Architectures pour Oracle Database Enterprise Edition sur Azure
S’applique à : ✔️ Machines virtuelles Linux
Azure héberge toutes les charges de travail d’Oracle, y compris celles qui doivent continuer à fonctionner de manière optimale dans Azure avec Oracle. Si vous disposez du pack de diagnostics Oracle ou du référentiel automatique de charge de travail (AWR), vous pouvez collecter des données sur vos charges de travail. Utilisez ces données pour évaluer la charge de travail Oracle, dimensionner les besoins en ressources et migrer la charge de travail vers Azure. Les différentes métriques fournies par Oracle dans ces rapports peuvent fournir une base pour comprendre les performances des applications et l’utilisation de la plateforme.
Cet article vous aide à préparer une charge de travail Oracle pour son exécution dans Azure et à explorer les meilleures solutions d’architecture pour offrir des performances optimales dans le cloud. Les données fournies par Oracle dans le Statspack et davantage dans son descendant, l’AWR, vous aident à développer des attentes claires. Ces attentes comprennent les limites du réglage physique par l’architecture, les avantages du réglage logique du code de la base de données et la conception globale de la base de données.
Différences entre les deux environnements
Lorsque vous migrez des applications locales vers Azure, gardez à l’esprit quelques différences importantes entre les deux environnements.
L’une des principales différences est que, dans une implémentation Azure, les ressources, telles que les machines virtuelles, les disques et les réseaux virtuels, sont partagées avec les autres clients. Les ressources peuvent aussi être limitées en fonction des critères définis. Au lieu de se concentrer sur ce qui permet d’éviter une défaillance, Azure est plus axé sur la survie à une défaillance. La première approche tente d’augmenter le temps moyen entre les défaillances (MTBF) et la seconde tente de réduire le temps moyen de récupération (MTTR).
Le tableau suivant liste certaines des différences qui existent entre une implémentation locale et une implémentation Azure d’une base de données Oracle.
| Implémentation locale | Implémentation d’Azure | |
|---|---|---|
| Mise en réseau | LAN/WAN | Réseau à définition logicielle (SDN) |
| Groupe de sécurité | Outils de restriction d’adresse IP/de port | Groupe de sécurité réseau |
| Résilience | MTBF | Temps moyen de résolution |
| Maintenance planifiée | Correctifs/mises à niveau | Groupes à haute disponibilité avec des correctifs et des mises à jour gérés par Azure |
| Ressource | Dédié | Partagée avec d’autres clients |
| Régions | Centres de données | Paires de régions |
| Stockage | SAN/disques physiques | Stockage géré par Azure |
| Mettre à l'échelle | Mise à l’échelle verticale | Mise à l’échelle horizontale |
Spécifications
Prenez en compte les exigences suivantes avant de commencer votre migration :
- Déterminez l’utilisation réelle de l’UC. Oracle concède des licences par cœur, ce qui signifie que le dimensionnement de vos besoins en vCPU peut s’avérer essentiel pour vous aider à réduire vos coûts.
- Déterminez la taille, le stockage de sauvegarde et le taux de croissance de la base de données.
- Déterminez les besoins en E/S, que vous pouvez estimer sur la base d’Oracle Statspack et des rapports AWR. Vous pouvez également estimer les besoins à partir des outils d’analyse du stockage disponibles dans le système d’exploitation.
