Modèle de document général Intelligence documentaire
Important
À compter des versions 2024-02-29-preview, 2023-10-31-preview de l’Intelligence documentaire, le modèle de document général (prédéfini-document) est déconseillé. Pour extraire des paires clé-valeur, des marques de sélection, du texte, des tableaux et de la structure à partir de documents, utilisez les modèles suivants :
| Fonction | version | ID de modèle |
|---|---|---|
Modèle Layout avec le paramètre de chaîne de requête facultatif features=keyValuePairs activé. |
• v4:2024-02-29-preview • v3.1:2023-07-31 (GA) |
prebuilt-layout |
| Modèle de document général | • v3.1:31-07-2023 (GA) • v3.0:31-08-2022 (GA) • v2.1 (GA) |
prebuilt-document |
Ce contenu s’applique à :![]() v3.1 (GA) | Dernière version :
v3.1 (GA) | Dernière version :![]() v4.0 (préversion) | Version précédente :
v4.0 (préversion) | Version précédente :![]() v3.0
v3.0
Ce contenu s’applique à :![]() v3.0 (GA) | Dernières versions :
v3.0 (GA) | Dernières versions :![]() v4.0 (préversion)
v4.0 (préversion)![]() v3.1
v3.1
Le modèle Document général v3.0 combine de puissantes capacités de reconnaissance optique de caractères (OCR) à des modèles de Deep Learning pour extraire des paires clé-valeur, des tableaux et des marques de sélection à partir des documents. Le modèle Document général est uniquement disponible avec les API v3.1 et v3.0. Pour plus d’informations, consultez le Guide de migration.
Fonctionnalités Document général
Le modèle de document général est un modèle prédéfini. Il ne nécessite ni étiquettes ni apprentissage.
Une API unique extrait des paires clé-valeur, des marques de sélection, du texte, des tableaux et la structure des documents.
Le modèle de document général prend en charge les documents structurés, semi-structurés et non structurés.
Les marques de sélection sont identifiées en tant que champs avec une valeur
:selected:ou:unselected:.
Exemple de document traité utilisant Document Intelligence Studio
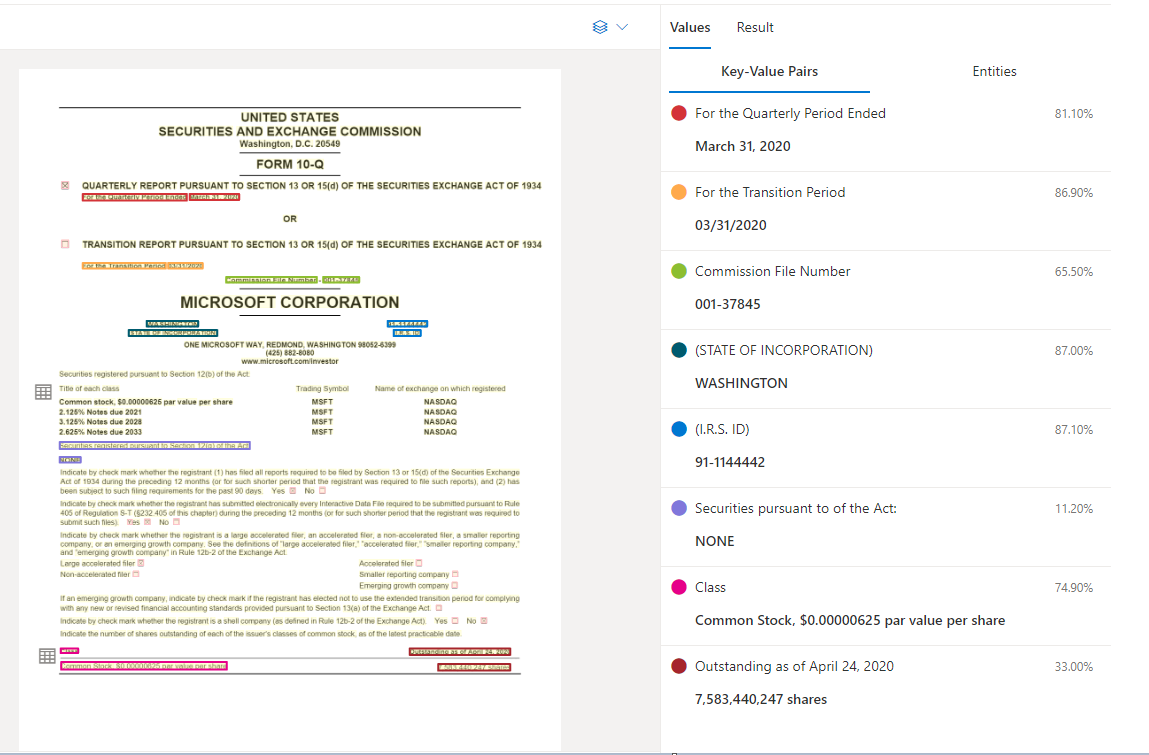
Extraction de paires clé-valeur
L’API de document général prend en charge l’essentiel des types de formulaires. L’API analyse vos documents et extrait les clés et les valeurs associées. Cet outil est idéal pour extraire les paires clé-valeur courantes des documents. Vous pouvez utiliser le modèle de document général comme alternative à la formation d’un modèle personnalisé sans étiquettes.
