Personnalisation du modèle (version 4.0 en préversion)
La personnalisation du modèle vous permet d’entraîner un modèle d’analyse d’image spécialisé pour votre propre cas d’usage. Les modèles personnalisés peuvent effectuer une classification d’images (les étiquettes s’appliquent à l’image entière) ou une détection d’objets (les étiquettes s’appliquent à des zones particulières de l’image). Une fois créé, puis formé, votre modèle personnalisé appartient à votre ressource Vision, et vous pouvez l’appeler à l’aide de l’API Analyse Image.
Implémentez rapidement et facilement la personnalisation du modèle en suivant un guide de démarrage rapide :
Important
Vous pouvez entraîner un modèle personnalisé à l’aide du service Custom Vision ou du service Image Analysis 4.0 avec la personnalisation du modèle. Le tableau suivant compare les deux services.
| Zones (Areas) | Service Custom Vision | Service Analyse d’image 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tâches | Classification d’images Détection d’objets |
Classification d’images Détection d’objets |
||||||||||||||||||||||||||||||||||||
| Modèle de base | CNN | Modèle transformateur | ||||||||||||||||||||||||||||||||||||
| L’étiquetage | Customvision.ai | Studio AML | ||||||||||||||||||||||||||||||||||||
| Portail web | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Bibliothèques | REST, SDK | REST, Exemple Python | ||||||||||||||||||||||||||||||||||||
| Données d’apprentissage minimales nécessaires | 15 images par catégorie | 2 à 5 images par catégorie | ||||||||||||||||||||||||||||||||||||
| Stockage des données d’apprentissage | Chargé vers le service | Compte de stockage d’objets blob du client | ||||||||||||||||||||||||||||||||||||
| Hébergement de modèles | Cloud et périphérie | Hébergement cloud uniquement, hébergement de conteneur de périphérie à venir | ||||||||||||||||||||||||||||||||||||
| Qualité de l’IA |
|
|
||||||||||||||||||||||||||||||||||||
| Tarification | Tarifs Custom Vision | Tarification d’Analyse d’image |
Composants du scénario
Les principaux composants d’un système de personnalisation de modèle sont les images d’entraînement, le fichier COCO, l’objet de jeu de données et l’objet de modèle.
Images d’entraînement
Votre ensemble d’images d’entraînement doit inclure plusieurs exemples de chacune des étiquettes que vous souhaitez détecter. Vous allez également collecter quelques images supplémentaires pour tester votre modèle une fois qu’il sera entraîné. Les images doivent être stockées dans un conteneur de stockage Azure, afin d’être accessibles au modèle.
Pour entraîner votre modèle efficacement, utilisez des images avec une variété de visuels. Sélectionnez des images dont les éléments suivants varient :
- angle de l’appareil photo
- éclairage
- background
- style de visuel
- objets individuels/groupés
- taille
- type
En outre, vérifiez que toutes vos images d’entraînement respectent les critères suivants :
- L’image doit être présentée au format JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF ou MPO.
- La taille de fichier de l’image doit être inférieure à 20 mégaoctets (Mo).
- Les dimensions de l’image doivent être supérieures à 50 x 50 pixels et inférieures à 16 000 x 16 000 pixels.
Fichier COCO
Le fichier COCO référence toutes les images d’entraînement et les associe à leurs informations d’étiquetage. Dans le cas de la détection d’objet, il a spécifié les coordonnées de cadre englobant de chaque étiquette sur chaque image. Ce fichier doit être au format COCO, qui est un type particulier de fichier JSON. Le fichier COCO doit être stocké dans le même conteneur de stockage Azure que les images d’entraînement.
