Tutoriel : Entraîner un modèle dans Python avec le Machine Learning automatisé
Azure Machine Learning est un environnement informatique qui vous permet d’effectuer l’apprentissage, le déploiement, l’automatisation, la gestion et le suivi des modèles Machine Learning.
Dans ce tutoriel, vous utilisez le Machine Learning automatisé d’Azure Machine Learning pour créer un modèle de régression permettant de prédire les prix des courses de taxi. Ce processus parvient au meilleur modèle en acceptant des données d’entraînement et des paramètres de configuration, et en bouclant automatiquement dans des combinaisons de différentes méthodes, de différents modèles et de différentes valeurs pour les hyperparamètres.
Dans ce tutoriel, vous allez apprendre à :
- Télécharger les données en utilisant Apache Spark et d’Azure Open Datasets.
- Transformer et nettoyer des données en utilisant des DataFrames Apache Spark.
- Entraîner un modèle de régression dans le Machine Learning automatisé.
- Calculer la précision d’un modèle.
Avant de commencer
- Créez un pool Apache Spark serverless en suivant le démarrage rapide Créer un pool Apache Spark serverless.
- Suivez le tutoriel de configuration de l’espace de travail Azure Machine Learning si vous n’avez pas d’espace de travail Azure Machine Learning existant.
Avertissement
- Depuis le 29 septembre 2023, Azure Synapse ne prend plus officiellement en charge les runtimes Spark 2.4. Depuis le 29 septembre 2023, nous ne traitons aucun ticket de support lié à Spark 2.4. Aucun pipeline de mise en production ne sera mis en place pour les correctifs de bogues ou de sécurité de Spark 2.4. Après la date de fin du support, vous devrez assumer les risques découlant de l’utilisation de Spark 2.4. Nous vous déconseillons fortement de continuer à l’utiliser en raison de problèmes potentiels de sécurité et de fonctionnalités.
- Dans le cadre du processus de dépréciation d’Apache Spark 2.4, nous souhaitons vous informer de ce qu’AutoML dans Azure Synapse Analytics va également être déconseillé. Cela comprend à la fois l’interface à code faible et les API utilisées pour créer des essais AutoML par du code.
- Remarquez que la fonctionnalité AutoML était exclusivement disponible au travers du runtime Spark 2.4.
- Pour les clients souhaitant continuer à tirer parti des fonctionnalités AutoML, nous vous recommandons d’enregistrer vos données dans votre compte Azure Data Lake Storage Gen2 (ADLSg2). À partir de là, vous pouvez accéder en toute transparence à l’expérience AutoML par Azure Machine Learning (AzureML). Des informations supplémentaires concernant cette solution de contournement sont disponibles ici.
Comprendre les modèles de régression
Les modèles de régression prédisent des valeurs de sortie numériques basées sur des prédicteurs indépendants. Dans une régression, l’objectif est d’aider à établir la relation entre ces variables de prédiction indépendantes en estimant comment une variable affecte les autres variables.
Exemple basé sur les données relatives aux taxis de New York
Dans cet exemple, vous utilisez Spark pour effectuer une analyse sur les données de pourboires pour les courses de taxi à New York. Les données sont disponibles dans Azure Open Datasets. Ce sous-ensemble du jeu de données contient des données sur les courses de taxis jaunes, avec des informations sur chaque course, les heures et les lieux de départ et d’arrivée, et le prix.
Important
Des frais supplémentaires peuvent s’appliquer pour l’extraction de ces données à partir de leur emplacement de stockage. Dans les étapes suivantes, vous développez un modèle permettant de prédire les prix des courses de taxi à New York.
Télécharger et préparer les données
Voici comment procéder :
Créez un notebook en utilisant le noyau PySpark. Pour obtenir des instructions, consultez Créer un notebook.
Notes
Grâce au noyau PySpark, il est inutile de créer des contextes explicitement. Le contexte Spark est créé automatiquement pour vous lorsque vous exécutez la première cellule de code.