Options de configuration
Il est judicieux de générer un rapport AWR et d’en tirer certaines métriques qui vous aideront à prendre des décisions concernant la configuration. Il existe alors quatre domaines potentiels que vous pouvez régler pour améliorer les performances dans un environnement Azure :
- Taille de la machine virtuelle
- Débit du réseau
- Types de disque et configurations
- Paramètres de cache des disques
Générer un rapport AWR
Si vous disposez d’une base de données Oracle Enterprise Edition que vous envisagez de migrer vers Azure, vous avez plusieurs options. Si vous avez le Diagnostics Pack pour vos instances Oracle, vous pouvez exécuter le rapport Oracle AWR pour obtenir les métriques (par exemple, IOPS, mégabits par seconde, et Gio). Pour ces bases de données sans licence Diagnostics Pack ou pour une base de données Oracle Standard Edition, vous pouvez collecter les mêmes métriques importantes à l’aide d’un rapport Statspack après avoir collecté des instantanés manuels. Les principales différences entre ces deux méthodes de rapport sont que le rapport AWR est collecté automatiquement et qu’il fournit plus d’informations sur la base de données que le rapport Statspack.
Envisagez d’exécuter votre rapport AWR lors des charges de travail normales et des charges de travail maximales, afin de pouvoir les comparer. Pour collecter la charge de travail la plus précise, envisagez un rapport à fenêtre étendue d’une semaine, plutôt que d’un jour. AWR fournit des moyennes dans le cadre de ses calculs dans le rapport. Par défaut, le référentiel AWR conserve huit jours de données et prend des instantanés toutes les heures.
Dans le cas d’une migration de centre de données, vous devriez rassembler des rapports pour le dimensionnement des systèmes de production. Estimez les copies de base de données restantes utilisées pour les tests utilisateurs, le test et le développement en pourcentage. Par exemple, estimez 50 % du dimensionnement de la production.
Pour exécuter un rapport AWR à partir de la ligne de commande, utilisez la commande suivante :
sqlplus / as sysdba
@$ORACLE_HOME/rdbms/admin/awrrpt.sql;
Mesures clés
Le rapport vous invite à fournir les informations suivantes :
- Type de rapport : HTML ou TEXT. Le type HTML fournit plus d’informations.
- Le nombre de jours d’instantanés à afficher. Par exemple, pour des intervalles d’une heure, un rapport d’une semaine produit 168 identifiants d’instantanés.
- Le
SnapshotIDde début pour la fenêtre du rapport. - Le
SnapshotIDde fin pour la fenêtre du rapport. - Nom du rapport créé par le script AWR.
Si vous exécutez le rapport AWR sur une base de données Real Application Cluster (RAC), le rapport de la ligne de commande est le fichier awrgrpt.sql, au lieu du fichier awrrpt.sql. Le rapport g crée un rapport pour tous les nœuds de la base de données RAC, dans un seul rapport. Ce rapport évite d’avoir à exécuter un rapport sur chaque nœud RAC.
Vous pouvez obtenir les métriques suivantes à partir du rapport AWR :
- Nom de la base de données, nom de l’instance et nom d’hôte
- Version de la base de données pour la prise en charge par Oracle
- Processeur/cœurs
- SGA/PGA, et conseillers qui vous préviennent en cas de sous-dimensionnement
- Quantité totale de mémoire en Go
- Pourcentage UC occupé
- Processeurs de base de données
- E/S par seconde (lecture/écriture)
- Mbits/s (lecture/écriture)
- Débit du réseau
- Taux de latence réseau (élevée/basse)
- Premiers événements d’attente
- Paramètres de la base de données
- Que la base de données soit de type RAC ou Exadata, ou qu’elle utilise des fonctionnalités ou des configurations avancées
Taille de la machine virtuelle
Voici quelques étapes que vous pouvez suivre pour configurer la taille de la machine virtuelle afin d’obtenir des performances optimales.
Estimer la taille de la machine virtuelle en fonction des données d’utilisation du processeur, de la mémoire ou des E/S du rapport AWR
Examinez les cinq principaux événements de premier plan expirés, qui indiquent où se trouvent les goulots d’étranglement du système. Par exemple, dans le diagramme suivant, la synchronisation des fichiers journaux se trouve en haut. Elle indique le nombre d’attentes nécessaires avant que l’enregistreur de journal écrive le tampon journal dans le fichier journal de la phase de restauration par progression. Ces résultats indiquent qu’un stockage ou des disques plus performants sont nécessaires. Le diagramme montre aussi le nombre de cœurs d’UC et la quantité de mémoire.