Conseil
À propos des fichiers COCO
Les fichiers COCO sont des fichiers JSON avec des champs obligatoires spécifiques : "images", "annotations" et "categories". Un exemple de fichier COCO se présente comme suit :
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Informations de référence sur les champs de fichier COCO
Si vous générez votre propre fichier COCO à partir de zéro, assurez-vous que tous les champs obligatoires sont remplis avec les détails corrects. Les tableaux suivants décrivent chaque champ dans un fichier COCO :
"images"
| Clé | Type | Description | Requis ? |
|---|---|---|---|
id |
entier | ID d’image unique, à partir de 1 | Oui |
width |
entier | Largeur de l’image en pixels | Oui |
height |
entier | Hauteur de l’image en pixels | Oui |
file_name |
string | Nom unique de l’image | Oui |
absolute_url ou coco_url |
string | Chemin d’accès à l’image en tant qu’URI absolu d’un objet blob dans un conteneur d’objets blob. La ressource Vision doit être autorisée à lire les fichiers d’annotation et tous les fichiers image référencés. | Oui |
La valeur de absolute_url se trouve dans les propriétés de votre conteneur d’objets blob :
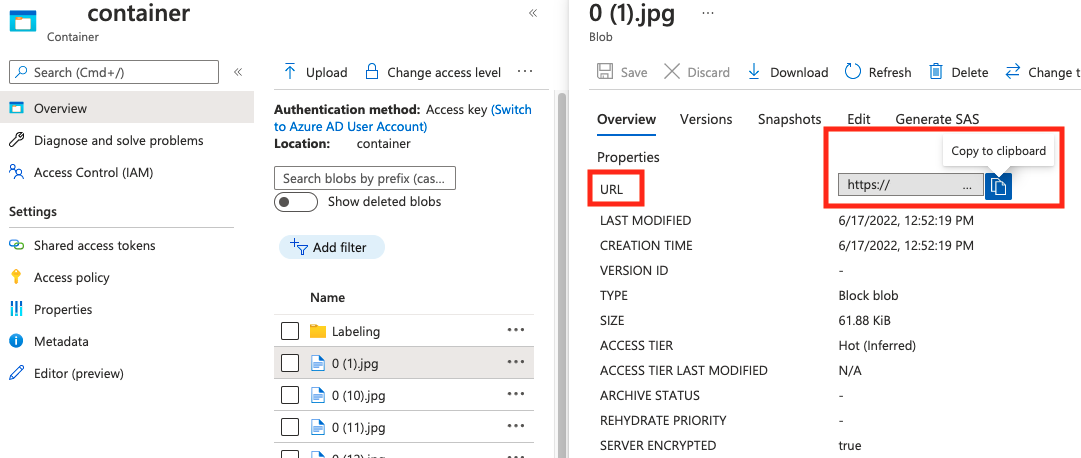
"annotations"
| Clé | Type | Description | Requis ? |
|---|---|---|---|
id |
entier | ID de l’annotation | Oui |
category_id |
entier | ID de la catégorie définie dans la section categories |
Oui |
image_id |
entier | ID de l’image | Oui |
area |
entier | Valeur de Largeur x Hauteur (troisième et quatrième valeurs de bbox) |
Non |
bbox |
list[float] | Coordonnées relatives du cadre englobant (0 à 1), dans l’ordre « Gauche », « Haut », « Largeur », « Hauteur » | Oui |
"categories"
| Clé | Type | Description | Requis ? |
|---|---|---|---|
id |
entier | ID unique pour chaque catégorie (classe d’étiquette). Ceux-ci doivent être présents dans la section annotations. |
Oui |
name |
string | Nom de la catégorie (classe d’étiquette) | Yes |
Vérification de fichiers COCO
Vous pouvez utiliser notre exemple de code Python pour vérifier le format d’un fichier COCO.
Objet Dataset
L’objet Dataset est une structure de données stockée par le service d’analyse d’image qui référence le fichier d’association. Vous devez créer un objet Dataset avant de pouvoir créer et entraîner un modèle.
Objet Model
L’objet Model est une structure de données stockée par le service d’analyse d’image qui représente un modèle personnalisé. Il doit être associé à un Dataset pour effectuer l’entraînement initial. Une fois l’entraînement accompli, vous pouvez interroger votre modèle en entrant son nom dans le paramètre de requête model-name de l’appel de l’API Analyse Image.
Limites de quota
Le tableau suivant décrit les limites de l’échelle de vos projets de modèles personnalisés.