Comme les données brutes sont au format Parquet, vous pouvez utiliser le contexte Spark pour extraire le fichier directement en mémoire en tant que DataFrame. Créez un DataFrame Spark en extrayant les données via l’API Open Datasets. Vous allez utiliser ici les propriétés
schema on readdu DataFrame Spark pour déduire les types de données et le schéma.blob_account_name = "azureopendatastorage" blob_container_name = "nyctlc" blob_relative_path = "yellow" blob_sas_token = r"" # Allow Spark to read from the blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name),blob_sas_token) # Spark read parquet; note that it won't load any data yet df = spark.read.parquet(wasbs_path)Selon la taille de votre pool Spark, les données brutes peuvent être trop grandes ou leur exploitation peut prendre trop de temps. Vous pouvez filtrer ces données pour en réduire le volume, par exemple sur un mois de données, à l’aide des filtres
start_dateetend_date. Après avoir filtré un DataFrame, vous pouvez aussi exécuter la fonctiondescribe()sur le nouveau DataFrame pour afficher des statistiques récapitulatives pour chaque champ.D’après les statistiques récapitulatives, vous pouvez voir qu’il existe quelques irrégularités dans les données. Par exemple, les statistiques montrent que la distance de trajet minimale est inférieure à 0. Vous devez filtrer ces points de données irréguliers.
# Create an ingestion filter start_date = '2015-01-01 00:00:00' end_date = '2015-12-31 00:00:00' filtered_df = df.filter('tpepPickupDateTime > "' + start_date + '" and tpepPickupDateTime< "' + end_date + '"') filtered_df.describe().show()Générez des caractéristiques à partir du jeu de données en sélectionnant un ensemble de colonnes et en créant différentes caractéristiques basées sur le temps à partir du champ
datetimede la prise en charge. Filtrez les valeurs hors norme qui ont été identifiées à l’étape précédente, puis supprimez les quelques dernières colonnes qui ne sont pas nécessaires pour l’entraînement.from datetime import datetime from pyspark.sql.functions import * # To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) taxi_df = sampled_taxi_df.select('vendorID', 'passengerCount', 'tripDistance', 'startLon', 'startLat', 'endLon' \ , 'endLat', 'paymentType', 'fareAmount', 'tipAmount'\ , column('puMonth').alias('month_num') \ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , date_format('tpepPickupDateTime', 'EEEE').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month') ,(unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('trip_time'))\ .filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\ & (sampled_taxi_df.tipAmount >= 0)\ & (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\ & (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\ & (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 200)\ & (sampled_taxi_df.rateCodeId <= 5)\ & (sampled_taxi_df.paymentType.isin({"1", "2"}))) taxi_df.show(10)Comme vous pouvez le voir, cela crée un nouveau DataFrame avec des colonnes supplémentaires pour le jour du mois, l’heure de collecte, le jour de la semaine et la durée totale de la course.

Générer des jeux de données de test et de validation
Une fois que vous avez votre jeu de données final, vous pouvez diviser les données en jeux d’entraînement et de test en utilisant la fonction random_ split de Spark. En utilisant les poids fournis, cette fonction divise de manière aléatoire les données dans le jeu de données d’entraînement pour l’entraînement du modèle et le jeu de données de validation à des fins de test.
# Random split dataset using Spark; convert Spark to pandas
training_data, validation_data = taxi_df.randomSplit([0.8,0.2], 223)
Cette étape garantit que les points de données pour tester le modèle fini n’ont pas été utilisées pour l’entraînement du modèle.
Se connecter à un espace de travail Azure Machine Learning
Dans Azure Machine Learning, un espace de travail est une classe qui accepte les informations concernant votre abonnement et vos ressources Azure. Il crée également une ressource cloud pour superviser et suivre les exécutions de votre modèle. Dans cette étape, vous créez un objet d’espace de travail à partir de l’espace de travail Azure Machine Learning existant.
from azureml.core import Workspace
# Enter your subscription id, resource group, and workspace name.
subscription_id = "<enter your subscription ID>" #you should be owner or contributor
resource_group = "<enter your resource group>" #you should be owner or contributor
workspace_name = "<enter your workspace name>" #your workspace name
ws = Workspace(workspace_name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group)
Convertir un DataFrame en jeu de données Azure Machine Learning
Pour envoyer une expérience à distance, convertissez votre jeu de données en instance TabularDatset Azure Machine Learning. TabularDataset représente les données sous forme de tableau en analysant les fichiers fournis.
Le code suivant obtient l’espace de travail existant et le magasin de données Azure Machine Learning par défaut. Ensuite, il transmet les emplacements du magasin de données et des fichiers au paramètre de chemin pour créer une nouvelle instance TabularDataset.
import pandas
from azureml.core import Dataset
# Get the Azure Machine Learning default datastore
datastore = ws.get_default_datastore()
training_pd = training_data.toPandas().to_csv('training_pd.csv', index=False)
# Convert into an Azure Machine Learning tabular dataset
datastore.upload_files(files = ['training_pd.csv'],
target_path = 'train-dataset/tabular/',
overwrite = True,
show_progress = True)
dataset_training = Dataset.Tabular.from_delimited_files(path = [(datastore, 'train-dataset/tabular/training_pd.csv')])

Soumettre une expérience automatisée
Les sections suivantes vous guident tout au long du processus de soumission d’une expérience de Machine Learning automatisé.