Options de développement
Document Intelligence v3.1 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de document général | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-document |
Intelligence documentaire v3.0 prend en charge les outils, applications et bibliothèques suivants :
| Fonction | Ressources | ID de modèle |
|---|---|---|
| Modèle de document général | • Document Intelligence Studio • API REST • Kit de développement logiciel (SDK) C# • Kit de développement logiciel (SDK) Python • Kit de développement logiciel (SDK) Java • Kit de développement logiciel (SDK) JavaScript |
prebuilt-document |
Critères des entrées
Pour de meilleurs résultats, fournissez une photo nette ou une copie de qualité par document.
Formats de fichiers pris en charge :
Modèle PDF Image :
JPEG/JPG, PNG, BMP, TIFF, HEIFMicrosoft Office :
Word (DOCX), Excel (XLSX), PowerPoint (PPTX) et HTMLLire ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview) Document général ✔ ✔ Prédéfinie ✔ ✔ Extraction personnalisée ✔ ✔ Classification personnalisée ✔ ✔ ✔ (2024-02-29-preview) Pour PDF et TIFF, il est possible de traiter jusqu’à 2 000 pages (avec un abonnement gratuit, seules les deux premières pages sont traitées).
La taille de fichier pour l’analyse des documents est de 500 Mo pour le niveau payant (S0) et de 4 Mo pour le niveau gratuit (F0).
Les dimensions des images doivent être comprises entre 50 x 50 et 10 000 x 10 000 pixels.
Si vos fichiers PDF sont verrouillés par mot de passe, vous devez supprimer le verrou avant leur envoi.
La hauteur minimale du texte à extraire est de 12 pixels pour une image de 1024 x 768 pixels. Cette dimension correspond à environ
8points de texte à 150 points par pouce (PPP).Pour la formation de modèles personnalisés, le nombre maximal de pages pour les données de formation est de 500 pour le modèle personnalisé et 50 000 pour le modèle neural personnalisé.
Pour l’entraînement du modèle d’extraction personnalisé, la taille totale des données d’entraînement est de 50 Mo pour le modèle et 1G-Mo pour le modèle neural.
Pour l’entraînement du modèle de classification personnalisée, la taille totale des données de formation est
1GB, avec un maximum à 10 000 pages.
Extraction de données du modèle de document général
Essayez d’extraire du texte à partir de formulaires et de documents à l’aide de Document Intelligence Studio.
Vous avez besoin des ressources suivantes :
Un abonnement Azure. Vous pouvez en créer un gratuitement.