| Category | Classifieur d’images génériques | Détecteur d’objets génériques |
|---|---|---|
| Nbre max. d’heures d’entraînement | 288 (12 jours) | 288 (12 jours) |
| Nbre max. d’images d’entraînement | 1 000 000 | 200 000 |
| Nbre max. d’images d’évaluation | 100 000 | 100 000 |
| Nbre min. d’images d’entraînement par catégorie | 2 | 2 |
| Nbre max. d’étiquettes par image | multiclasse : 1 | N/D |
| Nbre max. de régions par image | N/D | 1 000 |
| Nbre max. de catégories | 2 500 | 1 000 |
| Nbre min. de catégories | 2 | 1 |
| Taille maximale de l’image (Entraînement) | 20 Mo | 20 Mo |
| Taille maximale de l’image (Prédiction) | Synchro. : 6 Mo, Lot : 20 Mo | Synchro. : 6 Mo, Lot : 20 Mo |
| Largeur/hauteur max. de l’image (Entraînement) | 10 240 | 10 240 |
| Largeur/hauteur min. de l’image (Prédiction) | 50 | 50 |
| Régions disponibles | USA Ouest 2, USA Est, Europe Ouest | USA Ouest 2, USA Est, Europe Ouest |
| Types d’images acceptés | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Forum aux questions
Pourquoi l’importation de mon fichier COCO échoue-t-elle lors de l’importation à partir du stockage d’objets blob ?
Actuellement, Microsoft travaille sur un problème qui provoque l’échec de l’importation de fichiers COCO avec des jeux de données volumineux lorsqu’elle est lancée dans Vision Studio. Pour effectuer l’apprentissage à l’aide d’un jeu de données volumineux, il est recommandé d’utiliser plutôt l’API REST.
Pourquoi l’entraînement prend-il plus/moins de temps que mon budget spécifié ?
Le budget d’entraînement précisé est le temps de calcul étalonné, et non le temps de l’horloge. Voici quelques raisons qui expliquent cette différence :
Plus long que le budget spécifié :
- Le service d’analyse d’image connaît un trafic d’entraînement élevé, et les ressources GPU peuvent être insuffisantes. Votre travail peut attendre dans la file d’attente ou être mis en attente pendant l’entraînement.
- Le processus d’entraînement back-end a rencontré des échecs inattendus, ce qui s’est soldé par une nouvelle tentative de logique. Les exécutions ayant échoué ne consomment pas votre budget, mais un temps d’entraînement plus long peut en découler en général.
- Vos données sont stockées dans une région différente de celle de votre ressource Vision créée, ce qui se traduit par un allongement du temps de transmission des données.
Plus court que le budget spécifié : Les facteurs suivants accélèrent l’entraînement au détriment d’une utilisation accrue du budget dans un certain temps d’horloge.
- L’entraînement de l’analyse d’images s’effectue parfois avec plusieurs GPU, en fonction de vos données.
- L’analyse d’images entraîne parfois plusieurs essais d’exploration sur plusieurs GPU en même temps.
- L’analyse d’images utilise parfois des SKU de GPU du support Premier (plus rapides) pour l’entraînement.
Pourquoi mon entraînement échoue-t-il, et que dois-je faire ?
Voici quelques raisons courantes de l’échec de l’entraînement :
diverged: L’entraînement ne peut pas apprendre de choses significatives de vos données. Certaines causes communes sont les suivantes :- Les données sont insuffisantes : l’apport de plus de données devrait aider.
- Les données sont de mauvaise qualité : vérifiez si vos images sont de faible résolution, de proportions extrêmes ou si les annotations sont incorrectes.
notEnoughBudget: Votre budget spécifié n’est pas suffisant pour la taille de votre jeu de données et du type de modèle que vous entraînez. Indiquez un budget plus important.datasetCorrupt: Cela signifie généralement que vos images fournies ne sont pas accessibles ou que le fichier d’annotation est au format incorrect.datasetNotFound: Le jeu de données est introuvable.unknown: Il peut s’agir d’un problème de back-end. Prenez contact avec le support pour examen.
Quelles métriques sont utilisées pour évaluer les modèles ?
Les mesures suivantes sont utilisées :
- Classification d’images : Précision moyenne, Précision Top 1, Précision Top 5
- Détection d’objet : Précision moyenne @ 30, Précision moyenne @ 50, Précision moyenne @ 75
Pourquoi l’inscription de mon jeu de données échoue-t-elle ?
Les réponses de l’API doivent donner suffisamment d’informations. Il s'agit des éléments suivants :
DatasetAlreadyExists: Un jeu de données du même nom existe déjà.DatasetInvalidAnnotationUri: Un URI non valide a été fourni parmi les URI d’annotation au moment de l’inscription du jeu de données.
Combien d’images sont nécessaires pour une qualité de modèle raisonnable/bonne/optimale ?