Définir les paramètres d’entraînement
Pour soumettre une expérience, vous devez définir le paramètre de l’expérience et les paramètres du modèle pour l’entraînement. Pour obtenir la liste complète des paramètres, consultez Configurer des expériences de Machine Learning automatisé dans Python.
import logging automl_settings = { "iteration_timeout_minutes": 10, "experiment_timeout_minutes": 30, "enable_early_stopping": True, "primary_metric": 'r2_score', "featurization": 'auto', "verbosity": logging.INFO, "n_cross_validations": 2}Passez les paramètres d’entraînement définis en tant que paramètre
kwargsà un objetAutoMLConfig. Comme vous utilisez Spark, vous devez aussi passer le contexte Spark, qui est automatiquement accessible par la variablesc. Vous spécifiez aussi les données d’entraînement et le type de modèle, qui dans ce cas est « régression ».from azureml.train.automl import AutoMLConfig automl_config = AutoMLConfig(task='regression', debug_log='automated_ml_errors.log', training_data = dataset_training, spark_context = sc, model_explainability = False, label_column_name ="fareAmount",**automl_settings)
Notes
Les étapes de prétraitement du Machine Learning automatisé deviennent partie intégrante du modèle sous-jacent. Ces étapes incluent la normalisation des caractéristiques, la gestion des données manquantes et la conversion du texte en type numérique. Quand vous utilisez le modèle pour des prédictions, les étapes de prétraitement qui sont appliquées pendant l’entraînement sont appliquées automatiquement à vos données d’entrée.
Entraîner le modèle de régression automatique
Ensuite, vous créez un objet d’expérience dans votre espace de travail Azure Machine Learning. Une expérience fait office de conteneur pour vos exécutions individuelles.
from azureml.core.experiment import Experiment
# Start an experiment in Azure Machine Learning
experiment = Experiment(ws, "aml-synapse-regression")
tags = {"Synapse": "regression"}
local_run = experiment.submit(automl_config, show_output=True, tags = tags)
# Use the get_details function to retrieve the detailed output for the run.
run_details = local_run.get_details()
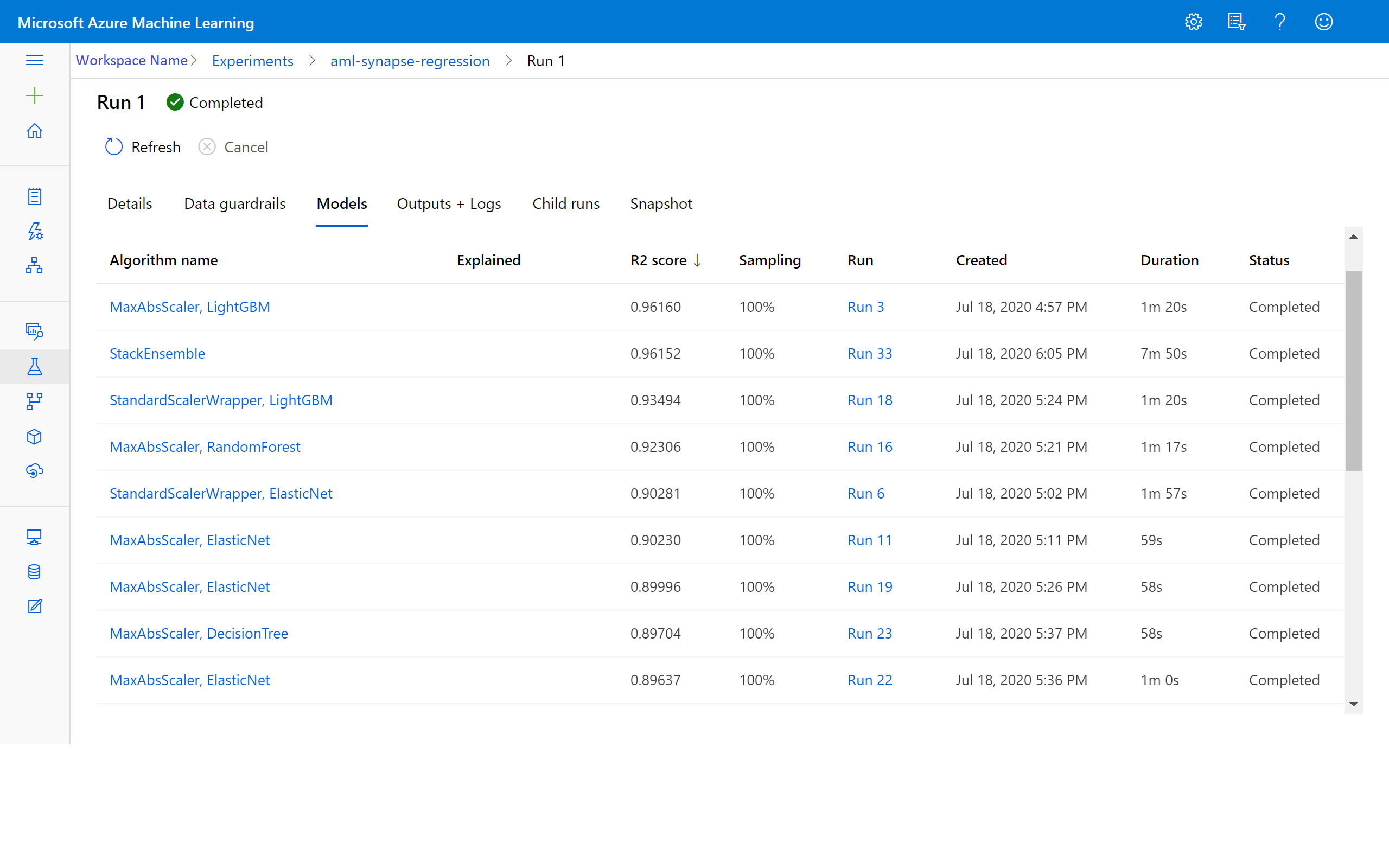
Une fois l’expérience terminée, la sortie retourne des détails sur les itérations effectuées. Pour chaque itération, vous voyez le type de modèle, la durée d’exécution et la précision de l’entraînement. Le champ BEST effectue un suivi du meilleur score obtenu à l’entraînement en fonction de votre type de métrique.

Remarque
