espace de travail, et d’en gérer les versions. Une fois que vous avez inscrit un modèle, vous pouvez trouver tous les autres modèles inscrits au même endroit dans Azure Studio, appelé « registre de modèles ». Le registre de modèles vous permet d’organiser et de suivre vos modèles entraînés.
Configurer la commande
Maintenant que vous disposez d’un script qui peut effectuer la tâche de classification, utilisez la commande à usage général qui peut exécuter des actions de ligne de commande. Cette action de ligne de commande peut appeler directement des commandes système ou exécuter un script.
Ici, créez des variables d’entrée pour spécifier les données d’entrée, le ratio de fractionnement, le taux d’apprentissage et le nom du modèle inscrit. Le script de commande effectue les actions suivantes :
- Utilisez l’environnement créé précédemment. Vous pouvez utiliser la notation
@latestpour indiquer la dernière version de l’environnement lors de l’exécution de la commande. - Configurez l’action de ligne de commande elle-même.
python main.py, dans ce cas. Les entrées/sorties sont accessibles sur la commande au moyen de la notation${{ ... }}. - Étant donné qu’aucune ressource de calcul n’a été spécifiée, le script est exécuté sur un cluster de calcul serverless qui est automatiquement créé.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Envoi du travail
Il est à présent temps de soumettre le travail à exécuter dans Azure Machine Learning Studio. Cette fois, vous allez utiliser create_or_update sur ml_client. ml_client est une classe cliente qui vous permet de vous connecter à votre abonnement Azure à l’aide de Python et d’interagir avec les services Azure Machine Learning. ml_client vous permet d’envoyer vos travaux à l’aide de Python.
ml_client.create_or_update(job)
Afficher la sortie du travail et attendre l’achèvement du travail
Affichez le travail dans Azure Machine Learning Studio en sélectionnant le lien dans la sortie de la cellule précédente. La sortie de ce travail ressemblera à ceci dans Azure Machine Learning Studio. Explorez les onglets pour obtenir différents détails tels que les métriques, les sorties, etc. Une fois terminé, le travail inscrit un modèle dans votre espace de travail suite à l’entraînement.
Important
Attendez que l’état du travail soit terminé avant de revenir à ce notebook pour continuer. Le travail prend 2 à 3 minutes. Cela peut prendre plus de temps (jusqu’à 10 minutes) si le cluster de calcul a été mis à l’échelle jusqu’à zéro nœuds et que l’environnement personnalisé est toujours généré.
Quand vous exécutez la cellule, la sortie du notebook affiche un lien vers la page de détails du travail dans Azure Studio. Vous pouvez également sélectionner Travaux dans le menu de navigation de gauche. Une tâche est un regroupement d’un grand nombre d’exécutions d’un script ou d’un morceau de code spécifié. Les informations concernant l’exécution sont stockées sous cette tâche. La page de détails donne une vue d’ensemble du travail, de son temps d’exécution, du moment de sa création, etc. Cette page contient également des onglets vers d’autres informations sur le travail, telles que les métriques, les sorties, les journaux et le code. Vous trouverez ci-dessous les onglets disponibles sur la page de détails du travail :
- Vue d’ensemble : la section de vue d’ensemble fournit des informations de base sur le travail, notamment son état, les heures de début et de fin, ainsi que le type de travail exécuté.
- Entrées : la section des entrées répertorie les données et le code qui ont été utilisés comme entrées pour le travail. Cette section peut inclure des jeux de données, des scripts, des configurations d’environnement et d’autres ressources utilisées pendant l’apprentissage.
- Sorties + journaux : l’onglet Sorties + journaux contient les journaux générés pendant l’exécution du travail. Cet onglet vous aide à résoudre les problèmes liés à la création de votre script ou de votre modèle d’apprentissage.
- Métriques : l’onglet Métriques présente les principales métriques de performances de votre modèle, telles que le score d’apprentissage, le score f1 et le score de précision.
Nettoyer les ressources
Si vous comptez suivre d’autres tutoriels, passez aux Étapes suivantes.
Arrêter l’instance de calcul
Si vous ne comptez pas l’utiliser maintenant, arrêtez l’instance de calcul :
- Dans la zone de navigation gauche de Studio, sélectionnez Calculer.
- Sous les onglets supérieurs, sélectionnez Instances de calcul
- Sélectionnez l’instance de calcul dans la liste.
- Dans la barre d’outils supérieure, sélectionnez Arrêter.
Supprimer toutes les ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans le portail Azure, sélectionnez Groupes de ressources tout à gauche.
Dans la liste, sélectionnez le groupe de ressources créé.
Sélectionnez Supprimer le groupe de ressources.