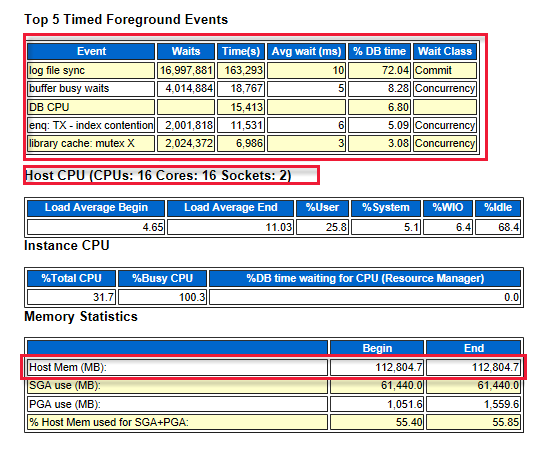
Le diagramme suivant montre le nombre total d’E/S de lecture et d’écriture. 59 Go ont été lus et 247,3 Go ont été écrits au moment de la création du rapport.

Choisir une machine virtuelle
À partir des informations collectées dans le rapport AWR, l’étape suivante consiste à choisir une machine virtuelle de taille similaire qui répond à vos besoins. Pour plus d’informations relatives aux VM disponibles, reportez-vous à Tailles de machine virtuelle à mémoire optimisée.
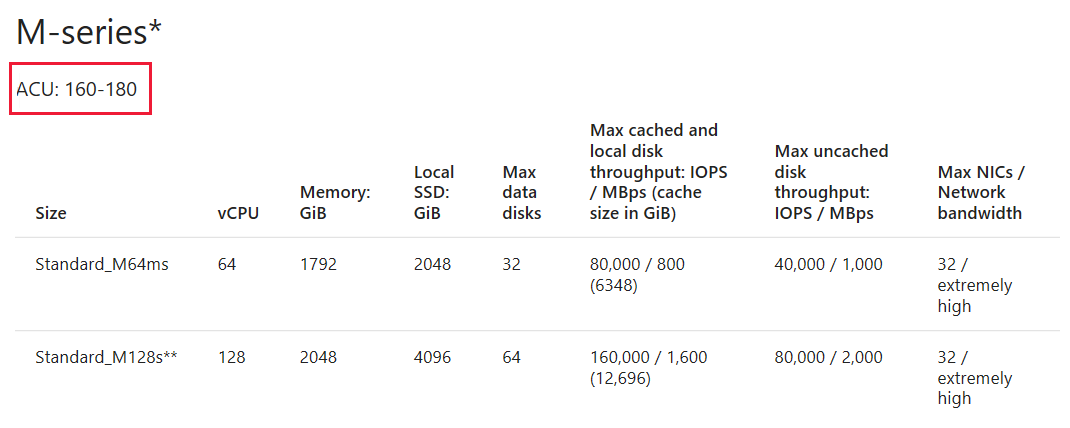
Ajuster la taille de la machine virtuelle aux séries de machines virtuelles similaires en fonction de l’ACU
Une fois que vous avez choisi la machine virtuelle, faites attention à son unité Compute Azure (ACU). Vous choisirez peut-être une autre machine virtuelle en fonction de la valeur ACU, qui répondra mieux à vos besoins. Pour plus d’informations, consultez Unité de calcul Azure (ACU).