Une fois l’expérience de Machine Learning automatisé soumise, elle exécute différentes itérations avec différents types de modèles. Cette exécution prend généralement entre 60 et 90 minutes.
Récupérer le meilleur modèle
Pour sélectionner le meilleur modèle parmi vos itérations, utilisez la fonction get_output pour retourner le modèle le mieux adapté. Le code ci-dessous récupère le modèle le mieux adapté pour toutes les métriques journalisées ou pour une itération particulière.
# Get best model
best_run, fitted_model = local_run.get_output()
Tester la précision du modèle
Pour tester la précision du modèle, utilisez le meilleur modèle pour faire des prédictions des prix des courses de taxi sur le jeu de données de test. La fonction
predictutilise le meilleur modèle et prédit les valeurs dey(montant du tarif) à partir du jeu de données de validation.# Test best model accuracy validation_data_pd = validation_data.toPandas() y_test = validation_data_pd.pop("fareAmount").to_frame() y_predict = fitted_model.predict(validation_data_pd)L’erreur quadratique moyenne est une mesure fréquemment utilisée des différences entre les exemples de valeurs prédites par un modèle et les valeurs observées. L’erreur quadratique moyenne des résultats se calcule en comparant le DataFrame
y_testaux valeurs prédites par le modèle.La fonction
mean_squared_erroraccepte deux tableaux et calcule l’erreur quadratique moyenne entre ces tableaux. Vous prenez ensuite la racine carrée du résultat. Cette métrique indique l’écart approximatif entre les prédictions des tarifs de taxi et les tarifs réels.from sklearn.metrics import mean_squared_error from math import sqrt # Calculate root-mean-square error y_actual = y_test.values.flatten().tolist() rmse = sqrt(mean_squared_error(y_actual, y_predict)) print("Root Mean Square Error:") print(rmse)Root Mean Square Error: 2.309997102577151L’erreur quadratique moyenne est une bonne mesure de la manière dont le modèle prédit la réponse. Dans les résultats, vous voyez que le modèle est assez bon dans la prédiction des tarifs de taxi à partir des caractéristiques du jeu de données, en général avec un écart de ± 2,00 dollars.
Exécutez le code suivant pour calculer l’erreur absolue moyenne en pourcentage. Cette mesure exprime la précision sous la forme d’un pourcentage de l’erreur. Pour ce faire, elle calcule une différence absolue entre chaque valeur prédite et réelle, puis additionne toutes les différences. Ensuite, elle exprime cette somme sous forme de pourcentage du total des valeurs réelles.