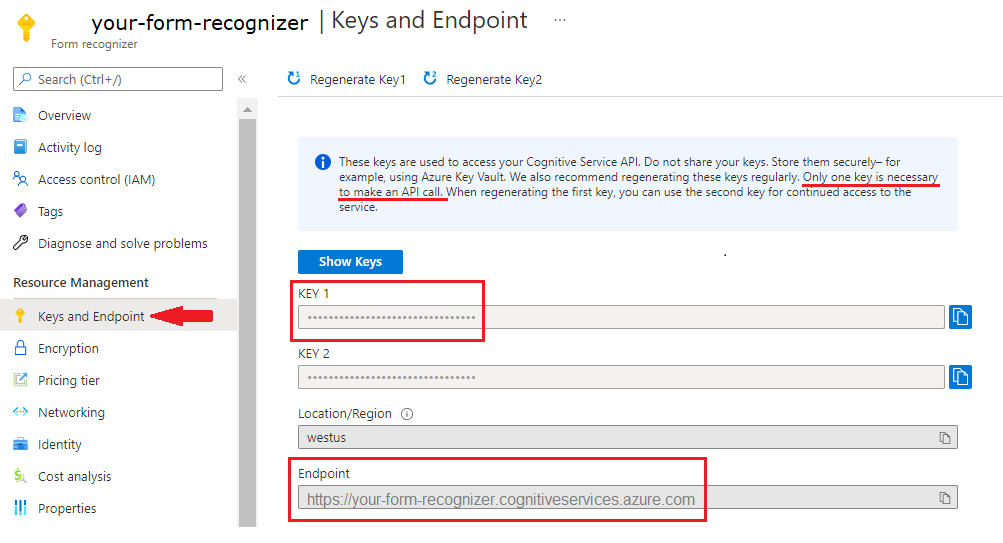
Instance Intelligence documentaire dans le Portail Azure. Vous pouvez utiliser le niveau tarifaire gratuit (
F0) pour tester le service. Une fois votre ressource déployée, sélectionnez Accéder à la ressource pour accéder à la clé et au point de terminaison.
Remarque
Document Intelligence Studio et le modèle de document général sont disponibles avec l’API v3.0.
Dans la page d’accueil Document Intelligence Studio, sélectionnez Documents généraux.
Vous pouvez analyser l’exemple de document ou charger vos propres fichiers.
Sélectionnez le bouton Exécuter l’analyse et, si nécessaire, configurez les Options d’analyse :

Paires clé-valeur
Les paires clé-valeur sont des portions spécifiques dans le document qui identifient une étiquette ou une clé, ainsi que la réponse ou la valeur associée. Dans un formulaire structuré, ces paires pourraient être l’étiquette et la valeur saisie par l’utilisateur pour ce champ. Dans un document non structuré, il pourrait s’agir de la date d’exécution d’un contrat en fonction du texte d’un paragraphe. Le modèle d’IA est formé à l’extraction des clés et des valeurs identifiables à partir d’une grande variété de types, de formats et de structures de documents.
Les clés peuvent également exister de manière isolée lorsque le modèle détecte qu’une clé existe sans valeur associée ou lors du traitement de champs facultatifs. Par exemple, le champ du second prénom peut être laissé vide sur un formulaire dans certains cas. Les paires clé-valeur sont des étendues de texte contenues dans le document. Si, dans certains documents, la même valeur est décrite de plusieurs manières, par exemple client/utilisateur, la clé associée est soit client, soit utilisateur (en fonction du contexte).
Extraction de données
| Modèle | Extraction de texte | Paires clé-valeur | Marques de sélection | Tables | Noms communs |
|---|---|---|---|---|---|
| Document général | ✓ | ✓ | ✓ | ✓ | ✓* |
✓* : disponible uniquement dans les 2023-07-31 versions d’API (v3.1 GA) et ultérieures.
Langues et régions prises en charge
Consultez notre page Support linguistique - modèles d'analyse documentaire pour une liste complète des langages pris en charge.
À propos de l’installation
Les clés étant des portions de texte extraites du document. Pour les documents semi-structurés, les clés doivent être mappées à un dictionnaire de clés existant.
Attendez-vous à voir des paires clé-valeur avec une clé, mais sans valeur. Par exemple, si un utilisateur a choisi de ne pas fournir d’adresse e-mail sur le formulaire.
Étapes suivantes
Suivez le guide de migration Intelligence documentaire v3.1 pour apprendre à utiliser la version 3.1 dans vos applications et workflows.
Découvrir notre API REST.