Débit du réseau
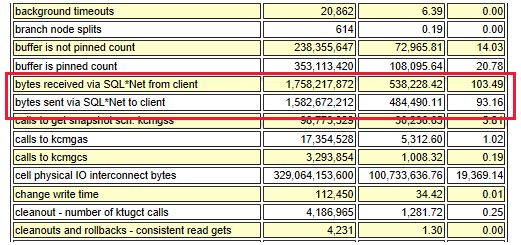
Le diagramme suivant montre la relation entre le débit et le nombre d’E/S par seconde :

Le débit réseau total est estimé selon les informations suivantes :
- Trafic SQL*Net
- Mbits/s multiplié par le nombre de serveurs (flux sortant, par exemple Oracle Data Guard)
- Autres facteurs, comme la réplication de l’application
Selon vos besoins en bande passante réseau, vous pouvez choisir différents types de passerelles, Ces types comprennent une passerelle de base, VpnGw ou Azure ExpressRoute. Pour plus d’informations, consultez Tarification Passerelle VPN.
Recommandations
- La latence réseau est supérieure par rapport à un déploiement local. La diminution des allers-retours réseau peut considérablement améliorer les performances.
- Pour réduire le nombre d’allers-retours, regroupez les applications avec un nombre élevé de transactions et les applications « bavardes » sur une même machine virtuelle.
- Utilisez des machines virtuelles avec des performances réseau accélérées pour de meilleures performances réseau.
- Pour certaines distributions Linux, pensez à activer la prise en charge de TRIM/UNMAP.
- Installez Oracle Enterprise Manager sur une machine virtuelle distincte.
- Les Huge Pages ne sont pas activées par défaut sur Linux. Envisagez d’activer les Hugepages et définissez
use_large_pages = ONLYsur Oracle DB. Cette approche peut contribuer à améliorer les performances. Pour plus d’informations, consultez USE_LARGE_PAGES.
Types de disque et configurations
Voici quelques conseils pour vous aider à choisir vos disques.
Disques de système d’exploitation par défaut : Ces types de disques permettent la persistance et la mise en cache des données. Ils sont optimisés pour l’accès au système d’exploitation au moment du démarrage, mais ils ne sont pas conçus pour les charges de travail transactionnelles ou d’entrepôt de données (analytiques).
Disques managés : Azure gère les comptes de stockage que vous utilisez pour vos disques de machine virtuelle. Vous spécifiez le type de disque et la taille de disque dont vous avez besoin. Le type est le plus souvent Premium (SSD) pour les charges de travail Oracle. Azure crée et gère le disque pour vous. Un disque managé SSD Premium est disponible uniquement pour les séries de machines virtuelles à mémoire optimisée à la conception. Une fois que vous avez choisi une taille de machine virtuelle, le menu affiche uniquement les références SKU de stockage Premium disponibles qui sont associées à cette taille de machine virtuelle.


Une fois que vous avez configuré votre stockage sur une machine virtuelle, vous pouvez tester la charge des disques avant de créer une base de données. Le fait de connaître la latence et le débit du taux d’E/S peut vous aider à déterminer si les machines virtuelles prennent en charge le débit attendu avec les cibles de latence. Il existe plusieurs outils pour le test de charge d’application, notamment Oracle Orion, Sysbench, SLOB et Fio.
Réexécutez le test de charge après avoir déployé une base de données Oracle. Démarrez vos charges de travail normales et maximales pour voir la base de référence de votre environnement. Soyez réaliste lors du test de la charge de travail. Il est inutile d’exécuter une charge de travail qui ne ressemble en rien à celle que vous exécutez réellement sur la machine virtuelle.
Oracle pouvant être une base de données qui consomment beaucoup d’E/S, il est important de dimensionner le stockage en fonction du taux d’IOPS plutôt que de la taille de stockage. Par exemple, si la valeur d’IOPS nécessaire est de 5 000, alors que vous n’avez besoin que de 200 Go, vous pouvez quand même obtenir le disque Premium de classe P30, même s’il est fourni avec plus de 200 Go de stockage.
Vous pouvez obtenir le taux d’IOPS dans le rapport AWR. Le taux de journalisation en phase de restauration par progression, de lectures physiques et d’écritures détermine le taux d’IOPS. Vérifiez toujours que la série de machines virtuelles que vous choisissez peut gérer la demande d’E/S de la charge de travail. Si la limite d’E/S de la VM est inférieure à celle du stockage, la VM fixe la limite maximale.