# Calculate mean-absolute-percent error and model accuracy sum_actuals = sum_errors = 0 for actual_val, predict_val in zip(y_actual, y_predict): abs_error = actual_val - predict_val if abs_error < 0: abs_error = abs_error * -1 sum_errors = sum_errors + abs_error sum_actuals = sum_actuals + actual_val mean_abs_percent_error = sum_errors / sum_actuals print("Model MAPE:") print(mean_abs_percent_error) print() print("Model Accuracy:") print(1 - mean_abs_percent_error)Model MAPE: 0.03655071038487368 Model Accuracy: 0.9634492896151263Dans les deux métriques de précision de la prédiction, vous voyez que le modèle est assez bon dans la prédiction des tarifs de taxi à partir des caractéristiques du jeu de données.
Après avoir ajusté un modèle de régression linéaire, vous devez maintenant déterminer dans quelle mesure le modèle est adapté aux données. Pour ce faire, vous tracez les valeurs des tarifs réels par rapport au résultat prédit. En outre, vous calculez la racine carrée de la mesure pour comprendre le degré de proximité des données avec la ligne de régression ajustée.
import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import mean_squared_error, r2_score # Calculate the R2 score by using the predicted and actual fare prices y_test_actual = y_test["fareAmount"] r2 = r2_score(y_test_actual, y_predict) # Plot the actual versus predicted fare amount values plt.style.use('ggplot') plt.figure(figsize=(10, 7)) plt.scatter(y_test_actual,y_predict) plt.plot([np.min(y_test_actual), np.max(y_test_actual)], [np.min(y_test_actual), np.max(y_test_actual)], color='lightblue') plt.xlabel("Actual Fare Amount") plt.ylabel("Predicted Fare Amount") plt.title("Actual vs Predicted Fare Amount R^2={}".format(r2)) plt.show()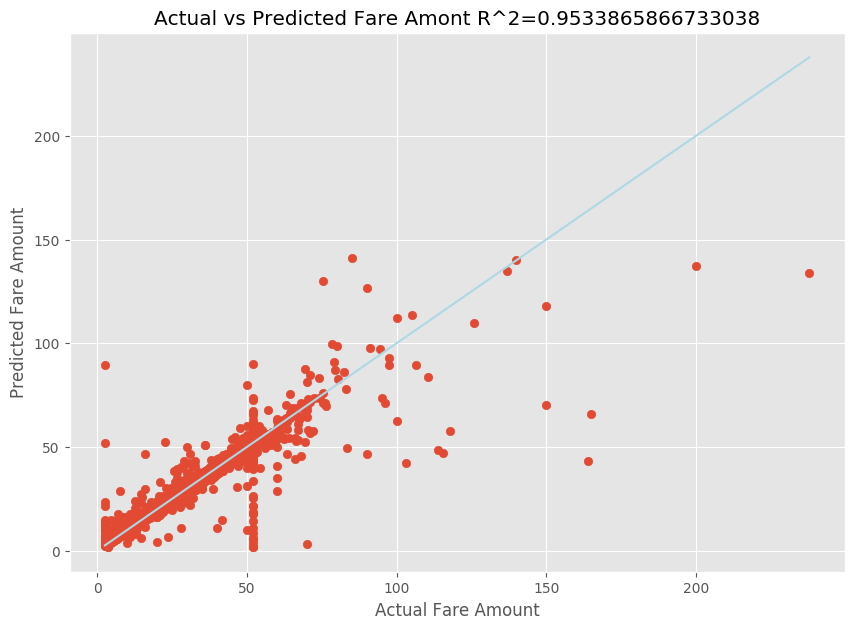
Dans les résultats, vous pouvez voir que la racine carrée de la mesure compte pour 95 % de la variance. Ceci est également vérifié par le tracé réel comparé au tracé observé. Plus la variance prise en compte par le modèle de régression est importante, plus les points de données sont proches de la ligne de régression ajustée.
Inscrire le modèle auprès d’Azure Machine Learning
Une fois que vous avez vérifié votre meilleur modèle, vous pouvez l’inscrire auprès d’Azure Machine Learning. Vous pouvez ensuite télécharger ou déployer le modèle inscrit, et recevoir tous les fichiers que vous avez inscrits.
description = 'My automated ML model'
model_path='outputs/model.pkl'
model = best_run.register_model(model_name = 'NYCYellowTaxiModel', model_path = model_path, description = description)
print(model.name, model.version)
NYCYellowTaxiModel 1
Afficher les résultats dans Azure Machine Learning
Vous pouvez aussi consulter les résultats des itérations en accédant à l’expérience dans votre espace de travail Azure Machine Learning. Vous y trouverez des détails supplémentaires sur l’état de votre exécution, sur les modèles essayés et sur d’autres métriques de modèle.