Bien que les modèles Florence disposent d’une grande capacité few-shot (permettant d’obtenir d’excellentes performances de modèle avec une disponibilité limitée de données), en général, un volume plus important de données améliore votre modèle entraîné et le rend plus robuste. Certains scénarios nécessitent peu de données (comme la classification d’une pomme par rapport à une banane), mais d’autres demandent davantage (comme la détection de 200 types d’insectes dans une forêt tropicale). Il est donc difficile de donner une seule recommandation.
Si votre budget d’étiquetage des données est limité, le workflow que nous recommandons est de répéter les étapes suivantes :
Collectez des images
Npar classes, pour lesquelles la collecte d’imagesNest facile pour vous (par exemple,N=3).Entraînez un modèle et testez-le sur votre jeu d’évaluation.
Si les performances du modèle sont les suivantes :
- Suffisantes (performances supérieures à vos attentes, ou performances proches de votre expérience précédente avec moins de données collectées) : arrêtez-vous ici et utilisez ce modèle.
- Insuffisantes (les performances sont toujours inférieures à vos attentes, ou supérieures à celles de votre expérience précédente avec moins de données collectées dans une marge acceptable) :
- Collectez plus d’images pour chaque classe, un nombre facile à collecter pour vous, et revenez à l’étape 2.
- Si vous remarquez que les performances ne s’améliorent plus après quelques itérations, c’est peut-être parce que :
- ce problème n’est pas bien défini, ou qu’il est trop difficile. Contactez-nous pour une analyse au cas par cas.
- les données d’entraînement peuvent être de qualité médiocre : vérifiez s’il existe des annotations incorrectes ou des images à nombre très faible de pixels.
Quel budget d’entraînement dois-je préciser ?
Vous devez indiquer la limite supérieure de budget que vous êtes prêt à consommer. L’analyse d’images utilise un système AutoML dans son back-end pour tester différents modèles et recettes d’entraînement qui permettent de trouver le meilleur modèle pour votre cas d’usage. Plus le budget est élevé, plus il y a de chances de trouver un meilleur modèle.
Le système AutoML s’arrête aussi automatiquement s’il conclut qu’il n’est pas nécessaire d’essayer davantage, même s’il reste encore du budget. Ainsi, il n’épuise pas toujours votre budget spécifié. Vous êtes sûr qu’un montant supérieur à votre budget spécifié ne vous est pas facturé.
Puis-je contrôler les hyper-paramètres ou utiliser mes propres modèles dans l’entraînement ?
Non, le service de personnalisation du modèle d’analyse d’images utilise un système d’entraînement AutoML à faible code, qui gère la recherche hyper-param et la sélection du modèle de base dans le back-end.
Puis-je exporter mon modèle après l’entraînement ?
L’API de prédiction est uniquement prise en charge via le service cloud.
Pourquoi l’évaluation échoue-t-elle pour mon modèle de détection d’objet ?
Voici les raisons possibles :
internalServerError: Une erreur inconnue s’est produite. Veuillez réessayer plus tard.modelNotFound: Le modèle spécifié est introuvable.datasetNotFound: Le jeu de données spécifié est introuvable.datasetAnnotationsInvalid: Une erreur s’est produite lors de la tentative de téléchargement ou d’analyse des annotations de réalité de terrain associées au jeu de données de test.datasetEmpty: Le jeu de données de test ne contenait aucune annotation de « réalité de terrain ».
Quelle est la latence attendue pour les prédictions faites avec des modèles personnalisés ?
Nous vous déconseillons d’utiliser des modèles personnalisés pour les environnements vitaux pour l’entreprise en raison d’une latence potentiellement élevée. Lorsque les clients forment des modèles personnalisés dans Vision Studio, ces modèles personnalisés appartiennent à la ressource Azure AI Vision sous laquelle ils ont été formés, et le client peut effectuer des appels à ces modèles à l’aide de l’API Analyse Image. Lors de ces appels, le modèle personnalisé est chargé en mémoire et l’infrastructure de prédiction est initialisée. Dans ce cas, les clients peuvent rencontrer une latence plus longue que prévu avant de recevoir les résultats de prédiction.
Sécurité et confidentialité des données
Comme avec tous les services Azure AI services, les développeurs utilisant la personnalisation du modèle Analyse d’image doivent connaître les politiques de Microsoft relatives aux données clientes. Si vous souhaitez obtenir plus d’informations, consultez la page Azure AI services dans le Centre de gestion de la confidentialité Microsoft.