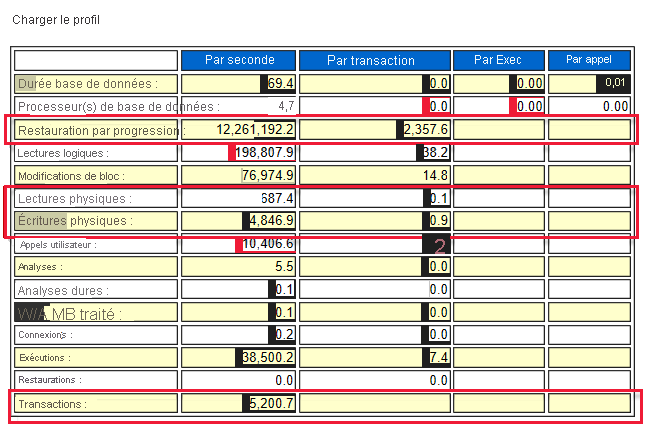
Par exemple : la restauration par progression fait 12 200 000 octets par seconde, ce qui est égal à 11,63 Mbits/s. La valeur d’IOPS est de 12 200 000/2 358 = 5 174.
Une fois que vous avez une vision claire de vos besoins en E/S, vous pouvez choisir une combinaison de disques mieux adaptée à ces besoins.
Recommandations sur les types de disque
- Pour l’espace disque logique de données, répartissez la charge de travail E/S sur plusieurs disques en utilisant le stockage géré ou Oracle Automatic Storage Management (ASM).
- Utilisez la compression avancée d’Oracle pour réduire les E/S des données et des index.
- Placez les journaux de restauration par progression ainsi que les espaces disques logiques Temp et Undo sur des disques de données distincts.
- Ne placez aucun fichier d’application sur les disques de système d’exploitation par défaut. Ces disques sont optimisés pour les démarrages rapides de machine virtuelle et risquent de ne pas fournir de performances optimales pour votre application.
- Lorsque vous utilisez des machines virtuelles de série M sur le stockage Premium, activez Accélérateur d’écriture sur le disque des journaux de restauration par progression.
- Envisagez de déplacer les journaux de restauration par progression présentant une latence élevée vers le disque UItra.
Paramètres de cache des disques
Bien que vous disposiez de trois options pour la mise en cache de l’hôte, seule la mise en cache en lecture seule est recommandée pour une charge de travail de base de données sur une base de données Oracle. Le mode lecture/écriture peut introduire des vulnérabilités importantes dans un fichier de données, car l’objectif d’une écriture de base de données est d’enregistrer les informations dans le fichier de données, et non de les mettre en cache. Avec la lecture seule, toutes les demandes sont mises en cache pour les lectures ultérieures. toutes les écritures continuent d’être écrites sur le disque.
Recommandations de cache de disque
Pour maximiser le débit, commencez par la lecture seule pour la mise en cache de l’hôte lorsque cela est possible. Pour le stockage Premium, vous devez désactiver les barrières lorsque vous montez le système de fichiers avec les options de lecture seule. Mettez à jour le fichier /etc/fstab avec l’identificateur unique universel sur les disques.

- Pour les disques de système d’exploitation, utilisez SSD Premium avec mise en cache de l’hôte en lecture/écriture.
- Pour les disques de données qui contiennent les éléments qui suivent, utilisez un SSD Premium avec une mise en cache de l’hôte en lecture seule : fichiers de données Oracle, fichiers temporaires, fichiers de contrôle, fichiers de suivi des modifications en bloc, BFILE, fichiers pour les tables externes et journaux flashback.