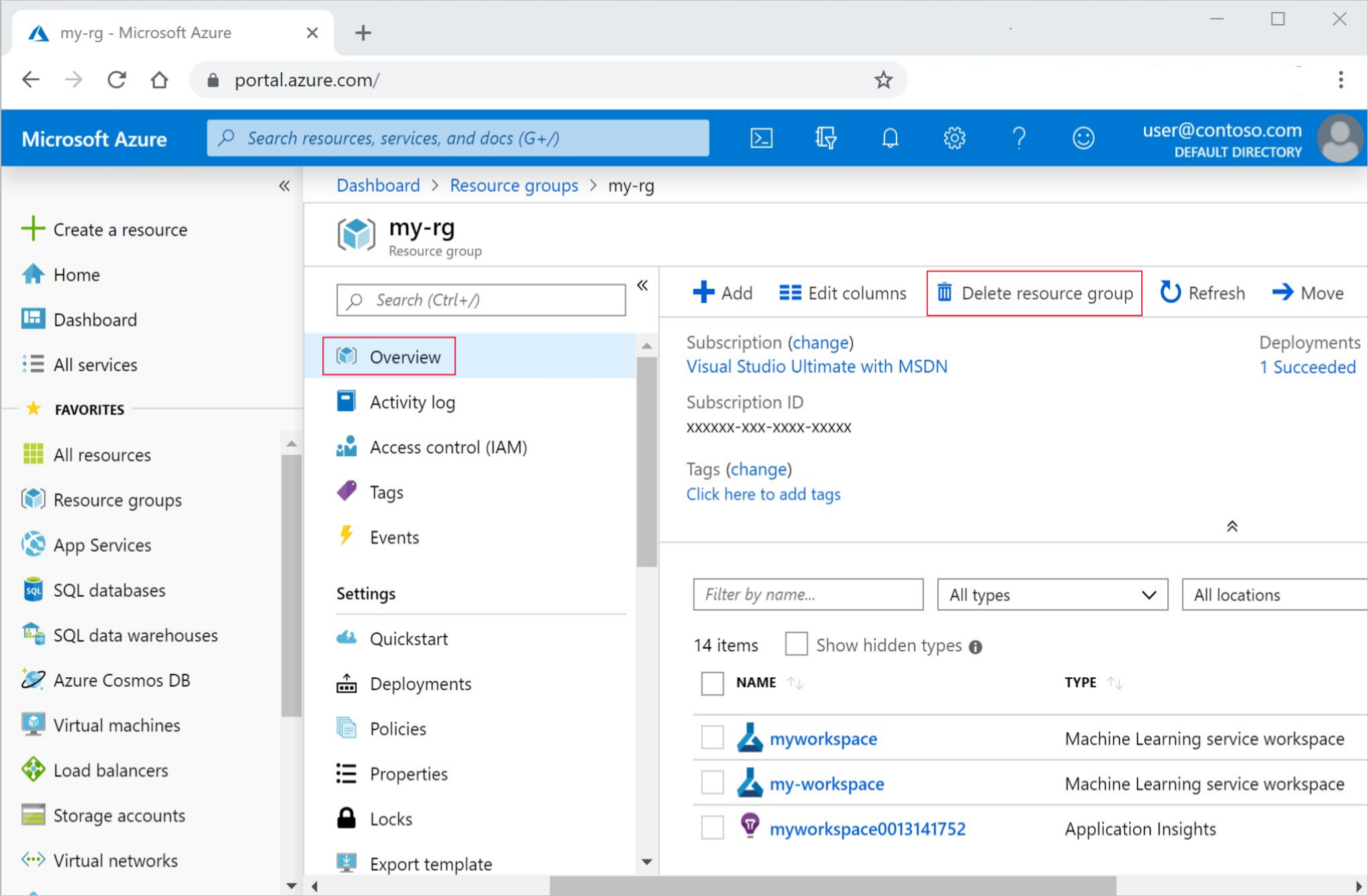
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
En savoir plus sur le déploiement d’un modèle
Ce tutoriel utilisait un fichier de données en ligne. Pour en savoir plus sur les autres façons d’accéder aux données, consultez le tutoriel Charger, accéder et explorer vos données dans Azure Machine Learning.
Si vous souhaitez en savoir plus sur les différentes façons d’effectuer l’apprentissage des modèles dans Azure Machine Learning, consultez l’article Qu’est-ce que le Machine Learning automatisé (AutoML) ?. Le ML automatisé est un outil supplémentaire qui permet de réduire le temps passé par un scientifique des données à trouver le modèle idéal pour ses données.
Si vous souhaitez obtenir d’autres exemples similaires à ce tutoriel, consultez la section Exemples de Studio. Ces mêmes exemples sont disponibles sur notre page d’exemples GitHub. Les exemples incluent des notebooks Python complets que vous pouvez exécuter et apprendre pour effectuer l’apprentissage d’un modèle. Vous pouvez modifier et exécuter des scripts existants à partir des exemples, qui contiennent des scénarios, notamment la classification, le traitement du langage naturel et la détection d’anomalie.