- Pour les disques de données qui contiennent des fichiers journaux de restauration par progression en ligne d’Oracle, utilisez un SSD Premium ou UltraDisk sans mise en cache de l’hôte (option Aucun). Les fichiers journaux de restauration par progression d’Oracle qui sont archivés et les jeux de sauvegarde Oracle Recovery Manager peuvent également résider avec les fichiers journaux de restauration par progression en ligne. La mise en cache de l’hôte est limitée à 4 095 Gio : n’allouez pas de SSD Premium supérieur à P50 avec la mise en cache de l’hôte. Si vous avez besoin de plus de 4 Tio de stockage, regroupez plusieurs disques SSD haut de gamme en RAID-0. Utilisez Linux LVM2 ou Oracle Automatic Storage Management.
Si les charges de travail varient fortement entre la journée et la soirée et que la charge de travail d’E/S peut prendre en charge ces variations, un disque SSD Premium P1 à P20 en mode bursting peut fournir les performances requises pendant les charges par lots de nuit ou les demandes d’E/S limitées.
Sécurité
Une fois votre environnement Azure créé et configuré, vous devez sécuriser votre réseau. Voici quelques recommandations :
Stratégie de groupe de sécurité réseau : Vous pouvez définir votre groupe de sécurité réseau par un sous-réseau ou une carte d’interface réseau. Il est plus simple de contrôler l’accès au niveau du sous-réseau, à la fois pour la sécurité et pour le routage forcé des pare-feu d’application.
Serveur de rebond : Pour un accès plus sécurisé, les administrateurs ne doivent pas se connecter directement au service d’application ou à la base de données. Utilisez un serveur de rebond entre la machine de l’administrateur et les ressources Azure.
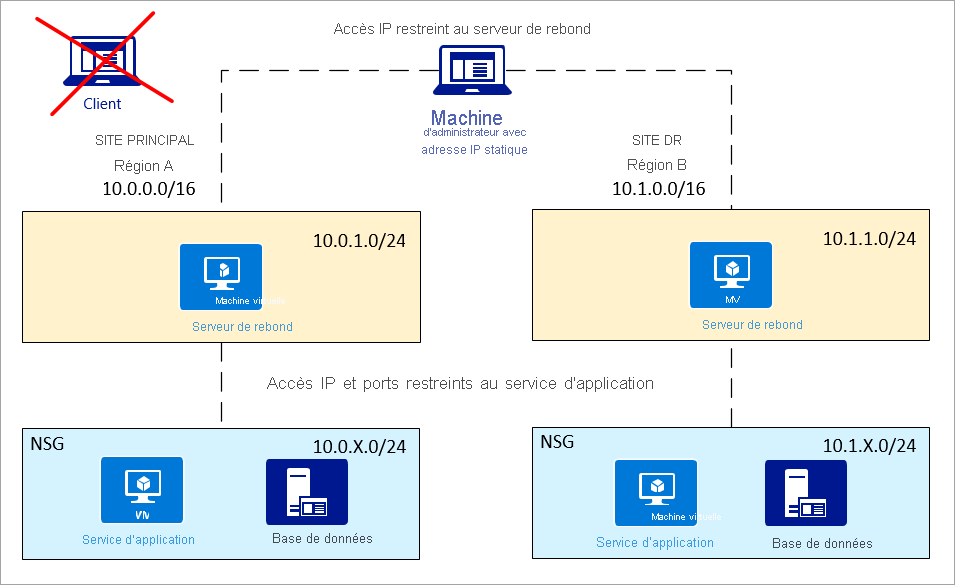
L’accès à la machine de l’administrateur doit être limité à l’adresse IP du serveur de rebond. La jumpbox doit avoir accès à l’application et à la base de données.
Réseau privé (sous-réseaux) : Il est judicieux de placer le service d’application et la base de données sur des sous-réseaux distincts, afin que la stratégie du groupe de sécurité réseau puisse mieux les contrôler.

Ressources
- Configurer Oracle ASM
- Implémenter Oracle Data Guard sur une machine virtuelle Linux Azure
- Configurer Oracle GoldenGate
- Sauvegarde et récupération Oracle